

Увеличение пропускной способности LLM Decod
14 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
2.1 Модели больших языков
2.2 Фрагментация и Pagegataturation
3 проблемы с моделью Pagegatatturetion и 3.1 требуют переписывания ядра внимания
3.2 Добавляет избыточность в рамки порции и 3,3 накладных расходов
4 понимания систем обслуживания LLM
5 Vattument: проектирование системы и 5.1 Обзор дизайна
5.2 Использование поддержки CUDA низкого уровня
5.3 Служение LLMS с ваттенцией
6 -й ваттиция: оптимизация и 6,1 смягчения внутренней фрагментации
6.2 Скрытие задержки распределения памяти
7 Оценка
7.1 Портативность и производительность для предпочтений
7.2 Портативность и производительность для декодов
7.3 Эффективность распределения физической памяти
7.4 Анализ фрагментации памяти
8 Связанная работа
9 Заключение и ссылки
7.2 Portability and Performance for Decodes
Чтобы оценить производительность декодирования, мы сосредоточены на сценариях с длинным контекстом (16K), потому что задержка ядра внимания становится значительной только для длинных контекстов [4]. Мы оцениваем следующие конфигурации:
vllm: Мы используем VLLM V0.2.7 в качестве основной базовой линии. VLLM, пионерный Pagegatattureation и использует пользовательское ядро для лиц для декодов, полученное от более быстрого перевода [4].
FA_PAGED:Во второй базовой линии мы интегрируем ядро вспышки в стек VLLM. Это представляет собой современное ядро Pagegatattureation, которое включает в себя оптимизации, такие как параллелизм последовательности и копия новых ключевых и значения векторов в кв. Мы оцениваем ядра погибло VLLM и вспышку с двумя разными размерами блоков - 16 и 128 - чтобы захватить влияние размера блока на производительность.
FA_VATTITION:Что касается ваттций, мы интегрировали ванильное ядро вспышки в стек VLLM. Ядро работает с практически смежным кв-кэш, на которую мы динамически распределяем физическую память, используя 2 МБ страниц.
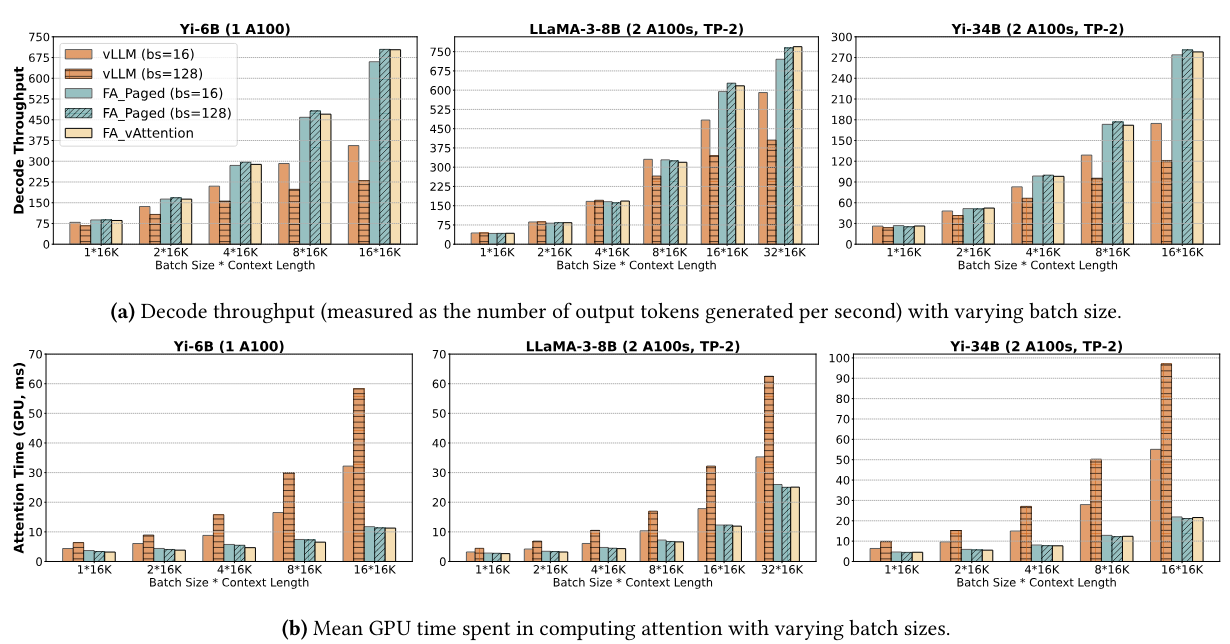
На рисунке 9а показана пропускная способность декодирования YI-6B, Llama3-8B и YI-34B с различными размерами партий, в которых начальная длина контекста каждого запроса составляет 16K токены, и мы генерируем 256 токенов для каждого запроса. Мы вычисляем пропускную способность декодирования на основе средней задержки 256 итераций декодирования. Мы суммируем ключевые выводы ниже.
Во -первых, VATTINATION превзойдет VLLM (оба размера блоков) и FA_PAGE (размер блока 16), при этом примерно соответствует наилучшей конфигурации FA_PAGE (размер блока 128). Максимальное улучшение по сравнению с VLLM составляет 1,97 × для YI-6B, 1,3 × для Llama3-8B и 1,6 × для YI-34B. Относительные прибыли над VLLM также увеличиваются по мере роста размера партии. Например, усиление увеличивается с 1,1 × до 1,97 ×, поскольку размер партии увеличивается с 1 до 8 для YI-6B. Это связано с тем, что задержка расчета внимания растет пропорционально общему количеству токенов в партии (см. Рисунок 9b), тогда как стоимость линейных операторов остается примерно одинаковой [25, 26, 41]. Следовательно, вклад ядра внимания в общую задержку - и впоследствии приобретает более эффективное ядро - увеличивается с размером партии. В то время как FA_PAGED (размер блока 128) обеспечивает аналогичные выгоды, как и ваттиционирование, обратите внимание, что FA_PAGE требует новой реализации ядра графического процессора, тогда как ваттиция просто использует ванильное ядро вспышки.
Во -вторых, рисунок 9b подтверждает, что разница в производительности между VLLM и FA_PAGED/VATTUTION действительно обусловлена ядрами внимания. В худшем случае задержка лучшего ядра VLLM Pagegatatention (размер блока 16) составляет до 2,85 × выше для YI-6B, до 1,45 × для Llama-3-8B и до 2,62 × для YI-34B, чем ядра Flashattention.
Наконец, пропускная способность может быть чувствительной к размеру блокировки, даже если емкость памяти не является ограничением. Например, как обсуждалось в §3.3, ядро внимания VLLM имеет значительно более высокую задержку с размером блока 128, чем с размером блока 16 (также см. Рисунок 9b). В худшем случае размер блока 128 разлагает пропускную способность VLLM на 36%. В то время как размер блока имеет меньший
Влияние на вспышку, использование небольшого размера блока все еще может повредить пропускной способности из-за накладных расходов на ЦП, особенно из-за накладных расходов на создание блок-таблиц для каждой итерации (§3.3). Например, вспышка с размером блока 128 обеспечивает 7% выше пропускной способности, чем размер блока 16 для Llama-3-8B (531 против 494 токенов в секунду с размером партии 32).
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
[4] Для коротких контекстов время вычисления в сети подачи доминирует задержкой вывода [25]
Авторы:
(1) Рамья Прабху, Microsoft Research India;
(2) Аджай Наяк, Индийский институт науки и участвовал в этой работе в качестве стажера в Microsoft Research India;
(3) Джаяшри Мохан, Microsoft Research India;
(4) Рамачандран Рамджи, Microsoft Research India;
(5) Ашиш Панвар, Microsoft Research India.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Социальные медиа и интернет-культура (107)
- Экономика и финансы (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)