Когда мы возьмем такие модели генерации изображений, как Stable Diffusion, качество создаваемого изображения просто ошеломляет. Однако вывод в значительной степени контролируется вводом текста, который представляет собой подсказку. Возможности текстового ввода весьма ограничены в управлении выводом.
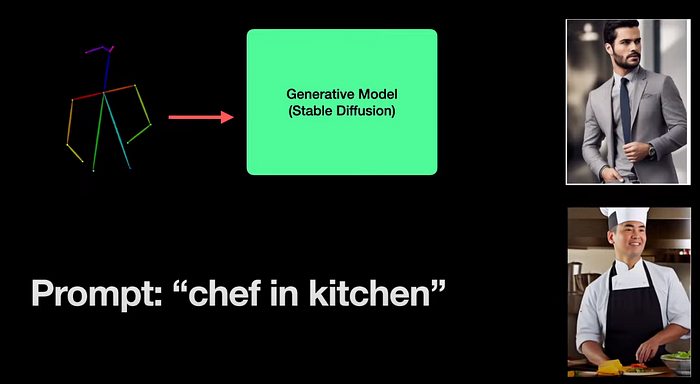
Например, если я хочу сгенерировать изображение мужчины, стоящего в позе выше, я не могу себе представить, сколько слов нам нужно, чтобы определить эту позу. Но если мы сможем передать эту позу непосредственно модели, это значительно облегчит нашу работу. Если мы сможем подать текстовую подсказку («шеф-повар на кухне») вместе с позой, тогда у нас будет еще лучший контроль и мы сможем создать изображение повара, стоящего в той же позе.
Эту проблему точного управления пространственным расположением генерируемых изображений с помощью входных изображений решает ControlNet. Входными данными могут быть эскизы, карты нормалей, карты глубины, края, маски сегментации и позы людей.
Неудивительно, что ControlNet получила престижную премию Марра на конференции ICCV в 2023 году. Влияние на сообщество уже можно почувствовать по более чем 730 цитированиям статьи.
Итак, в этой статье давайте рассмотрим архитектуру управляющей сети, метод нулевой инициализации и качественные результаты, а также некоторые исследования абляции. Итак, без лишних слов, давайте начнем.
Визуальное объяснение
Если вы похожи на меня и хотите получить наглядное анимированное объяснение ControlNet, вы можете посмотреть видео ниже:
https://youtu.be/WgrmCVa35ws?feature=shared&embedable=true
Архитектура ControlNet
Все мы знаем, что нейронные сети состоят из нескольких блоков нейронных сетей. Например, если взять знаменитый ResNet, то в нем есть несколько последовательно расположенных блоков ResNet. Точно так же знаменитые трансформеры имеют последовательность многоглавых блоков внимания.
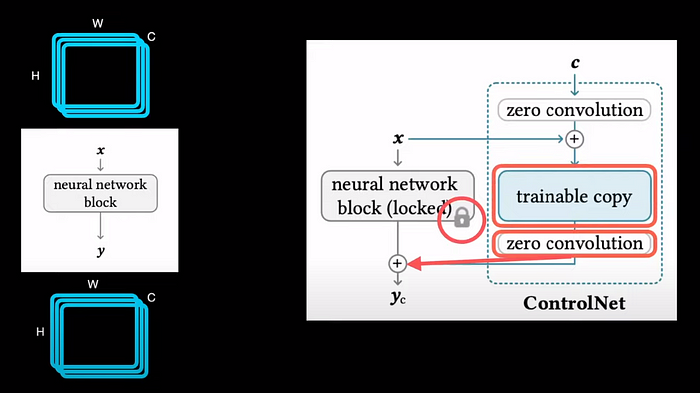
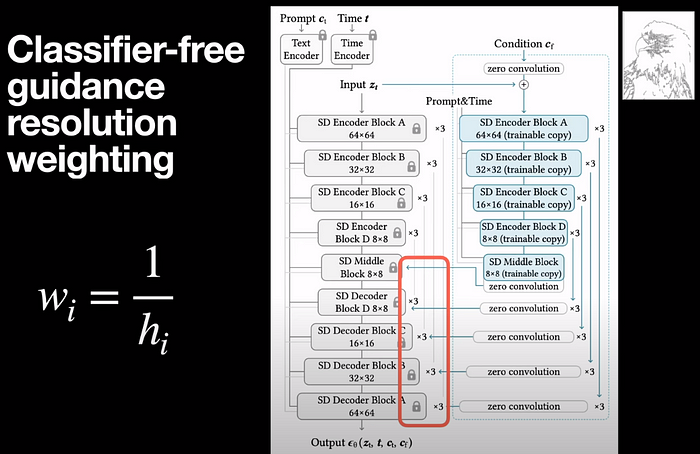
Чтобы понять архитектуру ControlNet, давайте рассмотрим отдельный блок любой нейронной сети из генеративной модели, скажем, Stable Diffusion. Обычно он принимает трехмерный тензор с высотой, шириной и количеством каналов в качестве входных данных и выводит аналогичный размерный тензор. Чтобы добавить ControlNet в этот блок, мы сначала делаем копию весов блока и замораживаем фактические веса. Эта обучаемая копия затем подключается к нулевой свертке, а выходные данные нулевой свертки отправляются обратно в качестве входных данных в замороженный блок. Поэтому всякий раз, когда мы обучаем модель, обновляется именно эта обучаемая копия, но фактическая предварительно обученная генеративная модель остается замороженной.
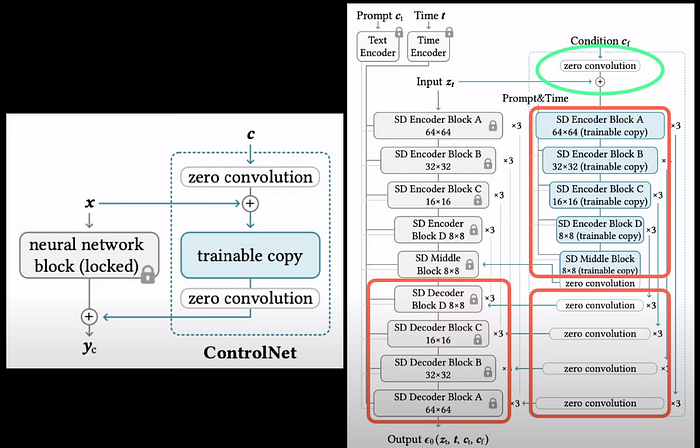
При масштабировании этой идеи до стабильной диффузии, в которой есть уровни кодера и декодера, блоки синего цвета представляют собой обучаемые копии слоев кодера. Выходные данные каждого из этих блоков проходят через нулевые свертки, которые, в свою очередь, подаются в блоки стабильного диффузионного декодера. Еще одно место, где используются нулевые свертки, — это когда мы берем входные условия, такие как карта глубины или поза, и объединяем их с входными данными, представленными как z_t.
Говоря о нулевых свертках, это простые сверточные слои, состоящие один за другим, чьи веса и смещения инициализируются нулевым значением.
Объединение пространства управления и функций
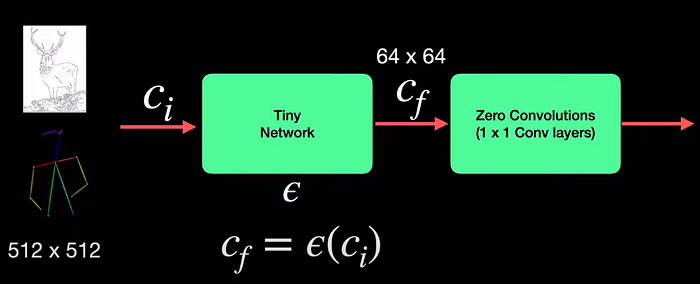
Входные данные кондиционирования, которые представляют собой карты ребер или позы, имеют размер 512 на 512, что оказывается очень высоким размером для этих слоев свертки один за другим. Чтобы преодолеть эту проблему, вводится крошечная нейронная сеть с четырьмя слоями конвекторов, которая преобразует эти изображения из пространства обработки изображений c_i в пространство обработки признаков c_f, тем самым уменьшая размерность до 64 на 64. Это означает, что размерность часть условия достаточно мала, чтобы ее можно было успешно использовать без каких-либо сверток.
Всякий раз, когда в качестве вводных входных данных используются дополнительные текстовые подсказки c_t, они обрабатываются кодировщиками CLIP вместе с позиционным кодированием времени и передаются непосредственно в замороженные веса модели стабильной диффузии.
Процесс обучения
При обучении ControlNet мы хотели бы ввести графические подсказки вместо текстовых, чтобы переключить управление с текстовых на графические подсказки. Итак, мы намеренно заменяем половину текстовых подсказок в обучающих данных пустыми строками. Таким образом, теперь сеть вынуждена изучать семантику кондиционирующих изображений, таких как края, позы или карты глубины.
При таком обучении модели внезапно удается следовать изображению обработки входных данных, обычно за менее чем 10 тысяч шагов оптимизации. Это явление называется «феноменом внезапной конвергенции».
Например, в статье мы можем заметить, что на этапе 6100, хотя на выходе получается яблоко, пространственное расположение яблока сильно отличается от такового при обработке входных краев в тестовом изображении. Но вдруг, после 8 тысяч шагов, мы видим, что пространственная семантика соблюдена до мелочей. И на 12 тысячах шагов соответствие семантике входного изображения становится только лучше.
С помощью этой обученной модели, если мы перейдем к выводу, ControlNet представляет так называемое взвешивание разрешения руководства без классификатора. Теперь это глоток. Итак, давайте разберемся и начнем с рекомендаций классификатора. Затем перейдите к руководству без классификатора и весу разрешения.
Руководство по классификатору

Чтобы понять рекомендации классификатора, давайте немного углубимся в математику и начнем с известной теоремы Байеса. Просто применив журнал к уравнению, мы можем преобразовать умножение в сложение, а деление в вычитание. Итак, модифицированное уравнение становится таким. Наконец, предполагая, что распределение меток p(y) тривиально или если мы принимаем их как должное, мы можем установить его равным нулю. Итак, мы приходим к этому упрощенному уравнению.
Давайте разберем это, чтобы увидеть, что представляет собой каждый из терминов. Самый правый член — это просто распределение входных данных x. Другими словами, это генеративная модель, потому что, если мы просто выберем образец из этого распределения x, мы можем получить результаты, аналогичные результатам x. Средний термин представляет собой дискриминативный классификатор, как он говорит: учитывая входные данные x, дайте мне вероятность класса y. Самый левый термин - это условная генеративная модель, как говорится , имея метку y, дайте мне сгенерированный образец x из дистрибутива.
Короче говоря, просто добавив классификатор в генеративную модель (модель диффузии), мы получаем условный генеративная модель. В этом и заключается суть руководства по классификатору.
Однако одним из недостатков этого классификатора является то, что его необходимо обучать с использованием входных данных шума, поскольку входными данными для модели диффузии является шум. Итак, классификатору необходимо взять выборку шума и классифицировать, к какому классу принадлежит этот шум. Однако решение этой проблемы состоит в том, чтобы полностью избавиться от классификатора и прийти к руководству без классификаторов.
Руководство без классификаторов

Мы избавляемся от классификатора с помощью идеи отсева. Итак, мы обучаем модель условной диффузии, такую как стабильная диффузия, с метками условий y и без них. И мы находим баланс между ними, используя весовой коэффициент, скажем, бета. И мы установили его таким образом, чтобы условие y удалялось примерно в 20 % случаев.
В таких статьях, как GLIDE от OpenAI, эта идея руководства без классификаторов использовалась для создания изображений, подобных этим, для приглашения к вводу: «Витраж с изображением панды, поедающей бамбук».
Руководство без классификаторов. Взвешивание разрешения
Возвращаясь к ControlNet, ControlNet уточняет эту идею до взвешивания разрешения наведения без классификатора. Поскольку ControlNet имеет две сети: модель диффузии и ее обученную копию, ControlNet, всякий раз, когда у нас есть кондиционное изображение, скажем, карта ребер, мы вводим дополнительные веса, которые умножаются при соединении между моделью диффузии и ControlNet, так что выходные данные гораздо более изысканный. Это не веса нейронной сети, а простые числа, умноженные на каждом этапе. Вес обратно пропорционален размеру блоков h_i, к которым мы подключаемся.
Результаты показывают, что при использовании этого взвешивания по разрешению, которое справа показано как «полное без подсказок», мы получаем лучшие результаты по сравнению с результатами, полученными без взвешенных указаний.
Исследования абляции

Что касается исследований абляции, они разделяются на две части и изучают влияние инициализации сети и настроек подсказки ввода. Для инициализации они пробуют стандартную инициализацию весов с помощью гауссовой свертки вместо нулевой. В строке b показаны результаты с инициализацией по Гауссу. И качество изображений хуже, чем при использовании нулевой свертки. Аналогичным образом они обучались с помощью облегченной версии ControlNet (ControlNetLite), заменяя копию весов простыми свертками, чтобы проверить, может ли ControlNet быть облегченной.
Авторы также попытались протестировать сценарии подсказок, такие как отсутствие подсказок, недостаточные подсказки и противоречивые подсказки. И во всех сценариях ControlNet удается генерировать достаточно значимые изображения, а не разрушаться.

Они также изучают размер набора данных, необходимый для обучения ControlNet, и показывают, что, хотя мы можем получить приемлемые результаты, используя всего лишь 1 тысячу изображений, мы видим, что с гораздо большим количеством изображений, скажем, 50 тысячами, результаты выглядят лучше, и они становятся еще лучше с 3 миллионами обучающих выборок.
Наконец, ControlNet не ограничивается только стабильной диффузией, но также может применяться к другим генеративным моделям, таким как космическая диффузия и протоген.
Итак, в заключение, это различные управляющие изображения, которые вы можете предоставить в качестве подсказок для ввода, а также сгенерированные изображения для каждого из них. Он включает в себя эскизы, карты нормалей, карты глубины, края и позу человека.
На этом, я думаю, мы рассмотрели все, что я хотел сказать о controlNet. Надеюсь, это дает достаточно информации о controlNet.
Надеюсь увидеть вас в следующем выпуске. А пока берегите себя…
Также опубликовано здесь.