

Строительство «Строителя» — путь от обязательства к производству за 13 секунд
10 марта 2023 г.Этот пост посвящен тому, почему и как мы создали The Builder: с какими проблемами мы столкнулись и как создать современную, надежную и быструю систему непрерывной интеграции и развертывания.
Чтобы дать вам небольшое представление, вот обзор нашей окончательной архитектуры Builder с описанием различных компонентов, таких как Firecracker, fly.io Machines, Podman и Temporal.io, а также их взаимодействия.
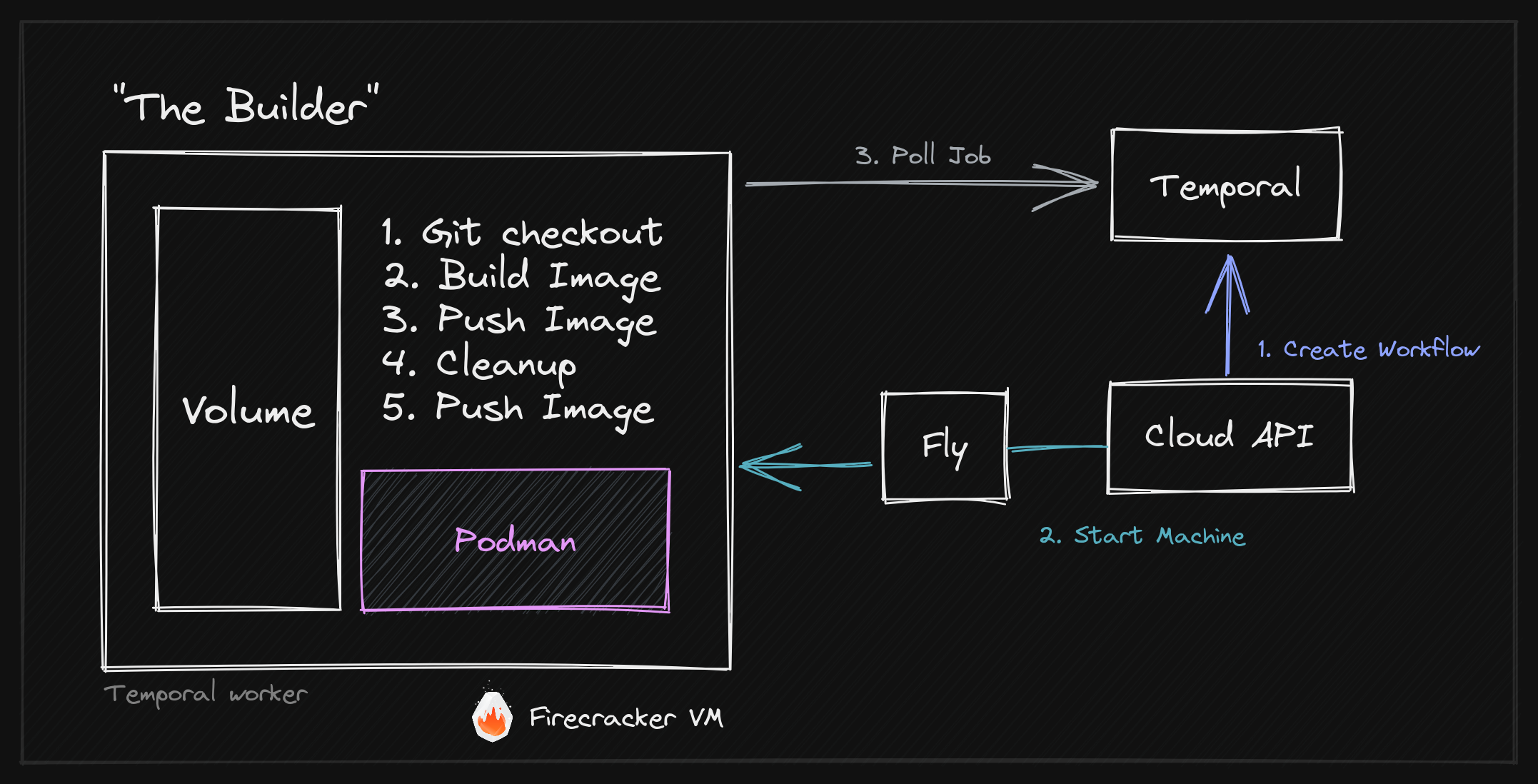
Пользователи могут подключить свой проект GitHub к WunderGraph Cloud. После фиксации Builder создаст новый образ Docker и развернет его по всему миру за 13 секунд.
Строитель стоит на плечах гигантов. Мы используем Podman для безрутовых сборок Docker, fly.io для виртуальных машин Firecracker (Fly Machines) и Temporal.io для надежной координации процесса сборки.
Как я узнал от Саймона Синека, важно начать с «Почему», прежде чем углубляться в детали. По этой причине я хотел бы объяснить, почему «Строитель» не просто меняет правила игры для управления API и интеграции API (наша цель), но и в более общем смысле, как этот шаблон изменит способ создания мультиарендных продуктов SaaS. .
Почему мы создали «Строителя»
До создания WunderGraph я несколько лет работал в компании, занимающейся управлением API с полным жизненным циклом. Работая там, я столкнулся с проблемами создания мультитенантных приложений.
n «Старый» подход заключался в создании и запуске одного большого монолитного кластера шлюза API, который обслуживал бы все проекты, и это именно то, что сегодня делает большинство наших конкурентов в области управления API. Когда у компании достаточно ресурсов, она может построить отдельный промежуточный и производственный кластер. Но это дорого в эксплуатации и обслуживании, поэтому очень немногие компании делают это.
При подключении нового проекта или API к системе вы обычно используете вызовы API для настройки шлюза API. Это означает, что API Gateway имеет своего рода серверную часть с базой данных для сохранения конфигурации каждого проекта, маршрутов, политик безопасности и т. д. Эти серверные части обычно называются «Плоскость управления» или «Панель мониторинга».
Преимущество этого подхода заключается в том, что вы можете «развернуть» изменение конфигурации шлюза API за считанные секунды. Поддерживать синхронизацию кластера шлюзов API сложно, но возможно.
Тем не менее, мы поняли, что у этого подхода много недостатков:
* Нет готовых версий конфигурации шлюза API. * Нет готового способа аудита изменений * Кластер шлюза является многопользовательским, что приводит к: * «Шумные» API, которые крадут ресурсы из других проектов. * Нет изоляции между проектами * Нет изоляции между средами (постановка, производство и т. д.) * Нет изоляции между командами * Нет изоляции между клиентами * Нет изоляции между версиями API
Что, если бы мы могли создавать легкие шлюзы API, предназначенные для одного проекта, полностью изолированные от других проектов, безопасные и индивидуально масштабируемые?
Это именно то, что мы делаем с WunderGraph Cloud. Мы развертываем облегченные шлюзы API по всему миру с помощью машин fly.io. Мы уже говорили об архитектуре.
Одна из особенностей этого подхода заключается в том, что вам необходимо создать и развернуть новый шлюз API за считанные секунды, чтобы обеспечить удобство работы пользователей. Вот где в игру вступает «Строитель».
Преимущества изолированных шлюзов Micro API перед монолитными кластерами шлюзов API
Помимо изоляции, безопасности и масштабируемости, этот подход дает дополнительные преимущества.
- Неизменяемые развертывания
Каждое развертывание является неизменным. Это означает, что вы не можете изменить работающее развертывание. Это здорово, потому что позволяет откатиться к предыдущей версии в случае ошибки. Это также позволяет вам запускать несколько версий шлюза API параллельно.
- Среда предварительного просмотра, подобная рабочей
Благодаря этой архитектуре мы можем легко предоставлять полностью изолированные среды предварительного просмотра для каждого запроса на вытягивание. Это прекрасно сочетается с подходом GitOps, где вы можете использовать среду предварительного просмотра для проверки своих изменений перед их слиянием с основной веткой. Самое главное, что Previews — это рабочие среды с такой архитектурой.
Синие/зеленые развертывания и канареечные выпуски стали проще
В дополнение к средам предварительного просмотра мы также можем легко внедрить Blue/Green Deployments и Canary Releases.
Возможны следующие рабочие процессы:
- Развертывание новой среды предварительного просмотра для каждого запроса на вытягивание
- Отправлять небольшой процент теневого трафика в среду предварительного просмотра.
- Измеряйте производительность среды предварительного просмотра.
- Если все в порядке, направьте небольшой процент рабочего трафика на новую версию.
- Постепенно увеличивайте трафик
- В конце концов закройте старую версию
Резюме. Почему изолированные микроразвертывания и быстрые сборки меняют правила игры для мультитенантных SaaS и Open Source (OSS)
Итак, изолированные микроразвертывания для каждого арендатора и быстрые сборки меняют правила игры для мультитенантных продуктов SaaS. Вместо создания монолитных мультитенантных приложений вы можете создавать облегченные микросервисы, предназначенные для одного арендатора.
Еще одним заметным преимуществом этой архитектуры является возможность создать вокруг WunderGraph отличное сообщество разработчиков ПО с открытым исходным кодом. Нам не нужно встраивать многопользовательские функции в ядро продукта. Нам не нужно каким-либо образом ограничивать продукт или создавать несколько редакций. Основной продукт является однопользовательским, с лицензией Apache 2.0 и простым в использовании. Вы можете использовать WunderGraph Cloud или самостоятельно развернуть его на любом хосте Docker.
Как мы создали The Builder: развертывание образов Docker за 13 секунд
Отказ от ответственности: у меня (Йенса) были некоторые идеи о том, как должен работать "Строитель", но реализация была выполнена Дастином (кодовое имя: Машина), одним из моих соучредителей. Это невероятное произведение инженерной мысли, и я очень горжусь тем, что мы создали.
Исследовать
Все началось с нескольких простых вопросов:
- Можем ли мы сделать создание образов Docker достаточно быстрым?
- Можем ли мы сделать его надежным?
- Можем ли мы сделать это рентабельным?
Нашей первоначальной целью в отношении "достаточно быстрого" было развертывание изменения менее чем за 30 секунд. «Надежность» означает, что мы должны иметь возможность восстанавливаться после сбоев, перезапускать сборки, повторять попытки неудачных сборок и т. д. Мы также поставили перед собой цель предложить пользователям бесплатный уровень, поэтому наше решение должно было быть рентабельным. также.
Самое главное, нам нужно было решение, которое мы могли бы легко «подписать» и предложить нашим пользователям. Это не должно выглядеть как сторонний сервис, а скорее первоклассная функция WunderGraph Cloud. Например, мы могли бы каким-то образом обернуть GitHub Actions, но это было бы неправильно.
В процессе мы оценили AWS Build, Google Build и несколько других решений. Однако эти варианты, казалось, имели одни и те же общие недостатки: они были не только медленными, но и чрезвычайно дорогими; и уровень производительности, которого мы добивались, был просто невозможен.
<цитата>Архитектура CI/CD как услуги принципиально нарушена, что делает ее медленной, сложной в настройке и дорогостоящей.
Мы пришли к выводу, что CI/CD как услуга в корне неверна, что делает ее излишне медленной и дорогой. По сравнению с нашим окончательным решением состояние отрасли невероятно.
Кроме того, мы также поняли, что наши требования очень специфичны и очень нишевые. Большинство решений CI/CD ориентированы на компании, которые создают и развертывают свои собственные приложения. Нам нужно было решение CI/CD, которое мы могли бы пометить и предложить нашим пользователям.
Пользователи не должны связывать свою учетную запись GitHub с «Google Cloud Build», а скорее с «WunderGraph Cloud»”
Что замедляет работу CI/CD?
Еще один вопрос, который мы задали себе, заключался в том, что на самом деле делает службы CI/CD такими медленными. Если вы хотите создать проект локально, вам необходимо выполнить следующие шаги:
- Клонировать репозиторий
- Установите зависимости
- Создать проект
- Запустите тесты
- Создайте образ Docker
- Отправьте образ Docker
Это занимает некоторое время, особенно загрузка зависимостей, загрузка базовых слоев образа Docker и отправка образа. Итак, если вы запускаете это последовательно, а ваш Dockerfile «умный» (мы поговорим об этом позже), вы сможете использовать много кэширования и ускорить процесс сборки с минут до секунд.
Аналогично локальной сборке, службы CI/CD должны выполнять те же действия. Единственное отличие состоит в том, что вы обычно запускаете каждую сборку на другой "чистой" машине, что также означает, что вы не можете использовать какое-либо кэширование.
Ну, это не совсем так. Некоторые службы CI/CD имеют распределенные кэши сборки, но эта концепция в корне ошибочна. Давайте посмотрим, как работают распределенные кэши сборки и в чем заключаются проблемы.
Распределенные кэши сборки — Основная причина медленной сборки
Будучи молодым инженером, я хотел продвинуться по карьерной лестнице и узнать больше о проектировании систем, распределенных системах и архитектуре программного обеспечения. Всякий раз, когда я уезжал в отпуск, я читал пару книг на эти темы. Одной из таких книг была "Проектирование приложений, интенсивно использующих данные" Мартина Клеппманна.
Это отличная книга, и я настоятельно рекомендую ее всем, кто хочет получить прочные фундаментальные знания по этим темам. Если вы хотите узнать о Consistency, Raft, пакетной обработке и т. д., то эта книга для вас.
В любом случае, я отвлекся. В книге есть одна глава, которая сильно повлияла на архитектуру «Строителя». Но также я понял, почему все существующие решения CI/CD такие медленные.
В главе 10 Мартин Клеппманн более конкретно говорит о пакетной обработке или MapReduce. Один из ключевых выводов этой главы заключается в том, что вы всегда должны стараться свести к минимуму объем данных, которые необходимо передать по сети. Это особенно важно для пакетной обработки, когда приходится иметь дело с большими объемами данных. Таким образом, вместо того, чтобы «переносить» данные на вычислительные узлы, вы должны «переносить» вычислительные узлы на данные.
<цитата>Вместо того, чтобы «переносить» данные на вычислительные узлы, вы должны «перенести» вычислительные узлы на данные.
Но это именно то, что делают решения CI/CD. Они используют «пулы» вычислительных узлов в сочетании с распределенными кэшами.
Например, когда вы запускаете сборку на GitHub Actions, вам сначала нужно дождаться, пока вычислительный узел станет доступным, что обычно отображается как «очередь» в пользовательском интерфейсе. Как только узел станет доступен, ему нужно будет загрузить кеш сборки из предыдущей сборки. А затем, как только сборка будет завершена, ему нужно будет загрузить кеш сборки для следующей сборки.
Таким образом, хотя удаленный кеш сборки может ускорить процесс сборки, он все же не такой быстрый, как локальная сборка, потому что мы по-прежнему передаем много данных по сети.
Переосмысление виртуальных машин с помощью fly.io Machines — что такое виртуальная машина?
Все это приводит к интересному вопросу: что такое виртуальная машина?
Если вы используете компьютеры fly.io, ответ на этот вопрос будет странным. Они запускают Firecracker, OSS VMM (Virtual Machine Manager) от AWS на больших машинах и, возможно, «голое железо» от Equinix или Packet. Муха «Абстракция» представляет собой «Машину», и для взаимодействия с ней есть REST API. Мы могли бы использовать Firecracker напрямую, но тогда мы, вероятно, все еще находились бы в фазе «R & D» (исследования и разработки). Firecracker великолепен благодаря надежным гарантиям изоляции, а также быстрому запуску (~ 500 мс).
Итак, что особенного в Fly Machines? Используя API, вы можете создать машину, назначить ей том, запустить ее и перевести в спящий режим. Когда ваше приложение завершится с кодом выхода 0, Машина будет остановлена, что означает, что она будет закрыта, и вы больше не будете платить за нее — только за емкость хранилища тома. Если мы хотим снова запустить Машину, мы можем сделать это, вызвав API. Он запустится примерно через 400 мс, снова подключит том, и все готово.
Подводя итог, можно сказать, что виртуальная машина — это просто том. Когда вам захочется, вы можете назначить ЦП и память тому и сделать его работающей виртуальной машиной. Но чаще всего это просто том.
Эта концепция немного ненадежна, потому что том может выйти из строя в любой момент; это все еще том, а тома терпят неудачу. Но нас это не волнует, потому что мы просто используем его как кеш.
Однако нас очень заботит другое: устранение сетевой передачи кэша сборки. Каждому проекту в облаке WunderGraph назначается выделенная машина с томом в качестве кэша сборки. Это означает, что мы вернулись к «местному» опыту сверху. Первая сборка может занять некоторое время — обычно около минуты, — но последующие сборки будут работать молниеносно, потому что мы используем «локальный» кеш, как и на вашем локальном компьютере.
Подобно MapReduce, мы переносим Задание, ЦП и Память в данные (кеш сборки), а не наоборот.
Эта архитектура настолько проста по сравнению с пулами сборки, распределенными кэшами и т. д. Иногда самые простые решения оказываются лучшими.
Однако мы далеки от завершения. Теперь у нас есть машина с кэшем на основе файловой системы, но это еще не делает ее сервисом CI/CD.
Как создавать образы Docker? Пакеты сборки? Никспаки? А может...
Нам нужно было решение для создания образов Docker на компьютере. Мы оценили несколько решений, включая Buildpacks и его преемника, Nixpacks. Для наших вариантов использования мы пришли к выводу, что оба решения являются слишком общими и предназначены для создания образов для всех типов языков и сред. В нашем случае мы хотели оптимизировать скорость и простоту, поэтому решили создать собственное решение на основе Podman.
Podman — это контейнерный движок, совместимый с Docker. Podman написан на Go, поэтому он отлично подходит для нашего варианта использования. Более того, Podman предназначен для использования в качестве библиотеки, что позволило легко интегрировать его в наше приложение. С точки зрения безопасности Podman — отличный выбор, поскольку для запуска не требуются привилегии root или демон.
Оркестрация рабочего процесса — постановка в очередь, планирование и отмена с помощьюtemporal.io
С архитектурной точки зрения у нас есть почти все, что нужно, за исключением способа организации рабочего процесса сборки. Когда пользователь отправляет фиксацию в репозиторий, нам нужно запустить сборку, отслеживать ход выполнения и сообщать о статусе пользователю.
Долгое время я присматривался к Temporal.io, который идеально подходил для нашего варианта использования для организации рабочего процесса сборки. Я думаю, что Uber использует Cadence, предшественника Temporal, и для своего решения CI/CD, поэтому я был уверен, что это сработает для нас. Тем не менее, мы все еще были очень маленькой командой, и я боялся сложности интеграции и запуска темпоральной системы.
Имея это в виду, я предложил использовать простую систему очередей для MVP, такую как RabbitMQ, для постановки задач сборки в очередь. Затем мы могли бы вернуться к этой теме позже. Одним из недостатков этого подхода является то, что нам придется самостоятельно реализовывать отказоустойчивость и мониторинг. С временным вы можете легко повторить неудачные действия, но с RabbitMQ вам придется реализовать это самостоятельно. Что касается мониторинга, вы можете использовать временный веб-интерфейс для отладки сбойных рабочих процессов. но с RabbitMQ вам придется снова изобретать колесо. Было очевидно, что временной формат нам больше подходит, но я все еще боялся сложности.
На следующий день мой технический соучредитель Дастин проделал классический «прием Дастина». Полный радости и волнения, он сообщил, что уже интегрировал темпоральную систему в наше приложение. «Это даже можно проверить!» — взвизгнул он. И вот как мы закончили темпоральный и никогда не оглядывались назад. Было несколько сбоев с отменой рабочих процессов, но временная команда была очень отзывчивой и полезной.
Оркестрация рабочих процессов CI/CD с помощьюtemporal.io
Организация рабочих процессов CI/CD, даже с временными, нетривиальна, поэтому давайте разобьем ее на несколько шагов:
- Пользователь отправляет фиксацию в репозиторий.
- Это активирует веб-перехватчик из нашего приложения GitHub.
- Веб-перехватчик принимается нашим шлюзом WunderGraph, так как мы фактически используем WunderGraph OSS для создания облака WunderGraph. Это позволяет нам тестировать наш собственный продукт. Наш шлюз проверяет подпись веб-перехватчика и перенаправляет ее в облачный API WunderGraph, который является нашим внутренним API GraphQL. Если вы знакомы с WunderGraph, вы могли заметить, что мы не раскрываем GraphQL, а прячем его за нашим шлюзом.
- Мы вызываем преобразователь в нашем внутреннем API. Преобразователь создает «Развертывание» в нашей базе данных, которое в основном является записью развертывания. Затем он отправляет задание сборки во временную службу.
- Задание сборки получает рабочий процесс, который работает в рамках нашего Cloud API, так что это, по сути, тот же процесс. Рабочий процесс запускает рабочий процесс сборки, который является оболочкой рабочего процесса «Build Machine». Затем мы создаем дочерний рабочий процесс для выполнения фактической сборки. Стоит отметить, что для каждого «Проекта» у нас есть одна очередь рабочего процесса сборки только с одним рабочим — выделенной машиной сборки, которая в данный момент находится в спящем режиме.
- После отправки дочернего рабочего процесса мы пробуждаем машину сборки от рабочего процесса-оболочки.
- Машина сборки запускается и подключается к временному серверу. Затем он будет опрашивать новые задания сборки и выполнять их. Поскольку мы уже отправили задание на сборку на предыдущем шаге, машина сборки немедленно примет его.
- После того, как построитель завершит работу, он опрашивает новое задание и завершает работу, если не может немедленно получить новое.
- Родительский рабочий процесс получит результат дочернего рабочего процесса и обновит "Развертывание" как завершенное или неудачное.
Еще несколько подробностей о рабочем процессе сборки:
Дочерний рабочий процесс использует Query API временного для запроса последнего состояния рабочего процесса сборки. Это доступно через родительский рабочий процесс, поэтому мы можем запросить последнее состояние рабочего процесса из нашего API. Мы можем передавать состояние сборки пользователю практически в режиме реального времени с помощью подписки GraphQL.
Один крайний случай, который может возникнуть, заключается в том, что пользователь отправляет новую фиксацию в репозиторий, пока сборка все еще выполняется. В этом случае мы отменяем текущий рабочий процесс, отправляя сигнал рабочему процессу. Затем рабочий процесс отменит дочерний рабочий процесс и запустит новый.
Эта архитектура оказалась очень надежной и простой в отладке.
Единственное, что нужно добавить, это ведение журнала. Мы могли бы написать целую запись в блоге о ведении журналов, особенно о ведении журналов в реальном времени, поэтому в этой статье я буду краток.
Поскольку фактическая сборка выполняется внутри Podman, мы можем доверять коду «вокруг» Podman, который управляется временными. Когда мы выполняем команды внутри Podman, мы можем пометить каждую команду как «общедоступную» или «частную». Все общедоступные команды автоматически записываются в zap.Logger , который передает журналы в два приемника, NATS JetStream и стандартный вывод.< /p>
Мы используем NATS JetStream для потоковой передачи журналов пользователю в режиме реального времени через подписку GraphQL во время выполнения сборки. В то же время мы передаем журналы на стандартный вывод, который в конечном итоге оказывается в нашей обычной инфраструктуре журналов, поддерживаемой вектором и ClickHouse. После завершения сборки мы можем загрузить и запросить журналы из ClickHouse. ClickHouse — это (в конечном итоге) непротиворечивая база данных с очень мощными возможностями запросов. При приеме данных журналы могут быть не в порядке, но после завершения сборки мы можем использовать весь потенциал базы данных. Мы выбрали этот гибридный подход, потому что не смогли найти подходящего решения, поддерживающего потоковую передачу журналов в режиме реального времени и запросы к ним позже. На эту тему было потрачено много времени, но это тема для другой статьи в блоге.
сложность кэширования рабочих процессов CI/CD и создание отличной стратегии кэширования
Теперь, когда у нас есть способ организовать рабочий процесс сборки, нам нужно обсудить детали стратегии кэширования.
Никогда не используйте последний тег для образов Docker< /h4>
При создании образа Docker, даже с помощью Podman, вам понадобятся базовые образы (слои). Чтобы сделать их кэшируемыми, вам нужно убедиться, что вы не используете тег latest. Вместо этого используйте SHA, которые определяют точную версию артефакта.
Это важно не только для базового образа/слоев, но и при передаче окончательного образа в удаленный реестр. Использование SHA ускоряет отправку слоев при повторной отправке одного и того же изображения. Благодаря этому мы можем за считанные секунды откатиться к предыдущей версии кода, используя точно такой же рабочий процесс, поскольку все кэшируется.
Рекомендации по использованию Docker — Создавайте слои в кэшируемой последовательности
Далее нам нужно быть осторожными с тем, как мы строим наши слои. В Docker важно создавать слои последовательно, чтобы не сделать их недействительными слишком рано или без причины.
Вот пример плохой стратегии многослойности:
COPY . /app
Это приведет к аннулированию кеша для всего слоя, даже если вы изменили только один файл. Давайте исправим это!
Сначала скопируйте файлы, которые блокируют ваши зависимости, например package.json, package-lock.json, установите зависимости, а затем скопируйте исходный код приложения. .
WORKDIR /app
COPY wundergraph/package.json wundergraph/package-lock.json /app/
RUN npm install
COPY . /app/
n Установка зависимостей npm может быть очень дорогостоящей операцией, поэтому важно кэшировать результат этого шага. Благодаря многоуровневой стратегии мы можем кешировать результат npm install и делать кеш недействительным только тогда, когда либо package.json, либо package-lock. json изменяется. Этот шаг экономит нам не менее 45 секунд на каждую последующую сборку.
Рекомендации по использованию Docker — Использовать кэш-монтирование для слоев
Далее нам нужно принять во внимание монтирование кэша уровня Docker. Все менеджеры пакетов Node используют общее хранилище артефактов, чтобы избежать многократной загрузки одного и того же пакета. С помощью монтирования кеша уровня Docker мы можем указать Podman кэшировать и восстанавливать местоположение кеша при запуске npm install.
Вот пример:
RUN --mount=type=cache,id=npm-global,target=/root/cache/npm npm ci --cache /root/cache/npm --prefer-offline --no-audit
Кэш больших двоичных объектов Podman. сжатие и загрузка
Когда дело доходит до отправки слоев образа в удаленный реестр, Podman запускает несколько запросов параллельно. Хотя в большинстве случаев это быстро, это также может стать узким местом. Сетевой ввод-вывод медленнее по сравнению с оперативной памятью или диском — служба может дать сбой и привести к более длительным или неудачным сборкам. Чтобы тратить меньше времени и сделать этот процесс еще более надежным, Podman управляет локальным кэшем больших двоичных объектов. На практике это позволяет избежать ненужного сжатия и загрузки. Подробнее о кэше больших двоичных объектов можно узнать здесь.
Уборка и уборка после сборки
После того, как ваш образ создан и отправлен в удаленный реестр, нам нужно выполнить некоторую очистку. Каждая новая сборка создает новый образ Docker. Это только вопрос времени, когда у вас закончится свободное место на диске. Однако простое удаление всех образов после сборки — неправильный подход, поскольку при этом будут удалены базовые образы и локальный кеш слоя Docker.
Мы используем метки Docker, чтобы различать разные образы, что позволяет нам фильтровать только ранее созданные образы и удалять их. Наконец, мы анализируем том строителя. Если он когда-либо превысит 75% пространства, мы запустим жесткий системный сброс podman -f и очистим все временные каталоги. При следующем коммите ваш билдер вернется в чистое состояние.
Native OverlayFS — секретный соус
В этот момент вы можете подумать, что мы закончили: мы собрали все вместе и готовы к работе. Со всем этим кешированием мы должны создавать и отправлять изображения за считанные секунды, верно?
Ну, не совсем. Нам не хватало ОДНОЙ СТРОКИ КОДА! Мы думали, что закончили, но почему-то сборка все еще занимала до 30 секунд. Что-то было не так... поэтому Дастин начал копать глубже в проблему.
Podman использует оверлейную файловую систему в качестве драйвера хранилища. Overlay File System — это эффективный способ создания и хранения различий в файловой системе. Вместо перемещения и копирования сотен мегабайт при каждом запуске контейнера отслеживаются только модификации. У каждого контейнера есть свое монтирование overlayfs.
Короче говоря, когда контейнер не вносит никаких изменений в файловую систему, никакие дополнительные данные не копируются. Если новый файл добавляется/обновляется/удаляется, сохраняется только разница. Если вы предпочитаете визуальный подход, я могу порекомендовать эту страницу иллюстраций Джулии Эванс .
Каждая файловая операция должна проходить через несколько вызовов ядра. Если вы используете старое ядро, которое не поддерживает собственные оверлеи, и вам нужно скопировать сотни тысяч маленьких файлов, например, путем копирования node_modules, это может привести к узким местам. Вот отличный ресурс, если вас интересуют подробности.
Вначале мы не запускали сборки с включенными собственными оверлеями, потому что не смогли заставить их работать с нашей настройкой с использованием Подман внутри контейнера . Если вы инициализируете Podman внутри контейнера, он проверит свои возможности хранения в корневом расположении хранилища Podman. Во время сборки образа это расположение монтируется в файле overlayfs. Наложение поверх собственного наложения не будет работать. Чтобы обойти первое наложение, нам нужно volume смонтировать корень хранилища следующим образом:
# https://github.com/containers/buildah/issues/3666
volume /var/lib/containers
n Благодаря этому небольшому изменению мы смогли включить собственные оверлеи. Первоначальные сборки улучшились с 1:15 до 0:55, а последующие сборки — с 30 до 13 секунд.
Мы считаем, что 13 секунд — приемлемое время сборки конвейера CI/CD. Это не так быстро, как вызов API, если сравнивать со временем, которое требуется для обновления конфигурации шлюза API. Но это достаточно быстро, чтобы обеспечить фантастическое удобство для разработчиков, учитывая все преимущества, которые предоставляются по сравнению с традиционной настройкой шлюза API.
Строитель — краткое изложение
Окончательное решение позволяет нам предоставить нашим пользователям наилучший пользовательский опыт.
Когда вы создаете новый проект в облаке WunderGraph, мы выделяем компьютер-конструктор и компьютер-шлюз. Оба спят, пока вы их не используете. Когда вы делаете коммит, мы пробуждаем сборщик и запускаем процесс сборки. Когда сборка завершена, мы снова переводим конструктор в спящий режим.
Шлюз также находится в спящем режиме, пока вы не сделаете вызов API, и в этом случае мы пробуждаем его примерно через 500 мс и обслуживаем ваш API. В этом сила Serverless без каких-либо ограничений.
Несмотря на то, что администрирование парка машин нельзя недооценивать, представленный подход позволяет нам развертывать WunderGraph наших пользователей за 13 секунд с бесшовной интеграцией в нашу общую архитектуру.
эффекты быстрой сборки и изолированных сред для приложений SaaS и мультитенантных приложений
В заключение этой статьи я хочу поделиться некоторыми соображениями о влиянии быстрой сборки и изолированных сред на приложения SaaS и мультитенантные приложения. Этот пост был посвящен созданию основы WunderGraph Cloud, многопользовательского многопроектного шлюза API, который строится на основе шлюза API с одним арендатором. Но, как я уже говорил ранее, тот же шаблон можно применить к любому приложению SaaS с замечательными преимуществами.
Компании могут полностью использовать открытый исходный код и создать сильное сообщество вокруг своего продукта, сохраняя при этом возможность построить вокруг него сильную бизнес-модель. Если вы не различаете версию с открытым исходным кодом и облачную версию, вам не придется жертвовать опытом разработки.
Одним из таких примеров является реализация поддержки OpenTelemetry (OTEL) в WunderGraph. Версия с открытым исходным кодом будет полностью поддерживать создание трассировок OTEL. Вы можете настроить сборщик OTEL с помощью переменных среды и использовать его для отправки трассировок в ваш любимый сервер трассировки без ограничений.
Когда вы развертываете свое приложение WunderGraph в WunderGraph Cloud, мы автоматически настраиваем эти переменные среды, запускаем сборщик OTEL, серверную часть OTEL, хранилище и пользовательский интерфейс для вас.
Это сильно мотивирует нас как компанию поддерживать сильное предложение с открытым исходным кодом, потому что это основа нашего бизнеса. В то же время мы можем предложить нашим пользователям большую ценность, предоставив полностью управляемый набор инструментов, который вам понадобится для создания рабочей среды.
Если бы мы создали отдельную мультитенантную версию WunderGraph, нам всегда пришлось бы искать компромисс между предложением функции в версии с открытым исходным кодом или повышением ценности нашего облачного предложения.
Еще одним заметным эффектом SaaS является невероятно быстрое время холодного запуска развернутой версии WunderGraph API Gateway. Но тот же принцип применим к любому приложению SaaS, развернутому таким же образом.
Благодаря времени холодного запуска около 500 мс мы можем предоставить нашим пользователям «серверный» опыт (имейте в виду, что мы говорим о полностью изолированной среде для каждого проекта) за небольшую часть стоимости традиционного API. Шлюз.
Кластеры традиционных шлюзов API работают круглосуточно и без выходных, даже если вы их не используете. Это делает их экономически невыгодными для небольших команд, стартапов, хобби-проектов и Proof Of Concepts. Благодаря этой новой модели развертывания мы можем предложить эту функциональность аудитории, которая раньше не могла себе этого позволить. Но в то же время вы можете легко масштабироваться по горизонтали и получать выгоду от строгой изоляции, если вы крупная компания.
Я считаю, что это будущее многопользовательских приложений SaaS. Компании из других отраслей могут просто следовать той же схеме и превратить свои однопользовательские приложения в многопользовательские предложения SaaS. Он основан на силе открытого исходного кода, позволяя компаниям по-прежнему строить прочный и защищенный ров вокруг своего продукта.
Каждый может самостоятельно разместить WunderGraph — сделайте это, если хотите, — но если вам нужно полностью управляемое, готовое к работе развертывание за 5 кликов, вы можете воспользоваться нашим сервисом.
Попробуйте сами
Если вы хотите испытать Builder в действии, вы можете попробовать его самостоятельно бесплатно. Просто перейдите в WunderGraph Cloud и создайте новый проект на основе шаблона. Загляните в репозиторий, сделайте коммит и наблюдайте, как происходит волшебство.
Если у вас есть вопросы, отзывы или идеи о том, что еще мы можем сделать с конструктором, не стесняйтесь обращаться к нам в Discord. .
Что дальше?
Следующей задачей для нас является реализация предварительных сред, распределенная трассировка от периферии до источника и пограничное кэширование для нашего шлюза API, чтобы завершить наше предложение бессерверного шлюза API.
Что заставляет нас улыбаться
В наших демонстрациях продуктов мы любим демонстрировать идеальную интеграцию WunderGraph с Vercel, где WunderGraph отвечает за уровень API, а Vercel — за внешний интерфейс. Забавно видеть, что мы можем выполнить полное развертывание шлюза быстрее, чем развертывание исправления опечатки в приложении Next.js.
Мысли о fly.io
Мы используем fly.io не только для сборки, но и для развертывания бессерверных рабочих нагрузок для наших пользователей. У нас было несколько проблем с fly и их надежностью, но в целом мы очень довольны их обслуживанием. Несмотря на недавние дискуссии об их надежности, я хотел бы поделиться нашим взглядом на этот вопрос.
На самом деле мы используем API fly Machines и некоторые части их API GraphQL для управления fly Machines. Хотя дизайн API можно было бы улучшить, у нас он работает очень хорошо. Большинство проблем, о которых люди сообщают на форумах fly, связаны с развертыванием и интерфейсом командной строки flyctl.
Я думаю, что проблема с fly заключается в том, как они управляют ожиданиями. Они хотят быть «облачными провайдерами», но на текущем этапе они больше похожи на «REST API для глобально распределенных виртуальных машин Firecracker». Эта абстракция «Машина» очень мощная, с частной сетью, томами и т. д. . и это вполне надежно.
На самом деле я не думаю, что нам нужен еще один «облачный провайдер» с PostgreSQL, Redis и т. д. в качестве сервиса. Я могу пойти в Aiven, Planetscale или Neon и получить полностью управляемую базу данных.
Что нам действительно нужно, так это надежный, надежный и простой в использовании REST API для глобального управления виртуальными машинами с быстрым холодным запуском, частной сетью и файловым хранилищем.
Если бы я был летчиком или, может быть, даже конкурентом, я бы принял решение сосредоточиться на компаниях, которые создают свои собственные облака, вместо того, чтобы пытаться продавать напрямую конечным пользователям (разработчикам). Многие проблемы возникают у разработчиков, пытающихся вручную развернуть свои контейнеры Docker. Мы никогда не используем flyctl и редко пользуемся веб-интерфейсом fly, нас интересует только их API, у которого даже нет спецификации OpenAPI.
Я думаю, что муха на правильном пути, и мне не терпится увидеть, куда они ее поведут. Некоторое время назад Курт дразнил идею, позволяющую вам «приостановить» виртуальную машину, а затем «возобновить» ее позже. Одна только эта функция сильно изменила бы правила игры для нас и для всех остальных, потому что мы могли сократить время холодного запуска NodeJS, Java и других «тяжелых» сред выполнения намного ниже 1 с. Одного этого и отличного REST API (без странных прокси) для управления этими виртуальными машинами было бы достаточно, чтобы построить компанию на миллиард долларов. Мои 2 цента.
Также опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)