
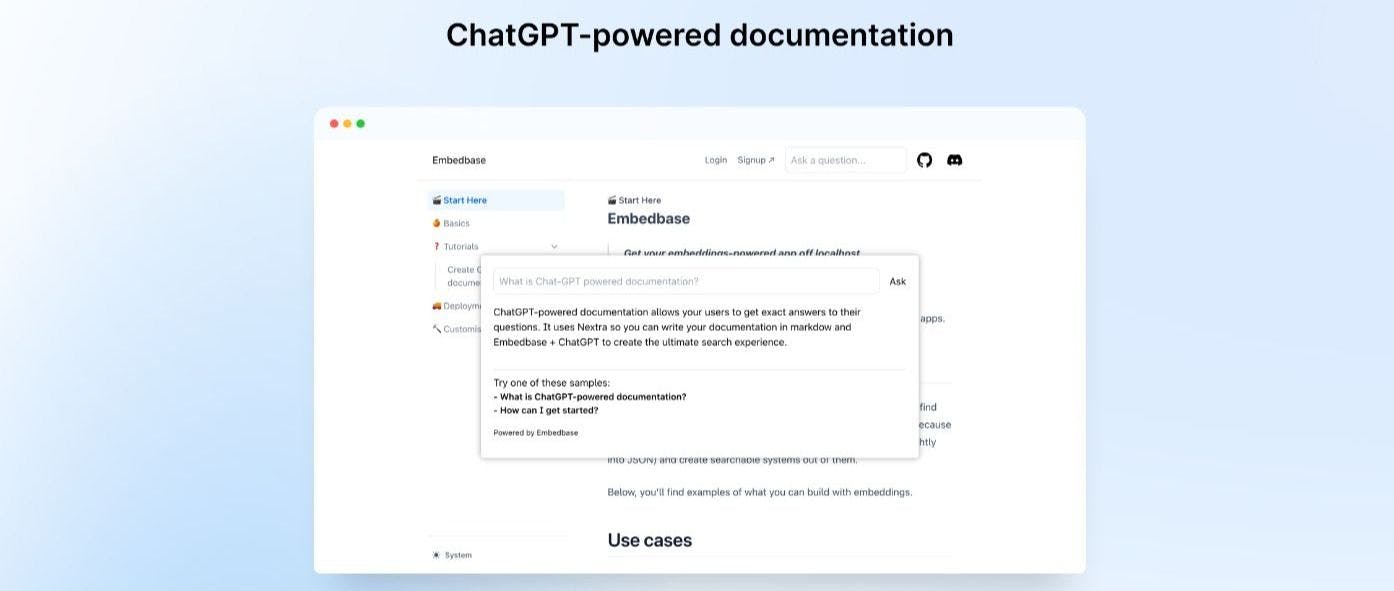
Создание документации Markdown на основе ChatGPT
15 марта 2023 г.Сегодня мы узнаем, как построить систему, которая требует ChatGPT задает вопросы и получает точные ответы о документации. Весь создаваемый проект доступен здесь.
Вы также можете попробовать интерактивную версию.
https://www.youtube.com/watch?v=-9jL9r9QQm0&embedable=true
Обзор
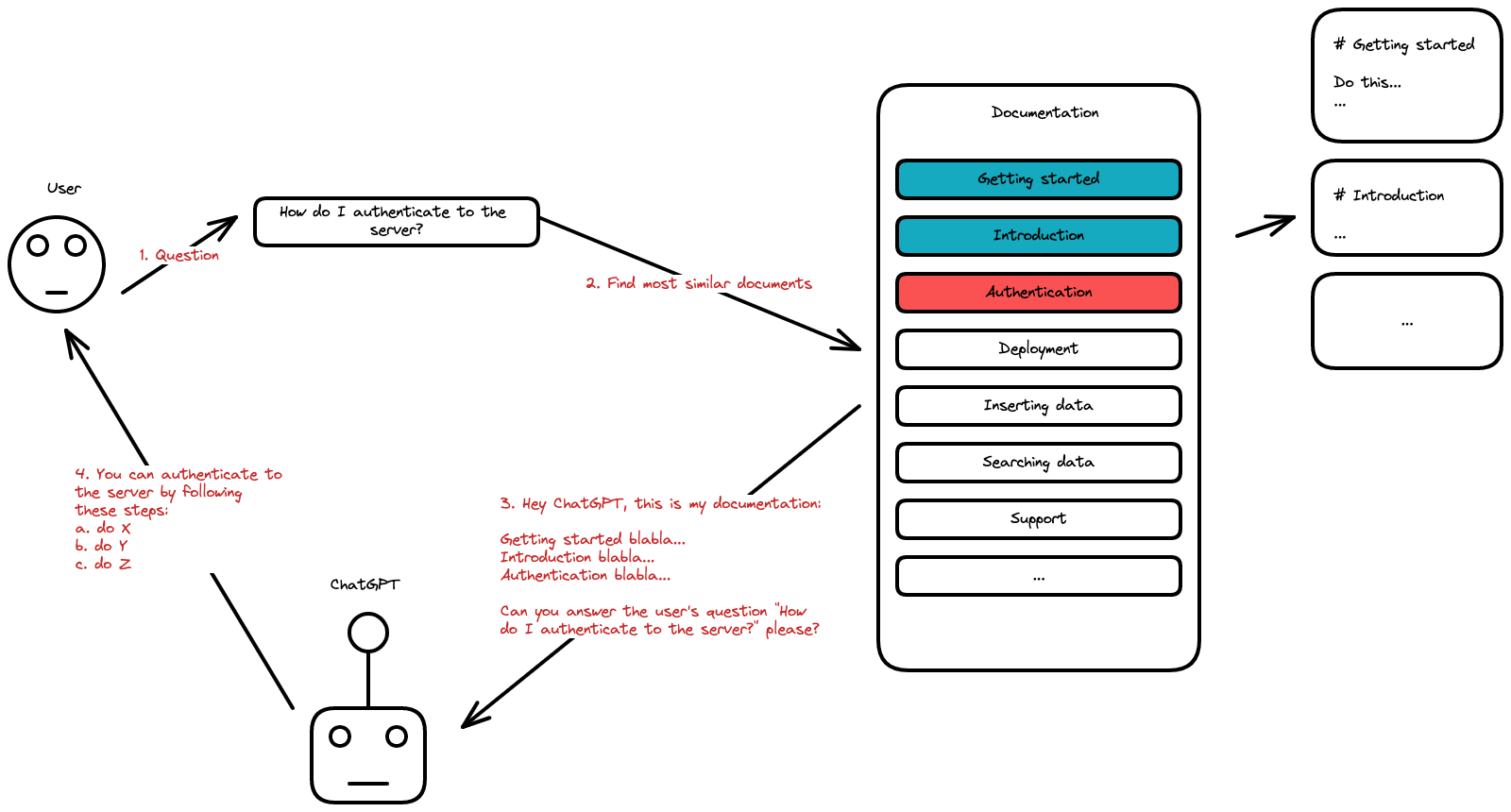
Здесь мы рассмотрим несколько вещей, но общая картина такова:
- Нам нужно сохранить наш контент в базе данных
- Мы попросим пользователя ввести запрос
- Мы будем искать в базе данных результаты, наиболее похожие на запрос пользователя (подробнее об этом позже)
- Мы создадим «контекст» на основе пяти наиболее похожих результатов, соответствующих запросу, и запросим ChatGPT.
Answer the question based on the context below, and if the question can't be answered based on the context, say "I don't know"
Context:
[CONTEXT]
---
Question:
[QUESTION]
Answer:
Погружение в реализацию
Хорошо, приступим
Вот что вам понадобится для этого урока:
* База данных, позволяющая найти «наиболее похожие результаты». Не все базы данных подходят для такой работы. Сегодня мы будем использовать Embedbase, который позволит вам это сделать. Embedbase позволяет найти «семантическое сходство» между поисковым запросом и сохраненным содержимым. * Ключ OpenAI API: для части ChatGPT. * Nextra: NodeJS установлен.
Запишите ключи API Embedbase и OpenAI в .env:
OPENAI_API_KEY="<YOUR KEY>"
EMBEDBASE_API_KEY="<YOUR KEY>"
Напоминаем, что мы будем создавать документацию по контролю качества на базе ChatGPT с помощью замечательной среды документации Nextra, которая позволяет писать документацию с использованием NextJS, tailwindcss и MDX (Markdown + React). Мы также будем использовать Embedbase в качестве базы данных вместе с OpenAI для использования ChatGPT.
Создание документа Nextra
Вы можете найти и использовать официальный шаблон документации Nextra здесь. Создав документацию с помощью этого шаблона, откройте ее в своем любимом редакторе.
# we won't use "pnpm" here, rather the traditional "npm"
rm pnpm-lock.yaml
npm i
npm run dev
Теперь просто перейдите здесь.
Попробуйте отредактировать некоторые документы .mdx и посмотрите, как изменится содержимое.
Подготовка и хранение документов
На первом этапе нам нужно сохранить нашу документацию в Embedbase. Однако есть небольшая оговорка: это работает лучше, если мы храним относительно небольшие фрагменты в БД. Мы разобьем наш текст на предложения.
Давайте начнем с написания скрипта с именем sync.js в папке scripts. Вам понадобится библиотека glob для списка файлов npm i glob@8.1.0 (мы будем использовать версию 8.1.0).
const glob = require("glob");
const fs = require("fs");
const sync = async () => {
// 1. read all files under pages/* with .mdx extension
// for each file, read the content
const documents = glob.sync("pages/**/*.mdx").map((path) => ({
// we use as id /{pagename} which could be useful to
// provide links in the UI
id: path.replace("pages/", "/").replace("index.mdx", "").replace(".mdx", ""),
// content of the file
data: fs.readFileSync(path, "utf-8")
}));
// 2. here we split the documents in chunks, you can do it in many different ways, pick the one you prefer
// split documents into chunks of 100 lines
const chunks = [];
documents.forEach((document) => {
const lines = document.data.split("n");
const chunkSize = 100;
for (let i = 0; i < lines.length; i += chunkSize) {
const chunk = lines.slice(i, i + chunkSize).join("n");
chunks.push({
// and use id like path/chunkIndex
id: document.id + "/" + i,
data: chunk
});
}
});
}
sync();
Теперь, когда у нас есть фрагменты, которые нужно сохранить в БД, мы расширим наш скрипт, чтобы он добавлял фрагменты в Embedbase.
Чтобы запросить Embedbase, мы установим версию 2.6.9 node-fetch, запустив npm i node-fetch@2.6.9.
const fetch = require("node-fetch");
// your Embedbase api key
const apiKey = process.env.EMBEDBASE_API_KEY;
const sync = async () => {
// ...
// 3. we then insert the data in Embedbase
const response = await fetch("https://embedbase-hosted-usx5gpslaq-uc.a.run.app/v1/documentation", { // "documentation" is your dataset ID
method: "POST",
headers: {
"Authorization": "Bearer " + apiKey,
"Content-Type": "application/json"
},
body: JSON.stringify({
documents: chunks
})
});
const data = await response.json();
console.log(data);
}
sync();
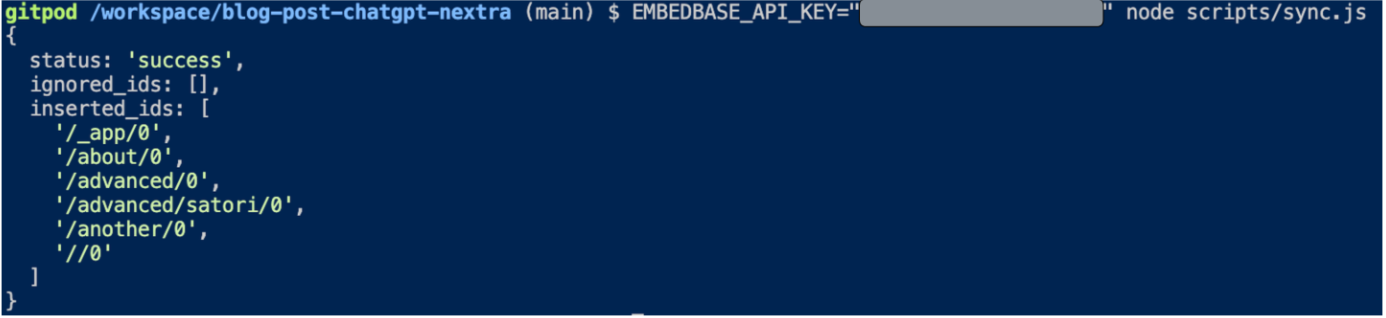
Отлично, теперь вы можете запустить его:
EMBEDBASE_API_KEY="<YOUR API KEY>" node scripts/sync.js
Если это сработало, вы должны увидеть:
Получение запроса пользователя
Теперь мы изменим тему документации Nextra, чтобы заменить встроенную панель поиска на ту, которая будет работать на базе ChatGPT.
Мы добавим компонент Modal в theme.config.tsx со следующим содержимым:
// update the imports
import { DocsThemeConfig, useTheme } from 'nextra-theme-docs'
const Modal = ({ children, open, onClose }) => {
const theme = useTheme();
if (!open) return null;
return (
<div
style={{
position: 'fixed',
top: 0,
left: 0,
right: 0,
bottom: 0,
backgroundColor: 'rgba(0,0,0,0.5)',
zIndex: 100,
}}
onClick={onClose}>
<div
style={{
position: 'absolute',
top: '50%',
left: '50%',
transform: 'translate(-50%, -50%)',
backgroundColor: theme.resolvedTheme === 'dark' ? '#1a1a1a' : 'white',
padding: 20,
borderRadius: 5,
width: '80%',
maxWidth: 700,
maxHeight: '80%',
overflow: 'auto',
}}
onClick={(e) => e.stopPropagation()}>
{children}
</div>
</div>
);
};
Теперь мы хотим создать панель поиска:
// update the imports
import React, { useState } from 'react'
// we create a Search component
const Search = () => {
const [open, setOpen] = useState(false);
const [question, setQuestion] = useState("");
// ...
// All the logic that we will see later
const answerQuestion = () => { }
// ...
return (
<>
<input
placeholder="Ask a question"
// We open the modal here
// to let the user ask a question
onClick={() => setOpen(true)}
type="text"
/>
<Modal open={open} onClose={() => setOpen(false)}>
<form onSubmit={answerQuestion} className="nx-flex nx-gap-3">
<input
placeholder="Ask a question"
type="text"
value={question}
onChange={(e) => setQuestion(e.target.value)}
/>
<button type="submit">
Ask
</button>
</form>
</Modal>
</>
);
}
Наконец, обновите конфигурацию, чтобы установить панель поиска, которую мы создали:
const config: DocsThemeConfig = {
logo: <span>My Project</span>,
project: {
link: 'https://github.com/shuding/nextra-docs-template',
},
chat: {
link: 'https://discord.com',
},
docsRepositoryBase: 'https://github.com/shuding/nextra-docs-template',
footer: {
text: 'Nextra Docs Template',
},
// add this to use our Search component
search: {
component: <Search />
}
}
Создание контекста
Здесь вам понадобится библиотека для подсчета токенов OpenAI tiktoken, поэтому запустите npm i @dqbd/tiktoken.
Теперь мы собираемся создать приглашение для контекстуализации ChatGPT в конечной точке API NextJS.
Создайте файл pages/api/buildPrompt.ts с кодом:
// pages/api/buildPrompt.ts
import { get_encoding } from "@dqbd/tiktoken";
// Load the tokenizer which is designed to work with the embedding model
const enc = get_encoding('cl100k_base');
const apiKey = process.env.EMBEDBASE_API_KEY;
// this is how you search Embedbase with a string query
const search = async (query: string) => {
return fetch("https://embedbase-hosted-usx5gpslaq-uc.a.run.app/v1/documentation/search", {
method: "POST",
headers: {
Authorization: "Bearer " + apiKey,
"Content-Type": "application/json"
},
body: JSON.stringify({
query: query
})
}).then(response => response.json());
};
const createContext = async (question: string, maxLen = 1800) => {
// get the similar data to our query from the database
const searchResponse = await search(question);
let curLen = 0;
const returns = [];
// We want to add context to some limit of length (tokens)
// because usually LLM have limited input size
for (const similarity of searchResponse["similarities"]) {
const sentence = similarity["data"];
// count the tokens
const nTokens = enc.encode(sentence).length;
// a token is roughly 4 characters, to learn more
// https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
curLen += nTokens + 4;
if (curLen > maxLen) {
break;
}
returns.push(sentence);
}
// we join the entries we found with a separator to show it's different
return returns.join("nn###nn");
}
// this is the endpoint that returns an answer to the client
export default async function buildPrompt(req, res) {
const prompt = req.body.prompt;
const context = await createContext(prompt);
const newPrompt = `Answer the question based on the context below, and if the question can't be answered based on the context, say "I don't know"nnContext: ${context}nn---nnQuestion: ${prompt}nAnswer:`;
res.status(200).json({ prompt: newPrompt });
}
Вызов ChatGPT
Во-первых, добавьте служебную функцию, которая используется для выполнения потоковых вызовов OpenAI, в файл utils/OpenAIStream.ts. Вам потребуется установить eventsource-parser. запустив npm i eventsource-parser.
import {
createParser,
ParsedEvent,
ReconnectInterval,
} from "eventsource-parser";
export interface OpenAIStreamPayload {
model: string;
// this is a list of messages to give ChatGPT
messages: { role: "user"; content: string }[];
stream: boolean;
}
export async function OpenAIStream(payload: OpenAIStreamPayload) {
const encoder = new TextEncoder();
const decoder = new TextDecoder();
let counter = 0;
const res = await fetch("https://api.openai.com/v1/chat/completions", {
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${process.env.OPENAI_API_KEY ?? ""}`,
},
method: "POST",
body: JSON.stringify(payload),
});
const stream = new ReadableStream({
async start(controller) {
// callback
function onParse(event: ParsedEvent | ReconnectInterval) {
if (event.type === "event") {
const data = event.data;
// https://beta.openai.com/docs/api-reference/completions/create#completions/create-stream
if (data === "[DONE]") {
controller.close();
return;
}
try {
const json = JSON.parse(data);
// get the text response from ChatGPT
const text = json.choices[0]?.delta?.content;
if (!text) return;
if (counter < 2 && (text.match(/n/) || []).length) {
// this is a prefix character (i.e., "nn"), do nothing
return;
}
const queue = encoder.encode(text);
controller.enqueue(queue);
counter++;
} catch (e) {
// maybe parse error
controller.error(e);
}
}
}
// stream response (SSE) from OpenAI may be fragmented into multiple chunks
// this ensures we properly read chunks and invoke an event for each SSE event stream
const parser = createParser(onParse);
// https://web.dev/streams/#asynchronous-iteration
for await (const chunk of res.body as any) {
parser.feed(decoder.decode(chunk));
}
},
});
return stream;
}
Затем создайте файл pages/api/qa.ts, который будет конечной точкой для простого потокового вызова ChatGPT.
// pages/api/qa.ts
import { OpenAIStream, OpenAIStreamPayload } from "../../utils/OpenAIStream";
export const config = {
// We are using Vercel edge function for this endpoint
runtime: "edge",
};
interface RequestPayload {
prompt: string;
}
const handler = async (req: Request, res: Response): Promise<Response> => {
const { prompt } = (await req.json()) as RequestPayload;
if (!prompt) {
return new Response("No prompt in the request", { status: 400 });
}
const payload: OpenAIStreamPayload = {
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: prompt }],
stream: true,
};
const stream = await OpenAIStream(payload);
return new Response(stream);
};
export default handler;
Подключите все и amp; Задавать вопросы
Пришло время задавать вопросы через вызовы API.
Отредактируйте theme.config.tsx, чтобы добавить функцию в компонент Search:
// theme.config.tsx
const Search = () => {
const [open, setOpen] = useState(false);
const [question, setQuestion] = useState("");
const [answer, setAnswer] = useState("");
const answerQuestion = async (e: any) => {
e.preventDefault();
setAnswer("");
// build the contextualized prompt
const promptResponse = await fetch("/api/buildPrompt", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
prompt: question,
}),
});
const promptData = await promptResponse.json();
// send it to ChatGPT
const response = await fetch("/api/qa", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
prompt: promptData.prompt,
}),
});
if (!response.ok) {
throw new Error(response.statusText);
}
const data = response.body;
if (!data) {
return;
}
const reader = data.getReader();
const decoder = new TextDecoder();
let done = false;
// read the streaming ChatGPT answer
while (!done) {
const { value, done: doneReading } = await reader.read();
done = doneReading;
const chunkValue = decoder.decode(value);
// update our interface with the answer
setAnswer((prev) => prev + chunkValue);
}
};
return (
<>
<input
placeholder="Ask a question"
onClick={() => setOpen(true)}
type="text"
/>
<Modal open={open} onClose={() => setOpen(false)}>
<form onSubmit={answerQuestion} className="nx-flex nx-gap-3">
<input
placeholder="Ask a question"
type="text"
value={question}
onChange={(e) => setQuestion(e.target.value)}
/>
<button type="submit">
Ask
</button>
</form>
<p>
{answer}
</p>
</Modal>
</>
);
}
У вас уже должно быть это:

Конечно, смело улучшайте стиль 😁.
Заключительные мысли
Итак, у нас есть:
- Создал документацию Nextra
- Подготовка и хранение наших документов в Embedbase
- Создал интерфейс для получения запроса пользователя.
- Поиск контекста вопроса в нашей базе данных для предоставления ChatGPT.
- Создайте приглашение с этим контекстом и вызовите ChatGPT
- Позвольте пользователю задать вопрос, соединив все вместе
Спасибо, что прочитали этот документ, есть шаблон с открытым исходным кодом для создания документации такого типа здесь .
Дополнительная литература
Внедрение – это концепция машинного обучения, которая позволяет вам представлять семантику ваших данных в виде числа, что позволяет создавать такие функции, как:
* семантический поиск (например, в чем сходство между «корова ест траву» и «обезьяна ест бананы», который также работает для сравнения изображений и т. д.) * системы рекомендаций (если вам нравится фильм «Аватар», вам могут понравиться «Звездные войны») * классификация («этот фильм потрясающий» — положительное предложение, «этот фильм — отстой» — отрицательное предложение) * генеративный поиск (чат-бот, который отвечает на вопросы о PDF, веб-сайте, видео на YouTube и т. д.)
Внедрение — не новая технология, но в последнее время оно стало более популярным, более универсальным и более доступным благодаря быстрой и дешевой конечной точке встраивания OpenAI. Не будем углубляться в техническую тему встраивания, о них много информации в интернете.
Вложения ИИ можно рассматривать как сортировочную шляпу Гарри Поттера. Точно так же, как сортировочная шляпа распределяет дома на основе характеристик учеников, встраивания ИИ назначаются аналогичному контенту на основе их характеристик. Когда мы хотим найти похожие элементы, мы можем попросить ИИ предоставить нам вложения элементов, а затем вычислить расстояние между ними.
Чем ближе расстояние между встраиваниями, тем более похожи предметы. Этот процесс похож на то, как распределяющая шляпа использует черты каждого ученика, чтобы определить, кто лучше всего подходит для дома. Благодаря внедрению искусственного интеллекта мы можем быстро и легко сравнивать элементы на основе их характеристик, что приводит к более взвешенным решениям и более эффективным результатам поиска.
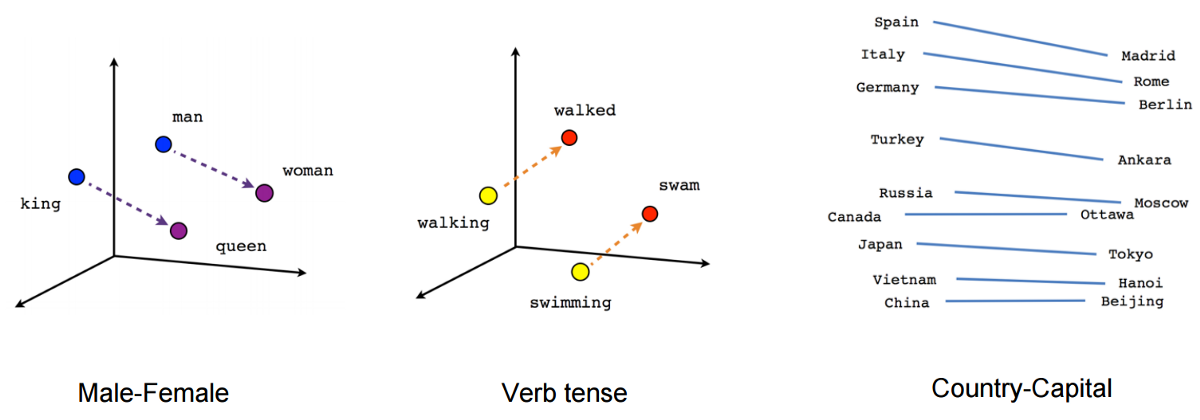
Описанный выше метод заключается в простом встраивании слов, но сегодня возможны предложения, изображения, предложения + изображения и многое другое.
Если вы хотите использовать встраивания в производственном программном обеспечении, нужно быть осторожным с некоторыми подводными камнями:
* Вся информация о хранении вложений в масштабе * Оптимизация затрат (например, избегайте двойного расчета данных) * Сегментация пользовательских вложений (вы не хотите, чтобы ваша функция поиска отображала данные другого пользователя) * Работа с ограничением размера входных данных модели * Интеграция с популярными инфраструктурами приложений (supabase, firebase, google cloud и т. д.)
Непрерывная подготовка данных в GitHub Actions
Суть встраивания в том, чтобы иметь возможность индексировать любые неструктурированные данные, мы хотим, чтобы наша документация индексировалась каждый раз, когда мы ее модифицируем, верно?
Это действие GitHub, которое будет индексировать каждый файл уценки, когда git push выполняется в ветке main:
# .github/workflows/index.yaml
name: Index documentation
on:
push:
branches:
- main
jobs:
index:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v2
with:
node-version: 14
- run: npm install
- run: node scripts/sync.js
env:
EMBEDBASE_API_KEY: ${{ secrets.EMBEDBASE_API_KEY }}
Не забудьте добавить EMBEDBASE_API_KEY в свои секреты GitHub< /а>.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27142)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)