

Требование Кодекса обобщения: межмодальное выравнивание соответствует междоменному обучению
25 июня 2025 г.Почему кросс-модальный + кросс-домен = умный AI
В эпоху, когда ИИ должен не просто распознать кошку, но ичитать оэто иобобщатьЭто знание для диких тигров в другом наборе данных, нам нужны две вещи:
- Кросс-модальное выравнивание- Понимание отношений между текстом, изображениями, аудио и т. Д.
- Междоменное обучение-Применение знаний из одного домена (например, изображения продукта) к другому (например, фотографии реального мира).
Давайте разберем это.
Понимание межмодального выравнивания (с кодом)
Цель здесь состоит в том, чтобы внедрить различные типы данных - скажем, изображение и его текстовое подпись - в общее пространство, где их представления напрямую сопоставимы.
Идея
Представьте, что у вас есть:
- Изображение:
xᵛ ∈ V - Текст:
xᵗ ∈ T
Вы хотите изучить две функции:
fᵥ(V) → ℝᵈдля изображенийfₜ(T) → ℝᵈдля текста
... так чтоfᵥ(xᵛ)иfₜ(xᵗ)являютсязакрыватьЕсли они принадлежат друг другу.
Контрастное обучение: рабочая лошадка
Одна мощная функция потерь для этого - этоНедостаток, обычно используется в клипе. Вот формулировка для One Direction (изображение → Текст):
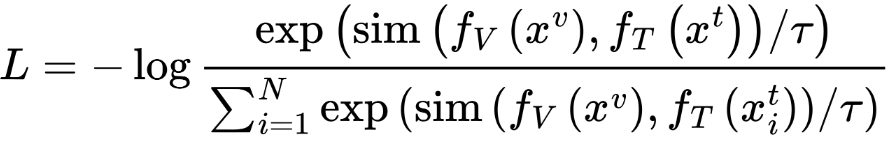
Где:
sim()косинус сходство или точечный продуктτпараметр температуры- Знаменатель включает в себя все текстовые встроения в партию (то есть как положительные, так и негативы)
На практике клип применяет потерю вОба направления, изображение → Текст и текст → Изображение. Вот как это обычно выглядит в Pytorch:
logits_per_image = img_emb @ txt_emb.T / tau
logits_per_text = txt_emb @ img_emb.T / tau
labels = torch.arange(batch_size).to(device)
loss_i2t = F.cross_entropy(logits_per_image, labels)
loss_t2i = F.cross_entropy(logits_per_text, labels)
loss = (loss_i2t + loss_t2i) / 2
Упрощенная модель, вдохновленная клипсом
Вот версия модели клипа размером с укус, которая выравнивает изображения и текст.
import torch
import torch.nn as nn
import torchvision.models as models
from transformers import BertModel
import numpy as np
class MiniCLIP(nn.Module):
def __init__(self, embed_dim=512):
super().__init__()
# Visual encoder (ResNet-based)
base_cnn = models.resnet18(pretrained=True)
self.visual_encoder = nn.Sequential(*list(base_cnn.children())[:-1])
self.visual_fc = nn.Linear(base_cnn.fc.in_features, embed_dim)
# Text encoder (BERT)
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.text_fc = nn.Linear(self.text_encoder.config.hidden_size, embed_dim)
# Learnable temperature
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
def forward(self, images, input_ids, attention_mask):
img_feat = self.visual_encoder(images).squeeze()
img_embed = self.visual_fc(img_feat)
txt_feat = self.text_encoder(input_ids=input_ids, attention_mask=attention_mask).pooler_output
txt_embed = self.text_fc(txt_feat)
# Normalize embeddings
img_embed = img_embed / img_embed.norm(dim=-1, keepdim=True)
txt_embed = txt_embed / txt_embed.norm(dim=-1, keepdim=True)
return img_embed, txt_embed
Поперечное обучение: теория и потеря MMD
Крестное обучение-это все о передаче того, что модель учится в одном домене (источник) другому, возможно, совершенно другому, домену (цель) Это особенно полезно, когда помеченные данные мало в целевой области - с чем борются модели глубокого обучения.
Обучение передачи по сравнению с доменной адаптацией
В то время как передача обучения тонко настразывает предварительно обученную модель от одного домена в другой,Доменная адаптацияПроходит на один шаг вперед: он уменьшает разрыв в распределениях данных между доменами, так что модель, обученная на источнике, может обобщать цель.
Потеря MMD: максимальное среднее расхождение
Одним из популярных способов минимизировать разрыв в распределении являетсяПотеря MMD- Коротко для максимального среднего расхождения. Он измеряет, насколько далеко друг от друга распределения доменов и целевых доменов находятся в высокомерном пространстве признаков.
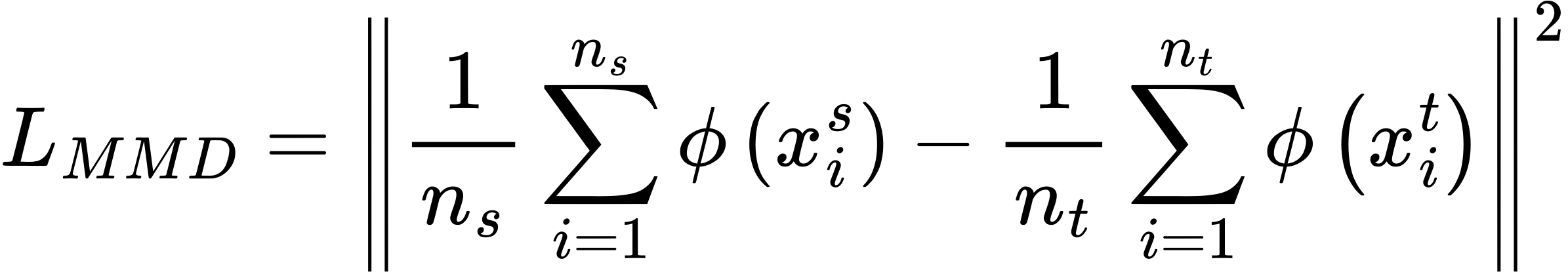
Где:
- ϕ(⋅) отображает данные в пространство воспроизводительного ядра Гилберта (RKHS)
MMD по сути говорит:Если среднее представление данных исходных и целевых данных близко в некотором пространстве близко, модель будет лучше обобщать.
А как насчет разных областей?
Теперь, когда мы заложили теоретическую основу, давайте посмотрим, как кросс-доменное обучение применяется в реальных сценариях.
Поперечное обучение становится особенно ценным, когда распределение данных сдвигается-например, когда модели, обученные высококачественным изображениям студийного продукта, используются на размытых, реальных смартфонах. Несмотря на тренировку в одном домене, мы ожидаем, что модель будет хорошо работать в другом.
Здесь вступает в игру адаптация домена. Вы можете сочетать контрастные методы с доменом-инвариантным обучением функций (например, потеря MMD или состязательное обучение), чтобы гарантировать, что модель обобщается по этим разрывам в распределении.
В следующем разделе представлен один практический подход к этому: доменные нейронные сети (DANN).
Допустим, вы обучили модель на изображениях продуктов Amazon. Может ли он распознать те же продукты, сфотографированные в реальном магазине? Вот гдеМеждоменное обучениевмешивается.
Адаптация домена посредством состязательного обучения
Одно элегантное решение: сделайте свои функцииДомен-инвариантПолем ВходитьДанн—Domain-Edverarial Нейронные сети.
Данн в двух словах
Вы тренируете экстрактор функции, чтобы обмануть классификатор домена. Между тем, ваш предиктор лейбла продолжает делать свое дело.
class DomainClassifier(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(800, 100), # adjust to match flattened features
nn.ReLU(),
nn.Linear(100, 2) # binary: source vs target domain
)
def forward(self, x):
return self.model(x.view(x.size(0), -1))
Чтобы сделать его по -настоящему состязательным, используйте слой разворота градиента (не показан выше), чтобы классификатор домена учился, в то время как экстрактор функции пытается сбить его с толку.
Собрать это вместе: кросс-модальныйиМеждомен
Зачем останавливаться на одном вызове? Некоторые задачи, как многоязычное извлечение изображений в разных странах.
Комбинированная функция потерь
Вот потери выборки, которая объединяет контрастные (выравнивание) и состязательные (адаптация доменной) цели:
def combined_loss(img_emb, txt_emb, domain_logits, domain_labels, λ=0.5):
contrastive = -torch.mean((img_emb * txt_emb).sum(dim=-1)) # dot product loss
domain = nn.CrossEntropyLoss()(domain_logits, domain_labels)
return contrastive + λ * domain
Бесценыец и наборы данных
Задача | Набор данных | Зачем использовать его |
|---|---|---|
Кросс-модальное выравнивание | Коко, Flickr30k | Пары с изображением для поиска задач |
Междоменное обучение | Офис-31, Вишда | Эксперименты по сдвигу доменов (Amazon → Веб-камера и т. Д.) |
Эксперименты показывают, что сочетание обеих стратегий повышает точность поиска и устойчивость классификации, особенно в сценариях с низким даром или на распределении.
Последние мысли
Кросс-модальное выравнивание помогает машиныПодключите точкимежду различными типами данных. Междоменное обучение гарантирует, что ониоставаться точнымКогда контекст меняется.
Вместе они образуют мощную комбинацию для создания обобщаемых систем ИИ. Следующая граница? Добавьте больше модальностей (например, аудио или табличные данные), меньше меток и более жесткие домены.
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)