

Сочетание методов шкура с стробированием: как Unipelt обеспечивает надежную настройку LM по задачам
12 августа 2025 г.Авторы:
(1) Юнинг Мао, Университет Иллинойса Урбана-Шампейн и работа была выполнена во время стажировки в Meta AI (yuningm2@illinois.edu);
(2) Ламберт Матиас, Meta AI (mathiasl@fb.com);
(3) Rui Hou, Meta AI (rayhou@fb.com);
(4) Amjad Almahairi, Meta AI (aalmah@fb.com);
(5) Хао Ма, Мета Ай (haom@fb.com);
(6) Цзявей Хан, Университет Иллинойса Урбана-Шампейн (hanj@illinois.edu);
(7) Wen-tau Yih, Meta AI (scottyih@fb.com);
(8) Мадиан Хабса, Meta AI (mkhabsa@fb.com).
Таблица ссылок
Аннотация и 1. Введение
Предварительные
Объединение методов шкура
Эксперименты
4.1 Настройка эксперимента
4.2 Анализ отдельных методов шкура
4.3 Анализ Unipelt
4.4 Эффективность методов шкура
Связанная работа
Заключение, подтверждение и ссылки
Абстрактный
Недавние методы настройки моделей языка (PELT) могут сопоставить производительность тонкой настройки с гораздо меньшим количеством обучаемых параметров и особенно хорошо выполняются, когда обучающие данные ограничены. Тем не менее, различные методы шкура могут работать довольно по-разному в одной и той же задаче, что делает его нетривиальным выбирать наиболее подходящий метод для конкретной задачи, особенно с учетом быстрорастущего числа новых методов и задач. В свете разнообразия моделей и сложности выбора модели мы предлагаем унифицированную структуру Unipelt, которая включает в себя различные методы шкура в качестве подмодулей и учимся активировать те, которые наилучшим образом соответствуют текущим данным или настройке задач с помощью механизма стробирования. На тесте клея Unipelt постоянно достигает 1 ~ 4% прибыли по сравнению с лучшим отдельным методом шкура, который включает и превосходит тонкую настройку в различных настройках. Более того, Unipelt обычно превосходит верхнюю границу, которая берет наилучшие характеристики всех его подмодулей, используемых индивидуально для каждой задачи, что указывает на то, что смесь множественных методов шкура может быть по своей природе более эффективной, чем отдельные методы. [1]
1 Введение
По мере того, как предварительно обученные языковые модели (PLMS) (Devlin et al., 2019) становятся все больше и больше (Brown et al., 2020), становится все более невозможным выполнять обычную точную настройку, где отдельные копии параметров модели модифицируются для единой задачи. Чтобы решить эту проблему, недавно произошел всплеск исследований на настройке моделей языка (PELT), а именно, как эффективно настраивать PLMS с меньшим количеством обучаемых параметров.
Существующие исследования PELT, как правило, направлены на достижение производительности, сравнимого с точной настройкой с
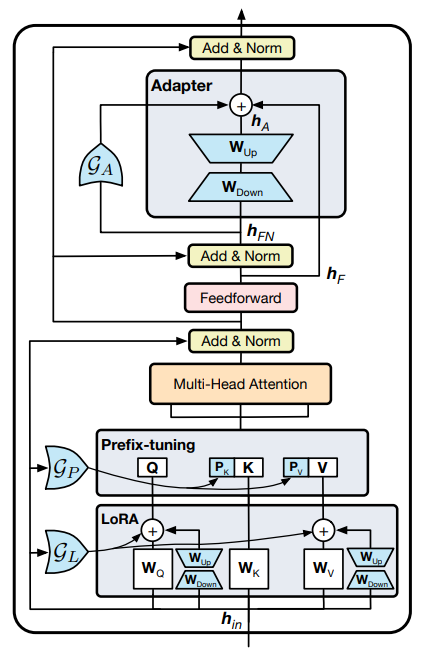
Как можно меньше тренировочных параметров, которые достигли значительного прогресса-специфические для задачи обучаемые параметры, используемые в самых последних подходах (Lester et al., 2021; Guo et al., 2021), почти незначительны по сравнению с общими параметрами PLM (<1%). Более сложная, но менее изученная проблема заключается в том, можно ли добиться лучшей производительности, чем тонкая настройка с меньшим количеством параметров. Недавние исследования (He et al., 2021; Li and Liang, 2021; Karimi Mahabadi et al., 2021b), обнаруживают, что некоторые методы шкура более эффективны, чем точная настройка определенных задач, когда данные обучения ограничены, возможно, из-за уменьшенного риска переосмысления. Однако, как обнаружено в наших экспериментах (Таблица 1), различные методы шкура демонстрируют различные характеристики и работают довольно по-разному по одной и той же задаче, что делает его нетривиальным выбирать наиболее подходящий метод для конкретной задачи, особенно с учетом быстрорастущего числа новых методов и задач (Ding and Hu, 2021).
В свете разнообразных характеристик методов PELT и стоимости выбора лучшего метода мы предлагаем единую структуру шкура, названную Unipelt, которая включает в себя различные методы PELT в качестве подмодулей и учится динамически активировать (комбинацию) подмодулей, которые наилучшим образом соответствуют текущим данным или настройке задач. В результате выбор модели больше не нужен, и постоянная производительность достигается при различных настройках. Активация каждого подмодуля в Unipelt контролируется механизмом стробирования, который учится одобрить (назначать больше веса) подмодули, которые положительно способствуют данной задаче. Кроме того, поскольку количество параметров, введенных каждым подмодулем, как правило, мало, объединение нескольких методов приводит к незначительным потерям в эффективности модели.
Мы выбираем четыре репрезентативных метода PELT для нашего исследования - адаптер (Houlsby et al., 2019), префикстун (Li and Liang, 2021), Lora (Hu et al., 2021) и Bitfit (Ben Zaken et al., 2021), которые в основном охватывают основные категории методов PELT. Мы выполняем два набора анализа, которые тщательно изучают (i) характеристики отдельных методов шкура и (ii) их эффективность при координации Unipelt в различных наборах. [2]
Обширные эксперименты по контрольно -промышленным тесту (Wang et al., 2019), с 32 установками (8 задач × 4 размера данных) и 1000+ прогонов, не только показывают разнообразное поведение методов PELT, но и показывают, что Unipelt более эффективен и надежны, чем использование каждого метода в одиночку в различных задачах и настройках данных. В частности, Unipelt последовательно улучшает лучший подмодуль, который включает в себя на 1 ~ 4 балла и даже превосходит тонкую настройку, достигая наилучшей средней производительности на эталоне клея под различными настройками. Более того, Unipelt обычно превосходит верхнюю границу, которая берет наилучшую производительность из всех его подмодулей, используемых индивидуально для каждой задачи, что говорит о том, что Unipelt поддерживает (почти) оптимальную производительность при различных настройках. Тот факт, что Unipelt превосходит верхнюю границу, также подразумевает, что смесь методов шкура, включающих различные части архитектуры PLM, может быть по своей природе более эффективной, чем отдельные методы.
ВкладПолем (1) Мы проводим всеобъемлющее исследование репрезентативных методов шкура и тщательно изучаем их различия и общие черты с точки зрения эффективности и характеристик. (2) Мы предлагаем унифицированную структуру PELT, которая может включать в себя существующие методы в качестве подмодулей и автоматически учиться активировать соответствующие подмодули для данной задачи. (3) Наша предлагаемая структура достигает лучшей средней производительности, чем производительность, и методы PELT, которые она включает в различные настройки, часто выполняя наилучшие и никогда не худшие на уровне за задание, демонстрируя превосходную эффективность и надежность с незначительными потерями в эффективности модели.
Эта статья есть
[2] BitFit не включен в Unipelt, поскольку обычно он выполняет худшее в наших предварительных экспериментах.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)