
Может ли ваш LLM обработать счету? Я проверил 5 - вот правда
15 июля 2025 г.Модели ИИ отлично подходят в написании стихов, суммировали электронные письма или притворяются философами. Но могут ли они извлечь дату срока из счета? Могут ли они понять сломанный стол с объединенными клетками и полупущенными заголовками?
Это то, что я хотел узнать.
Поэтому я протестировал 5 популярных моделей ИИ-от облачных API до LLM до кровотечения-на двух самых скучных и полезных задачах в реальных бизнес-процессах:
(1) Извлечение поля счетов и (2) структурированное анализа таблицы.
Настройка была простой: 20 реальных счетов и 20 таблиц, взятых из реальных деловых документов. Некоторые были чистыми, большинство не было. Я посмотрел, как каждая модель обрабатывала недостающие данные, непоследовательные макеты, артефакты OCR и вложенные структуры. Затем я измерил четыре вещи:
Точность, скорость, стоимость и стабильность при грязном вводе.
Каждая модель должна была обработать 20 счетов и 20 таблиц, а также возвращать структурированные выходы: итоговые, даты счетов, имена поставщиков, налоговые поля и значения уровня строки.
Входные данные давали в виде простого текста OCR, а не предварительно маркировки или тонко настраиваемых. Единственное, с чем модели должны были работать, это необработанный контент, а также подсказка.
Некоторые модели впечатлили. Другие галлюцинированные общие или игнорируемые заголовки.
Далее следует полевое руководство по поводу того, что на самом деле каждая из этих моделейможетине мочьДелайте - если вы планируете использовать их в производстве, это то, что вам нужно знать.
AWS Textract: Быстрый, стабильный, строго
Производительность: Textract дал надежные результаты при извлечении счета. Он набрал 91,3% без линейных предметов и 91,1% с ними.
Он хорошо справлялся с стандартными полями - складами, номерами счетов, датами - и не галлюцинировал значения или изобретательную структуру. Если вход был ясен, он выполнялся последовательно. Если поле отсутствовало или неоднозначно, оно оставило его пустым, не догадаясь.
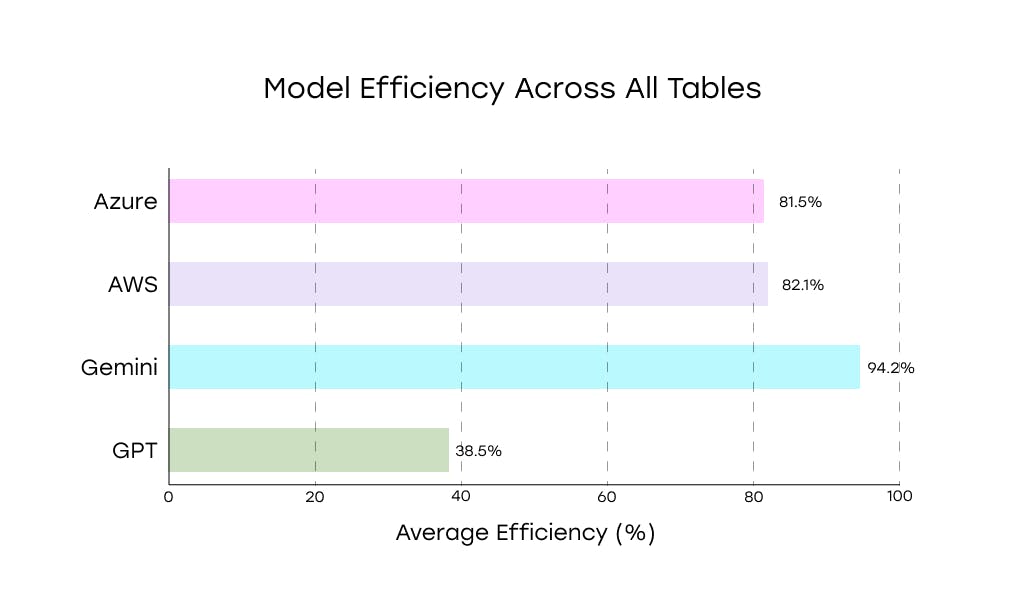
В таблицах Textract достиг 82,1% точности, опередив GPT-4O и слегка вытесняя Azure. Он плавно обрабатывал плоские конструкции и допустил меньше структурных ошибок, чем модели, зависящие от генеративных рассуждений.
Но это боролось с глубоко вложенными заголовками или непоследовательным выравниванием клеток.
Когда форматирование таблицы сломалось, Textract вернул частичные или сплющенные выходы, а не пытается интерпретировать намерения.
Он также обрабатывал сканирование с низким разрешением (200–300 DPI) без падения производительности, сохраняя стабильную точность поля, даже когда документы были немного размыты.
Скорость: Отличный. Среднее время обработки: 2,1 секунды на страницу, что делает ее самой быстрой протестированной моделью с постоянной точностью.
Расходы: Низкий. 10 долларов США за 1000 страниц с использованием конечной точки AnalyzeExpense, как сообщается в эталонном. Прямые цены, нет токенов, нет сюрпризов.
Вердикт: Textract построен для масштаба. Это не креативно, но это именно то, что в этом смысле. Он не выводит структуру и не адаптироваться к хаосу, но не сломается под давлением.
Лучше всего используется в трубопроводах, где контролируется формат документов, и вам нужны предсказуемые результаты на скорости.
Для грязных макетов или нерегулярных таблиц вам нужно будет искать в другом месте, но для хорошо сформированных деловых документов, это один из самых эффективных доступных инструментов.
Интеллект документов Azure: чистый выход, ограниченный нерв
Производительность: Azure обрабатывает счета -фактуры надежно, набрав 85,8% точности без линейных предметов и 85,7% с ними. Он последовательно извлекал базовые поля - число, дата, общая дата, но часто пропускает кромки, такие как имена разделенных поставщиков или менее распространенные этикетки. Это избегало галлюцинаций и редко неправильно меченных данных, но также не очень хорошо оправился от неоднозначности.
Он боролся с описаниями предметов из нескольких слов в таблицах счетов, таких как полные имена сотрудников или длинные линии обслуживания, что вызвало точность в некоторых случаях.
На таблицах он достиг 81,5% точности, сразу за AWS и намного ниже Близнецов.
Он хорошо выполнялся на плоских, обычных макетах, чтении рядов и столбцов без серьезных ошибок. Но он боролся со структурной сложностью - натуральными клетками, сложенными заголовками или непоследовательным выравниванием привело к падающим значениям или неправильно классифицированным столбцам. Это оставалось функциональным, но осторожным.
Скорость: Быстрый. Около 3,5 секунды на страницу в среднем. Немного медленнее, чем AWS, но стабильный и готовый к производству.
Расходы: Приблизительно 10 долларов США на 1000 страниц с использованием предварительно построенной модели счета -фактуры. Исправлена ценообразование через API Azure, настройка не требуется.
Вердикт: Azure выполняет работу, если работа четко определена. Это выбор низкого риска для структурированных счетов и чистых таблиц, но это не та модель, которую вы называете, когда макет становится грязной.
Это надежно, но это не раздвигает границы, и это не будет идти в ногу с моделями, которые делают. Лучше всего используется в потоках документов, где последовательность преодолевает адаптивность.
Google Document AI: Отлично, когда это легко, потеряно, когда это не так
Производительность: На счетах Google показал неровную производительность. Он достиг 83,8% точности без позиций, но упал до 68,1%, когда были включены таблицы
Он обрабатывал стандартные поля, такие как номер счета и дата, но часто неправильно помечали налоговые поля, дублированные итоговые данные или игнорируемые данные на уровне линии. Счета с небольшими сдвигами макета или менее обычными форматами вызывали частые ошибки извлечения.
Столовый анализ был его самой слабой областью. Google набрал 38,5% точности-с GPT-4O для самого низкого результата в эталон.
Он управлял чистыми, похожими на сетку столов, достаточно хорошо, но последовательно провалился в реальных случаях с объединенными заголовками, пустыми рядами или структурными нарушениями. Сотрудники сотовых отношений сломались, этикетки столбцов были потеряны, а конечный результат часто не имел полезной структуры.
Он также возвращал строки в виде неструктурированных строк текста, а не как правильно сегментированные поля. Это сделало количество, цену за единицу и общую добычу ненадежным или невозможным для проверки.
Скорость: Умеренный. Около 5,1 секунды на страницу, медленнее, чем Azure и AWS, но не резко.
Расходы: Примерно 10–12 долл. США на 1000 страниц, в зависимости от конфигурации и региона. Цены основаны на API и предсказуемо, но сложнее оправдать на текущих уровнях точности.
Вердикт:Google Document AI работает, когда документы являются чистыми, предсказуемыми и плотно структурированными.
Сложность макета увеличивается, точность сильно падает. Он не подходит для критических задач экстракции, включающих динамические форматы или слоистые таблицы.
Лучше всего используется в контролируемых внутренних рабочих процессах, где входная изменчивость минимальна, а ожидания - скромные.
GPT-4O: умный, точный, чувствительный к вводу
Производительность: GPT-4O хорошо обрабатывает счетов. Он достиг 90,8% точности без элементов линии и 86,5% с ними с использованием ввода на основе OCR.
При работе с изображениями документов баллы оставались последовательными: 88,3% и 89,2% соответственно. Он правильно определил итоги, даты, номера счетов и имена поставщиков.
Это также было хорошо при выборе правильного значения, когда на странице появилось несколько подобных.
Он обрабатывал документы с низким разрешением без значительной потери в точности. Тем не менее, иногда это неправильно прочитала пунктуацию - опускание запятых или неверных десятичных очков в числовых полях.
Но анализация таблицы была другой историей. GPT-4O набрал только 38,5% точность-самый низкий результат среди всех моделей в эталон.
В то время как он следовал основной структуре в простых случаях, он сломался на объединенных заголовках, вложенных рядах и неполных макетах.
Отношения столбцов часто были неправильно прочитаны, а значения ячейки неуместны или полностью отброшены. Это выглядело как текстовая модель, пытающаяся раскрыть свою визуальную проблему - и отсутствует ключевые сигналы.
Скорость: Около 17–20 секунд на страницу с вводом текста OCR.
При вводе изображения задержка резко увеличивается - часто 30 секунд или более, в зависимости от размера быстрого размера и системной нагрузки.
Расходы: Умеренный. Приблизительно 5–6 долл. США на 1000 страниц с использованием GPT-4-Turbo (текстовый ввод).
Ввод на основе изображения через API Vision может удвоить его, в зависимости от длины быстрого и использования токенов.
Вердикт:GPT-4O хорошо работает на счетах и понимает структурированный текст с нюансом и гибкостью. Но на визуально сложных таблицах он изо всех сил пытается поддерживать структуру или производить постоянные выходы.
Если вы работаете с документами, где макет имеет значение - и точность не может опуститься ниже 40% - вам нужно будет искать в другом месте.
Используйте его, когда вы управляете входным форматом или определяйте приоритет интеллекта уровня счета-фактуры над макетом документа.
Близнецы 1.5 Pro: тихо доминируют
Производительность: Близнецы обрабатывали анализ счетов с устойчивой точностью. Он набрал 90,0% точности без линейных предметов и 90,2% с ними.
Он последовательно вытащил итоги, даты, номера счетов и имена поставщиков - даже когда формат смещался или поля не были аккуратно помечены. Ошибки были незначительными: дубликаты значений, неправильные налоговые поля, случайный дополнительный символ. Но критические данные редко пропали без вести.
На таблицах Близнецы превзошли все остальные модели. Он достиг 94,2% точности, возглавляя эталон.
AWS и Azure следовали на 82,1%и 81,5%, в то время как GPT-4O отставали на 38,5%. Близнецы проанализировали многоуровневые заголовки, объединенные ячейки и неровные структуры ряда с меньшим количеством ошибок и лучшим структурным пониманием. Он делал случайные ошибки выравнивания, но сохранял использование данных.
Скорость: Постоянно быстро. 3–4 секунды на страницу в среднем. Быстрее, чем GPT-4O, немного позади AWS, без непредсказуемых замедлений.
Расходы: Предполагается 4–5 долларов США на 1000 страниц с использованием API Gemini в экспериментальном режиме только в текстовом режиме. Ввод изображения не был проверен в этом эталонном эталоне.
Вердикт: Gemini обеспечивает высокую точность как счетов, так и в таблицах без необходимости ввода зрения или сложной настройки. Это быстро, структурно осведомлен и более устойчива к причудам, чем любая другая протестированная модель.
Лучше всего использовать, когда вы хотите получить результаты производственного уровня от непоследовательных документов и могут управлять входным форматом.
Надежный под давлением - без драмы, просто вывод.
Результаты
Пять моделей. Те же задачи. Те же документы. Очень разные результаты.
- Близнецыбыл лучшим универсальным-быстрым, точным и острым на структуре.
- GPT-4OПрибитые счета, задохнутые на столах.
- AWS TextractБыл быстрым, жестким, и трудно сломать.
- ЛазурПолучил основы правильно, но ничего более.
- Googleборолся со всем, что не было чистым и помеченным.
Ни одна модель не справлялась с всем. Несколько обработанных достаточно. Если вы строите с ИИ, сначала протестируйте - или планируйте почистить позже.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)