

Создание обертки для Tesseract в несколько раз быстрее, чем PyTesseract
1 ноября 2022 г.В этой статье я хочу поделиться с вами, как создать свою обертку на python, решающую основную проблему движка tesseract — маленькую скорость распознавания нескольких страниц в одном документе.
Основная идея состоит в том, чтобы использовать встроенные функции многопроцессорности Python для разделения документов на отдельные страницы и запускать несколько экземпляров движка tesseract для параллельного распознавания страниц.
Tesseract использует одно ядро для распознавания изображений, в среднем этого будет достаточно, но если у вас «тяжелые» документы, в которых много листов, то это будет очень медленно, т.к. tesseract по умолчанию будет использовать только одно ядро процессора.
Зачем нам нужен тессеракт?
Итак, в некоторых случаях, когда вы не можете скопировать содержимое из pdf-документа (сам pdf имеет разные форматы, один из них — это отсканированный pdf-документ, представляющий собой просто изображение фактического текста), нам нужно программное обеспечение, который будет распознавать текст с изображения.
Эта технология называется OCR (оптическое распознавание символов). Одним из самых популярных и бесплатных программ для оптического распознавания текста является tesseract. Изначально Tesseract был разработан компанией Hewlett-Packard в 2006 году, а затем продан Google. Google сделал tesseract бесплатным и с открытым исходным кодом. Сегодня тессеракт разрабатывается группой энтузиастов бесплатно.
Настройте среду.
Для разработки нашей оболочки Python нам нужна последняя версия Python, в настоящее время это 3.11, ссылка для скачивания: https://www.python.org/downloads/release/python-3110/
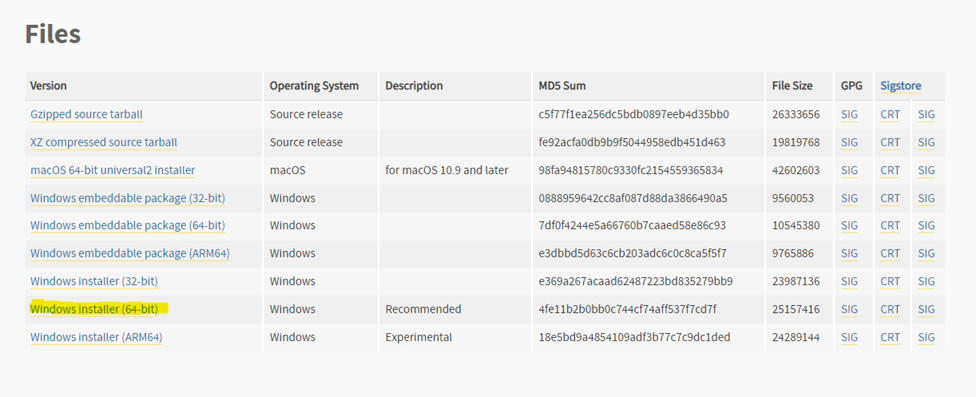
и pipenv (для виртуальной среды). Когда вы закончите загрузку Python, запустите его на своем компьютере. Не забудьте выбрать «Добавить python.exe в PATH», чтобы запустить его из PowerShell или cmd.exe.
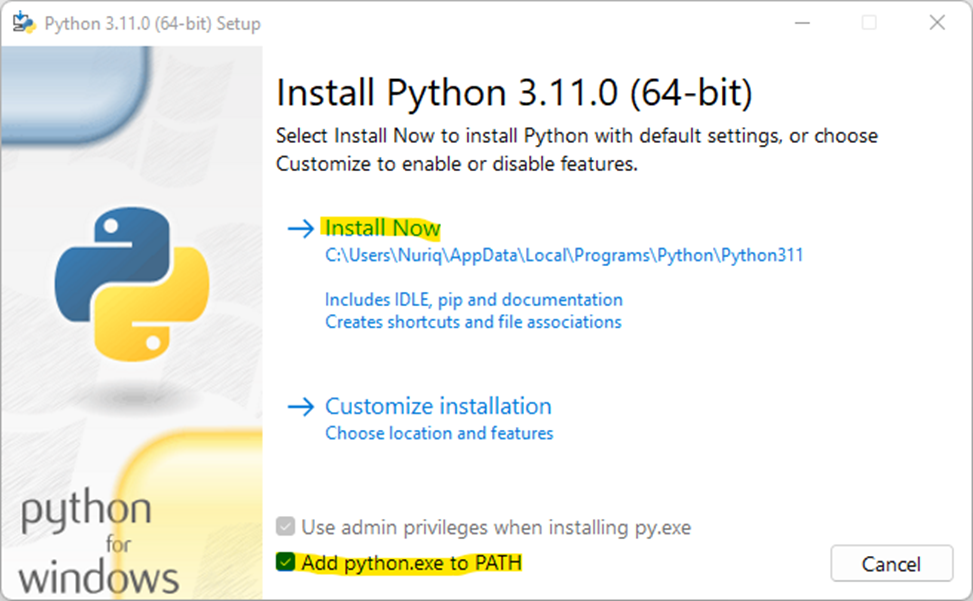
Затем установите pipenv с помощью команды pip install pipenv в cmd.exe. Наконец, вы увидите «Успешно установлено». Также нам необходимо установить pdf2image (pip install pdf2image) и скачать поплер для него.
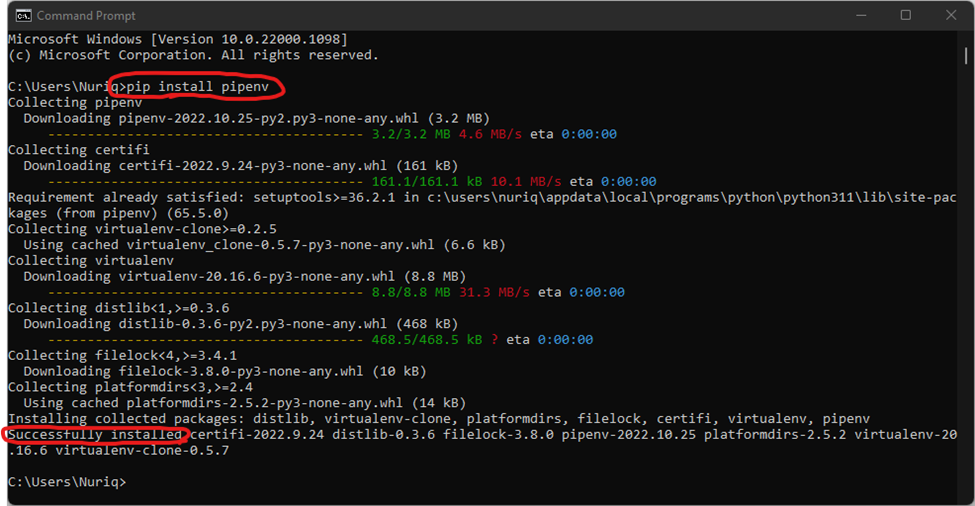
Вы увидите «Успешно созданную виртуальную среду» и полный путь к ней. Запомните полный путь, вы будете использовать его в IDE VS code. Откройте VS Code и выберите интерпретатор Python с помощью комбинации ctrl + shift + p, затем выберите «Python: Select Interpreter».
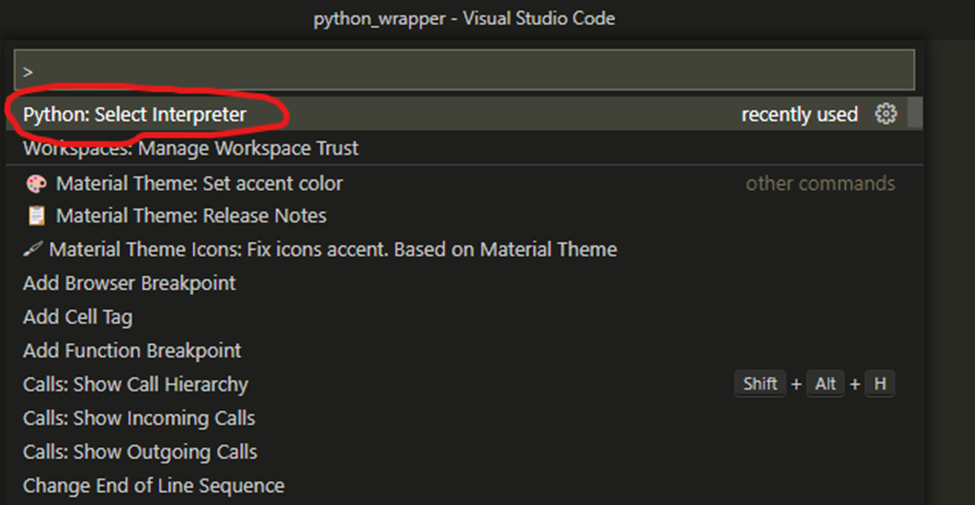
Выберите нашу вновь созданную виртуальную среду из меню.
Далее нам нужно скачать движок tesseract (v5.2.0.20220712) и поместить его в папку нашего проекта ( создайте папку tesseract внутри папки проекта.
После установки мы готовы к работе.
Программирование.
Создайте файл main.py и вставьте этот код.
import tempfile
from pdf2image import convert_from_path
import pytesseract
import time
pytesseract.pytesseract.tesseract_cmd=r'C:/Users/Nuriq/Desktop/python_wrapper/tesseract/tesseract.exe'
def start_ocr(pdf_path, poppler_path):
full_raw_text = ""
with tempfile.TemporaryDirectory() as path:
images_from_path = convert_from_path(
pdf_path=pdf_path,
output_folder=path,
paths_only=True,
fmt="jpeg",
poppler_path=poppler_path,
dpi=250,
grayscale=True
)
for img_path in images_from_path:
full_raw_text += pytesseract.image_to_string(img_path)
return full_raw_text
if __name__ == '__main__':
start_time = time.time()
full_raw_text = start_ocr(
'C:/Users/Nuriq/Desktop/python_wrapper/PublicWaterMassMailing.pdf',
'C:/Users/Nuriq/Desktop/python_wrapper/poppler-0.68.0/bin'
)
print(full_raw_text)
end_time = time.time()
print(f"it took: {end_time-start_time}")
Строка pytesseract.pytesseract.tesseract_cmd — это полный путь к нашему движку tesseract.exe. Мы используем python «TemporaryDirectory» для хранения временных файлов, что работает быстрее, чем их физическое хранение на нашем HDD/SDD. Чтобы начать использовать tesseract, нам нужно преобразовать один pdf-документ в изображения (файлы tiff/jpeg), где 1 страница = 1 изображение.
Сохраните его в верхней папке и запустите full_raw_text += by tesseract.image_to_string(img_path), где img_path — это полный путь к изображению.
Наконец, мы получили 51-секундный результат для обработки всех 32 страниц (pdf2image потребовалось 8 секунд для преобразования pdf в изображения). Затем напишите следующий код.
import tempfile
from pdf2image import convert_from_path
import pytesseract
import os
import time
import concurrent.futures
from concurrent.futures import ProcessPoolExecutor
pytesseract.pytesseract.tesseract_cmd = r'C:/Users/Nuriq/Desktop/python_wrapper/tesseract/tesseract.exe'
def start_ocr(pdf_path, poppler_path):
images_from_path = []
with tempfile.TemporaryDirectory() as path:
images_from_path = convert_from_path(
pdf_path=pdf_path,
output_folder=path,
paths_only=True,
fmt="jpeg",
poppler_path=poppler_path,
dpi=250,
grayscale=True
)
with ProcessPoolExecutor(max_workers=os.cpu_count()) as executor:
tasks = {executor.submit(pytesseract.image_to_string, img_path): img_path for img_path in images_from_path}
for future in concurrent.futures.as_completed(tasks):
page_number = tasks[future]
data = future.result(), page_number[-5]
yield data
def sort_text(text):
return(sorted(text, key = lambda x: x[1]))
def pdf_to_string(pdf_path, poppler_path):
full_raw_text = start_ocr(
pdf_path,
poppler_path
)
full_text = ""
text = sort_text(full_raw_text)
for page_text, _ in text:
full_text += page_text
return full_text
if __name__ == '__main__':
start_time = time.time()
text = pdf_to_string(
'C:/Users/Nuriq/Desktop/python_wrapper/PublicWaterMassMailing.pdf',
'C:/Users/Nuriq/Desktop/python_wrapper/poppler-0.68.0/bin'
)
print(text)
end_time = time.time()
print(f"it took: {end_time-start_time}")
Запустив его, мы получили 7 секунд (на Core i7 12700), что в 7,3 раза быстрее, чем в предыдущем примере кода.
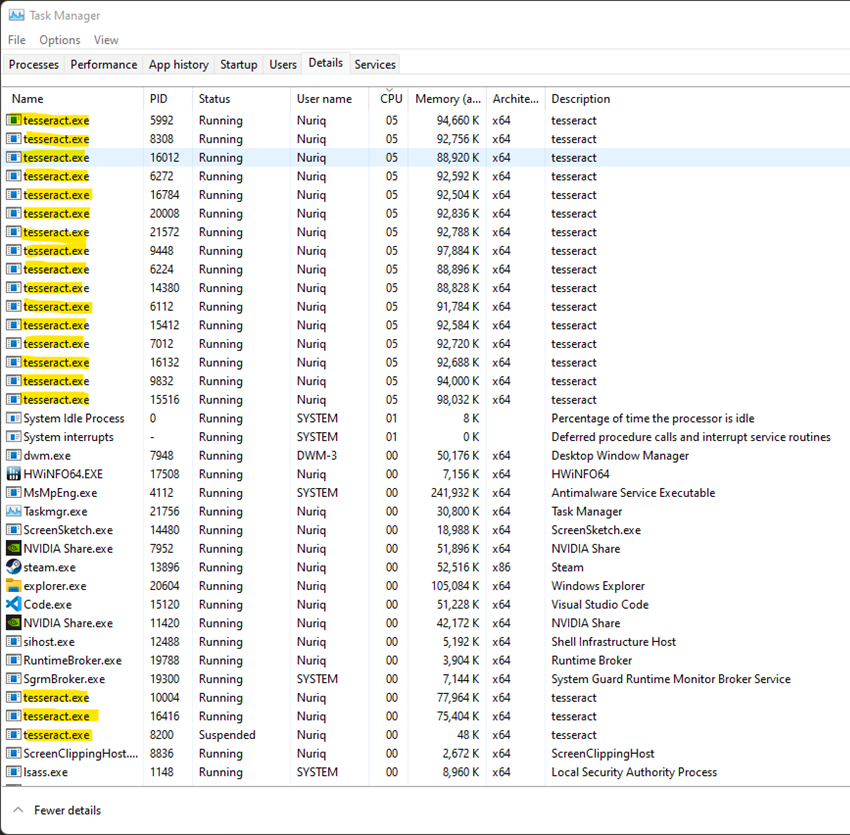
Вывод.
Наконец, используя ProcessPoolExecutor, мы запускаем 19 экземпляров tesseract для каждого файла в списке и выполняем параллельные вычисления. Затем мы сохраняем каждый результат процесса и присваиваем ему номер страницы. Ведь с помощью функции sort_text() мы их сортируем и объединяем в один текст.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27631)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)