

Может ли меньший ИИ превзойти гигантов?
15 июня 2025 г.Авторы:
(1) Хьюго Лоренсон, обнимающееся лицо и Sorbonne Université, (порядок был выбран случайным образом);
(2) Léo Tronchon, обнимающее лицо (порядок был выбран случайным образом);
(3) шнур Matthieu, Sorbonne Université;
(4) Виктор Сан, обнимающееся лицо.
Таблица ссылок
Аннотация и 1 введение
2 терминология
3 Изучение пространства дизайна моделей на языке зрения и 3.1. Все ли предварительно обученные основы эквивалентны VLMS?
3.2 Как полностью ауторегрессивная архитектура сравнивается с архитектурой перекрестного активации?
3.3 Где повышение эффективности?
3.4 Как можно вычислить торговлю на производительность?
4 IDEFICS2-открытая современная модель Фонда зрения и 4.1 многоэтапное предварительное обучение
4.2 Инструкция тонкая настройка и 4.3 оптимизация для сценариев чата
5 Заключение, подтверждение и ссылки
Приложение
A.1 Дальнейшие экспериментальные детали абляций
A.2 Детали инструкции тонкая настройка
A.3 Детали оценок
A.4 Красная команда
Абстрактный
Растущий интерес к моделям на языке зрения (VLMS) был обусловлен улучшением в крупных языковых моделях и трансформаторах зрения. Несмотря на обилие литературы по этому вопросу, мы отмечаем, что критические решения, касающиеся дизайна VLM, часто не оправданы. Мы утверждаем, что эти неподдерживаемые решения препятствуют прогрессу в этой области, затрудняя определение того, какие варианты улучшают производительность модели. Чтобы решить эту проблему, мы проводим обширные эксперименты вокруг предварительно обученных моделей, выбора архитектуры, данных и методов обучения. Наша консолидация результатов включает в себя разработку IDEFICS2, эффективного основополагающего VLM из 8 миллиардов параметров. IDEFICS2 достигает современной производительности в рамках своей категории по различным мультимодальным критериям и часто находится на одном уровне с моделями в четыре раза его размера. Мы выпускаем модель (база, инструкции и чат) вместе с наборами данных, созданными для его обучения.
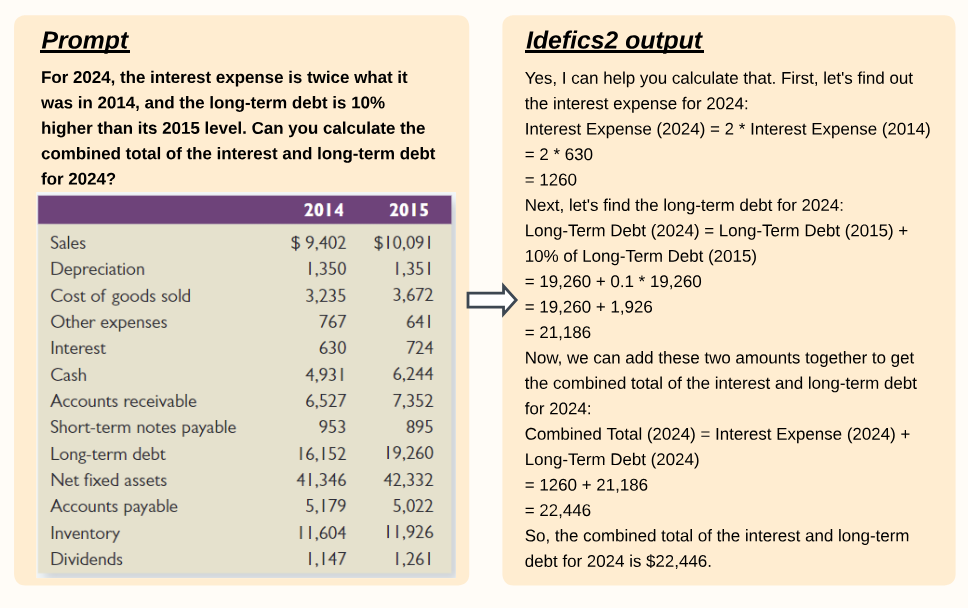
1 Введение
Модели на языке зрения (VLM), которые принимают изображения и тексты в качестве входных данных и выходных текстов, полезны для многих задач, таких как получение информации в сканируемом PDF (Hu et al., 2024), объяснение диаграмм или диаграмм (Carbune et al., 2024), транскрибирование текста в изображении (Blecher et al., 2023), Counts et ortys et ortting et ortting et ortting et ortting et ortting et ortting et al. 2017) или переворачивание скриншотов веб -страниц в код (Laurençon et al., 2024). Разработка мощных открытых крупных языковых моделей (Touvron et al., 2023; Jiang et al., 2023; Google, 2024b) и Emage Encoders (Zhai et al., 2023; Sun et al., 2023; Radford et al., 2021) позволяет исследователям создавать эти немодальные модели, создавая эти задачи, которые решают эти проблемы, которые решают, что они могут создавать, которые решают, что они могут создавать. 2023; Несмотря на прогресс в этой области, литература раскрывает много разрозненных вариантов дизайна, которые часто не являются оправданными экспериментально или очень кратко.
Эта ситуация затрудняет различие, какие решения действительно объясняют производительность модели, тем самым затрудняя для сообщества значительный и обоснованный прогресс. Например, (Alayrac et al., 2022; Laurençon et al., 2023) используют перекрестные преобразователи, чтобы объединить информацию о изображении в языковую модель, в то время как (Li et al., 2023; Liu et al., 2023), конкатенат последовательность скрытых состояний изображения с последовательности с последовательными по вставки и кормления концентратированных последовательных последователей. Насколько нам известно, этот выбор не был должным образом удален, и компромиссы с точки зрения вычисления, эффективность и эффективность данных плохо изучены. В этой работе мы стремимся принести экспериментальную ясность к некоторым из этих основных вариантов дизайна и задать вопрос:Что имеет значение при создании моделей на языке зрения?
Мы идентифицируем две области, в которых различные работы используют различные варианты дизайна: (а) модельная архитектура, и, в частности, модули соединительных соединений, которые объединяют модальности зрения и текста, и их влияние на эффективность вывода, (б) мультимодальная процедура обучения и ее влияние на стабильность обучения. Для каждой из этих областей мы строго сравниваем различные варианты дизайна в контролируемой среде и извлекаем экспериментальные результаты. Примечательно, что мы обнаруживаем, что (а) прогресс моделей на языке зрения в значительной степени обусловлено прогрессом предварительно обученных унимодальных магистралей, (б) более поздняя полностью авторегрессивная архитектура превзойдет архитектуру межоттравления, хотя она требует модификаций для процедуры оптимизации, чтобы обеспечить стабильную тренировку, (в) адаптация для преодоления подготовки к модульности и модуляции. С одной стороны, и обработка изображений в их исходном соотношении и размере, не нанося ущерба производительности вниз по течению с другой стороны, и (d) модификации для обработки изображений позволяют торговать стоимостью вывода для производительности.
Наши результаты дополняются с таковыми, представленными в (Karamcheti et al., 2024; McKinzie et al., 2024; Lin et al., 2024), которые получают представление о многоэтапной тренировке, избирательном разведении предварительно обученных магистралей, повторения данных и влияния тренировочной смеси на Zero и Mene Shot. Мы специально углубимся в неисследованные аспекты, такие как модельная архитектура, методы обучения, стабильность и повышение эффективности при выводе.
Изучая эти идеи, мы обучаем IDEFICS2, основополагающего VLM с 8 миллиардами параметров. IDEFICS2 достигает современной производительности в своей категории размеров по различным критериям, одновременно более эффективным при выводе, как для базы, так и для точно настроенной версии. Он находится на одном уровне с современными моделями в 4 раза больше на некоторых эталонах языка, и соответствует производительности Gemini 1.5 Pro на некоторых сложных эталонах. Мы выпускаем базу, инструкция и версии IDEFICS2 [1] [1] в качестве ресурсов для сообщества VLM, а также данные, созданные для обучения модели.
Эта статья есть
[1] https://huggingface.co/collections/huggingfacem4/idefics2-661d1971b7c50831dd3ce0fe
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)