
Аналитика данных: влияние Apache Doris на создание отчетов, тегирование и операции с озером данных
9 января 2024 г.Несмотря на то, что мы говорим, что Apache Doris — это универсальная платформа данных, способная выполнять различные аналитические рабочие нагрузки, она всегда привлекательна для продемонстрировать это на реальных примерах использования. Вот почему я хотел бы поделиться с вами этой историей пользователя. Речь идет о том, как они используют возможности Apache Doris в области отчетности, тегирования клиентов и анализа озера данных и достигают высокой производительности.
Этот поставщик финтех-услуг является давним пользователем Apache Doris. У них почти 10 производственных кластеров, сотни серверных узлов Doris и тысячи процессорных ядер. Общий размер данных составляет около 1 ПБ. Каждый день они одновременно запускают сотни рабочих процессов, получают почти 10 миллиардов новых записей данных и отвечают на миллионы запросов данных.
До перехода на Apache Doris они использовали ClickHouse, MySQL и Elasticsearch. Затем возникают разногласия из-за постоянно растущего размера данных. Им было сложно масштабировать кластеры ClickHouse, поскольку было слишком много зависимостей. Что касается MySQL, им приходилось переключаться между различными экземплярами MySQL, поскольку у одного экземпляра MySQL были свои ограничения, а запросы между экземплярами не поддерживались.
Отчетность
От ClickHouse + MySQL до Apache Doris
Отчетность по данным — одна из основных услуг, которые они предоставляют своим клиентам, и на них распространяется соглашение об уровне обслуживания. Раньше они поддерживали такую услугу с помощью комбинации ClickHouse и MySQL, но обнаружили значительные колебания в продолжительности синхронизации данных, из-за чего им было трудно обеспечить уровни обслуживания, указанные в их SLA. Диагностика показала, что это произошло потому, что множество компонентов усложняют и делают нестабильными задачи синхронизации данных. Чтобы исправить это, они использовали Apache Doris в качестве единого аналитического механизма для поддержки отчетов по данным.
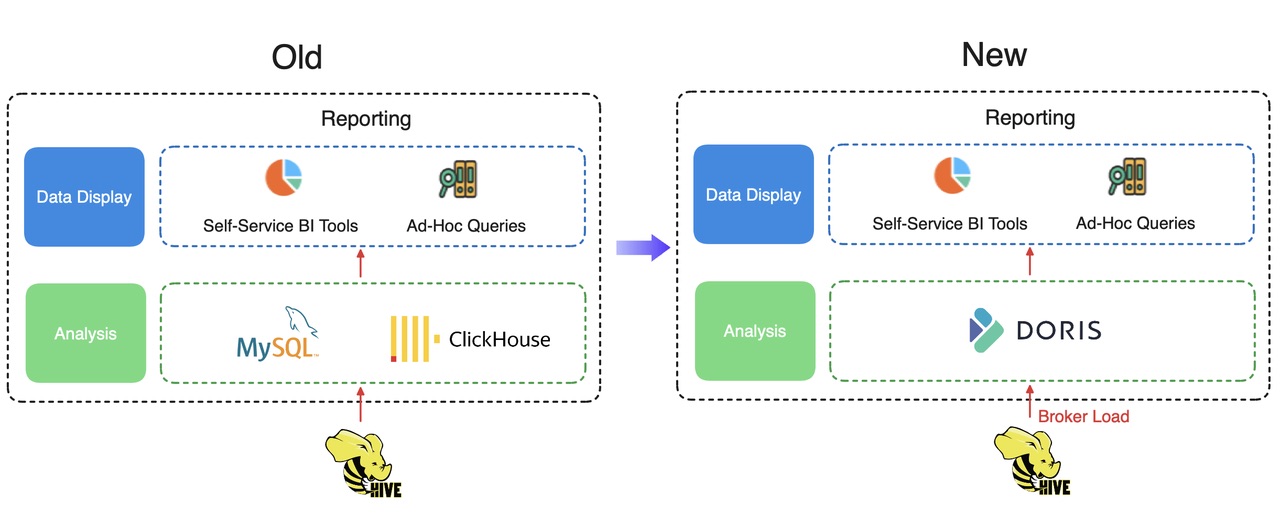
Улучшение производительности
При использовании Apache Doris они принимают данные через загрузку брокера метода и достижения уровня соответствия SLA более 99 % с точки зрения производительности синхронизации данных.
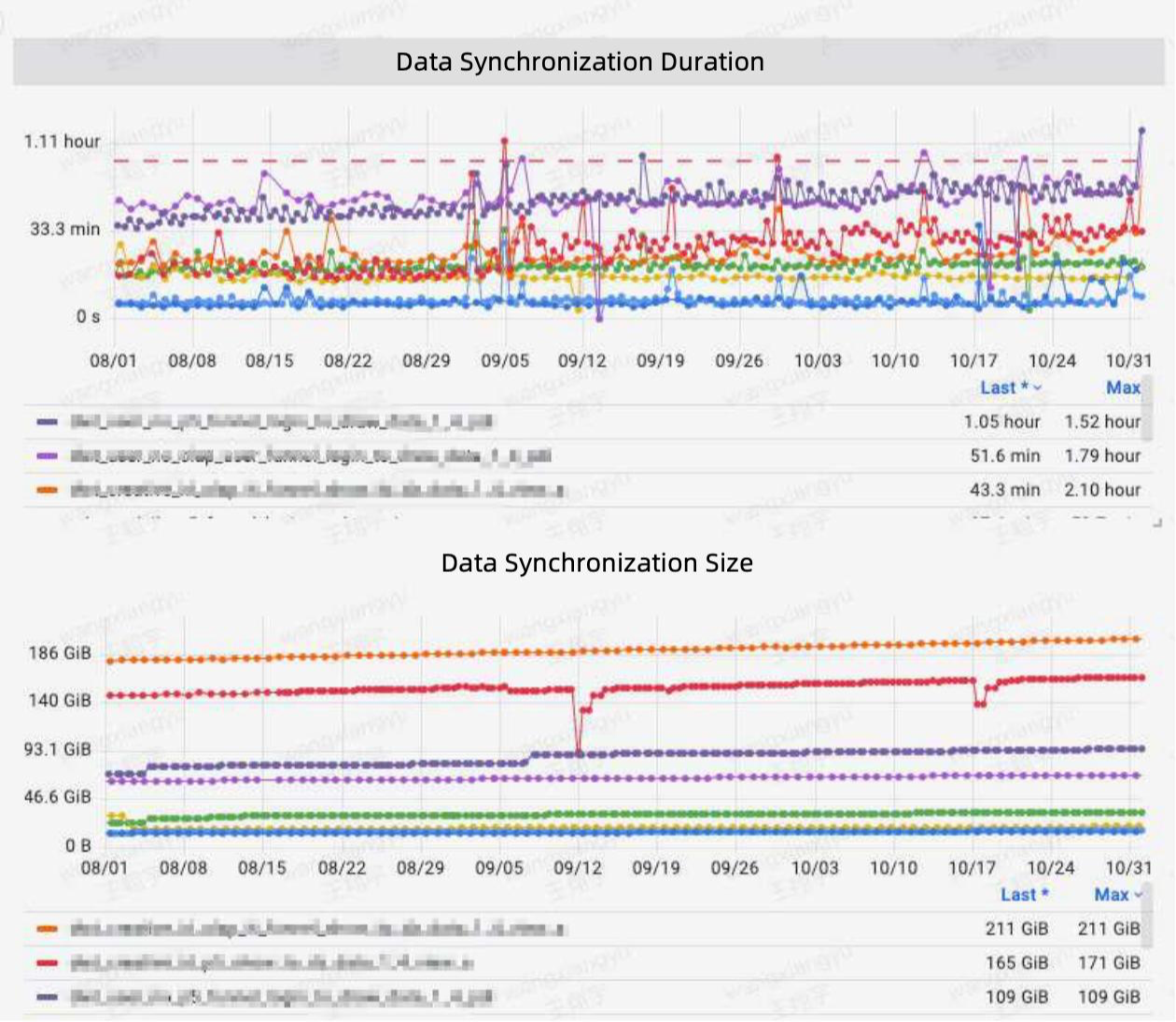
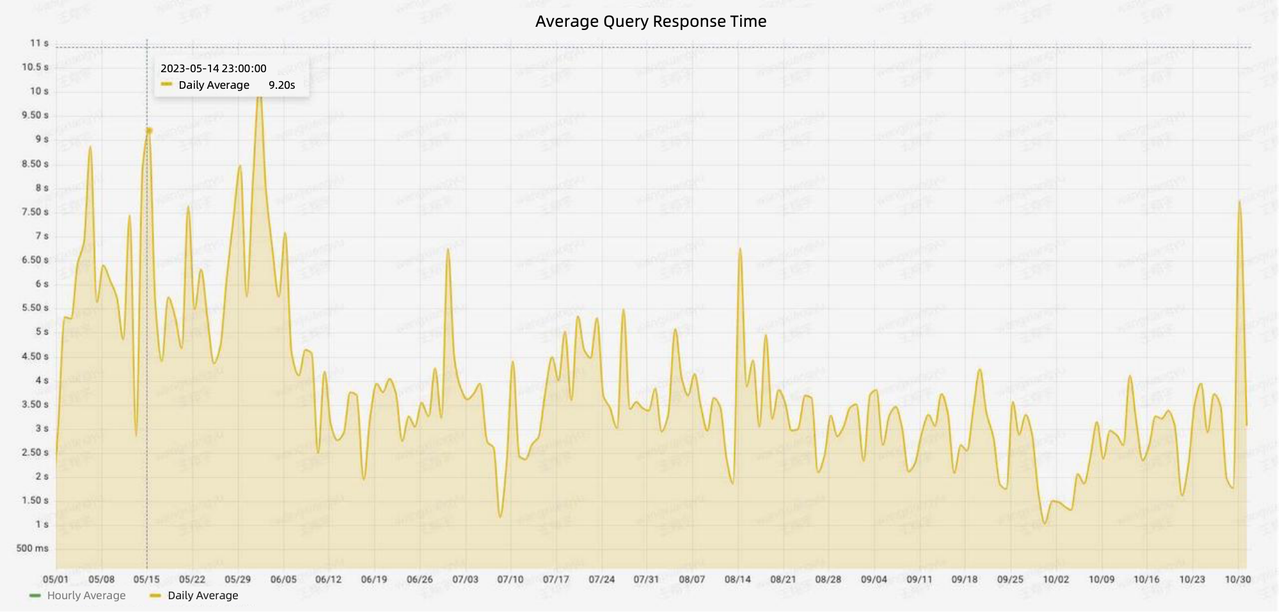
Что касается запросов данных, архитектура на основе Doris обеспечивает среднее время ответа на запрос менее 10 секунд и время ответа P90 менее < сильный>30 лет. Это ускорение на 50 % по сравнению со старой архитектурой.
Разметка
Тегирование – распространенная операция в аналитике клиентов. Вы присваиваете клиентам ярлыки на основе их поведения и характеристик, чтобы разделить их на группы и разработать целевые маркетинговые стратегии для каждой группы.
В старой архитектуре обработки, где механизмом обработки был Elasticsearch, необработанные данные принимались и правильно помечались. Затем они будут объединены в файлы JSON и импортированы в Elasticsearch, который предоставляет услуги обработки данных для аналитиков и маркетологов. В этом процессе этап слияния заключался в уменьшении количества обновлений и уменьшении нагрузки на Elasticsearch, но он оказался источником проблем:
* Любые проблемные данные в любом из тегов могут испортить всю операцию слияния и, таким образом, прервать работу служб передачи данных. *Операция объединения была реализована на базе Spark и MapReduce и заняла до 4 часов. Столь длительный срок может ущемить маркетинговые возможности и привести к невидимым потерям.
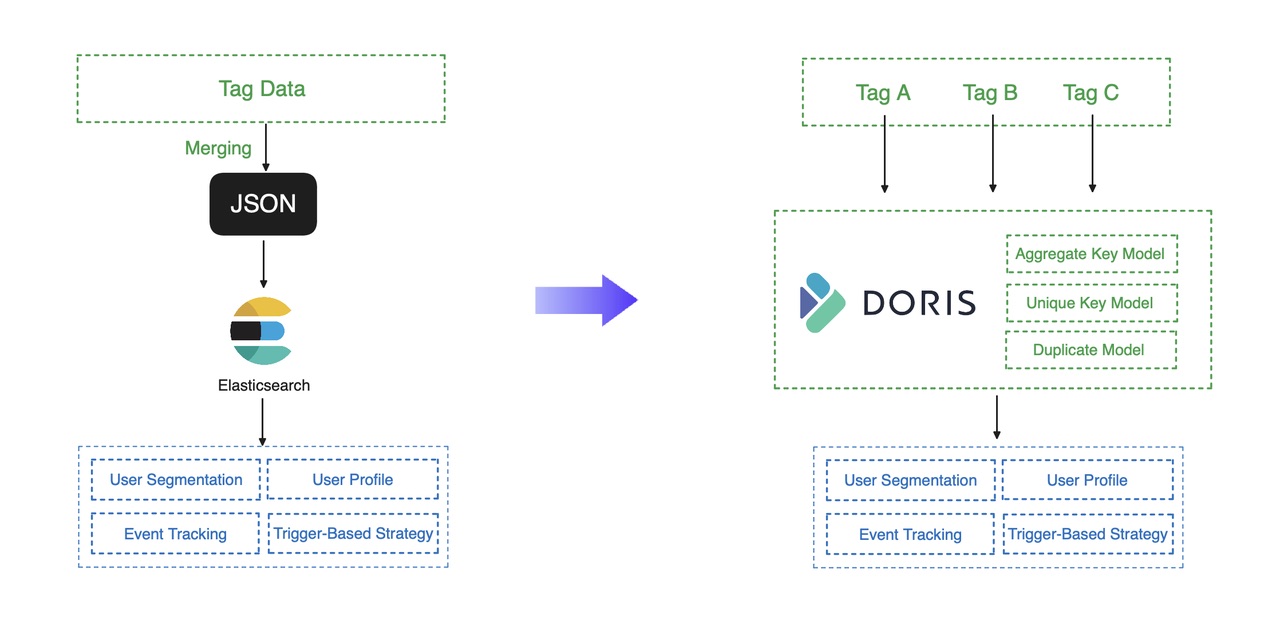
Затем это дело берет на себя Apache Doris. Apache Doris упорядочивает данные тегов с помощью своих моделей данных, которые обрабатывают данные быстро и плавно. Вышеупомянутый шаг слияния можно выполнить с помощью модели агрегатных ключей, которая объединяет теги. данные на основе указанного совокупного ключа при приеме данных. модель уникального ключа удобна для частичного обновления столбцов. Опять же, все, что вам нужно, это указать уникальный ключ. Это обеспечивает быстрое и гибкое обновление данных и избавляет вас от необходимости замены всей плоской таблицы. Вы также можете поместить свои подробные данные в дублирующую модель, чтобы ускорить выполнение определенных запросов. . На практике пользователю требовался 1 час для завершения приема данных по сравнению с 4 часами при старой архитектуре.
Что касается производительности запросов, Doris оснащен хорошо развитыми растровыми индексами и методами, адаптированными для запросов с высокой степенью параллелизма, поэтому в этом случае он может завершить сегментацию клиентов за считанные секунды и достичь более 700 QPS в запросах, ориентированных на пользователей.
Аналитика озера данных
В сценариях с озером данных размер данных, которые вам необходимо обработать, обычно огромен, но объем обработки данных в каждом запросе имеет тенденцию различаться. Чтобы обеспечить быстрый прием данных и высокую производительность запросов к огромным наборам данных, вам потребуется больше ресурсов. С другой стороны, в непиковое время вам нужно уменьшить масштаб кластера для более эффективного управления ресурсами. Как вы справляетесь с этой дилеммой?
Apache Doris имеет несколько функций, предназначенных для аналитики озера данных, включая мультикаталог и вычислительный узел. Первый защищает вас от головной боли, связанной с приемом данных в аналитике озера данных, а второй обеспечивает эластичное масштабирование кластера.
Механизм Мультикаталог позволяет подключать Doris к различным внешних источников данных, поэтому вы можете использовать Doris в качестве единого шлюза запросов, не беспокоясь о загрузке больших объемов данных в Doris.
Вычислительный узел Apache Doris — это серверная роль, предназначенная для удаленных рабочих нагрузок федеративных запросов, например в аналитике озера данных. Обычные серверные узлы Doris отвечают как за выполнение SQL-запросов, так и за управление данными, тогда как вычислительные узлы в Doris, как следует из названия, выполняют только вычисления. Вычислительные узлы не сохраняют состояние, что делает их достаточно эластичными для масштабирования кластера.
Пользователь вводит вычислительные узлы в свой кластер и развертывает их вместе с другими компонентами в гибридной конфигурации. В результате кластер автоматически масштабируется ночью, когда запросов меньше, и масштабируется в дневное время, чтобы справиться с большой рабочей нагрузкой запросов. Это более эффективно с точки зрения ресурсов.
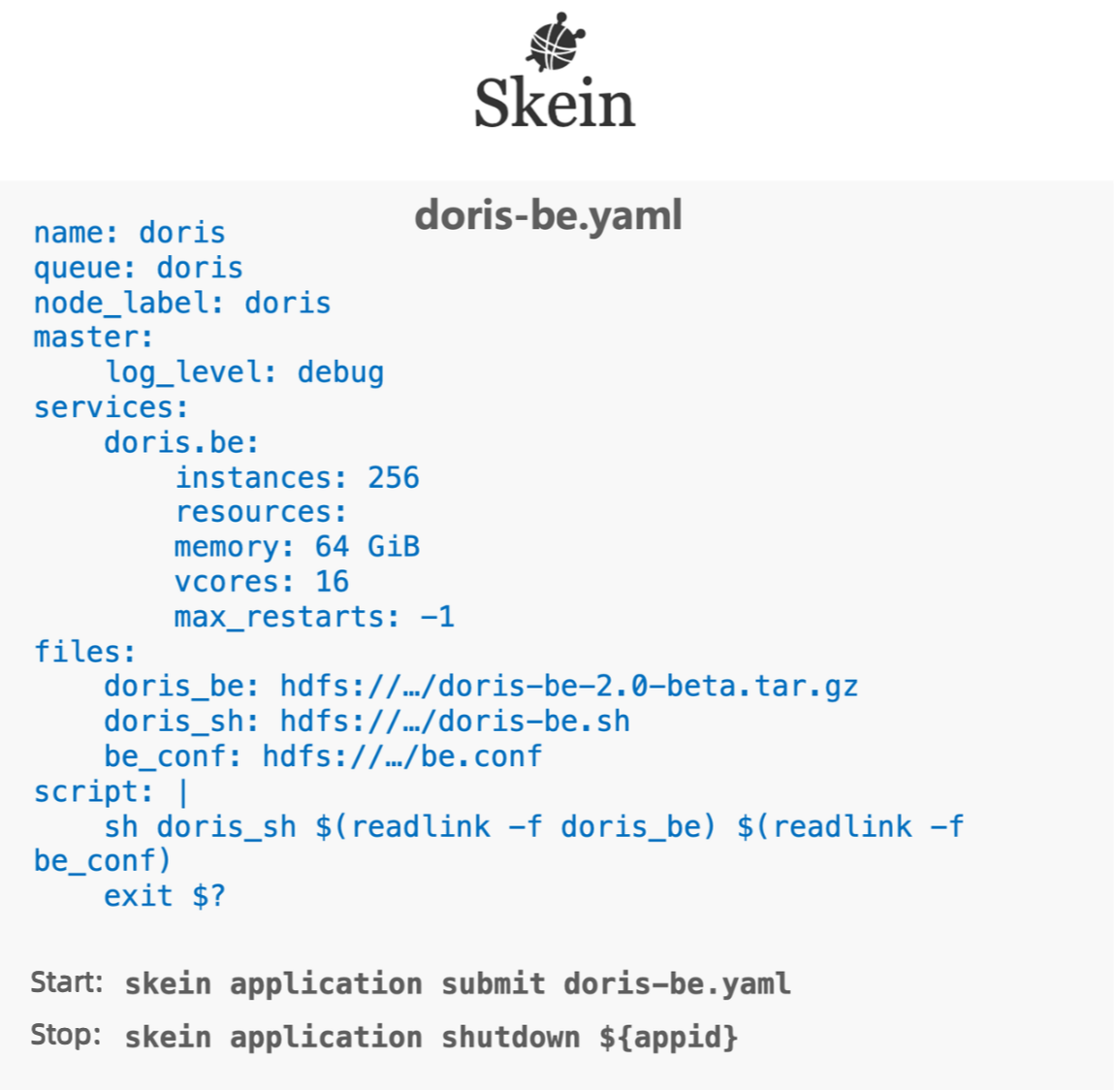
Для упрощения развертывания они также оптимизировали процесс развертывания на Yarn с помощью Skein. Как показано ниже, они определяют количество вычислительных узлов и необходимые ресурсы в файле YAML, а затем упаковывают установочный файл, файл конфигурации и сценарий запуска в распределенную файловую систему. Таким образом, они могут запустить или остановить весь кластер, состоящий из более чем 100 узлов, за считанные минуты, используя одну простую строку кода.
Заключение
Для создания отчетов по данным и маркировки клиентов Apache Doris упрощает этапы приема и объединения данных и обеспечивает высокую производительность запросов благодаря собственному дизайну и функциональности. При анализе озера данных пользователь повышает эффективность использования ресурсов за счет эластичного масштабирования кластеров с помощью вычислительного узла. В ходе работы над Apache Doris они также разработали механизм приоритезации задач приема данных и внесли его в проект Doris. Жест, облегчающий их вариант использования, в конечном итоге приносит пользу всему сообществу разработчиков ПО с открытым исходным кодом. Это отличный пример продуктов с открытым исходным кодом, которые процветают благодаря участию пользователей.
Также опубликовано здесь.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27521)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)