

Создание модульных рабочих процессов речи в тексте: архитектура и анализ производительности агента CLI AI
5 июля 2025 г.В этой статье представлен дизайн и реализация модульного интерфейса интерфейса командной строки (CLI) для рабочих процессов речи в тексте, объединяя аудиозаписи в реальном времени с транскрипцией с AI и интеллектуальным сохранением контента. Система демонстрирует многоуровневый архитектурный подход, который разделяет захват, обработку и понимание естественного языка на различные, совместимые компоненты. Анализ был сосредоточен на трех основных областях: конструкция модульных компонентов, механизмы кроссплатформенного совместимости и паттерны интеграции между локальными и удаленными службами обработки. Благодаря изучению моделей реализации и характеристик производительности, мы показываем, как модульные принципы проектирования могут улучшить обслуживание, кроссплатформенную совместимость и расширяемость в приложениях обработки речи. Наши результаты показывают, что хорошо структурированные слои абстракции могут снизить сложность интеграции при сохранении эффективности обработки и надежности системы.
Введение
Технология речи к тексту стала основополагающей для современных вычислительных приложений, от голосовых помощников до обслуживания транскрипционных услуг. Тем не менее, большинство реализаций либо определяют приоритеты в простоте использования за счет настройки, либо предлагают обширную конфигурируемость, требуя существенных усилий по разработке. Задача заключается в создании систем, которые балансируют простоту, настройку и производительность с помощью модульного дизайна.
В этой статье рассматривается агент ИИ на основе CLI, который отвечает этим конкурирующим требованиям с помощью модульной архитектуры. Система объединяет несколько ключевых технологий: кроссплатформенная аудиозапись с помощью системных утилит, распознавание речи с AI с помощью модели Whisper Openai и интеллектуальное суммирование контента с использованием крупных языковых моделей. Анализируя модели реализации и архитектурные решения, мы даем представление о разработке рабочих процессов по обработке речи.
Основным вкладом этой работы является демонстрация того, как слои абстракции могут изолировать специфичную платформу сложность при сохранении производительности и расширяемости системы. Мы фокусируемся на трех ключевых областях: модульный дизайн подсистемы записи, подход управления сеансом для обработки нескольких независимых рабочих процессов записи и моделей интеграции между локальной обработкой и удаленными службами API.
Современные приложения для обработки речи часто борются с фрагментацией платформы, где различные операционные системы требуют отдельных механизмов захвата звука. Наш анализ показывает, как унифицированный интерфейс может абстрагировать эти различия при сохранении нативных характеристик эффективности. Кроме того, мы рассмотрим, как управление файлами на основе сеансов может улучшить организацию рабочего процесса и включить сценарии обработки пакетной обработки.
Помимо технических соображений, этот агент CLI AI удовлетворяет растущую потребность в доступных инструментах захвата знаний, управляемых голосом. В эпоху, когда информационная перегрузка ставит под сомнение профессионалов, студентов и исследователей, способность быстро выразить мысли и получать структурированные, обобщенные результаты представляют собой значительное повышение производительности. Система преобразует простой акт разговора в мощный рабочий процесс для организации и анализа личной или профессиональной информации.
Запись о проблеме
Традиционные реализации речи в тексте сталкиваются с несколькими архитектурными проблемами, которые ограничивают их практическую применимость. Во-первых, механизмы аудиозаписи значительно варьируются в зависимости от операционных систем, требуя кода, специфичного для платформы, который усложняет техническое обслуживание и тестирование. Linux Systems обычно использует интерфейсы ALSA, MacOS опирается на основные аудиоам -каркасы, а Windows использует DirectSound или Wasapi. Эта фрагментация заставляет разработчиков ограничивать поддержку платформы или поддерживать несколько кодовых баз.
Во -вторых, большинство существующих решений тесно тесно связаны с разбором звука с обработкой транскрипции, что затрудняет изменение параметров записи, переключение между различными службами распознавания речи или добавлением этапов обработки, такими как снижение шума или идентификация динамика. Эта связь снижает гибкость системы и усложняет отладку, когда возникают проблемы на определенных этапах трубопровода.
В -третьих, управление рабочими процессами в приложениях по обработке речи часто не хватает структуры для обработки нескольких независимых сеансов записи, организации выходных файлов или реализации сценариев обработки пакетной обработки. Под одновременными сеансами мы подразумеваем возможность запускать новые рабочие процессы записи, в то время как предыдущие записи все еще обрабатываются или хранятся, предотвращая конфликты файлов и поддержание организованного вывода. Пользователям часто нужно вручную управлять организацией файлов, отслеживание состояния обработки и координировать между различными этапами обработки.
Разрыв в этом документе является отсутствие документированных архитектурных моделей для построения модульных систем обработки речи, которые поддерживают простоту при обеспечении расширяемости. В то время как академическая литература широко охватывает алгоритмы распознавания речи, существует ограниченное руководство по архитектуре системы для практических применений, которые необходимы для интеграции нескольких технологий и выполнения реальных оперативных требований.
Наш подход демонстрирует, насколько тщательный дизайн слоя абстракции может решить эти проблемы, не жертвуя производительностью и не вводя ненужную сложность. Изучив рабочую реализацию, мы приводим конкретные примеры того, как модульные паттерны применяются к рабочим процессам по обработке речи, и определяем ключевые проектные решения, которые влияют на обезболиваемость и расширяемость системы.
3. Исследование
Методология
Мы проанализировали шаблоны архитектуры и реализации агента CLI AI на основе TypeScript, предназначенного для рабочих процессов речи в тексте.
Экзамен кодовой базы включал в себя отслеживание потока данных через системную архитектуру, определение границ абстракции и измерение связи между компонентами. Мы оценили расширяемость подсистемы записи, изучив, как могут быть добавлены новые реализации регистратора без изменения существующего кода. Для конвейера транскрипции мы проанализировали разделение между компонентами обработки аудио и компонентами понимания естественного языка.
Анализ производительности был сосредоточен на шаблонах использования ресурсов во время записи аудио, операциях ввода -вывода файлов и связи API. Мы изучили характеристики использования памяти потоковой обработки звука и оценили эффективность подхода на основе сеанса.
Анализ архитектуры
Система реализует четырехслойную архитектуру, которая разделяет проблемы при сохранении четких путей потока данных. Рисунок 1 иллюстрирует общую структуру системы и отношения компонентов.
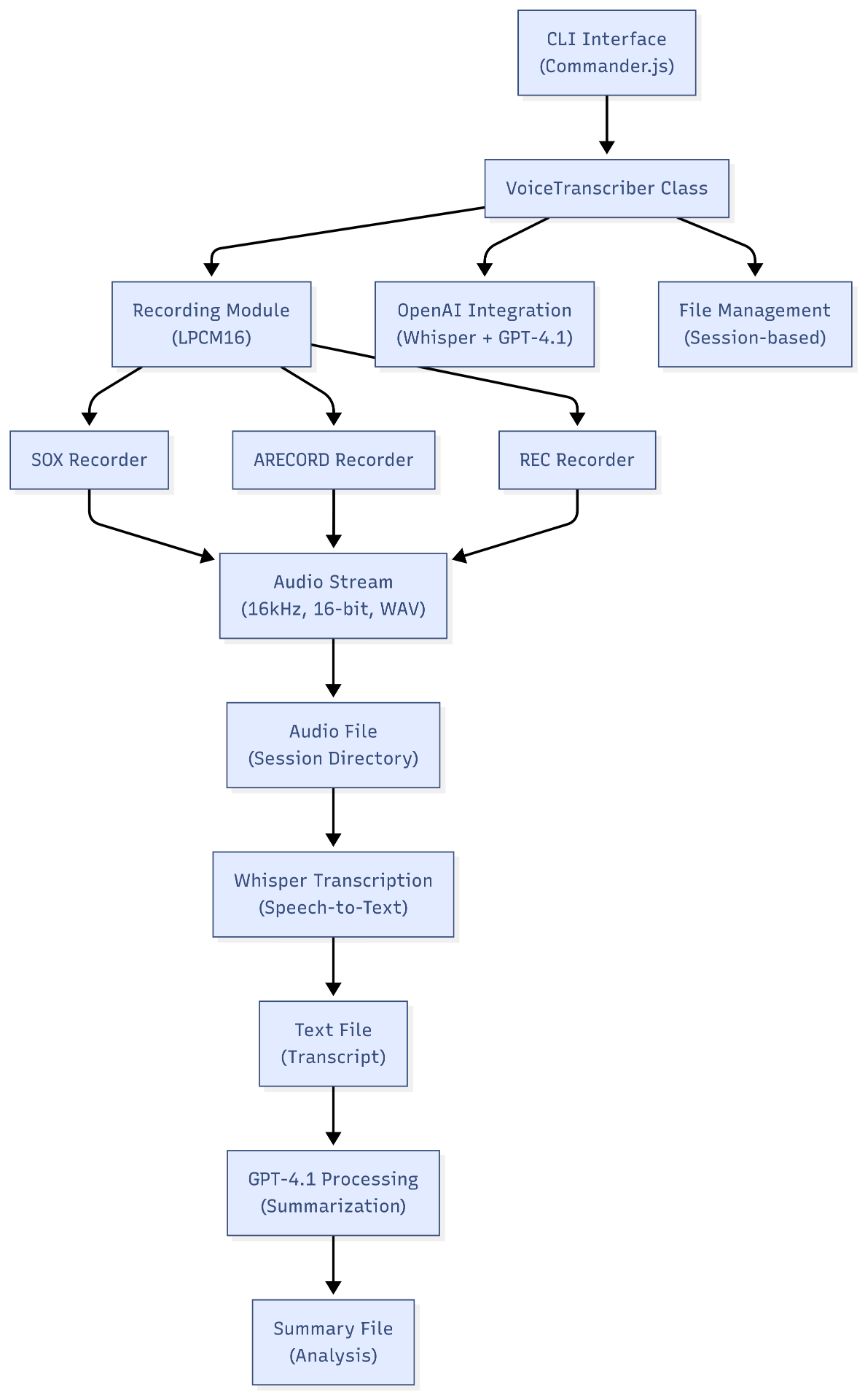
Рисунок 1: Обзор архитектуры системы
Фонд слой состоит из рекордов для конкретных платформ (Sox, Arecord, Rec), которые обрабатывают фактический захват звука. Sox Recorder обеспечивает кроссплатформенную совместимость через унифицированную интерфейс командной строки, в то время как ARECORD и ReC предлагают реализации, оптимизированные платформы для Linux и MacOS соответственно.
Уровень абстракции содержит класс записи, который реализует шаблон фасада, чтобы обеспечить унифицированный интерфейс для всех реализаций регистратора. Этот уровень обрабатывает управление жизненным циклом процесса, обработку потока и распространение ошибок. Изолируя различия в платформе на этой границе, компоненты более высокого уровня могут работать без знаний, специфичных для платформы.
Уровень приложения включает в себя класс Voicetranscriber и интерфейс команд CLI. Этот уровень управляет состоянием сеанса, координирует обработку рабочих процессов и обрабатывает взаимодействие с пользователями. Класс Voicetranscriber поддерживает конфигурацию записи, организацию выходного файла и координацию обработки конвейера.
Процедурный уровень интегрируется с внешними службами искусственного интеллекта для распознавания речи и понимания естественного языка. Whisper Model Openai обрабатывает конверсию речи в текст, в то время как GPT-4.1 обеспечивает интеллектуальную сумму и анализ контента.
Поток данных и трубопровод обработки
На рисунке 2 демонстрируется полный рабочий процесс обработки от захвата звука до окончательной выработки.

Рисунок 2: Последовательность рабочего процесса обработки
Рабочий процесс начинается, когда пользователи инициируют запись через интерфейс CLI. VoiceTranscriber создает экземпляр записи с указанными параметрами конфигурации, который порождает соответствующий системный процесс для захвата аудио. Аудиоданные потоки непрерывно от процесса регистратора через потоки node.js до выходного файла.
Когда пользователи прекращают запись, система изящно отключает процесс записи и ожидает завершения файлов. Фаза транскрипции отправляет аудиофайл в API Openai's Whisper и получает текстовый вывод. Наконец, этап суммирования обрабатывает транскрипт через GPT-4.1 для создания структурированного анализа.
Обработка ошибок происходит на нескольких уровнях, когда класс записи управления ошибками, связанными с процессом, вопросами API-обработки Voicetranscriber, а также интерфейс CLI, предоставляющий удобные сообщения об ошибках. Этот слоистый подход гарантирует, что ошибки обрабатываются на соответствующем уровне абстракции.
Оценка модульности компонентов
Модульная конструкция обеспечивает независимую эволюцию и тестирование независимой компонентов. На рисунке 3 иллюстрирует слоистая архитектура, которая обеспечивает модульную организацию компонентов.
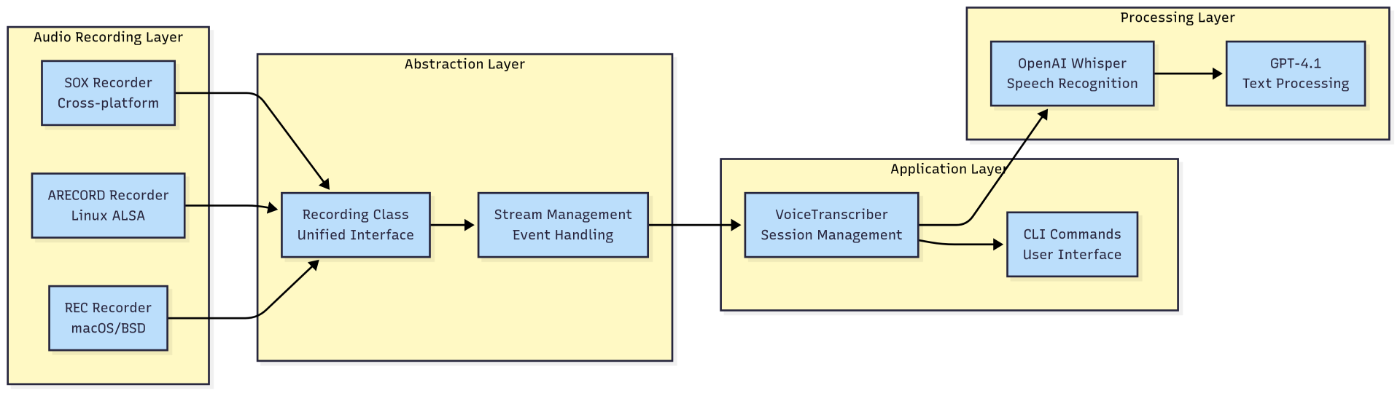
Рисунок 3: Архитектура модульных компонентов
В таблице 1 приведены характеристики связи между основными компонентами системы.
Пара компонентов | Тип связи | Направление зависимости | Влияние расширяемости |
|---|---|---|---|
Cli <> Voicetranscriber | Интерфейс | CLI зависит от VoiceTrancriber | Низкий - на основе интерфейса |
Voicetranscriber <> запись | Композиция | Voicetranscriber создает запись | Средний - зависимость творения |
Запись <> recorders | Стратегический шаблон | Запись выбирает регистратор | Низкий - заводской шаблон |
Voicetranscriber <> openai | Услуга | Voicetranscriber называет API | Низкий - внешний сервис |
Запись <> системный процесс | Управление процессом | Запись управляет процессом | Высокая зависимость системы |
Класс записи демонстрирует эффективное использование шаблона стратегии, позволяя реализации новых рекордеров без изменения существующего кода. Добавление поддержки для дополнительных утилит для захвата звука требует только реализации интерфейса RecorderResult и обновления логики выбора регистратора.
Характеристики производительности
Анализ использования ресурсов выявляет эффективные модели памяти и обработки. Потоковая передача аудио через node.js поддерживает постоянное использование памяти независимо от продолжительности записи, поскольку данные вытекают непосредственно из системного процесса для подачи вывода без промежуточной буферии.
Файл-организация, основанная на сессии, улучшает управление рабочими процессами, создавая временные каталоги для каждого сеанса записи. Этот подход предотвращает конфликты файлов в сценариях одновременного использования и упрощает операции по обработке пакетов.
Паттерны связи API показывают соответствующую обработку ошибок и логику повторения, хотя текущая реализация использует синхронную обработку для транскрипции и суммирования. Будущие оптимизации могут реализовать параллельную обработку для нескольких аудиофайлов или транскрипции потоковой передачи для приложений в реальном времени.
4. Примеры кода
Следующие примеры кода иллюстрируют ключевые архитектурные шаблоны и методы реализации, используемые в модульной системе речи в тексте.
Запись слоя абстракции
Класс записи демонстрирует, как абстрагировать захват аудио, специфичная для конкретной платформы при сохранении безопасности типа и обработке ошибок:

Этот шаблон отделяет выбор регистратора от управления процессами, что позволяет легко добавить новые реализации захвата аудио. АgetRecorderCommand()Метод служит фабрикой, которая возвращает стандартизированную конфигурацию команды независимо от базового регистратора.
Стратегический шаблон для аудиозаписи
Реализация Sox Recorder показывает, как может быть инкапсулирована логика для конкретной платформы, обеспечивая постоянный интерфейс:
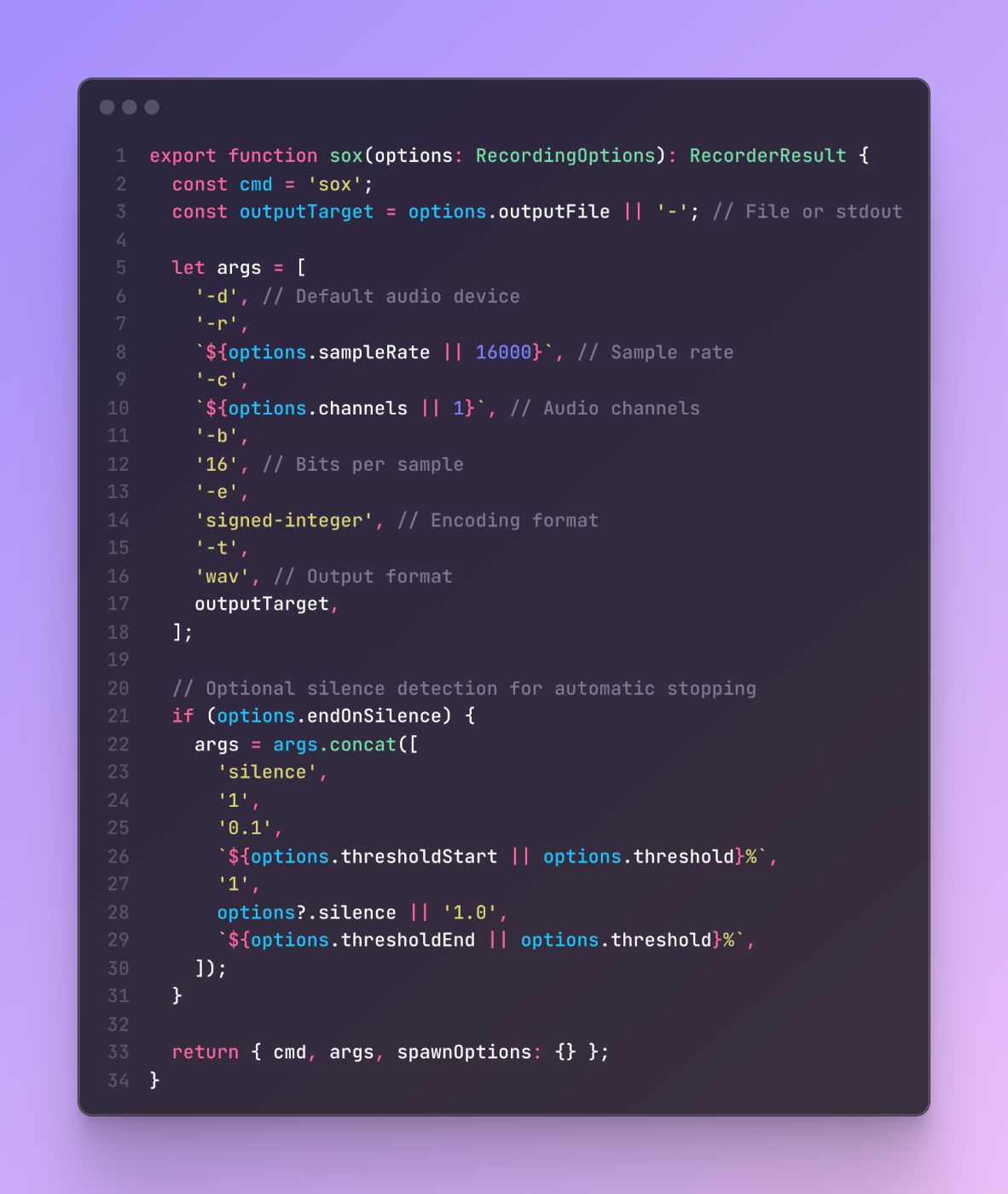
Эта реализация демонстрирует, как сложные параметры обработки звука могут быть настроены через простой интерфейс параметров при сохранении совместимости с базовой системой.
Управление сессиями и координация рабочих процессов
Класс Voicetranscriber показывает, как координировать множество этапов обработки при сохранении чистого разделения проблем:

Подход, основанный на сеансе, предотвращает конфликты с файлами и предоставляет четкую организацию для сценариев обработки пакетной обработки. Каждый сеанс записи создает изолированный каталог с последовательными соглашениями об именовании файлов.
Паттерн интеграции API
Метод транскрипции демонстрирует эффективную интеграцию с внешними службами при сохранении обработки ошибок и безопасности типа:
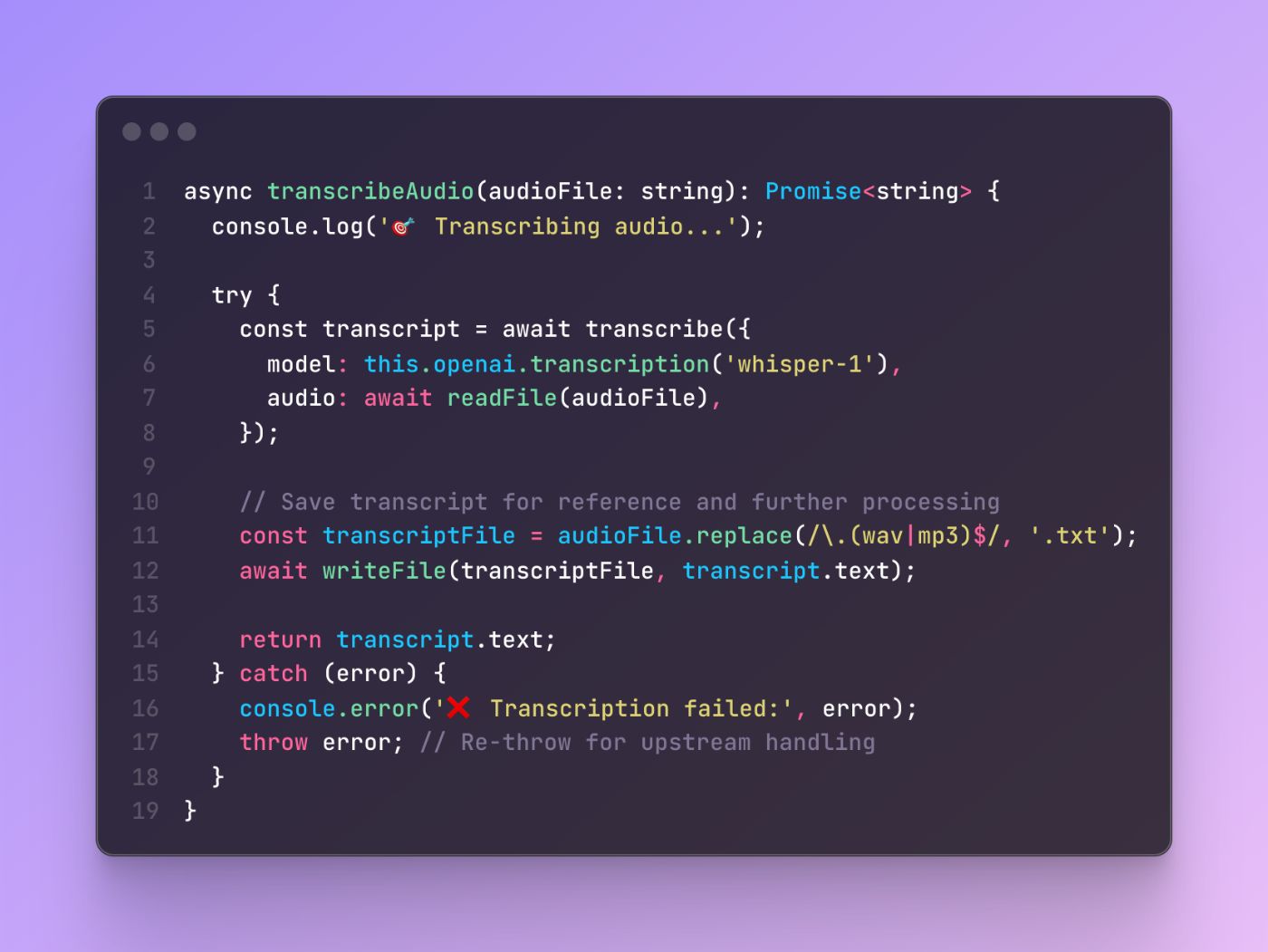
Этот шаблон показывает, как интегрироваться с внешними API, обеспечивая соответствующую обработку ошибок и локальное управление файлами. Метод поддерживает единую ответственность, сосредотачиваясь только на транскрипции при делегировании организации файлов на уровень управления сеансами.
5. Заключение
Этот анализ демонстрирует, что принципы модульной архитектуры могут эффективно решать проблемы сложности, присущие рабочим процессам речи в тексте. Исследованный агент CLI AI успешно отделяет захват аудио, специфичную для платформы от логики приложения, обеспечивая кроссплатформенную совместимость без жертвы производительности или обслуживания.
Ключевые архитектурные идеи включают эффективность уровней абстракции для изоляции системных зависимостей, ценность стратегических шаблонов для обработки вариаций платформы и важность организации, основанной на сеансе для управления рабочими процессами. Абстракция класса записи оказывается особенно ценной, что позволяет системе поддерживать несколько механизмов захвата аудио через унифицированный интерфейс.
Паттерны интеграции между локальной обработкой и удаленными службами API предоставляют шаблон для построения приложений, которые сочетают в себе преимущества с помощью облачных сервисов искусственного интеллекта. Стратегии обработки ошибок и подходы к управлению ресурсами обеспечивают надежную работу в производственных средах.
Однако несколько ограничений требуют рассмотрения. Текущая реализация обрабатывает аудиофайлы последовательно, что может не соответствовать требованиям производительности для высокопроизводительных сценариев. Системные зависимости от внешних аудио утилит могут усложнить развертывание в контейнерных средах. Кроме того, зависимость от облачных API вводит соображения задержки и доступности для приложений в реальном времени.
Практические приложения этой архитектуры выходят за рамки рабочих процессов речи к тексту. Агент CLI AI оказывается особенно ценным в повседневных сценариях, где пользователи должны быстро захватывать, организовать и анализировать разговорную информацию. Например, специалисты могут использовать систему для записи и автоматического обобщения заметок об собрании, исследователи могут отражать понимание интервью со структурированным анализом, а студенты могут преобразовать лекции в организованные учебные материалы. Обученный голосовой интерфейс устраняет трение ручного размещения заметок, позволяя пользователям просто говорить свои мысли, идеи или наблюдения и получать как точные транскрипции, так и интеллектуальные резюме.
Организация, основанная на сессии, делает систему особенно полезной для управления персональным знанием, где пользователи могут создавать доступный для поиска архив своих разговорных мыслей и идей с течением времени. Каждое сеанс записи создает временную ткань, классифицированную коллекцию как необработанных транскриптов, так и резюме, сгенерированных AI, позволяя пользователям эффективно пересматривать и ссылаться на свои устные заметки. Этот подход превращает CLI из простого инструмента транскрипции в всеобъемлющий личный помощник, способный к увеличению памяти и обработку информации.
Модульные паттерны также применяются к любой системе, требующей интеграции между локальными ресурсами и облачными службами, особенно в сценариях, включающих мультимедийную обработку, оркестровку трубопроводов данных или архитектуры гибридных вычислительных вычислений.
Будущие направления исследований включают исследование потоковой транскрипционной транскрипции для приложений в реальном времени, внедрение возможностей распределенной обработки для обработки нескольких одновременных сеансов и изучение интеграции с моделями распознавания речи на поступке для снижения зависимости облаков. Кроме того, расширение абстракции регистратора для поддержки передовых функций обработки аудио, таких как снижение шума, разделение динамиков и адаптация акустической среды, может улучшить применимость системы к сложным средам записи.
Анализ архитектуры показывает, что вдумчивый дизайн слоя абстракции может разрешить напряжение между простотой системы и расширяемостью. Изучая практические модели реализации, эта работа обеспечивает конкретное руководство для построения применений для обработки речи, которые могут развиваться с изменяющимися требованиями и технологическими достижениями.
Подход к управлению сессиями оказывается особенно ценным для организационных рабочих процессов, где обработка аудио является частью более крупных трубопроводов управления документами или создания контента. Четкое разделение между этапами записи, транскрипции и суммирования обеспечивает гибкую настройку рабочих процессов и облегчает интеграцию с существующими бизнес -процессами.
Это исследование способствует более широкому пониманию того, как модульные принципы проектирования применяются к приложениям, которые соединяют местные системы системных ресурсов и облачные услуги искусственного интеллекта, предоставляя основу для будущих разработок в области гибридных вычислительных архитектур для мультимедийных приложений обработки.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)