

Подробный учебник по созданию приложения RAG с использованием LangChain
3 сентября 2024 г.Сегодняшние большие языковые модели имеют доступ к постоянно растущему объему информации. Однако остается огромный кладезь личных данных, к которым эти модели не обращаются. Вот почему одним из самых популярных приложений LLM в корпоративных условиях является генерация дополненного поиска — сокращенно RAG. В
Вы узнаете, как использовать LangChain, чрезвычайно популярный фреймворк для построения систем RAG, чтобы построить простую систему RAG. К концу урока у нас будет чат-бот (с интерфейсом Streamlit и всем остальным), который будет RAG пробираться через некоторые частные данные, чтобы давать ответы на вопросы.
Что такое РАГ?
Чтобы пояснить, что такое RAG, давайте рассмотрим простой пример.
Студент первого курса колледжа Чендлер подумывает пропустить несколько занятий, но хочет убедиться, что не нарушает правила посещения университета. Как и во всем в эти дни, он спрашиваетЧатGPTвопрос.
Конечно, ChatGPT не может ответить на него. Чат-бот не тупой — у него просто нет доступа к университетским документам Чендлера. Поэтому Чендлер сам находит политический документ и обнаруживает, что это длинное техническое чтение, в которое он не хочет вникать. Вместо этого он передает весь документ ChatGPT и снова задает вопрос. На этот раз он получает ответ.
Это частный случай генерации с дополнениями и поиском. Ответ (генерация) языковой модели дополнен (обогащен) контекстом, извлеченным из источника, не являющегося частью ее первоначального обучения.
Масштабируемая версия системы RAG сможет ответить на любой вопрос студента, самостоятельно просматривая университетские документы, находя релевантные из них и извлекая фрагменты текста, которые с наибольшей вероятностью содержат ответ.
В общем случае в системе RAG вы извлекаете информацию из закрытого источника данных и передаете ее в языковую модель, что позволяет модели давать контекстно релевантный ответ.
Компоненты приложения RAG
Такая система, несмотря на то, что звучит просто, будет иметь много движущихся компонентов. Прежде чем строить ее самостоятельно, нам нужно рассмотреть, что это такое и как они взаимодействуют.
Документы
Первый компонент — это документ или набор документов. В зависимости от типа системы RAG, которую мы создаем, документами могут быть текстовые файлы, PDF-файлы, веб-страницы (RAG по неструктурированным данным) или графические, SQL- или NoSQL-базы данных (RAG по структурированным данным). Они используются для загрузки различных типов данных в систему.
Загрузчики документов
LangChainреализует сотни классов, называемыхзагрузчики документовдля чтения данных из различных источников документов, таких как PDF-файлы, Slack, Notion, Google Drive и т. д.
Каждый класс загрузчика документов уникален, но все они имеют одинаковые.load()метод. Например, вот как можно загрузить PDF-документ и веб-страницу в LangChain:
from langchain_community.document_loaders import PyPDFLoader, WebBaseLoader # pip install langchain-community
pdf_loader = PyPDFLoader("framework_docs.pdf")
web_loader = WebBaseLoader(
"https://python.langchain.com/v0.2/docs/concepts/#document-loaders"
)
pdf_docs = pdf_loader.load()
web_docs = web_loader.load()
Класс PyPDFLoader обрабатывает PDF-файлы, используя внутренний пакет PyPDF2, в то время как WebBaseLoader извлекает содержимое указанной веб-страницы.
pdf_docsсодержит четыре объекта документа, по одному на каждую страницу:
>>> len(pdf_docs)
4
Покаweb_docsсодержат только один:
>>> print(web_docs[0].page_content[125:300].strip())
You can view the v0.1 docs here.IntegrationsAPI referenceLatestLegacyMorePeopleContributingCookbooks3rd party tutorialsYouTubearXivv0.2v0.2v0.1🦜️🔗LangSmithLangSmith DocsLangCh
Эти объекты документа впоследствии передаются моделям внедрения для понимания семантического значения их текста.
Для получения подробной информации о других типах загрузчиков документов LangChain предлагает
Разделители текста
После загрузки документов крайне важно разбить их на более мелкие и более управляемые фрагменты текста. Вот основные причины:
- Многие модели встраивания (подробнее о них позже) имеют максимальный лимит токенов.
- Извлечение данных происходит точнее, если у вас есть меньшие фрагменты.
- В языковую модель передается точный контекст.
LangChain предлагает множество типов разделителей текста в своем пакете langchain_text_splitters, и они различаются в зависимости от типа документа.
Вот как использоватьRecursiveCharacterTextSplitterдля разделения обычного текста на основе списка разделителей и размера фрагмента:
!pip install langchain_text_splitters
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Example text
text = """
RAG systems combine the power of large language models with external knowledge sources.
This allows them to provide up-to-date and context-specific information.
The process involves several steps including document loading, text splitting, and embedding.
"""
# Create a text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=50,
chunk_overlap=10,
length_function=len,
separators=["\n\n", "\n", " ", ""],
)
# Split the text
chunks = text_splitter.split_text(text)
# Print the chunks
for i, chunk in enumerate(chunks):
print(f"Chunk {i + 1}: {chunk}")
Выход:
Chunk 1: RAG systems combine the power of large language
Chunk 2: language models with external knowledge sources.
Chunk 3: This allows them to provide up-to-date and
Chunk 4: and context-specific information.
Chunk 5: The process involves several steps including
Chunk 6: including document loading, text splitting, and
Chunk 7: and embedding.
Этот разделитель универсален и хорошо подходит для многих случаев использования. Он создает каждый фрагмент с количеством символов, максимально приближенным кchunk_sizeнасколько это возможно. Он может рекурсивно переключаться между разделителями, по которым нужно разделить текст, чтобы сохранить количество символов.
В приведенном выше примере наш разделитель пытается сначала разделить данные по символам новой строки, затем по одинарным пробелам и, наконец, по любым символам, чтобы достичь желаемого размера фрагмента.
Внутри есть много других разветвителей.langchain_text_splittersпакет. Вот некоторые:
HTMLSectionSplitterPythonCodeTexSplitterRecursiveJsonSplitter
и т. д. Некоторые из разделителей создают семантически значимые фрагменты, используя внутри себя модель трансформатора.
Правильный разделитель текста оказывает существенное влияние на производительность системы RAG.
Подробности использования разделителей текста см. в соответствующем разделе.
Встраивание моделей
После того как документы разделены на текст, их необходимо закодировать в числовое представление, что является обязательным требованием для всех вычислительных моделей, работающих с текстовыми данными.
В контексте RAG это кодирование называетсявстраиваниеи сделановстраивание моделей. Они создают векторное представление фрагмента текста, которое фиксирует его семантическое значение. Представляя текст таким образом, вы можете выполнять с ним математические операции, например, искать в нашей базе данных документов текст, наиболее похожий по значению, или находить ответ на запрос пользователя.
LangChain поддерживает все основные поставщики моделей встраивания, такие как OpenAI, Cohere, HuggingFace и т. д. Они реализованы какEmbeddingклассы и предоставляют два метода: один для встраивания документов и один для встраивания запросов (подсказок).
Вот пример кода, который встраивает фрагменты текста, созданные нами в предыдущем разделе с помощью OpenAI:
from langchain_openai import OpenAIEmbeddings
# Initialize the OpenAI embeddings
embeddings = OpenAIEmbeddings()
# Embed the chunks
embedded_chunks = embeddings.embed_documents(chunks)
# Print the first embedded chunk to see its structure
print(f"Shape of the first embedded chunk: {len(embedded_chunks[0])}")
print(f"First few values of the first embedded chunk: {embedded_chunks[0][:5]}")
Выход:
Shape of the first embedded chunk: 1536
First few values of the first embedded chunk: [-0.020282309502363205, -0.0015041005099192262, 0.004193042870610952, 0.00229285703971982, 0.007068077567964792]
Вышеприведенный вывод показывает, что модель внедрения создает 1536-мерный вектор для всех фрагментов в наших документах.
Чтобы встроить один запрос, вы можете использоватьembed_query()метод:
query = "What is RAG?"
query_embedding = embeddings.embed_query(query)
print(f"Shape of the query embedding: {len(query_embedding)}")
print(f"First few values of the query embedding: {query_embedding[:5]}")
Выход:
Shape of the query embedding: 1536
First few values of the query embedding: [-0.012426204979419708, -0.016619959846138954, 0.007880032062530518, -0.0170428603887558, 0.011404196731746197]
Векторные магазины
В крупномасштабных приложениях RAG, где у вас могут быть гигабайты документов, вы получите газиллион текстовых фрагментов и, следовательно, векторов. Они бесполезны, если вы не можете надежно их хранить.
Вот почемувекторные хранилища или базы данныхсейчас в моде. Помимо хранения ваших вложений, векторные базы данных заботятся о выполнении поиска векторов для вас. Эти базы данных оптимизированы для быстрого поиска наиболее похожих векторов при задании вектора запроса, что необходимо для получения релевантной информации в системах RAG.
Вот фрагмент кода, который встраивает содержимое веб-страницы и сохраняет векторы в базу данных векторов Chroma (Chroma — это решение векторной базы данных с открытым исходным кодом.который полностью работает на вашем компьютере):
!pip install chromadb langchain_chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load the web page
loader = WebBaseLoader("https://python.langchain.com/v0.2/docs/tutorials/rag/")
docs = loader.load()
# Split the documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(docs)
Сначала мы загружаем страницу сWebBaseLoaderи создаем наши куски. Затем мы можем напрямую передавать куски вfrom_documentsметодChromaвместе с выбранной нами моделью встраивания:
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
db = Chroma.from_documents(chunks, OpenAIEmbeddings())
Все векторные объекты базы данных в LangChain предоставляютsimilarity_searchметод, принимающий строку запроса:
query = "What is indexing in the context of RAG?"
docs = db.similarity_search(query)
print(docs[1].page_content)
Выход:
If you are interested for RAG over structured data, check out our tutorial on doing question/answering over SQL data.ConceptsA typical RAG application has two main components:Indexing: a pipeline for ingesting data from a source and indexing it. This usually happens offline.Retrieval and generation: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.The most common full sequence from raw data to answer looks like:IndexingLoad: First we need to load our data. This is done with Document Loaders.Split: Text splitters break large Documents into smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won't fit in a model's finite context window.Store: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a VectorStore and Embeddings model.Retrieval and
Результатsimilarity_searchсписок документов, которые с наибольшей вероятностью содержат информацию, которую мы запрашиваем в запросе.
Подробности использования векторных хранилищ см. в соответствующем разделе.
Ретриверы
Хотя все векторные хранилища поддерживают поиск в форме поиска по сходству, LangChain реализует специальныйRetrieverИнтерфейс, который возвращает документы по неструктурированному запросу. Получателю нужно только возвращать или извлекать документы, а не хранить их.
Вот как можно преобразовать любое векторное хранилище в ретривер в LangChain:
# Convert the vector store to a retriever
chroma_retriever = db.as_retriever()
docs = chroma_retriever.invoke("What is indexing in the context of RAG?")
>>> len(docs)
4
Можно ограничить количество соответствующих документов сверхукс использованиемsearch_kwargs:
chroma_retriever = db.as_retriever(search_kwargs={"k": 1})
docs = chroma_retriever.invoke("What is indexing in the context of RAG?")
>>> len(docs)
1
Вы можете передать другие параметры, связанные с поиском, в search_kwargs. Узнайте больше об использовании ретриверов из
Пошаговый рабочий процесс создания приложения RAG в LangChain
Теперь, когда мы рассмотрели ключевые компоненты системы RAG, мы создадим ее сами. Я проведу вас через пошаговую реализацию чат-бота RAG, разработанного специально для документации кода и учебных пособий. Вы найдете это особенно полезным, когда вам нужна помощь в кодировании ИИ для новых фреймворков или новых функций существующих фреймворков, которые еще не являются частью базы знаний сегодняшних LLM.
0. Создание структуры проекта
Сначала заполните свой рабочий каталог следующей структурой проекта:
rag-chatbot/
├── .gitignore
├── requirements.txt
├── README.md
├── app.py
├── src/
│ ├── __init__.py
│ ├── document_processor.py
│ └── rag_chain.py
└── .streamlit/
└── config.toml
Вот команды:
$ touch .gitignore requirements.txt README.md app.py
$ mkdir src .streamlit
$ touch src/{.env,__init__.py,document_processor.py,rag_chain.py}
$ touch .streamlit/{.env,config.toml}
1. Настройка среды
На этом этапе вы сначала создаете новую среду Conda и активируете ее:
$ conda create -n rag_tutorial python=3.9 -y
$ conda activate rag_tutorial
Далее откройтеrequirements.txtфайл и вставьте следующие зависимости:
langchain==0.2.14
langchain_community==0.2.12
langchain_core==0.2.35
langchain_openai==0.1.22
python-dotenv==1.0.1
streamlit==1.37.1
faiss-cpu
pypdf
и установите их:
$ pip install -r requirements.txt
Также создайте.gitignoreфайл для скрытия файлов из индексации git:
# .gitignore
venv/
__pycache__/
.env
*.pdf
*.png
*.jpg
*.jpeg
*.gif
*.svg
2. Настройка загрузчиков документов
Далее откройтеsrc/document_processor.pyфайл и вставьте следующие фрагменты кода.
Необходимый импорт:
import logging
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.text_splitter import Language
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders.parsers.pdf import (
extract_from_images_with_rapidocr,
)
from langchain.schema import Document
Объяснение импорта:
RecursiveCharacterTextSplitter: Рекурсивно разбивает текст на более мелкие фрагменты.Language: Перечисление для указания языков программирования при разбиении текста.PyPDFLoader: Загружает и извлекает текст из PDF-файлов.extract_from_images_with_rapidocr: Функция OCR для извлечения текста из изображений.Document: Представляет документ с содержимым и метаданными.logging: Обеспечивает функциональность ведения журнала для отладки и получения информации.
Затем функция для обработки PDF-файлов:
def process_pdf(source):
loader = PyPDFLoader(source)
documents = loader.load()
# Filter out scanned pages
unscanned_documents = [doc for doc in documents if doc.page_content.strip() != ""]
scanned_pages = len(documents) - len(unscanned_documents)
if scanned_pages > 0:
logging.info(f"Omitted {scanned_pages} scanned page(s) from the PDF.")
if not unscanned_documents:
raise ValueError(
"All pages in the PDF appear to be scanned. Please use a PDF with text content."
)
return split_documents(unscanned_documents)
Вот как это работает:
- Он загружает PDF-файл с помощью
PyPDFLoader. - Он отфильтровывает отсканированные страницы, удаляя документы с пустым содержимым.
- Регистрируется количество пропущенных отсканированных страниц, если таковые имеются.
- Если просканированы все страницы (т. е. текстового содержимого нет), возникает ошибка ValueError.
- Наконец, оставшиеся неотсканированные документы разбиваются на более мелкие части с помощью функции split_documents.
Функция обрабатывает случаи, когда PDF может содержать смесь текста и отсканированных страниц, гарантируя, что только текстовые страницы будут обработаны в дальнейшем. Это имеет решающее значение для задач анализа текста, где отсканированные страницы без OCR будут непригодны для использования. Мы определимsplit_documentsфункция позже.
Далее пишем функцию для извлечения информации из изображений (скриншотов фрагментов кода и/или веб-страниц):
def process_image(source):
# Extract text from image using OCR
with open(source, "rb") as image_file:
image_bytes = image_file.read()
extracted_text = extract_from_images_with_rapidocr([image_bytes])
documents = [Document(page_content=extracted_text, metadata={"source": source})]
return split_documents(documents)
Эта функция обрабатывает файл изображения, извлекая текст с помощью OCR (оптического распознавания символов). Она считывает файл изображения, преобразует его в байты, а затем использует библиотеку RapidOCR для извлечения текста из изображения. Извлеченный текст затем помещается в объект Document с метаданными, содержащими путь к исходному файлу. Наконец, функция разбивает документ на более мелкие части с помощьюsplit_documentsфункция, которую мы определим далее:
def split_documents(documents):
# Split documents into smaller chunks for processing
text_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=1000, chunk_overlap=200
)
return text_splitter.split_documents(documents)
Функция использует класс RecursiveCharacterTextSplitter с синтаксисом Python для разделения текста на фрагменты по 1000 символов и перекрытия по 200 символов.
Наша последняя функция объединяет функции анализа PDF и изображений в одну:
def process_document(source):
# Determine file type and process accordingly
if source.lower().endswith(".pdf"):
return process_pdf(source)
elif source.lower().endswith((".png", ".jpg", ".jpeg")):
return process_image(source)
else:
raise ValueError(f"Unsupported file type: {source}")
Эта последняя функция будет использоваться пользовательским интерфейсом Streamlit в дальнейшем для создания, внедрения и хранения фрагментов предоставленных документов и передачи их в компонент RAG нашей системы.
3. Настройка RAG
Теперь откройтеsrc/rag_chain.pyфайл и вставьте следующие фрагменты кода.
Сначала импортируем необходимые модули:
import os
from dotenv import load_dotenv
from langchain.prompts import PromptTemplate
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Load the API key from env variables
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
Вот объяснение импорта:
• os: Взаимодействие с операционной системой
•dotenv: Загрузить переменные среды
•langchainкомпоненты:
PromptTemplate: Создание пользовательских подсказокFAISS: Легкое векторное хранилище для документовStrOutputParser: Преобразование объектов сообщений LLM в строковые выходные данныеRunnablePassthrough: Создание составных цепочекChatOpenAI,OpenAIEmbeddings: Взаимодействие моделей OpenAI
Далее мы создаем нашу подсказку для системы RAG:
RAG_PROMPT_TEMPLATE = """
You are a helpful coding assistant that can answer questions about the provided context. The context is usually a PDF document or an image (screenshot) of a code file. Augment your answers with code snippets from the context if necessary.
If you don't know the answer, say you don't know.
Context: {context}
Question: {question}
"""
PROMPT = PromptTemplate.from_template(RAG_PROMPT_TEMPLATE)
Подсказка системы RAG является одним из важнейших факторов ее успеха. Наша версия проста, но в большинстве случаев справится с работой. На практике вы потратите много времени на итерации и улучшения подсказки.
Если вы заметили, мы используемPromptTemplateкласс для построения приглашения. Эта конструкция позволяет нам динамически вставлять контекст, извлеченный из документов и запроса пользователя, в окончательное приглашение.
Говоря о документах, нам нужна функция для их форматирования, прежде чем они будут переданы в качестве контекста в системное приглашение:
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
Это простая функция, которая объединяет содержимое страниц извлеченных документов.
Наконец, мы создаем функцию, которая будет развивать нашу цепочку RAG:
def create_rag_chain(chunks):
embeddings = OpenAIEmbeddings(api_key=api_key)
doc_search = FAISS.from_documents(chunks, embeddings)
retriever = doc_search.as_retriever(
search_type="similarity", search_kwargs={"k": 5}
)
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| PROMPT
| llm
| StrOutputParser()
)
return rag_chain
Функция принимает фрагменты документа, которые будут предоставленыprocess_documentфункция внутриdocument_processor.pyсценарий.
Функция начинается с определения модели встраивания и сохранения документов в хранилище векторов FAISS. Затем она преобразуется в интерфейс извлекателя с поиском по сходству, который возвращает пять лучших документов, соответствующих запросу пользователя.
Для языковой модели мы будем использоватьgpt-4o-miniно вы можете использовать и другие модели, например GPT-4o, в зависимости от вашего бюджета и потребностей.
Затем мы соединим все эти компоненты вместе, используя язык выражений LangChain (LCEL). Первый компонент цепочки — это словарь сcontextиquestionкак ключи. Значения этих ключей предоставляются ретривером, отформатированным нашей функцией форматирования иRunnablePassthrough(), соответственно. Последний класс действует как заполнитель для запроса пользователя.
Затем словарь передается в нашу системную подсказку; подсказка передается в LLM, который генерирует класс выходного сообщения. Класс сообщения передается в парсер строкового вывода, который возвращает ответ в виде простого текста.
4. Создание пользовательского интерфейса Streamlit
В этом разделе мы создадим следующий пользовательский интерфейс для нашего приложения:
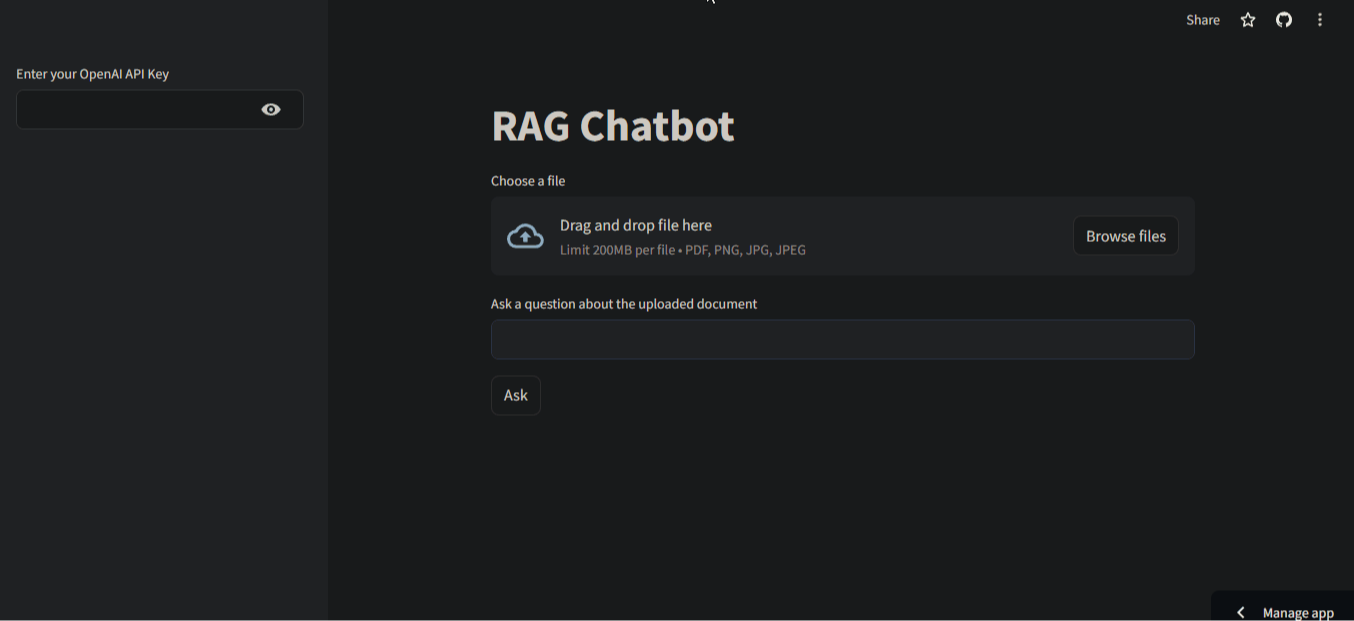
Это чистый, минимальный интерфейс с двумя полями ввода - одно для документа, другое для вопросов о документе. В левой боковой панели пользователю предлагается ввести свой ключ API.
Чтобы построить интерфейс, откройтеapp.pyскрипт на самом верхнем уровне вашего рабочего каталога и вставьте следующий код:
import streamlit as st
import os
from dotenv import load_dotenv
from src.document_processor import process_document
from src.rag_chain import create_rag_chain
# Load environment variables
load_dotenv()
st.set_page_config(page_title="RAG Chatbot", page_icon="🤖")
st.title("RAG Chatbot")
# Initialize session state
if "rag_chain" not in st.session_state:
st.session_state.rag_chain = None
# Sidebar for API key input
with st.sidebar:
api_key = st.text_input("Enter your OpenAI API Key", type="password")
if api_key:
os.environ["OPENAI_API_KEY"] = api_key
# File uploader
uploaded_file = st.file_uploader("Choose a file", type=["pdf", "png", "jpg", "jpeg"])
if uploaded_file is not None:
if st.button("Process File"):
if api_key:
with st.spinner("Processing file..."):
# Save the uploaded file temporarily
with open(uploaded_file.name, "wb") as f:
f.write(uploaded_file.getbuffer())
try:
# Process the document
chunks = process_document(uploaded_file.name)
# Create RAG chain
st.session_state.rag_chain = create_rag_chain(chunks)
st.success("File processed successfully!")
except ValueError as e:
st.error(str(e))
finally:
# Remove the temporary file
os.remove(uploaded_file.name)
else:
st.error("Please provide your OpenAI API key.")
# Query input
query = st.text_input("Ask a question about the uploaded document")
if st.button("Ask"):
if st.session_state.rag_chain and query:
with st.spinner("Generating answer..."):
result = st.session_state.rag_chain.invoke(query)
st.subheader("Answer:")
st.write(result)
elif not st.session_state.rag_chain:
st.error("Please upload and process a file first.")
else:
st.error("Please enter a question.")
Несмотря на то, что он состоит всего из 65 строк, он реализует следующие функции:
- Ввод ключа API: позволяет пользователям безопасно вводить свой ключ API OpenAI.
- Загрузка файлов: поддерживает загрузку файлов PDF, PNG, JPG и JPEG.
- Обработка документов: обрабатывает загруженный файл и создает текстовые фрагменты.
- Создание цепочки RAG: создает цепочку поиска и расширенной генерации с использованием обработанных фрагментов документа.
- Обработка запросов: принимает вопросы пользователей о загруженном документе.
- Генерация ответов: использует цепочку RAG для генерации ответов на основе загруженного документа и запроса пользователя.
- Обработка ошибок: предоставляет соответствующие сообщения об ошибках при отсутствии ключей API, необработанных файлах или пустых запросах.
- Обратная связь с пользователем: отображает счетчики во время обработки и сообщения об успешном выполнении/ошибке для информирования пользователя.
- Управление состоянием: использует состояние сеанса Streamlit для поддержания цепочки RAG при взаимодействиях.
5. Развертывание в качестве чат-бота Streamlit
Остался только один шаг — развернуть наше приложение Streamlit. Здесь есть много вариантов, но самый простой способ — использовать Streamlit Cloud, который бесплатный и простой в настройке.
Сначала откройте.streamlit/config.tomlскрипт и вставьте следующие конфигурации:
[theme]
primaryColor = "#F63366"
backgroundColor = "#FFFFFF"
secondaryBackgroundColor = "#F0F2F6"
textColor = "#262730"
font = "sans serif"
Это некоторые настройки темы, которые исходят из личных предпочтений. Затем напишите файл README.md (вы можете скопировать его содержимое изэтот файл размещен на GitHub).
Наконец, перейдите кGitHub.comи создайте новый репозиторий. Скопируйте его ссылку и вернитесь в свой рабочий каталог:
$ git init
$ git add .
$ git commit -m "Initial commit"
$ git remote add origin https://github.com/YourUsername/YourRepo.git
$ git push --set-upstream origin master
Приведенные выше команды инициализируют Git, создают начальный коммит и отправляют все в репозиторий (не забудьте заменить ссылку на репозиторий на свою собственную).
Теперь вам нужно зарегистрировать бесплатную учетную запись наСтруящееся облако. Подключите свою учетную запись GitHub и выберите репозиторий, содержащий ваше приложение.
Затем настройте параметры приложения:
- Установите версию Python (например, 3.9)
- Установите путь к основному файлу
app.py - Добавьте любые необходимые секреты (например,
OPENAI_API_KEY) в настройках приложения
Наконец, нажмите «Развернуть»!
Приложение должно быть готово к работе в течение нескольких минут. Приложение, которое я создал для этого руководства, можно найти наэта ссылка. Попробуйте!
Заключение
В этом руководстве рассматривается мощное сочетание Retrieval-Augmented Generation (RAG) и Streamlit, которое формирует интерактивную систему вопросов и ответов на основе документов. Оно проводит читателя через весь процесс, от настройки среды и обработки документов до построения цепочки RAG и развертывания дружественного веб-приложения.
Важные моменты включают в себя:
- RAG для более интеллектуальной (в смысле внешнего знания) языковой модели
- Цепочки RAG можно создавать с использованием LangChain, моделей OpenAI и интеграций сторонних сообществ.
- Приложение можно сделать интерактивным с помощью Streamlit и развернуть для публичного использования.
Этот проект формирует основу для более продвинутых приложений. Он может быть значительно расширен, например, путем включения нескольких типов документов, повышения точности поиска и таких функций, как резюмирование документов. И все же, то, что он действительно служит, — это демонстрация потенциальной силы этих технологий, по отдельности и в сочетании.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)