
Создание микросервиса FastAPI OCR
19 декабря 2022 г.Иногда вам нужно настроить микрослужбу OCR, которая принимает изображения и возвращает текст. В этой статье я попытаюсь объяснить основные идеи о том, как бесплатно создать собственный сервис распознавания текста, используя python, fastAPI, tesseract, redis, celery и docker.< /p>
Что такое микросервисная архитектура?
Это один из вариантов серверной архитектуры, основанный на мельчайших независимых службах (веб-приложениях), которые взаимодействуют друг с другом с помощью протоколов на основе SOAP, REST, GraphQL и RPC. В нашем микросервисе мы будем использовать архитектурный стиль REST для взаимодействия микросервиса с одним основным узлом микросервиса (fastAPI_service), но имейте в виду, что это не лучший вариант.
Наша микросервисная архитектура.
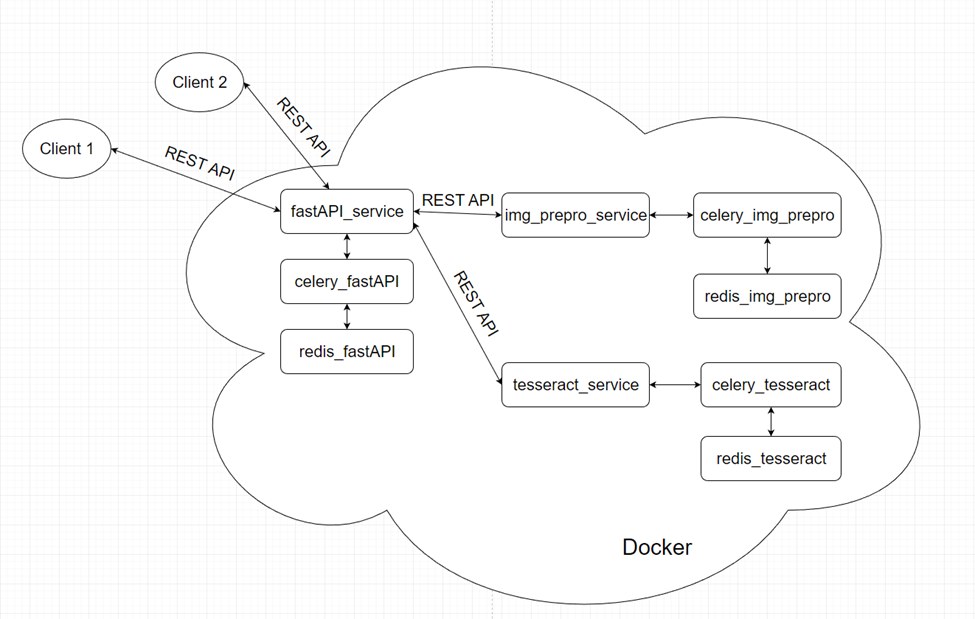
В нашей службе OCR у нас будет 9 микрослужб с дизайном архитектуры оркестровки, где у нас есть одна основная микрослужба, которая взаимодействует с другими. Я покажу вам, как создать каждую службу и заставить ее работать с другими.
Конечные точки FastAPI.
Служба FastAPI будет точкой входа в нашу службу OCR. Все коммуникации будут там. Он имеет python + fastAPI + uvicorn. Он будет иметь 3 конечных точки. Конечная точка POST /api/v1/ocr/img, GET /api/v1/ocr/status/{task_id} и GET /api/v1/ocr/ текст/{идентификатор_задачи}.
Мы собираемся использовать конечную точку POST /api/v1/ocr/img для загрузки изображений. Кроме того, он запустит задачу и даст нам идентификатор задачи. С помощью GET /api/v1/ocr/status/{task_id} мы получим статус нашей задачи (процесс ocr — довольно «тяжелая» задача, и ее выполнение займет некоторое время), после получения статус успеха, который мы собираемся использовать, и конечную точку GET /api/v1/ocr/text/{task_id}, чтобы увидеть окончательные результаты.
Во-первых, давайте создадим папку проекта и поместим следующую файловую структуру:
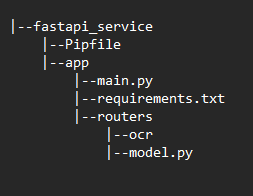
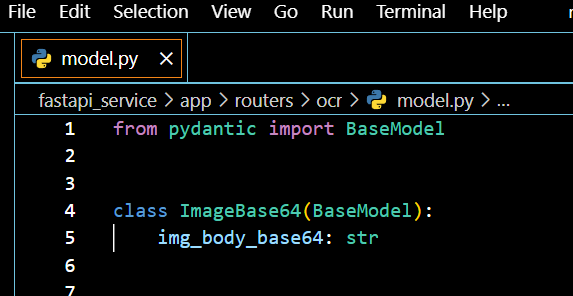
Для каждого сервиса у нас будет своя папка, я использую VS Code для написания кода, а для создания virtualenv я использую pipenv упаковка. Для локального тестирования вне Docker я буду запускать службы в виртуальных средах.
Давайте посмотрим на main.py.
from fastapi import FastAPI
from app.routers import ocr
app = FastAPI()
app.include_router(ocr.router)
@app.get("/")
async def root():
return {"message": "Hello Hackernoon.com!"}
Здесь мы определяем только одну корневую конечную точку GET. Он возвращает простое сообщение JSON. Кроме того, мы включаем маршрутизатор OCR, где у нас есть список конечных точек, принадлежащих OCR. Хорошей практикой является не помещать все ~~яйца в одну корзину~~ конечные точки в один файл, потому что это будет перегружено и не легко для понимания. Попробуйте разделить свой код на небольшие логически независимые части и соединить их короткими строками кода в один основной файл. Давайте посмотрим на наш маршрутизатор OCR, который мы включили в основной маршрутизатор FastAPI.
from fastapi import APIRouter
from model import ImageBase64
router = APIRouter(
prefix="/ocr",
tags=["ocr"],
)
@router.get("/status")
async def get_status():
return {"message": "ok"}
@router.get("/text")
async def get_text():
return {"message": "ok"}
@router.post("/img")
async def create_item(img: ImageBase64):
return {"message": "ok"}
В файле ocr.py у нас есть маршрутизатор, который содержит три конечные точки: GET /ocr/status, GET /ocr/text и Конечная точка POST ocr/img. Кроме того, мы импортируем модель данных для конечной точки POST. Я определил простую логику для проверки конечных точек. Мы можем запустить нашу службу через cmd.exe.
«uvicorn app.main:app –reload»
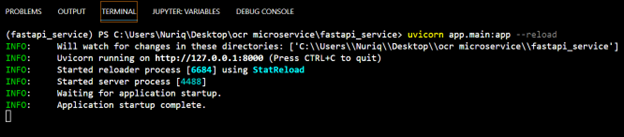
Uvicorn — это реализация веб-сервера ASGI для Python. Он запускает файл main.py. – reload означает, что если мы изменим код внутри файлов, uvicorn автоматически перезапустит новый код.
Базовое тестирование.
Для тестирования конечных точек мы будем использовать thunder client в VS Code. Сначала мы проверим наши конечные точки. GET http://127.0.0.1:8000 и GET http://127.0.0.1:8000/api/v1/ocr/status конечной точки.
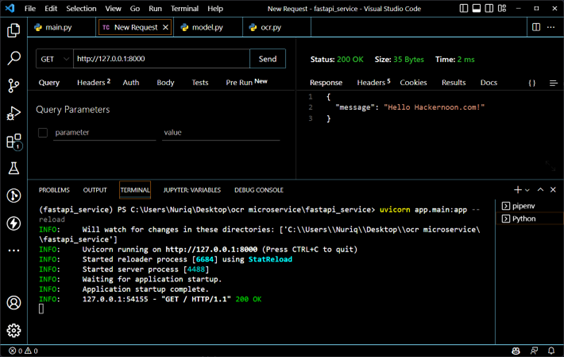
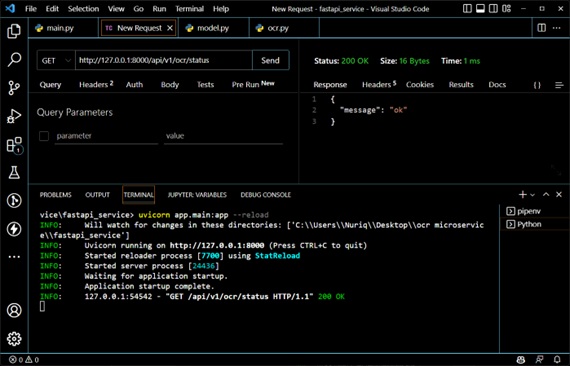
Оба работают нормально, теперь нам нужно написать логику. Мы получим наше изображение в формате строки base64 и получим сгенерированный task_id. Используя этот task_id, мы перейдем к GET /ocr/status и получим наш статус обработки OCR, у нас будет три типа статуса: ожидание, успех и ошибка. После получения статуса успеха мы получим текст из конечной точки GET /ocr/text, используя наш task_id.
Чтобы получить статус и отслеживать его, мы будем использовать пакет redis. Для выполнения параллельного процесса мы будем использовать пакет celery. Давайте установим докер и напишем код.
Установка Docker.
Перейдите на https://www.docker.com/ и установите Docker Desktop. После установки, если вы работаете в Windows, вам также необходимо установить пакет wsl и получить образ системы Linux. Подробные инструкции описаны по адресу https://docs.docker.com/desktop/install/windows-install/.
После успешной установки запустите docker desktop, и вы увидите это окно.
Настройка контейнера FastAPI.
Теперь нам нужно создать Dockerfile, в котором будут все необходимые команды docker для запуска нашей службы fastAPI внутри docker< /code> среда.
FROM python:3.11
WORKDIR /app
RUN apt-get update && apt-get install -y && apt-get clean
RUN pip install –upgrade pip
COPY ./requirements.txt .
RUN pip install -r requirements.txt && rm -rf /root/.cache/pip
COPY . .
Короче говоря, мы создаем рабочий каталог с именем «app» и помещаем в него requirements.txt, устанавливая все пакеты из этого файла с помощью python 3.11. После всего удаляем кешированные данные pip и копируем все наши файлы в рабочий каталог внутри контейнера. Итак, наш первый контейнер с точкой входа готов. Теперь нам нужно создать еще один файл — docker-compose.yml. Вкратце, это простой файл, содержащий все команды Docker, которые создают, развертывают и выполняют все контейнеры вместе с помощью простой однострочной команды.
version: '3.8'
services:
web:
build: ./fastapi_service
ports:
- 8001:8000
command: uvicorn app.main:app --host 0.0.0.0 –reload
Теперь у нас есть обновленная структура проекта.
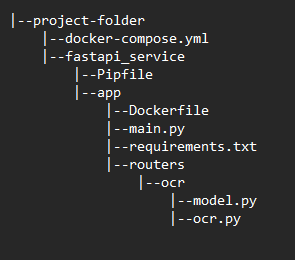
Мы готовы разместить вашу первую службу fastAPI в контейнере. Для этого нам нужно написать команды docker-compose. Он создает и запускает все контейнеры.
Запустите cmd.exe в папке, содержащей файл docker-compose.yml, с помощью команды docker-compose up --build и посмотрите .
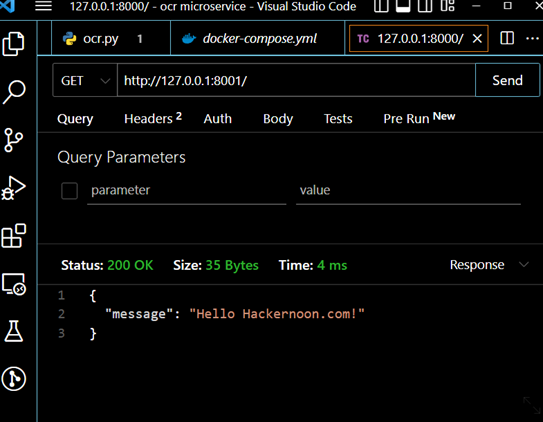
Теперь наша служба fastAPI работает внутри докера. Мы изменили номер порта на 8001 с помощью файла docker-compose.
Все построить.
Сначала клонируйте https://github.com/abizovnuralem/ocr.. Вы увидите эту структуру проекта.
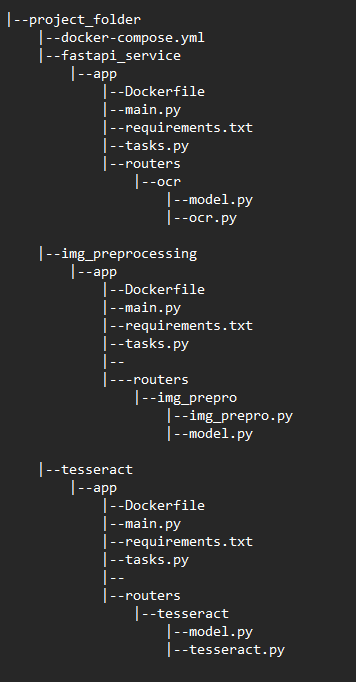
Я разделил каждое приложение на собственную папку с собственным экземпляром celery и redis. Я решил использовать 3 экземпляра redis и celery, чтобы сделать каждый микросервис независимым. Эти приложения имеют собственный dockerfile, куда мы устанавливаем виртуальную систему и все необходимые пакеты из requirements.txt. Каждое приложение содержит файл main.py, собственную точку входа и tasks.py, где мы выполняем задачи сельдерея. Папка routers содержит конечные точки, которые помогают обмениваться данными между контейнерами по протоколу REST API.
Служба FastAPI.
Основная логика всех наших сервисов находится в файле fastapi_service/app/tasks.py. Он координирует все процессы, получает изображения, выполняет некоторую предварительную обработку и запускает процесс распознавания тессеракта.
import os
import time
import requests
import json
from routers.ocr.model import PreProsImgResponse
from celery import Celery
app = Celery('tasks', broker=os.environ.get("CELERY_BROKER_URL"))
def check_until_done(url):
attempts = 0
while True:
response = requests.get(url)
if response.status_code == 200 and response.json()['task_status'] == "PENDING" and attempts < 60:
time.sleep(1)
attempts+=1
elif response.status_code == 200 and response.json()['task_status'] == "SUCCESS":
return True
else:
return False
def convert_img_to_bin(img):
response = requests.post(url = "http://img_prepro:8000/api/v1/img_prep/img", json={"img_body_base64": img})
task = response.json()
if check_until_done("http://img_prepro:8000/api/v1/img_prep/status" + f"/{task['task_id']}"):
url = "http://img_prepro:8000/api/v1/img_prep/img" + f"/{task['task_id']}"
response = requests.get(url)
return response.json()['img']
raise Exception("Sorry, something went wrong")
def get_ocr_text(img):
response = requests.post(url = "http://tesseract:8000/api/v1/tesseract/img", json={"img_body_base64": img})
task = response.json()
if check_until_done("http://tesseract:8000/api/v1/tesseract/status" + f"/{task['task_id']}"):
url = "http://tesseract:8000/api/v1/tesseract/text" + f"/{task['task_id']}"
response = requests.get(url)
return response.json()['text']
raise Exception("Sorry, something went wrong")
@app.task(name="create_task")
def create_task(img: str):
try:
bin_img = convert_img_to_bin(img)
text = get_ocr_text(bin_img)
return text
except Exception as e:
print(e)
return {"text": "error"}
Мы используем всего две строки кода, чтобы выполнить все в нашем сервисе.
bin_img = convert_img_to_bin(img)
текст = get_ocr_text(bin_img)
Он выполняет некоторую предварительную обработку изображений, которая помогает tesseract распознавать изображения более точно и быстрее через REST API с помощью микросервиса img_prepro, и запускает механизм tesseract внутри tesseract_service через REST API и получает окончательные результаты.
Тестирование.
Для тестирования мы будем использовать это изображение.

Во-первых, нам нужно преобразовать его в строку base64. Мы собираемся использовать https://codebeautify.org/image-to-base64-converter, чтобы получить строку изображения, а затем с помощью POST /http://localhost:8001/api. /v1/ocr/img мы получим task_id.
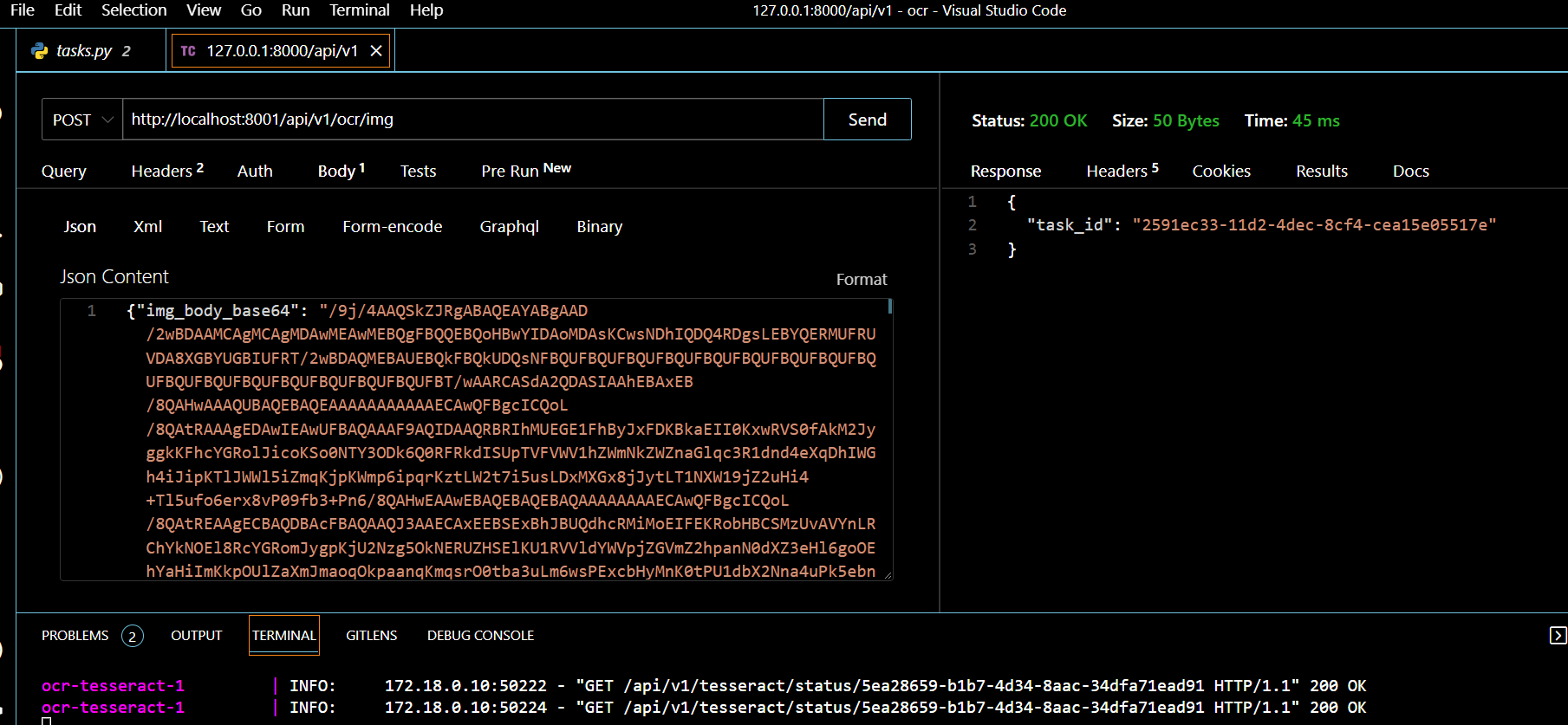
Используя GET /http://localhost:8001/api/v1/ocr/status/2591ec33-11d2-4dec-8cf4-cea15e05517e
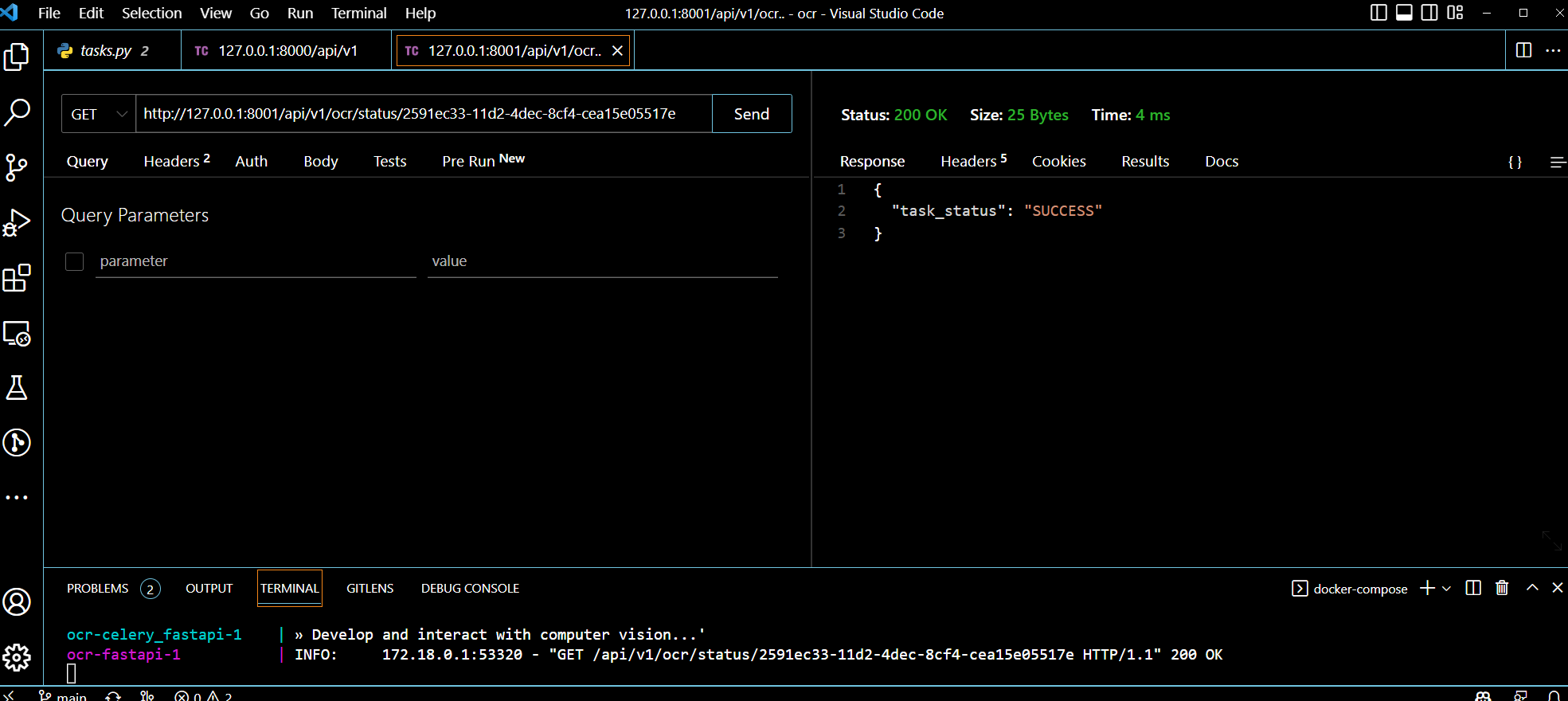
мы следим за статусом выполнения задачи, после получения статуса SUCCESS мы получим текст от
GET /http://localhost:8001/api/v1/ocr/text/2591ec33-11d2-4dec-8cf4-cea15e05517e
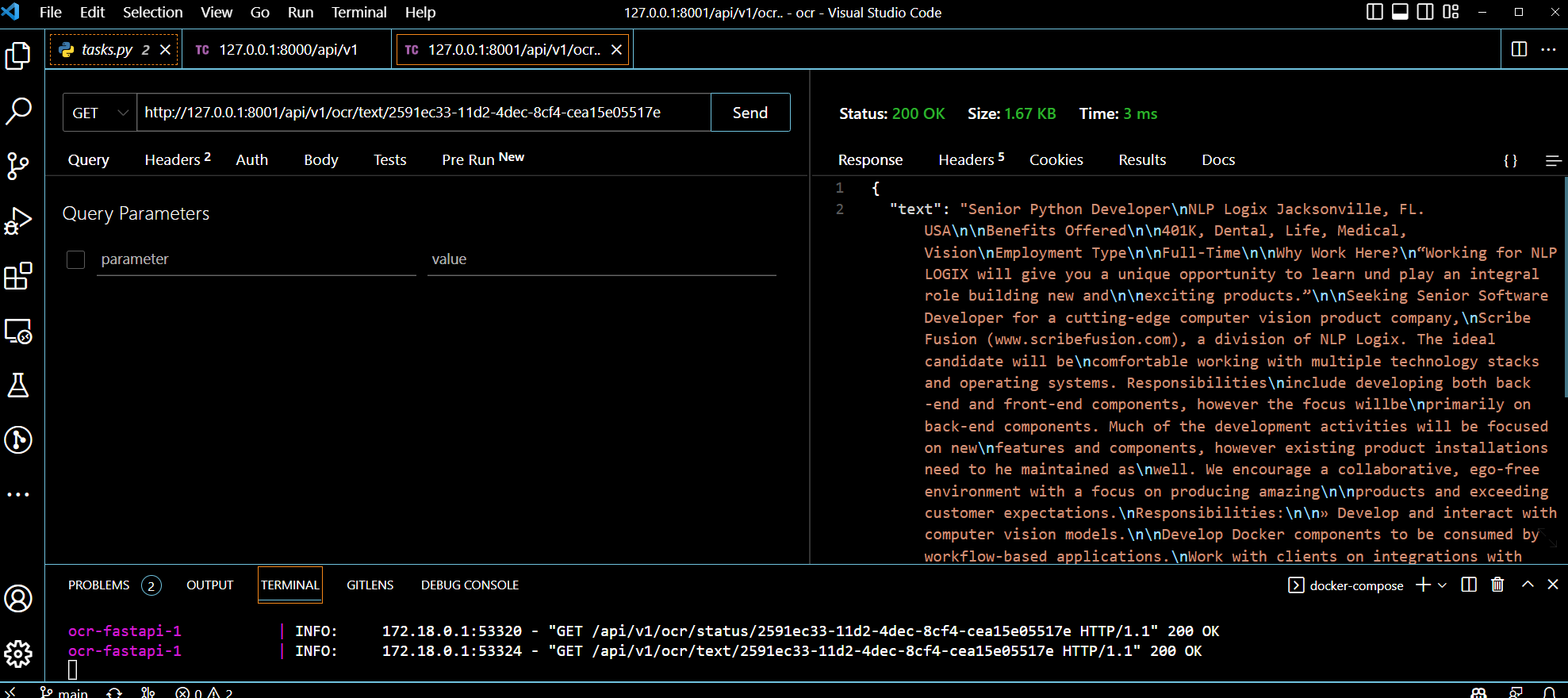
Заключение
Мы создали 9 микросервисов в одном сервисе OCR. Настройте все контейнеры для запуска и взаимодействия друг с другом. Некоторые вещи, которые нам нужно сделать в ближайшем будущем:
- Ведение журнала;
- Тестирование;
- Мониторинг;
- Улучшить распознавание OCR;
Основная идея этой статьи состояла в том, чтобы показать вам, как создать простую микросервисную архитектуру, которая выполняет базовое распознавание OCR. Спасибо за внимание!
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27211)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)