

За пределами статических рангов: сила динамического квантования в тонкой настройке LLM
1 июля 2025 г.Авторы:
(1) Хоссейн Раджабзаде, Университет Ватерлоо и лабораторию Хуауэя Ноа (hossein.rajabzadeh@uwaterloo.ca);
(2) Mojtaba Valipour, Университет Ватерлоо (mojtaba.valipour@uwaterloo.ca);
(3) Tianshu Zhu, Huawei Noah's Ark Lab (tianshu.zhu@huawei.com);
(4) Марзи Тахей, лаборатория Арк Хуауей Ноа (marzieh.tahaei@huawei.com);
(5) Hyock Ju Kwon, (hjkwon@uwaterloo.ca);
(6) Али Годси, (ali.ghodsi@uwaterloo.ca);
(7) Boxing Chen, Huawei Noah's Ark Lab (boxing.chen@huawei.com);
(8) Мехди Резагхолизаде, лаборатория Арк Хуавей Ноа (mehdi.rezagholizadeh@huawei.com).
Таблица ссылок
Аннотация и 1. Введение
- Предложенный метод: квантовая Dylora
- Эксперименты и оценка
- На полуосорвантном поведении Qdylora
- Заключение, ограничения и ссылки
А. Дополнительный материал
А.1 Гиперпараметры
А.2. Сгенерированное качество текста
Абстрактный
Создание больших языковых моделей требует огромной памяти графического процессора, ограничивающего выбор для получения более крупных моделей. В то время как квантовая версия метода адаптации с низким уровнем ранга, названная Qlora, значительно облегчает эту проблему, обнаружение эффективного звания Lora все еще является сложной задачей. Более того, Qlora обучается на предварительно определенном ранге и, следовательно, не может быть перенастроена для его более низких рангов, не требуя дальнейших шагов с точной настройкой. В этой статье предлагается динамическая динамическая адаптация с низким уровнем ранга Qdylora, как эффективный подход квантования для динамической адаптации с низким уровнем ранга. Мотивированный Dynamic Lora, Qdylora способен эффективно Finetune LLM на наборе заранее определенных рангов LORA. Qdylora включает в себя тонкую настройку Falcon-40B для ранга с 1 по 64 на одном 32 ГБ V100-GPU через один раунд тонкой настройки. Экспериментальные результаты показывают, что Qdylora конкурентоспособна для Qlora и превосходит при использовании его оптимального ранга.
1 Введение
За последние два года популярность принятия крупных языковых моделей (LLMS) в разнообразном диапазоне нижестоящих задач быстро увеличилась. Cenetuning LLMS стала необходимой для повышения их производительности и введения желаемого поведения, предотвращая нежелательные результаты (Ding et al., 2023). Однако по мере увеличения размера этих моделей затраты на точную настройку становятся более дорогими. Это привело к большому объему исследований, которые фокусируются на повышении эффективности стадии тонкой настройки (Liu et al., 2022; Mao et al., 2021; Hu et al., 2021; Edalati et al., 2022; Sung et al., 2022).
Низководный адаптер (LORA) (Hu et al., 2021)-это хорошо известный метод настройки параметров (PEFT), который уменьшает требования к памяти во время точной настройки, замораживая базовую модель и обновляя небольшой набор подготовленных параметров в форме низкого уровня матрицы, добавляемых в базовую модель. Тем не менее, спрос на память во время точной настройки остается существенной из-за необходимости обратного прохода через модель замороженного основания во время стохастического градиентного происхождения.
Таким образом, недавние исследования были сосредоточены на дальнейшем снижении использования памяти путем разработки новых параметров, которые можно настроить, которые можно настроить без необходимости градиентов из базовых моделей (Sung et al., 2022). Альтернативно, исследователи изучали сочетание других стратегий эффективности с методами параметров, эффективных настройки (Kwon et al., 2022; Dettmers et al., 2023).
Среди этих подходов Qlora (Dettmers et al., 2023) выделяется как недавний и высокоэффективный метод тонкой настройки, который резко уменьшает использование памяти. Это обеспечивает тонкую настройку модели на 65 миллиардов параметра на одном графическом процессоре 48 ГБ, сохраняя при этом полную 16-битную точную производительность. Qlora достигает этого, используя 4-бит Normalfloat (NF4), двойную квантование и оптимизаторы на странице, а также модули LORA.
Тем не менее, еще одна важная проблема при использовании модулей LORA - это необходимость настройки своего ранга в качестве гиперпараметра. Различные задачи могут потребовать модулей LORA различных рангов. Фактически, из экспериментальных результатов в статье LORA очевидно, что производительность моделей сильно варьируется с разными рядами, и нет четкой тенденции, указывающей на оптимальный ранг. С другой стороны, любая настройка гиперпараметра для поиска оптимального ранга противоречит основной цели эффективной настройки и невозможно для очень больших моделей. Более того, при развертывании нейронной сети на различных устройствах с различными конфигурациями использование более высоких рангов может стать проблематичным для высокочувствительных устройств из -за увеличения количества параметров. Чтобы решить это, обычно нужно выбирать между обучением нескольких моделей, адаптированных к различным конфигурациям устройства или определением оптимального ранга для каждого устройства и задачи. Тем не менее, этот процесс является дорогостоящим и трудоемким, даже при использовании таких методов, как Лора.
![Table 1: A comparison between QLoRA and QDyLoRA on the MMLU benchmark, reporting 5-shot test results for LLMs of varying sizes. QDyLoRA is evaluated on ranks [1,2,4,8,16,32,64] and the best rank is reported in brackets.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-ig033k7.png)
Dylora (Valipour et al., 2022), является недавним методом PEFT, целью которого является решение этих проблем, используя динамический адаптер с низким уровнем ранга (Dylora). Вдохновленный вложенным выпуском, этот метод направлен на упорядочение представлений узкого места в модулях с низким уровнем адаптера. Вместо того, чтобы тренировать блоки LORA с фиксированным рангом, Dylora расширяет обучение, чтобы охватить спектр рядов сортированным образом. Полученные в результате модули с низким рейтингом PEFT не только обеспечивают повышенную гибкость во время вывода, что позволяет выбирать различные ранги в зависимости от контекста, но и демонстрируют превосходную производительность по сравнению с LORA, и все это без какого-либо дополнительного времени обучения.
В этой статье мы используем метод Dylora PEFT в сочетании со схемой квантования, используемой в работе Qlora, что приводит к Qdylora. Qdylora имеет все вышеупомянутые преимущества Dylora, но со значительным снижением памяти как во время обучения, так и при выводе за счет 4-битного квантования. Мы используем Qdylora для эффективной тонкой настройки моделей Llama-7B, Llama13b и Falcon-40b в рядах в диапазоне от 1 до 64, все на одном графическом процессоре 32 ГБ V100. После настройки мы определяем оптимальный ранг, выводя модель на наборе тестирования. Наши результаты показывают, что оптимальный ранг может быть довольно низким, но он превосходит Qlora.
1.1 Связанная работа
Низкие методы PEFTЭти методы направлены на то, чтобы настраивать предварительно обученные LLM для конкретных задач при минимизации вычислительных ресурсов и памяти. Методы адаптации с низким уровнем ранга были вдохновлены (Aghajananyan et al., 2020), демонстрируя, что предварительно обученные языковые модели обладают низким внутренним измерением. С тех пор в нескольких работах изучалось включение обучаемых параметров в форме низковороткой подъема/нижнего проекции во время точной настройки. В (Houlsby et al., 2019) модуль адаптера включает в себя проекцию вниз, нелинейную функцию, проекцию UP и остаточное соединение. Эти модули последовательно вставляются после сети подачи (FFN) или блоков внимания.
Кроме того, (He et al., 2021) расширяет концепцию адаптера, внедряя обучаемые модули, которые работают параллельно (PA) с оригинальным модулем предварительно обученной языковой модели (PLM). В результате этого расширения PA продемонстрировала улучшенную производительность по сравнению с исходным методом адаптера. Одним из заметных подходов среди этих методов является Lora (Hu et al., 2021), которая вводит с низким уровнем повышения/снижения в рамках различных матриц в пределах PLM. Этот метод предлагает эффективный вывод путем беспрепятственной интеграции модуля адаптера в весовые матрицы оригинальной модели.
Квантование-методы ПефтAlphatuning (Kwon et al., 2022), направлена на объединение параметров-эффективной адаптации и сжатия модели. Alpha-Tuning достигает этого, используя квантование после тренировки, которая включает преобразование параметров полного характеристик в предварительно обученной языковой модели в двоичные параметры и отдельные коэффициенты масштабирования. Во время адаптации бинарные значения остаются фиксированными для всех задач, в то время как факторы масштабирования точно настроены для конкретной задачи в нижней части.
Qlora (Dettmers et al., 2023) представляет собой более недавнюю PEFT с квантованием, которая сочетает в себе адаптер с низким уровнем ранга с 4-битным квантованием NormalFloat (NF4) и двойной квантованием (DQ) базовой модели для оптимизации использования памяти. NF4 обеспечивает оптимальное распределение значений в мусорных банках, упрощая процесс, когда входные тензоры имеют фиксированное распределение. DQ дополнительно уменьшает накладные расходы на память за счет квантования констант квантования.
Для управления памятью во время градиентной контрольной точки, Qlora использует оптимизаторы Pagege, используя функцию Unified Memory Nvidia для эффективного управления памятью графического процессора. Эти методы в совокупности обеспечивают 4-разрядную настройку с высокой точки зрения при выполнении ограничений памяти.
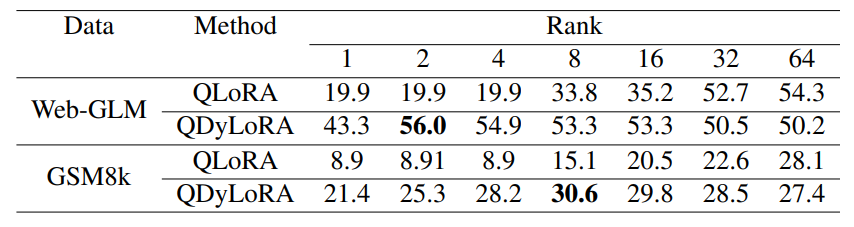
Динамические методы PEFTDylora Paper (Valipour et al., 2022) представляет новый подход для обучения модулям с низким уровнем ранга для эффективной работы по ряду рангов одновременно, устраняя необходимость обучения отдельных моделей для каждого ранга.
Вдохновленные концепцией вложенного отсева, авторы предлагают метод организации представлений в модулях с низким уровнем адаптера. Этот подход направлен на создание динамических адаптеров с низким уровнем ранга, которые могут хорошо адаптироваться к различным рядам, а не прикрепляться к одному рангу с установленным бюджетом обучения. Это достигается путем динамического выбора рангов во время обучения, что обеспечивает большую гибкость без необходимости обширного поиска ранга и многократных тренировок по модели.

Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)