

Создание продукта на базе Embeddings для поиска эссе Пола Грэма с использованием Siri
14 февраля 2023 г.https://www.youtube.com/shorts/9700RsFxMBc?embedable=true
:::информация Embedbase – это API с открытым исходным кодом для создания, хранения и обработки данных. получение вложений.
:::
Сегодня мы создадим поисковую систему для эссе Пола Грэма, которую мы будем использовать с Apple Siri Shortcuts, например. задавать Siri вопросы об этих эссе.
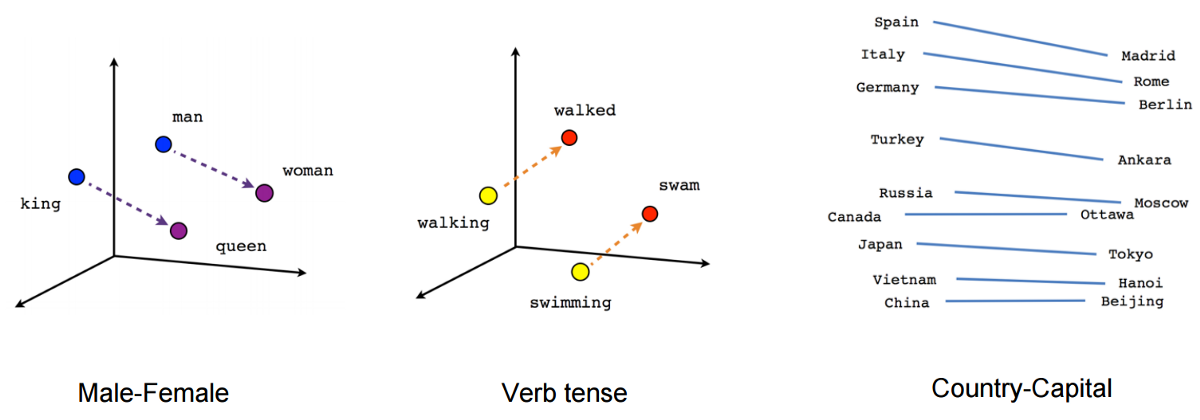
«Внедрение» – это концепция машинного обучения, позволяющая сравнивать данные.
Сегодня мы не будем углубляться в техническую тему встраивания.
:::подсказка Думать о «встраиваниях» — это как складывать похожие вещи в сумку. Итак, если у вас есть сумка с игрушками, и вы хотите найти определенную игрушку, вы заглядываете в сумку и видите, какие другие игрушки находятся рядом с ней, чтобы понять, какую из них вы хотите. Компьютер может делать то же самое со словами, складывая похожие слова в пакет, а затем находя нужное слово на основе других слов рядом с ним.
:::
Если вы хотите использовать встраивания в своем производственном программном обеспечении, вам необходимо иметь возможность легко хранить их и получать к ним доступ.
Существует множество векторных баз данных и моделей НЛП для хранения и вычисления вложений. Есть также несколько дополнительных приемов работы с вложениями.
n Например, может стать ==затратно и неэффективно== повторно вычислять, когда в этом нет необходимости, например, если в примечании содержится «собака», а затем «собака», вам не обязательно выполнять пересчет, потому что измененная информация может оказаться бесполезной.
Кроме того, эти векторные базы данных требуют серьезного обучения и понимания машинного обучения.
n Embedbase позволяет синхронизировать и выполнять семантический поиск данных, ничего не зная о машинном обучении, векторных базах данных и оптимизации вычислений. в несколько строк кода.
Поиск эссе Пола Грэма с помощью Siri
По порядку мы:
- Разверните Embedbase локально или в Google Cloud Run
- Создайте сканер для эссе Пола Грэма с помощью Crawlee, который загружает данные в Embedbase
- Создайте ярлык Apple Siri, который позволит вам искать эссе Пола Грэма в Embedbase с помощью Voice & естественный язык
Время сборки!
Технический стек
- Встроенная база
- Машинопись
- Сканер Crawlee + Playwright
- Google Cloud Run для развертывания
- Команды Apple Siri для запроса индекса
Клонирование репозитория
git clone https://github.com/another-ai/embedbase
cd embedbase
Настройка шишки
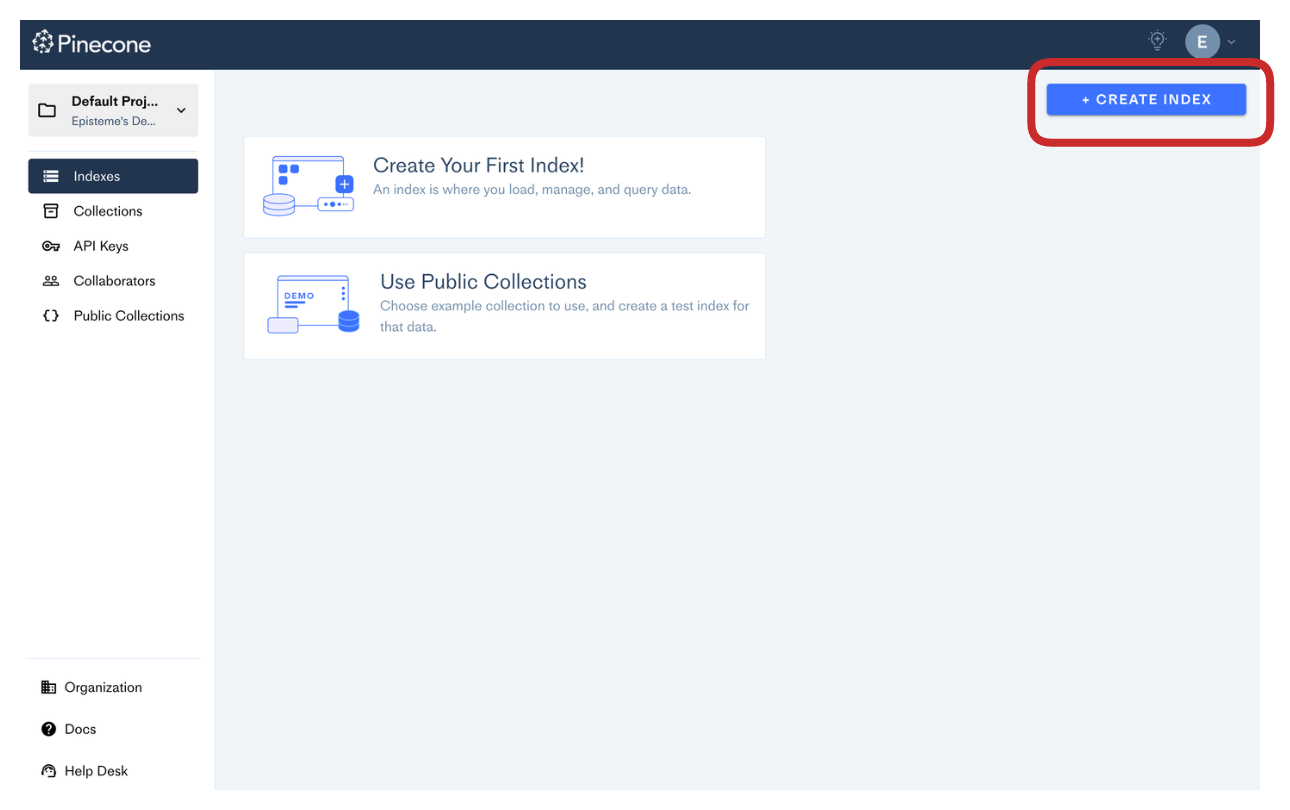
Перейдите на веб-сайт Pinecone, войдите в систему и создайте индекс:
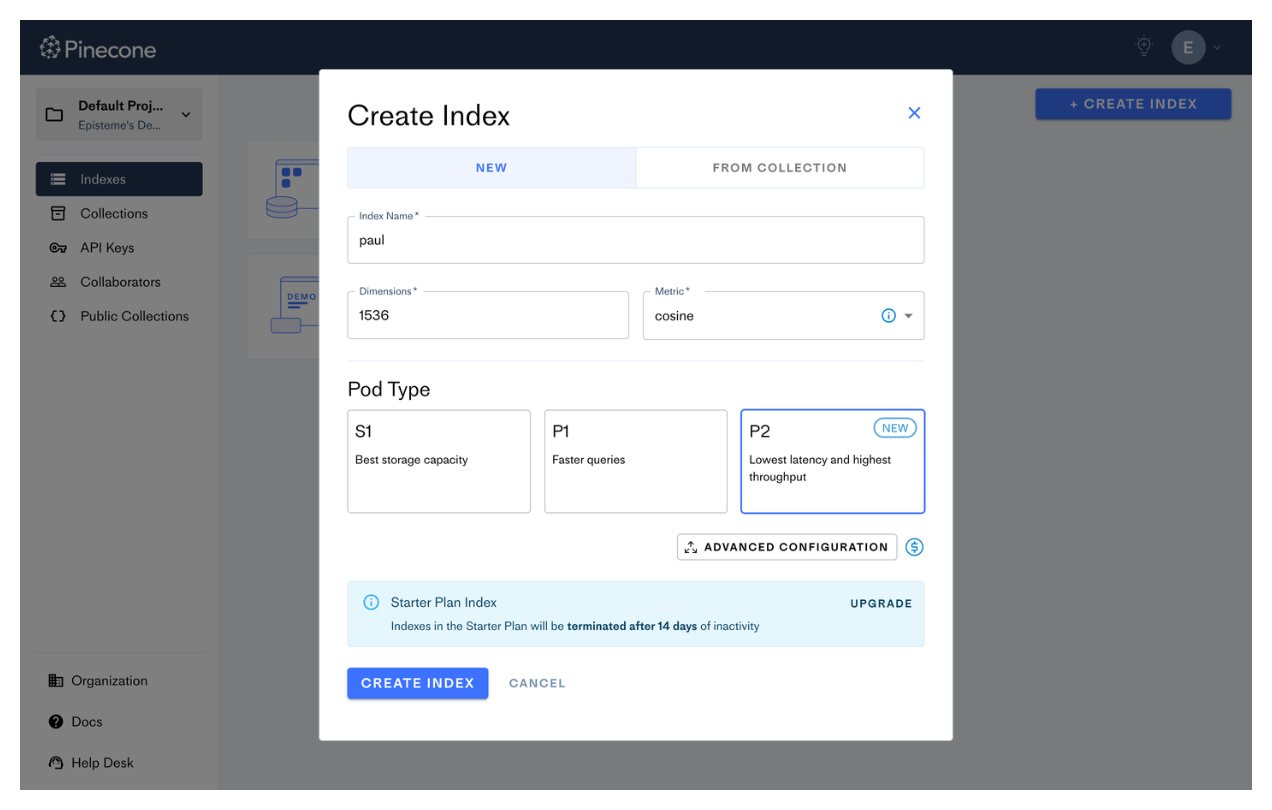
Мы назовем его «пол» и используем размер «1536» (важно правильно указать это число, под капотом это «размер» структуры данных OpenAI «встраивания»), другие настройки менее важны.
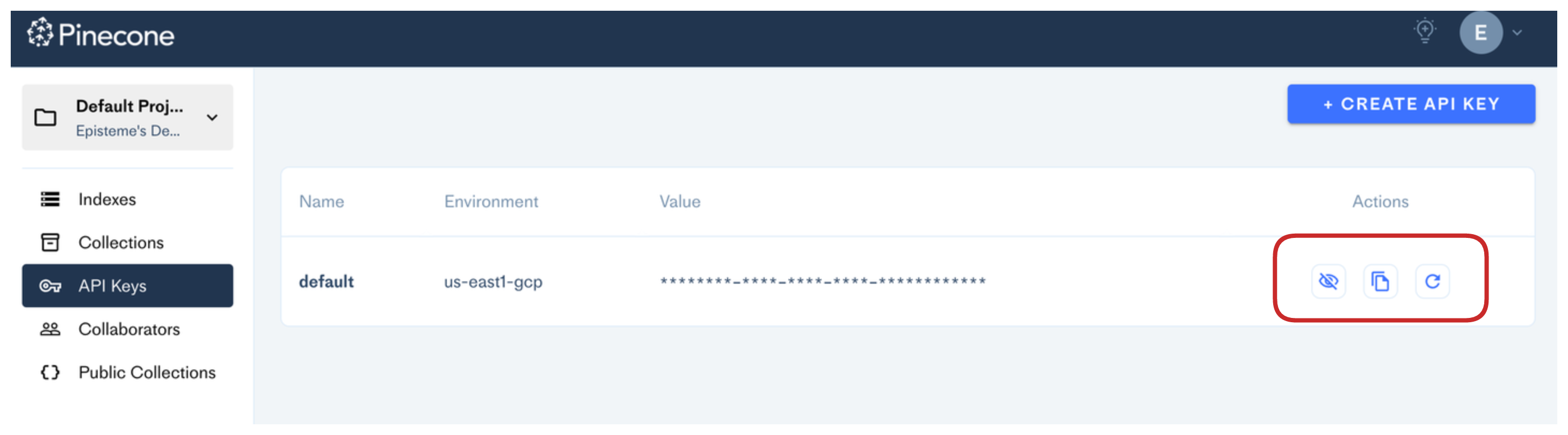
Вам необходимо получить ключ API Pinecone, который позволит Embedbase взаимодействовать с Pinecone:
Настройка OpenAI
Теперь вам нужно получить конфигурацию OpenAI по адресу https://platform.openai.com/account/api-keys. (при необходимости создайте учетную запись).
Нажмите «Создать новый ключ»:
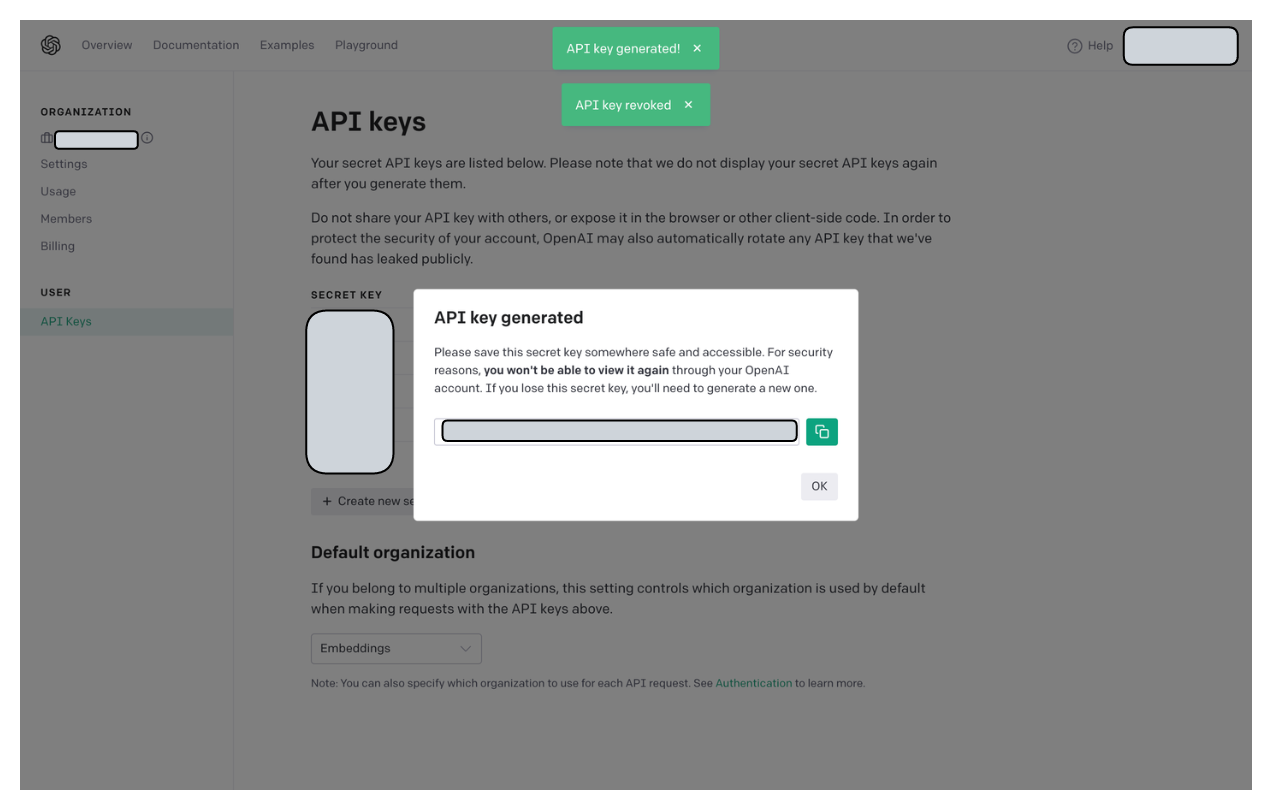
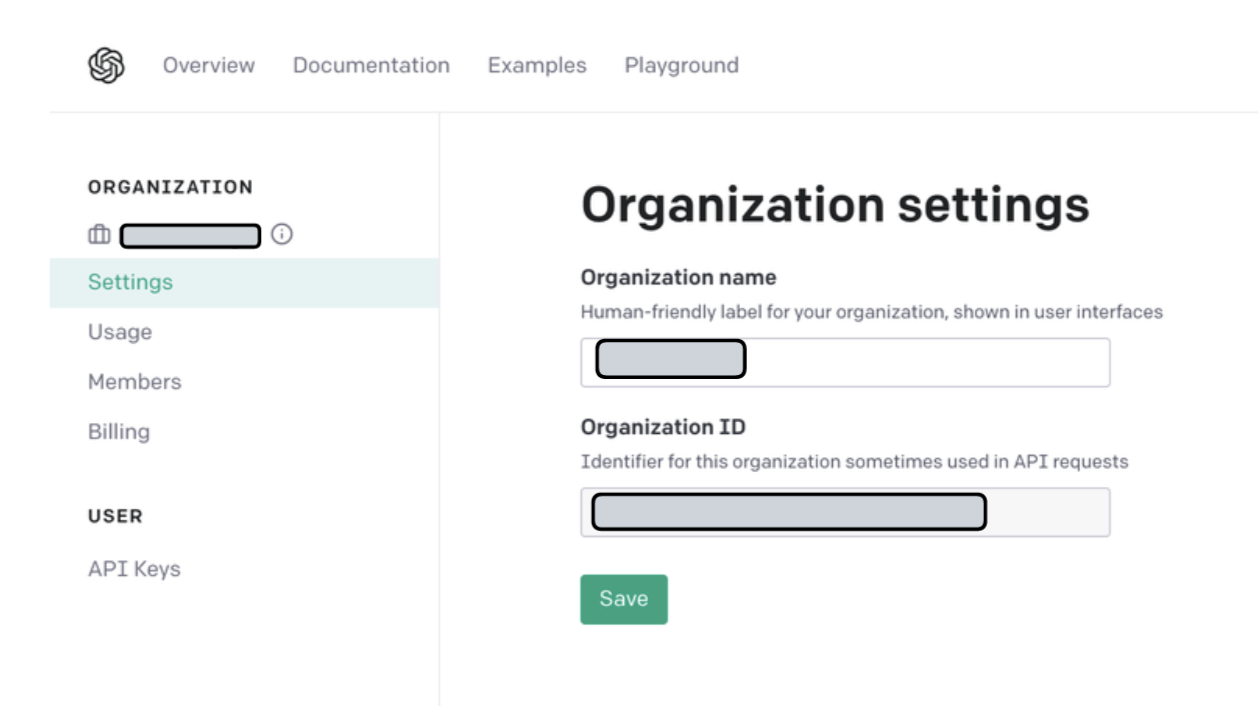
Кроме того, получите идентификатор своей организации здесь:
Создание конфигурации Embedbase
Теперь напишите и заполните значения в файле «config.yaml» (в каталоге embedbase):
# embedbase/config.yaml
# https://app.pinecone.io/
pinecone_index: "my index name"
# replace this with your environment
pinecone_environment: "us-east1-gcp"
pinecone_api_key: ""
# https://platform.openai.com/account/api-keys
openai_api_key: "sk-xxxxxxx"
# https://platform.openai.com/account/org-settings
openai_organization: "org-xxxxx"
Запуск Embedbase
🎉 Теперь вы можете запустить Embedbase!
Запустите Docker. Если у вас его нет, установите его, следуя инструкциям на официальном сайте. .
Теперь запустите Embedbase:
docker-compose up
(Необязательно) Облачное развертывание
:::подсказка Это необязательно, можете сразу перейти к следующей части!
:::
Если у вас есть мотивация, вы можете развернуть Embedbase в Google Cloud Run. Убедитесь, что у вас есть проект Google Cloud и установлена командная строка «gcloud» с помощью официальной документации.
# login to gcloud
gcloud auth login
# Get your Google Cloud project ID
PROJECT_ID=$(gcloud config get-value project)
# Enable container registry
gcloud services enable containerregistry.googleapis.com
# Enable Cloud Run
gcloud services enable run.googleapis.com
# Enable Secret Manager
gcloud services enable secretmanager.googleapis.com
# create a secret for the config
gcloud secrets create EMBEDBASE_PAUL_GRAHAM --replication-policy=automatic
# add a secret version based on your yaml config
gcloud secrets versions add EMBEDBASE_PAUL_GRAHAM --data-file=config.yaml
# Set your Docker image URL
IMAGE_URL="gcr.io/${PROJECT_ID}/embedbase-paul-graham:0.0.1"
# Build the Docker image for cloud deployment
docker buildx build . --platform linux/amd64 -t ${IMAGE_URL} -f ./search/Dockerfile
# Push the docker image to Google Cloud Docker registries
# Make sure to be authenticated https://cloud.google.com/container-registry/docs/advanced-authentication
docker push ${IMAGE_URL}
# Deploy Embedbase to Google Cloud Run
gcloud run deploy embedbase-paul-graham
--image ${IMAGE_URL}
--region us-central1
--allow-unauthenticated
--set-secrets /secrets/config.yaml=EMBEDBASE_PAUL_GRAHAM:1
Создание поискового робота для эссе Пола Грэма
Сканеры позволяют загружать все страницы веб-сайта. Это базовый алгоритм, используемый Google.
Клонируйте репозиторий и установите зависимости:
git clone https://github.com/another-ai/embedbase-paul-graham
cd embedbase-paul-graham
npm i
Давайте посмотрим на код, если вы перегружены всеми файлами, необходимыми для проекта Typescript, не волнуйтесь & игнорировать их.
// src/main.ts
// Here we want to start from the page that list all Paul's essays
const startUrls = ['http://www.paulgraham.com/articles.html'];
const crawler = new PlaywrightCrawler({
requestHandler: router,
});
await crawler.run(startUrls);
Вы можете видеть, что краулер инициализируется «маршрутами», что это за таинственные маршруты?
// src/routes.ts
router.addDefaultHandler(async ({ enqueueLinks, log }) => {
log.info(`enqueueing new URLs`);
await enqueueLinks({
// Here we tell the crawler to only accept pages that are under
// "http://www.paulgraham.com/" domain name,
// for example if we find a link on Paul's website to an url
// like "https://ycombinator.com/startups" if it will ignored
globs: ['http://www.paulgraham.com/**'],
label: 'detail',
});
});
router.addHandler('detail', async ({ request, page, log }) => {
// Here we will do some logic on all pages under
// "http://www.paulgraham.com/" domain name
// for example, collecting the page title
const title = await page.title();
// getting the essays' content
const blogPost = await page.locator('body > table > tbody > tr > td:nth-child(3)').textContent();
if (!blogPost) {
log.info(`no blog post found for ${title}, skipping`);
return;
}
log.info(`${title}`, { url: request.loadedUrl });
// Remember that usually AI models and databases have some limits in input size
// and thus we will split essays in chunks of paragraphs
// split blog post in chunks on the nn
const chunks = blogPost.split(/nn/);
if (!chunks) {
log.info(`no blog post found for ${title}, skipping`);
return;
}
// If you are not familiar with Promises, don't worry for now
// it's just a mean to do things faster
await Promise.all(chunks.flatMap((chunk) => {
const d = {
url: request.loadedUrl,
title: title,
blogPost: chunk,
};
// Here we just want to send the page interesting
// content into Embedbase (don't mind Dataset, it's optional local storage)
return Promise.all([Dataset.pushData(d), add(title, chunk)]);
}));
});
Что такое добавить()?
const add = (title: string, blogPost: string) => {
// note "paul" in the URL, it can be anything you want
// that will help you segment your data in
// isolated parts
const url = `${baseUrl}/v1/paul`;
const data = {
documents: [{
data: blogPost,
}],
};
// send the data to Embedbase using "node-fetch" library
fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(data),
}).then((response) => {
return response.json();
}).then((data) => {
console.log('Success:', data);
}).catch((error) => {
console.error('Error:', error);
});
};
Теперь вы можете запустить сканер, загрузка & загружать все в Embedbase.
:::предупреждение Будут использованы кредиты OpenAI на сумму менее <1 доллара США
.:::
npm start
Если вы развернули Embedbase в облаке, используйте
# you can get your cloud run URL like this:
CLOUD_RUN_URL=$(gcloud run services list --platform managed --region us-central1 --format="value(status.url)" --filter="metadata.name=embedbase-paul-graham")
npm run playground ${CLOUD_RUN_URL}
Вы должны увидеть некоторую активность в своем терминале (как в контейнере Embedbase Docker, так и в процессе узла) без ошибок (не стесняйтесь обращаться за помощью иначе).
(Необязательно) Поиск через Embedbase в вашем терминале
В примере репозитория вы можете заметить «src/playground.ts», который представляет собой простой скрипт, который позволяет вам взаимодействовать с Embedbase в вашем терминале, код прост:
// src/playground.ts
const search = async (query: string) => {
const url = `${baseUrl}/v1/paul/search`;
const data = {
query,
};
return fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(data),
}).then((response) => {
return response.json();
}).then((data) => {
console.log('Success:', data);
}).catch((error) => {
console.error('Error:', error);
});
};
const p = prompt();
// this is an interactive terminal that let you search in paul graham
// blog posts using semantic search
// It is an infinite loop that will ask you for a query
// and show you the results
const start = async () => {
console.log('Welcome to the Embedbase playground!');
console.log('This playground is a simple example of how to use Embedbase');
console.log('Currently using Embedbase server at', baseUrl);
console.log('This is an interactive terminal that let you search in paul graham blog posts using semantic search');
console.log('Try to run some queries such as "how to get rich"');
console.log('or "how to pitch investor"');
while (true) {
const query = p('Enter a semantic query:');
if (!query) {
console.log('Bye!');
return;
}
await search(query);
}
};
start();
Вы можете запустить его следующим образом, если вы запускаете Embedbase локально:
npm run playground
Или, например, если вы развернули Embedbase в облаке:
npm run playground ${CLOUD_RUN_URL}
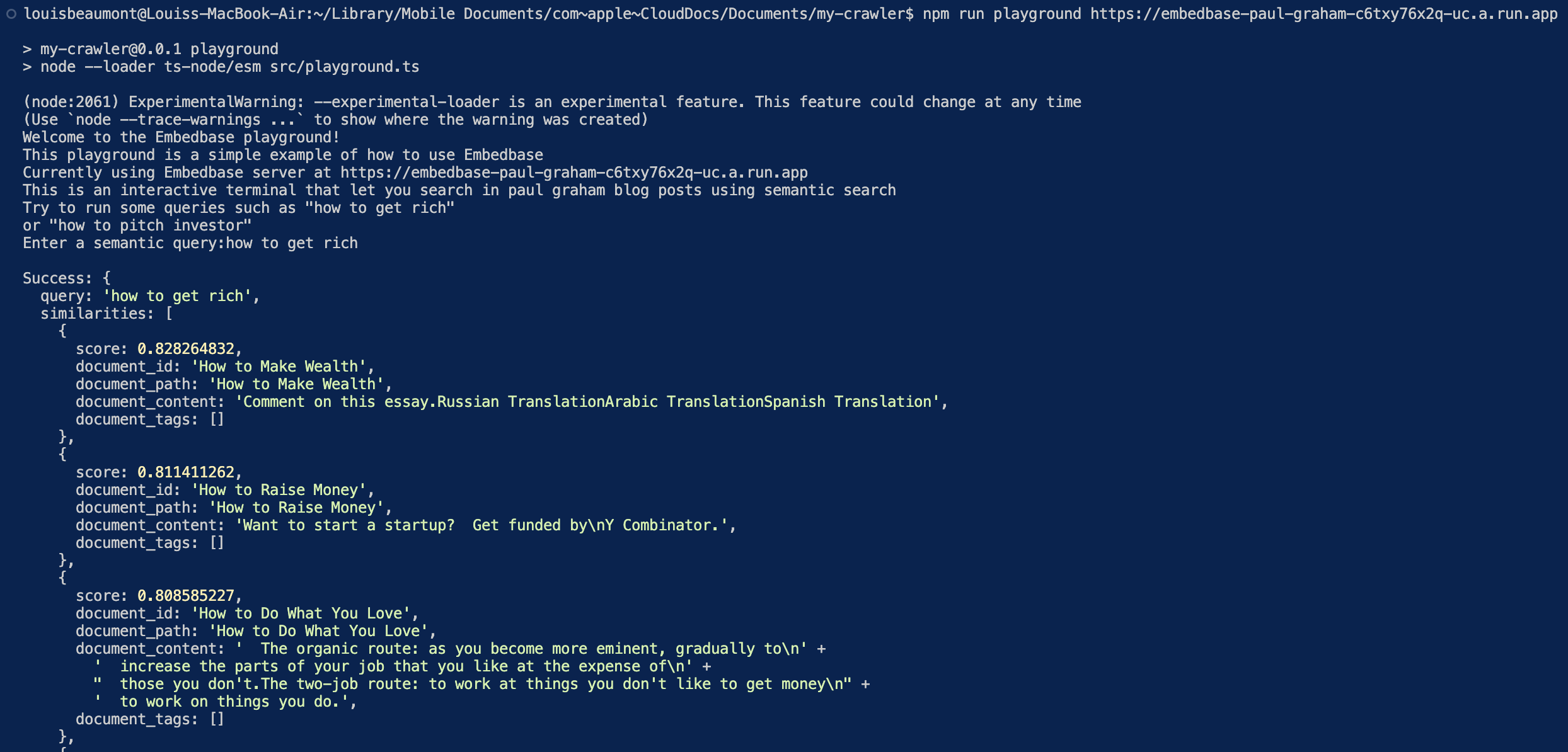
Результаты:
(Необязательно) Создание ярлыка Apple Siri
Веселое время! Давайте создадим ярлык Apple Siri, чтобы иметь возможность задавать Siri вопросы об эссе Пола Грэма 😜
Во-первых, давайте запустим Apple Shortcuts:

Создайте новый ярлык:

Мы назовем этот ярлык «Поиск Пола» (учтите, что именно так вы попросите Siri запустить ярлык, поэтому выберите что-нибудь попроще)
На простом английском языке этот ярлык задает пользователю запрос и вызывает с ним Embedbase, а также говорит Siri произносить вслух найденные эссе.
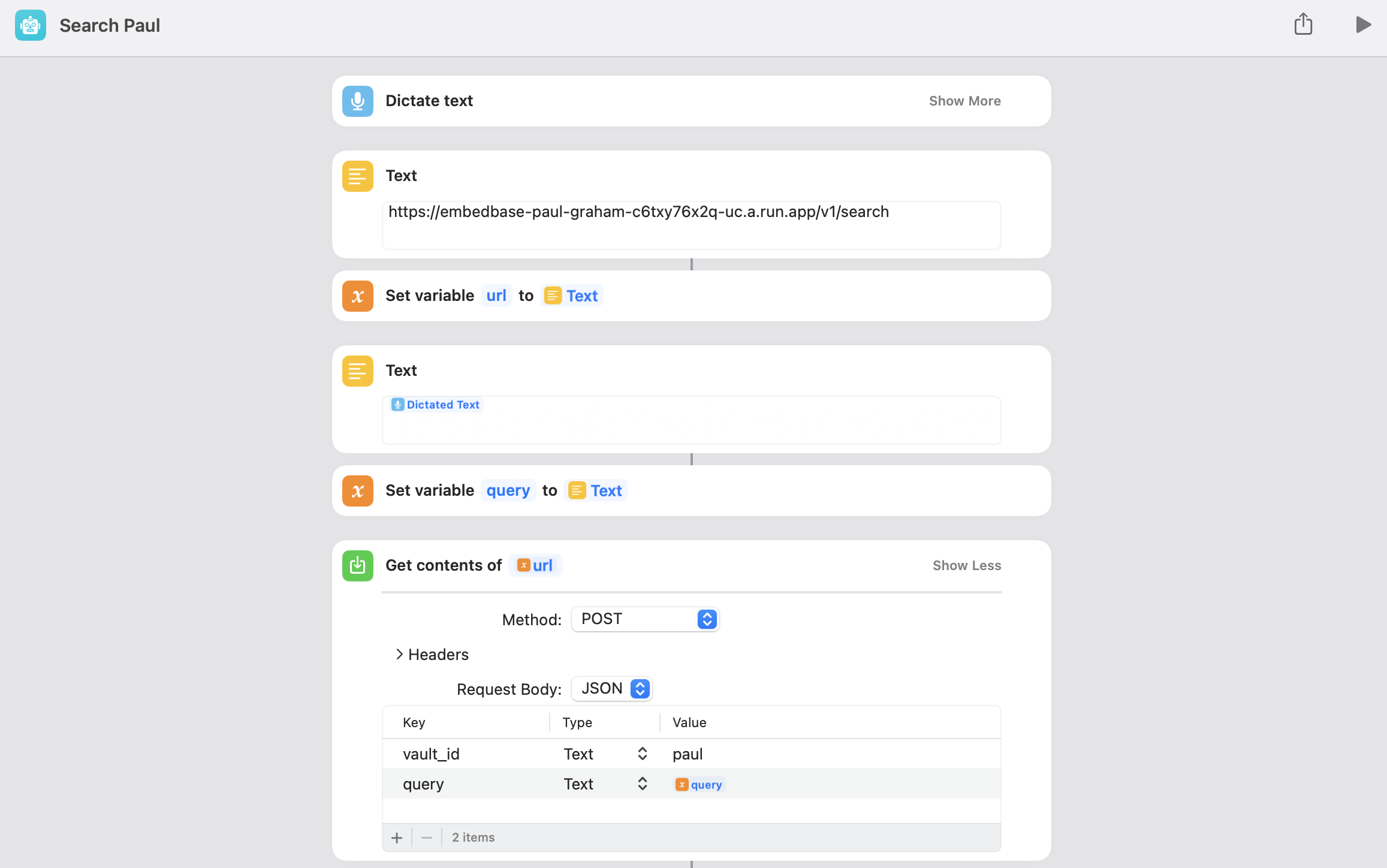
- "Диктовать текст" позволяет задавать поисковый запрос голосом (выберите английский язык)
- Мы храним конечную точку Embedbase в текстовом файле для ясности. Измените его в соответствии с вашими настройками ("https://localhost:8000/v1/search", если вы используете Embedbase локально)
- Мы снова установили конечную точку в переменной для ясности.
- То же самое для надиктованного текста
- Теперь «Получить содержимое» будет выполнять HTTP-запрос POST к Embedbase, используя наш ранее определенный во время сканирования «vault_id» как «paul» и использует переменную «query» для свойства «query».
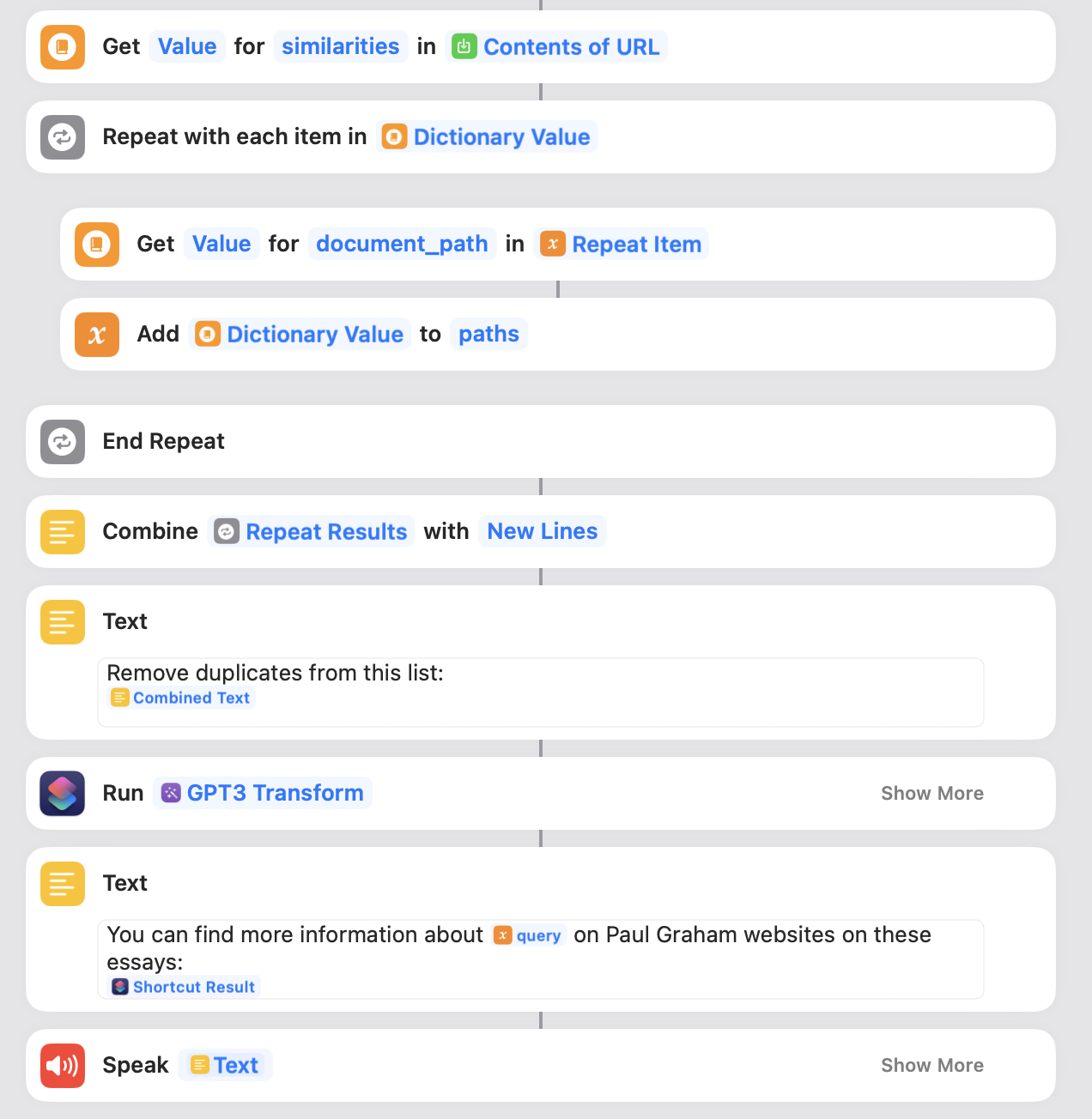
- «Получить» извлечет свойство «сходство» из ответа Embedbase.
-
"Повторить с каждым элементом" будет для каждого сходства:
-
Получить свойство «document_path»
- Добавить в переменную «пути» (список)
- «Объединить» приведет к «объединению» результатов новой строкой.
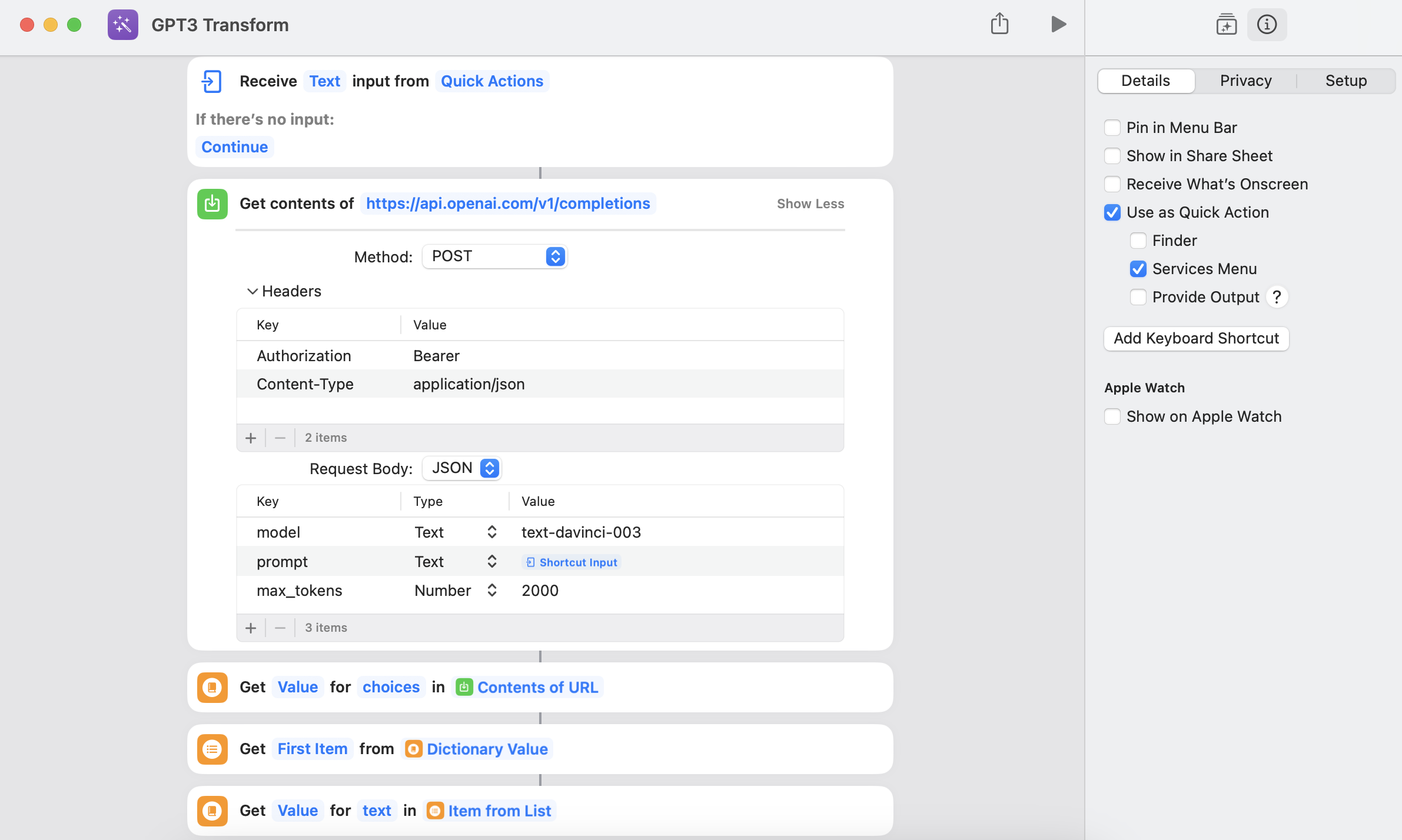
- (Необязательно, ниже показано, как это сделать) Это забавный трюк, который вы можете добавить к ярлыку для остроты, используя OpenAI GPT3, чтобы преобразовать часть текста результата, чтобы он лучше звучал, когда Siri произносит его
- Мы собираем результат в «Текст», чтобы его можно было озвучить.
- Попросите Siri произнести это
https://www.youtube.com/shorts/9700RsFxMBc?embedable=true
:::подсказка Вы можете преобразовать результаты в более красивый текст, используя этот функциональный ярлык GPT3
:::
(заполните значение «Авторизация» «Bearer [ВАШ OPENAI KEY]»)
С Embedbase вы можете создать семантический продукт в кратчайшие сроки, не беспокоясь о создании, хранении и расширении. извлечение вложений с минимальными затратами.
Заключение
:::
https://github.com/another-ai/embedbase-paul-graham?embedable =правда
https://www.youtube.com/shorts/9700RsFxMBc?embedable=true
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27455)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)