

Создайте приложение для очистки данных с помощью Puppeteer, Node.js, PostgreSQL и Aptible.
22 января 2024 г.Создание приложения для очистки данных является обычным делом для многих разработчиков, особенно в областях, где сбор, анализ и хранение данных имеют решающее значение. Использование трио Puppeteer, Node.js и PostgreSQL — отличный подход.
Puppeteer — отличный выбор для этой задачи. Он позволяет вам управлять автономным браузером, что имеет решающее значение для очистки динамических веб-сайтов. Многие веб-сайты теперь используют JavaScript для загрузки контента, а Puppeteer позволяет вам взаимодействовать с этим динамическим контентом и очищать его.
Node.js хорошо подходит для создания масштабируемых и эффективных серверных приложений. Он неблокирующий и управляемый событиями, что делает его хорошо подходящим для обработки одновременных запросов в приложении для очистки данных. Node.js будет обрабатывать серверную часть приложения для очистки данных.
Хранением очищенных данных для приложения будет заниматься PostgreSQL, поскольку он поддерживает сложные запросы и индексирование, что делает его подходящим для хранения и эффективное получение очищенных данных.
Aptible — поставщик PaaS, который помогает безопасно развертывать приложения. Он также предоставляет услуги управления базами данных, причем PostgreSQL является одной из поддерживаемых баз данных. Следовательно, в этом проекте будет использоваться управляемый сервис PostgreSQL, предоставляемый Aptible.
В этом руководстве вы узнаете, как создать приложение для очистки данных с помощью Puppeteer, Node.js, PostgreSQL и Aptible. Приложение будет собирать данные из популярного приложения для потоковой передачи фильмов Netflix и сохранять их в базе данных PostgreSQL, управляемой Aptible.
Предварительные условия
Чтобы следовать этому руководству, вам понадобится следующее:
* На вашем компьютере установлена версия узла 16.13.2 или выше. Его можно установить, следуя инструкциям на официальном сайте Node.js.
* Аккаунт Aptible. Посетите веб-сайт Aptible, чтобы зарегистрироваться.
* Фундаментальное понимание JavaScript и Node.js.
Настройка проекта
Для начала создайте новый каталог для проекта и инициализируйте в нем новый проект Node.js, выполнив следующие команды:
mkdir web-scraper
cd web-scraper
npm init -y
При этом будет создан файл package.json со следующим выводом:
Wrote to /home/user/web-scraper/package.json:
{
"name": "web-scraper",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Установка зависимостей
Чтобы установить зависимости проекта, выполните следующую команду:
npm install puppeteer pg dotenv
При этом будут установлены необходимые пакеты: Puppeteer, Node-postgres и dotenv.
Создание базы данных
Для базы данных PostgreSQL вы будете использовать службу управляемой базы данных в Aptible. Для этого выполните следующие действия:
- Войдите в свою учетную запись Aptible и создайте новую среду.
- Перейдите к созданной вами базе данных и нажмите Конечные точки > Новая конечная точка.
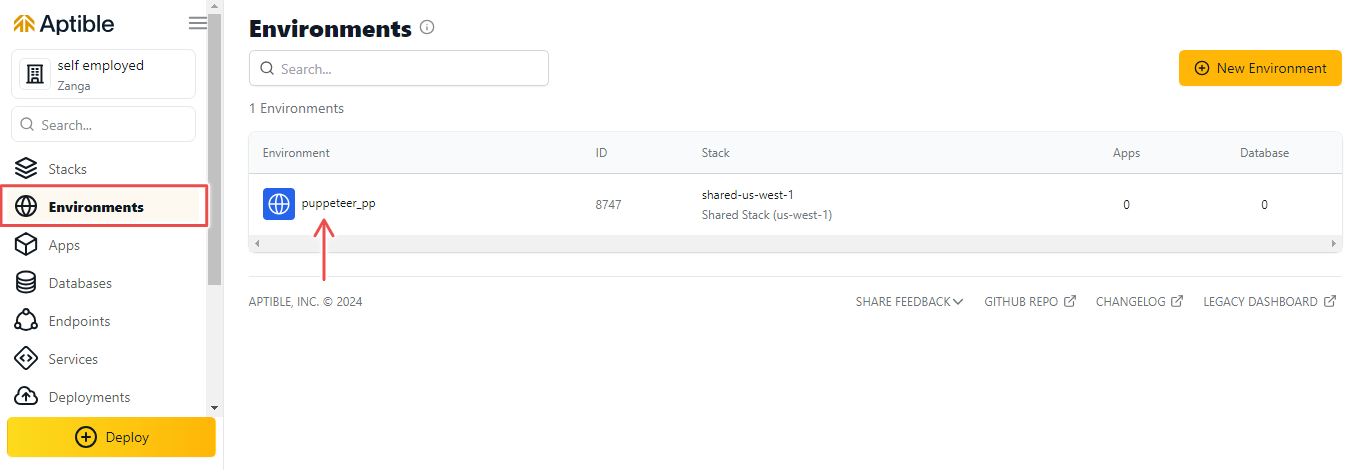
2. Перейдите в новую среду и нажмите Базы данных > Новая база данных.
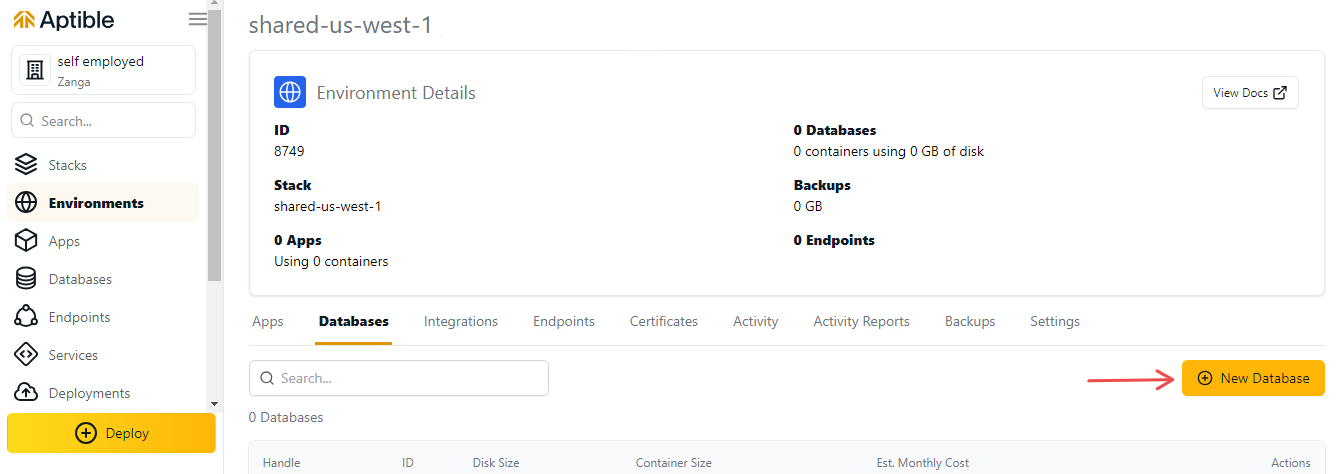
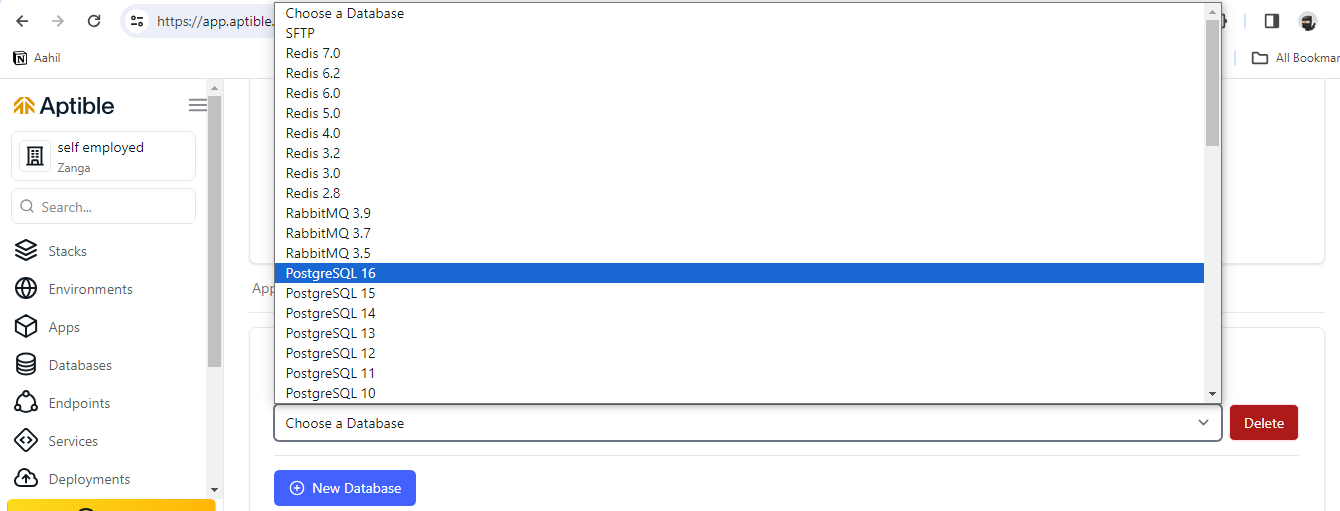
3. Нажмите раскрывающееся меню и выберите PostgreSQL 16. Это создаст для вас новую базу данных PostgreSQL.
4. Введите дескриптор базы данных и нажмите Новая база данных, чтобы создать базу данных.
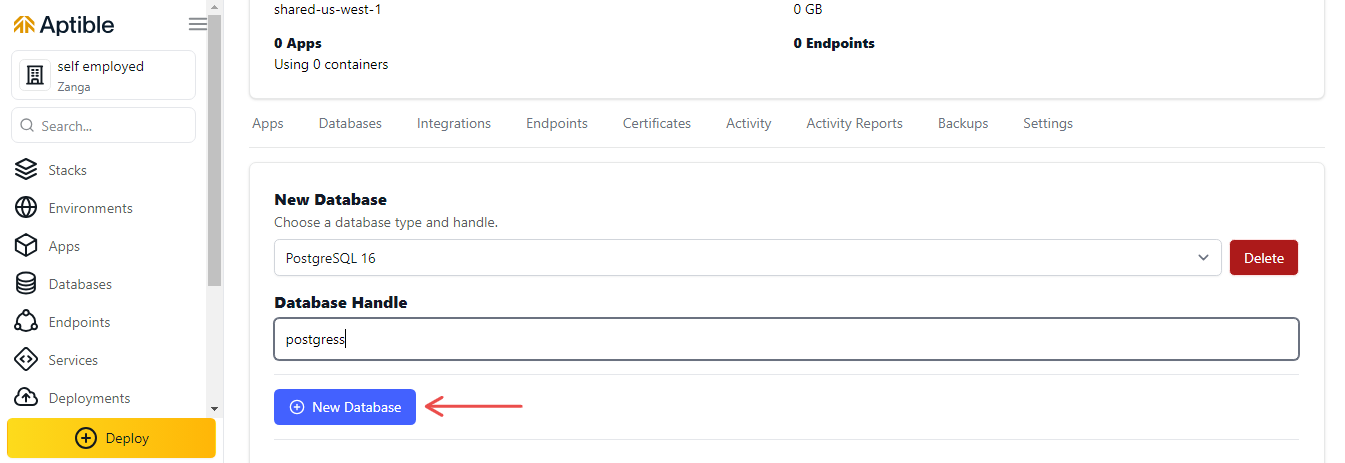
Это предоставит вам новую базу данных PostgreSQL.
Вы можете просмотреть базу данных, нажав вкладку Базы данных в меню слева.
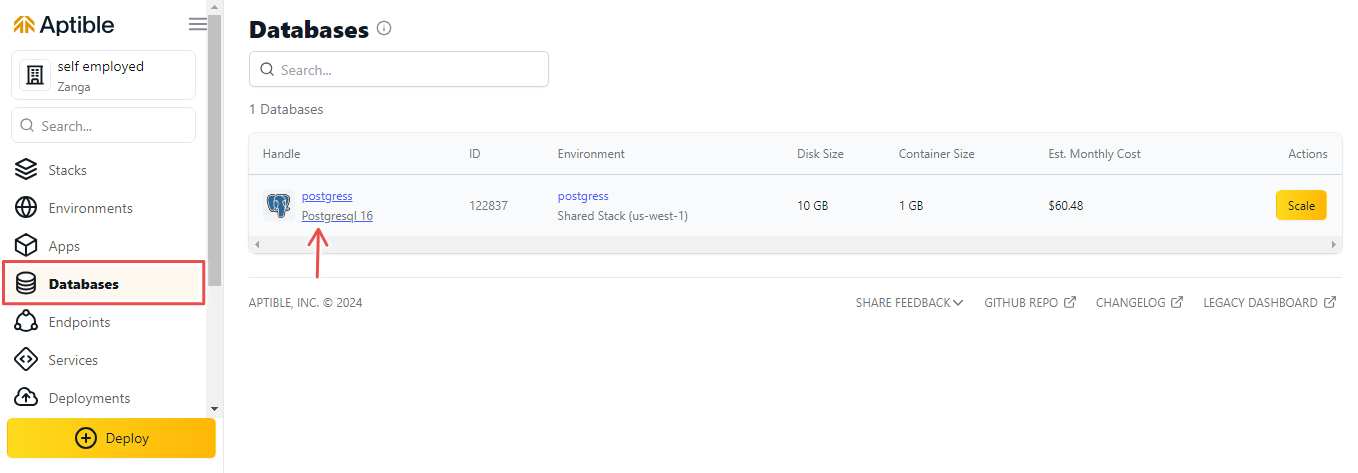
Создание конечной точки базы данных
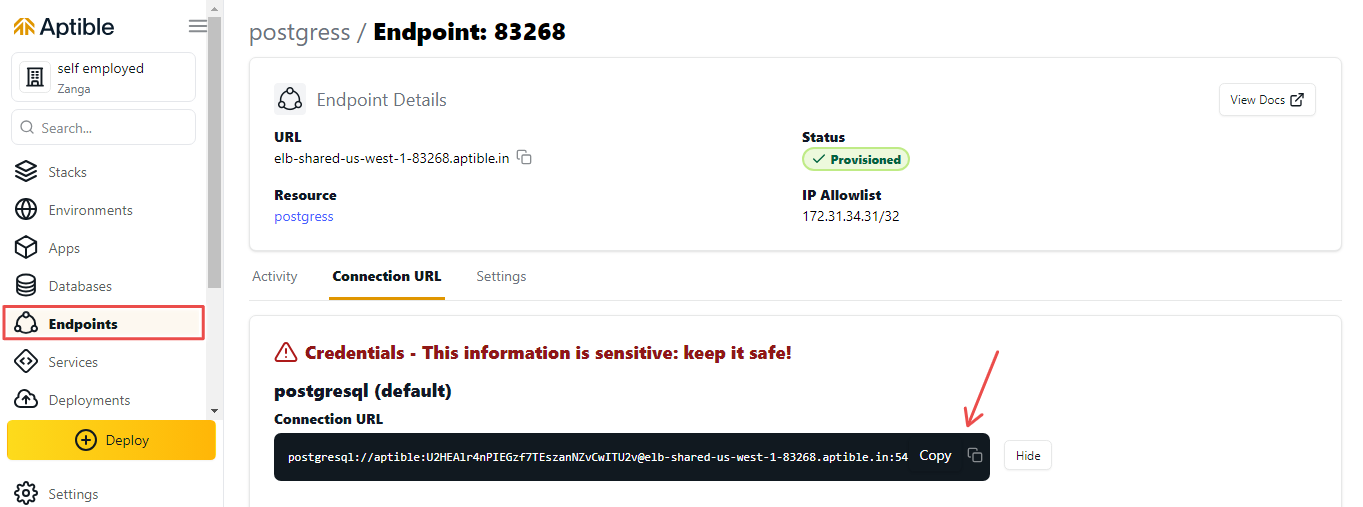
Чтобы подключиться к базе данных PostgreSQL, вам необходимо создать конечную точку базы данных. Для этого выполните следующие действия:
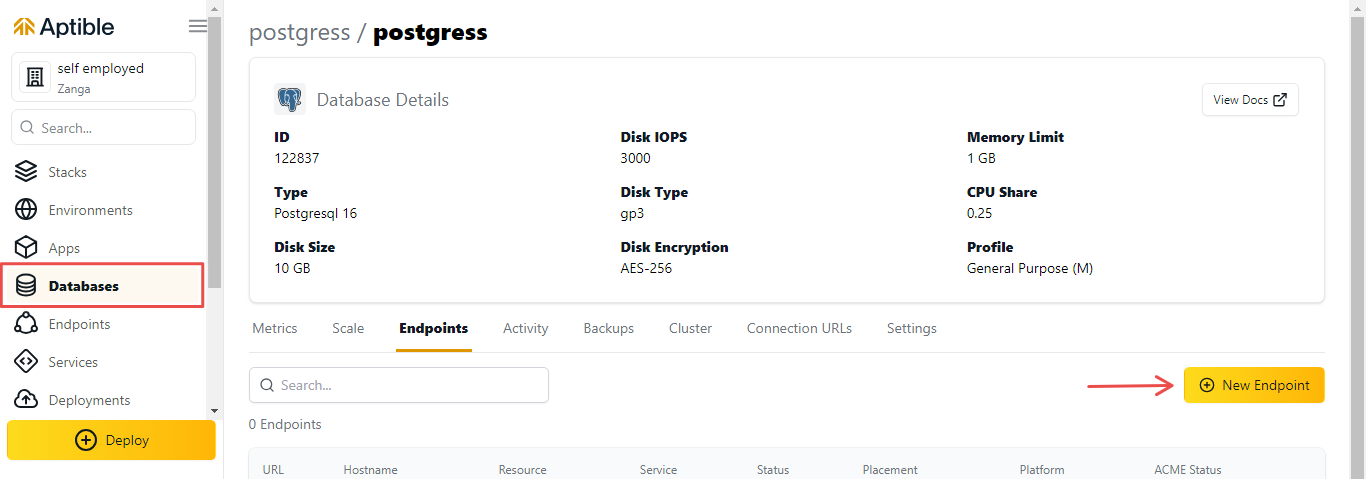
2. Включите IP-адрес в поле Список разрешенных IP-адресов. Это позволит вам подключиться к базе данных с вашего локального компьютера.
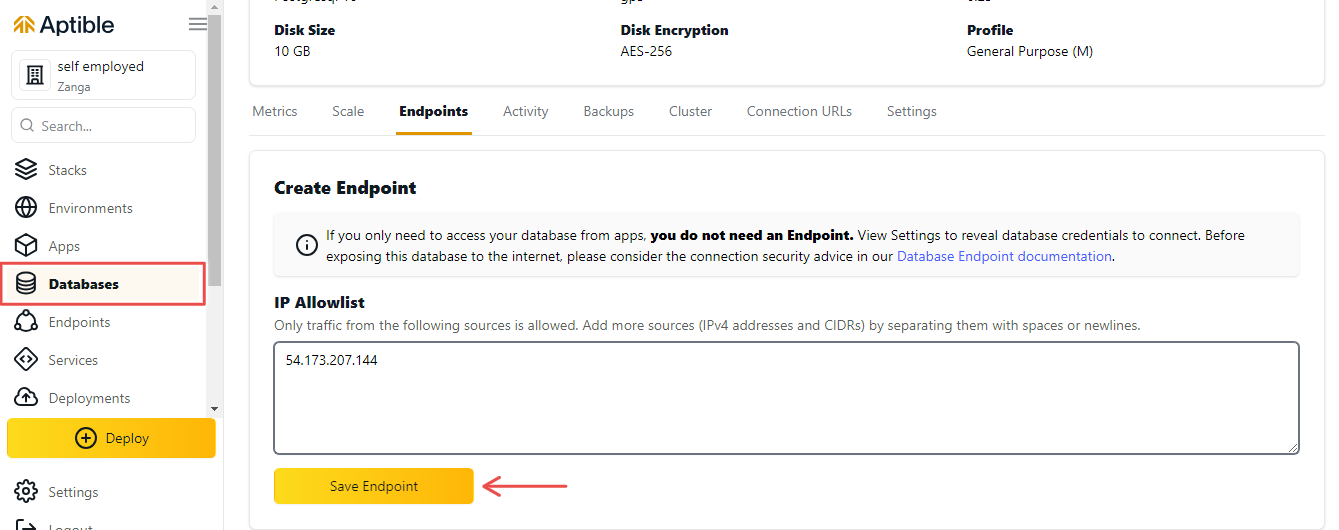
3. После завершения подготовки конечной точки нажмите вкладку ConnectionURL.
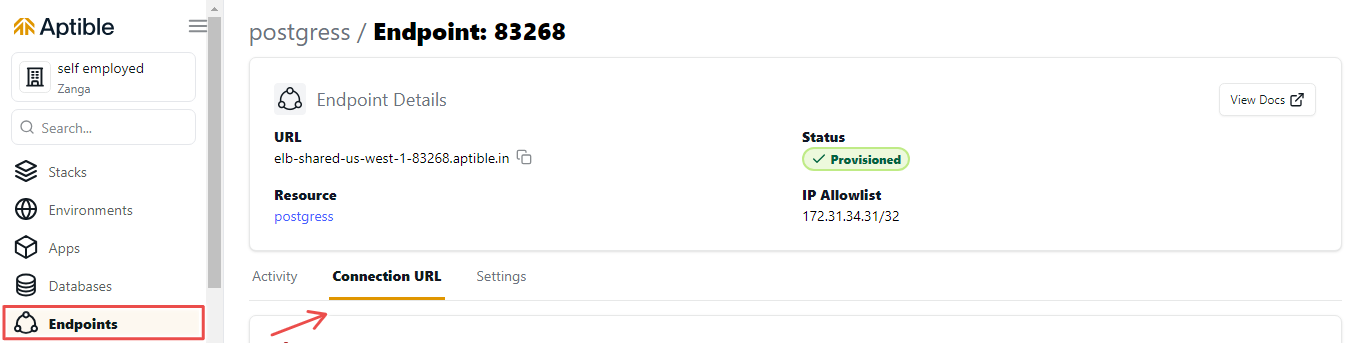
4. Нажмите кнопку показать, чтобы скопировать URL-адрес подключения. Это понадобится вам для подключения к базе данных.
Создайте скрипт парсера.
Этот скрипт очистки будет собирать данные из Netflix и сохранять их в базе данных PostgreSQL.
Чтобы создать скрипт, создайте новый файл с именем scraper.js в корне каталога проекта и добавьте в него следующий код:
const puppeteer = require("puppeteer");
const { Client } = require("pg");
require("dotenv").config();
Приведенный выше код импортирует необходимые пакеты и загружает переменные среды из файла .env.
Ниже приведена разбивка импортированных пакетов:
* puppeteer: библиотека автоматизации браузера без заголовка для Node.js, используемая для очистки веб-страниц.
* Клиент: часть библиотеки pg, клиент PostgreSQL для Node.js.
* dotenv: библиотека для загрузки переменных среды из файла, используемая для загрузки учетных данных базы данных.
Затем добавьте следующий код в файл scraper.js:
async function run() {
const browser = await puppeteer.launch({ headless: "new" });
const page = await browser.newPage();
// Navigate to the website you want to scrape
await page.goto("https://netflix.com/");
// Extract data from the page
const data = await page.evaluate(() => {
const title = document.querySelector("h1").innerText;
const url = window.location.href;
return { title, url };
});
// Close the browser
await browser.close();
return data;
}
Приведенный выше код создает функцию с именем run, которая будет использоваться для сбора данных с веб-сайта Netflix.
Краткое объяснение приведенного выше кода:
* run — асинхронная функция, запускающая автономный браузер с помощью Puppeteer.
* Он открывает новую страницу, переходит к https://netflix.com/, извлекает данные (заголовок и URL-адрес) со страницы с помощью функции, предоставляемой page.evaluate. , а затем закройте браузер.
* Извлеченные данные возвращаются как объект.
Затем добавьте следующий код в файл scraper.js:
async function saveToDatabase(data) {
const client = new Client({
connectionString: process.env.DATABASE_URL,
ssl: { rejectUnauthorized: false },
});
try {
await client.connect();
// Check if the table exists, and create it if not
const createTableQuery = `
CREATE TABLE IF NOT EXISTS scraped_data (
id SERIAL PRIMARY KEY,
title TEXT,
url TEXT
);
`;
await client.query(createTableQuery);
// Insert data into the database
const insertQuery = "INSERT INTO scraped_data (title, url) VALUES ($1, $2)";
const values = [data.title, data.url];
await client.query(insertQuery, values);
} finally {
await client.end();
}
}
Приведенный выше код создает функцию с именем saveToDatabase, которая будет использоваться для сохранения извлеченных данных в базу данных PostgreSQL.
Краткое объяснение приведенного выше кода:
* saveToDatabase — асинхронная функция, которая подключается к базе данных PostgreSQL, используя учетные данные в переменной среды DATABASE_URL.
* Он проверяет, существует ли таблица scraped_data, и создает ее, если нет.
* Затем он вставляет очищенные данные в базу данных с помощью SQL-запроса.
Затем добавьте следующий код в файл scraper.js:
(async () => {
try {
const scrapedData = await run();
console.log("Scraped Data:", scrapedData);
// Save data to the database
await saveToDatabase(scrapedData);
console.log("Data saved to the database.");
} catch (error) {
console.error("Error during scraping:", error);
}
})();
Приведенный выше код вызывает функцию run для очистки данных с веб-сайта Netflix, а затем вызывает функцию saveToDatabase для сохранения извлеченных данных в базе данных PostgreSQL.
Краткое объяснение приведенного выше кода:
* Это немедленно вызываемое функциональное выражение (IIFE) выполняет процесс очистки и сохранения базы данных.
* Он фиксирует любые ошибки, возникающие во время очистки данных или операций с базой данных, и регистрирует их.
* В случае успеха он записывает очищенные данные и выдает сообщение об успехе.
В целом файл scraper.js должен выглядеть следующим образом:
const puppeteer = require("puppeteer");
const { Client } = require("pg");
require("dotenv").config();
async function run() {
const browser = await puppeteer.launch({ headless: "new" });
const page = await browser.newPage();
// Navigate to the website you want to scrape
await page.goto("https://netflix.com/");
// Extract data from the page
const data = await page.evaluate(() => {
const title = document.querySelector("h1").innerText;
const url = window.location.href;
return { title, url };
});
// Close the browser
await browser.close();
return data;
}
async function saveToDatabase(data) {
const client = new Client({
connectionString: process.env.DATABASE_URL,
ssl: { rejectUnauthorized: false },
});
try {
await client.connect();
// Check if the table exists, and create it if not
const createTableQuery = `
CREATE TABLE IF NOT EXISTS scraped_data (
id SERIAL PRIMARY KEY,
title TEXT,
url TEXT
);
`;
await client.query(createTableQuery);
// Insert data into the database
const insertQuery = "INSERT INTO scraped_data (title, url) VALUES ($1, $2)";
const values = [data.title, data.url];
await client.query(insertQuery, values);
} finally {
await client.end();
}
}
(async () => {
try {
const scrapedData = await run();
console.log("Scraped Data:", scrapedData);
// Save data to the database
await saveToDatabase(scrapedData);
console.log("Data saved to the database.");
} catch (error) {
console.error("Error during scraping:", error);
}
})();
Создание файла .env
Файл .env будет содержать учетные данные базы данных. Создайте новый файл с именем .env в корне каталога проекта и добавьте в него следующий код:
DATABASE_URL=postgres://<username>:<password>@<host>:<port>/<database>
:::информация Примечание. Замените заполнители учетными данными базы данных из созданной ранее конечной точки базы данных.
:::
Запуск скрипта парсера
Чтобы запустить скрипт парсера, выполните следующую команду:
node scraper.js
Это запустит автономный браузер, перейдет на веб-сайт Netflix, скопирует данные со страницы и сохранит их в базе данных PostgreSQL в Aptible.
Вы должны увидеть следующий результат:
Scraped Data: {
title: 'Unlimited movies, TV shows, and more',
url: 'https://www.netflix.com/'
}
Data saved to the database.
Вы можете убедиться, что данные были сохранены в базе данных, войдя в базу данных PostgreSQL, используя учетные данные из конечной точки базы данных.
Вы можете сделать это, выполнив следующую команду:
psql <connection_url>
:::информация
Примечание. Замените <connection_url> URL-адресом подключения из конечной точки базы данных.
:::
После входа в систему вы можете просмотреть таблицы в базе данных, выполнив следующую команду:
dt
Вы должны увидеть таблицу scraped_data, указанную в выводе:
List of relations
Schema | Name | Type | Owner
--------+--------------+-------+---------
public | scraped_data | table | aptible
(1 row)
Вы можете просмотреть данные в таблице scraped_data, выполнив следующую команду:
SELECT * FROM scraped_data;
Вы должны увидеть очищенные данные, перечисленные в выводе:
id | title | url
----+--------------------------------------+--------------------------
1 | Unlimited movies, TV shows, and more | https://www.netflix.com/
(1 row)
Заключение
В этом руководстве вы узнали, как создать приложение для сбора данных с помощью Puppeteer, Node.js, PostgreSQL и Aptible.
Чтобы улучшить этот проект, рассмотрите возможность добавления дополнительных функций в скрипт парсера. Например, вы можете расширить его, чтобы собирать данные с нескольких веб-сайтов и сохранять их в базе данных.
Кроме того, вы можете расширить приложение, включив интерфейс. Это дополнение позволяет визуализировать очищенные данные в веб-браузере, повышая удобство работы пользователей.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)