

Помимо высокой доступности: архитектуры аварийного восстановления, которые продолжают работать, когда HA не удается
6 июня 2025 г.Введение
Высоко доступные системы катастрофически терпят неудачу, хотя они обещают 99,99% времени безотказной работы. Архитектуры HA могут испытывать неудачи из -за региональных отключений облака и атак вымогателей и человеческих ошибок. Организации должны установить аварийное восстановление в качестве отдельной строгой дисциплины для достижения истинной устойчивости системы за пределами высокой доступности.
Полная стратегия восстановления операций после катастрофических сбоев определяет аварийное восстановление (DR). Диапазон сбоев простирается в прошлом оборудованном неисправностях, потому что он охватывает программные ошибки и злонамеренные атаки, коррупцию данных и полные сбои облачных регионов. HA в основном фокусируется на предотвращении сбоя, где DR предполагает, что неудача неизбежна и готовит организацию к быстро и эффективно восстанавливаться.
В статье дается четкое объяснение аварийного восстановления посредством практических примеров и архитектурных моделей вместе с конкретными руководством для инженеров -программистов, инженеров по надежности сайта и архитекторов инфраструктуры.
HA VS DR: Критическое различие
Высокая доступность (HA) и аварийное восстановление (DR) работают как отдельные компоненты, которые работают вместе для повышения устойчивости системы. Вот как они отличаются:
Атрибут | Высокая доступность | Аварийное восстановление |
|---|---|---|
Объем | Локализованные неудачи | Региональные/катастрофические неудачи |
Примеры | Узел сбоев, отключения AZ | Удаление данных, потеря региона, вымогатели |
Цель | Поддерживать время безотказной работы | Восстановить услуги и данные пост-испуга |
Инструменты | Кластеры, балансировщики нагрузки, автоматическое масштаб | Резервные копии, репликация, развертывание с несколькими сайтами |
Фокус | Профилактика | Восстановление |
Пример:Кластер Kubernetes с использованиемPOD анти-аффинностьиразвертывание мульти-азОбеспечивает высокую доступность в одном регионе. Если одна зона доступности (AZ) терпит неудачу, стручки перенесены в здоровые зоны, поддерживая приложение.
Однако эта установка не поможет во времяОбщенациональный отключениеВОблачная неправильная конфигурация, илислучайное удалениересурсов, все из которых могут снизить всю систему.
Вот почемуПлан аварийного восстановления (DR)срезервные копииВрепликация в другой регион, иАвтоматизация аварийного переключенияпоможет восстановить приложения и данные в случае серьезных сбоев.
Высокая доступность сохраняет стабильные в небольших сбоях.DR-это безопасная сеть для крупномасштабных катастроф.
Инциденты в реальном мире: почему DR очень важен, а не необязательно
Люди, как правило, считают аварийное восстановление как страховой полис, потому что он служит защитой от неожиданных событий, но остается неиспользованным до тех пор, пока не нанесет удар. Но история рассказывает нам иначе, сбои системы быстро распространяются по большим сетям. Следующие основные инциденты демонстрируют, как системы становятся уязвимыми без надлежащей стратегии DR.
Гитлаб (2017): случайное удаление и неисправные резервные копии
Инженер Gitlab, который пытался решить проблемы с задержкой базы данныхУдаление всей производственной базы данных PostgreSQLПолем ГОРЯЧНАЯ БАЗА ДЕНЬ СТАРЬ, которая сразу же послужила резервной системойреплицировать операцию удаленияПолем Команда столкнулась с серьезным отключением обслуживания и потерей данных, потому что их последнее резервное копирование было шесть часов, а их процесс восстановления был непроверенным и ненадежным.
Урок:Настоящий DR нуждается в проверкепроцедуры восстановлениявместе сизолированные резервные копиииАвтоматизированный запаснойМеханизмы вместо избыточных систем, которые повторяют ошибки.
Кодовые пространства (2014): угон и общий Wipeout Cloud Account
Злоумышленник получил доступ к панели управления AWS Spaces и продолжилУдалить все, экземпляры EC2, ведра S3, резервные копии и даже конфигурации DRПолем БезОфлайн или вне облачных резервных копий, компания не смогла выздороветь и должна былаВыключите навсегдаПолем
Урок:Никогда не кладите все яйца в одну корзину, особенно не в однойоблачный аккаунтПолем Доктор должен бытьOffsite, Offline и невосприимчивые к нарушениям уровня счетаПолем
Maersk (2017): атака вредоносных программ Notpetya
Глобальный транспортный гигант был поражен Notpetya, вредоносным ПО, которыйзашифровали все системы на основе WindowsПолем Вся глобальная ИТ -инфраструктура Maersks вышла из строя от терминалов до систем электронной почты. Чудесным образом, одинконтроллер домена в Ганевыжил, потому что это былоОффлайн во время атакиИз -за локального отключения электроэнергии. Используя это, Maersk смог выздороветь, но это потребовалосьболее 10 дней и 300 миллионов долларовв ущербе.
Урок:ИногдаОфлайн -резервные копииединственные выжившие. Устойчивый план DR включаетГеографически изолированные системы и устойчивые к вредоносному обеспечению точки восстановленияПолем
Facebook (2021): неправильная конфигурация BGP снимает всю сеть
НеисправныйБр(Протокол пограничных шлюзов)Обновление конфигурацииПоиск Facebook и все его услуги (Instagram, WhatsApp, Messenger) в течение нескольких часов в течение нескольких часов. Внутренние инструменты также были недоступны, потому что они были размещены в одной и той же сети, заблокировав инженеров из быстрой решающей проблемы.
Урок:Доктор - это не только данные, а также оДоступность и восстановление работыПолем Держать инструменты восстановления визолированные средыЭто может функционировать, когда первичная среда не удается.
Ключевые выводы:
- Реализация резервных копий как DR требует автоматических процессов, которые должны быть расположены вне места и тестируются через регулярные промежутки времени.
- DR Infrastructure требует логической, географической, а иногда и поставщика.
- Способность восстанавливаться после сбоев стоит выше необходимости избыточных систем.
- Предприятия должны подготовиться к фактическим угрозам, которые включают человеческие ошибки, нарушения безопасности и стихийные бедствия.
Правильно разработанный план DR превращает основные бедствия в управляемые сбои. Отсутствие плана восстановления делает восстановление бизнеса опасным, потому что некоторые организации никогда не могут попробовать еще раз.
Ключевые метрики в аварийном восстановлении: RTO и RPO
Процесс проектирования плана аварийного восстановления (DR) требует не только восстановления системы, поскольку ему необходимо достичь как своевременного восстановления, так и минимальной потери данных. Два критических показателях
Цель времени восстановления (RTO)
Амаксимально допустимое времяВаша система или услуга могут быть опущены после сбоя, прежде чем она должна быть восстановлена.
Думайте об этом как о вашемУстойчивость к простоямПолем
Это определяетКак быстроУслуги должны быть восстановлены, чтобы избежать серьезного влияния на бизнес.
Цель точки восстановления (RPO)
Амаксимально приемлемое количество потери данных, измеряется во времени, с момента отказа.
- Это отвечает на вопрос:Сколько данных мы можем позволить себе проиграть?
- Это отражаетКак частоВам нужно сделать резервную копию данных.
Пример:
Допустим, отключение происходит в12:00Полем
- ТвойRTO - 1 час
- Вы должны полностью восстановиться и снова запустить услуги13:00Полем
- ТвойRPO - 15 минут
- Вы должны восстановить данныекак это существовало к 11:45Полем
Это означает любые транзакции или обновления, сделанные между11:45 и 12:00может быть потеряно, и ваши системы должны быть разработаны для обращения с этой потерей.
Ключевые выводы:
- RTO =Как быстро вы восстановитесь.
- Rpo =Сколько данных вы можете позволить себе потерять.
- Более строгие RTO и RPO означаетБолее высокая стоимость и сложность.
- ТвойBusiness SLAS (соглашения об уровне обслуживания)должен привести к тому, что RTO/RPO не наоборот.
- RTO и RPO влияют на вашТехнологический выборВчастота резервной копииВсетевой дизайн, иподход к отключениюПолем
Аварийное восстановление архитектуры
Каждая модель DR представляет собой различный компромисс между стоимостью, сложностью, RTO и RPO. Давайте рассмотрим их
Архитектура резервного копирования и восстановления (холодный DR)
Обзор: Простые резервные копии, хранящиеся в хранении объектов (например, Amazon S3, Azure Blob, Google Cloud Storage).
Архитектура:
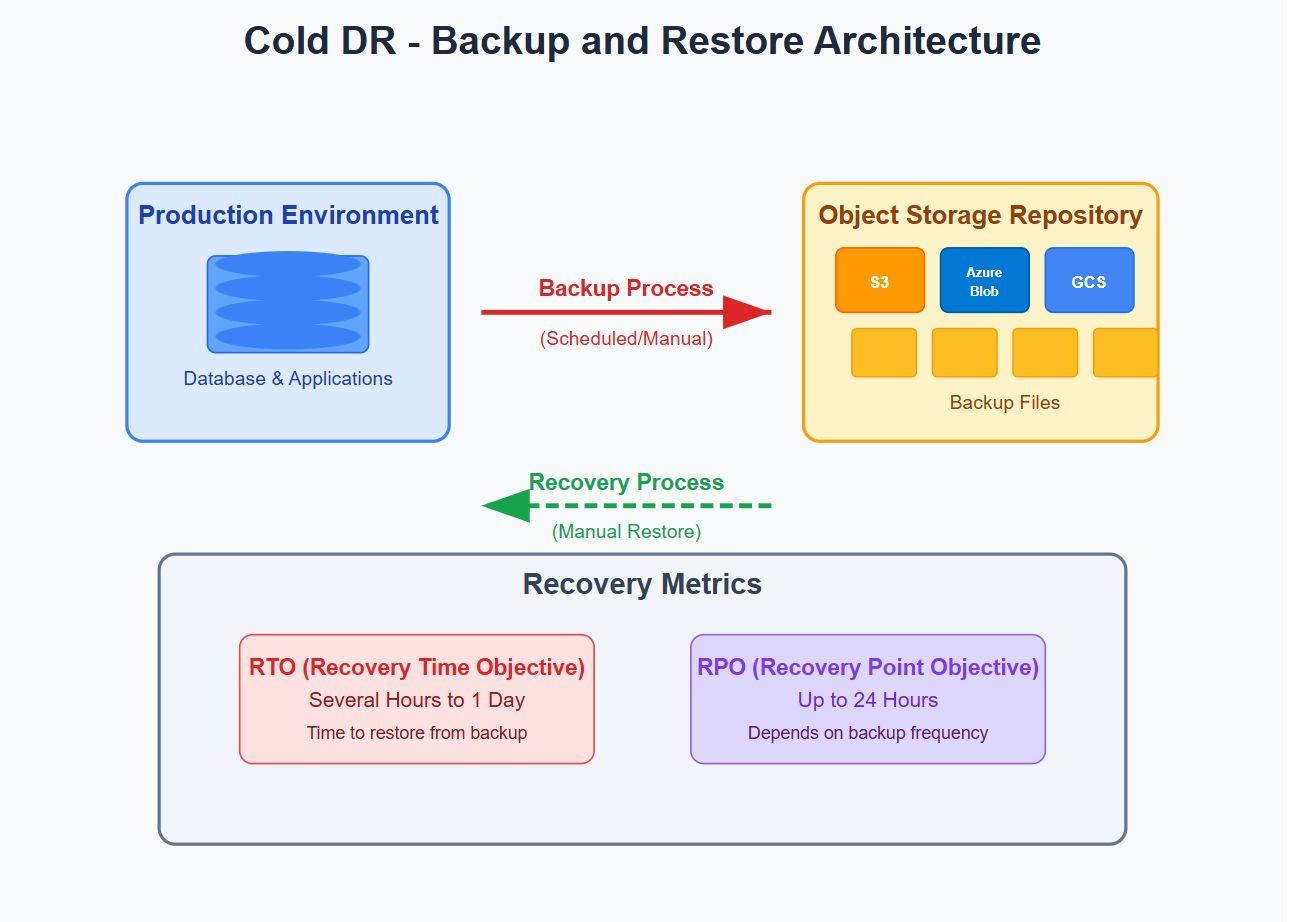
В случае использования:Некритические системы, среда разработки/тестирования.
Плюс: Низкая стоимость, минимальные операционные накладные расходы.
Минусы: Восстановление медленно; Резервные копии должны быть регулярно протестированы.
Пилотная световая архитектура
Обзор: Поддерживать минимальные ресурсы (пример: реплицирован DB, базовая сеть) в регионе DR. Серверы приложений предоставления только во время переключения.
Архитектура:
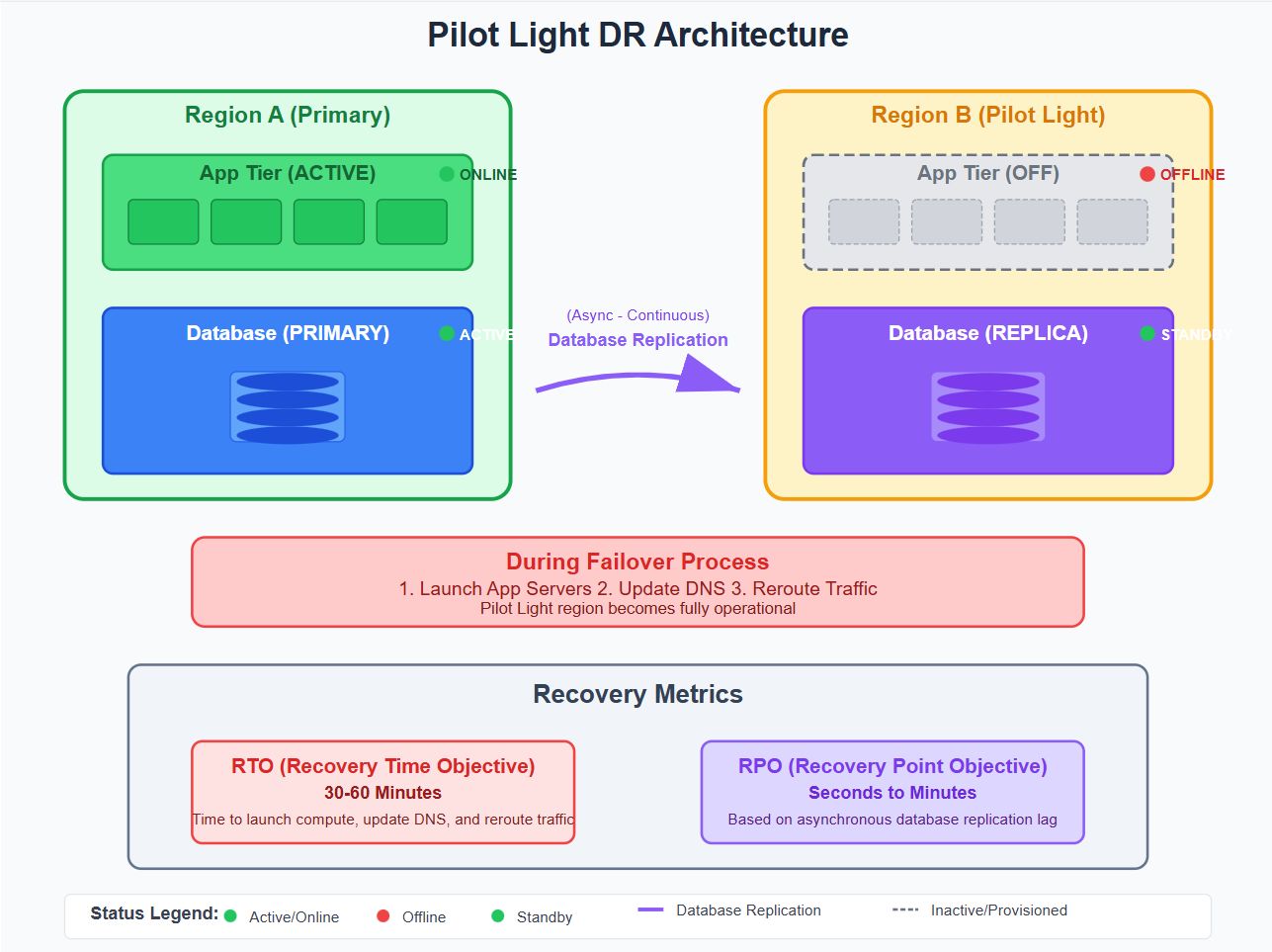
Вариант использования: Умеренно критические рабочие нагрузки.
Плюс: Эффективно с умеренным временем восстановления.
Минусы: Требуется автоматизированные сценарии обеспечения, аварийный оркестровка.
Теплый резервАрхитектура
Обзор: Вся инфраструктура DR обеспечивается и частично масштабируется. Услуги DR работают с уменьшенной нагрузкой и периодически проверены.
Архитектура:
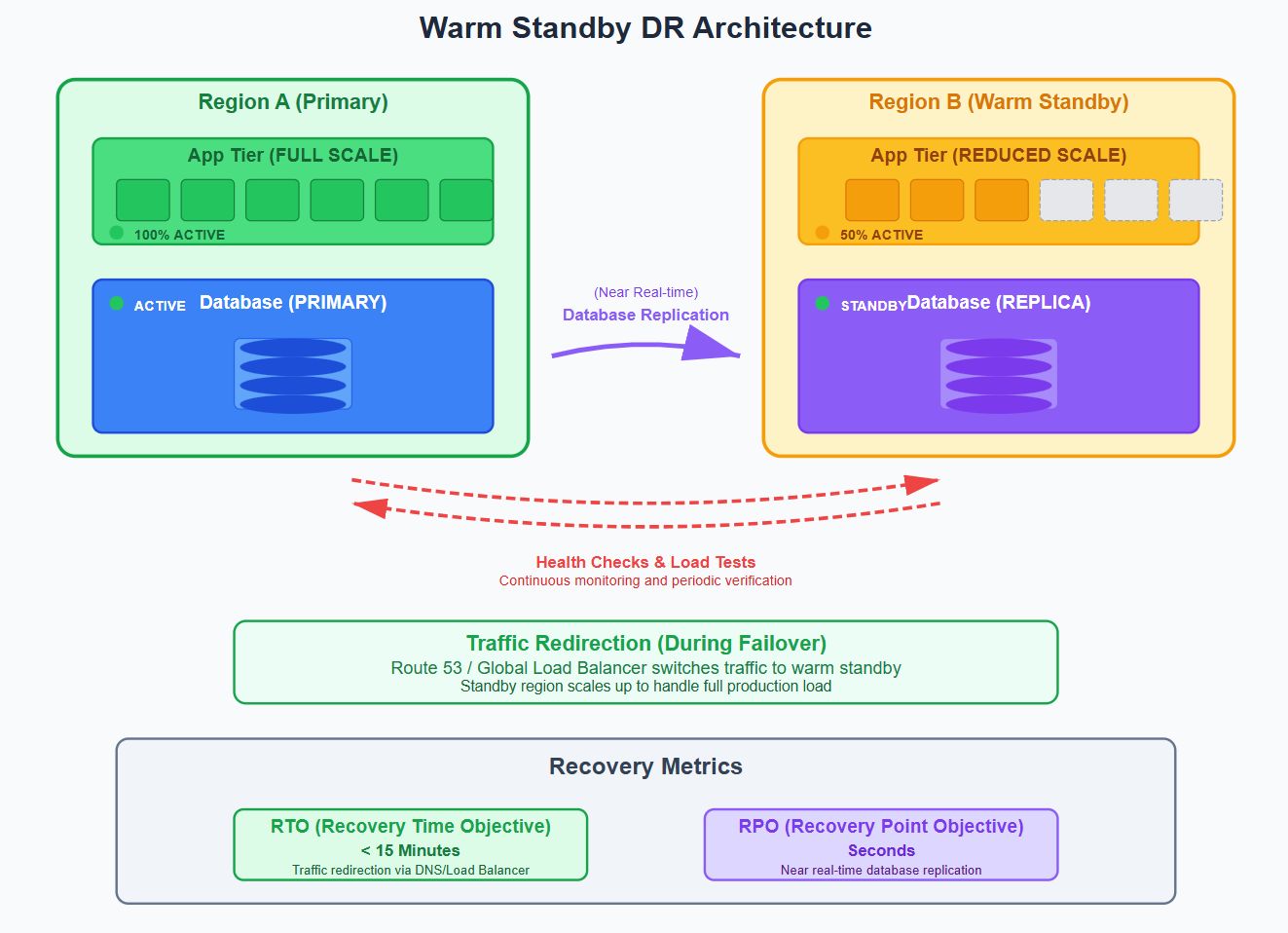
Вариант использования: Приложения с высоким содержанием SLA и умеренным бюджетом.
Плюс: Быстрое выздоровление, может подтвердить живую готовность
Минусы: Постоянные затраты на недостаточно используемый вычислитель, риски дрейфа конфигурации
Горячий резерв (Active-Passive)Архитектура
Обзор: Две идентичные среды, одна активная и одна холостяк. Трафик направляется на активное, а аварийное переключение является ручным или автоматическим.
Архитектура:
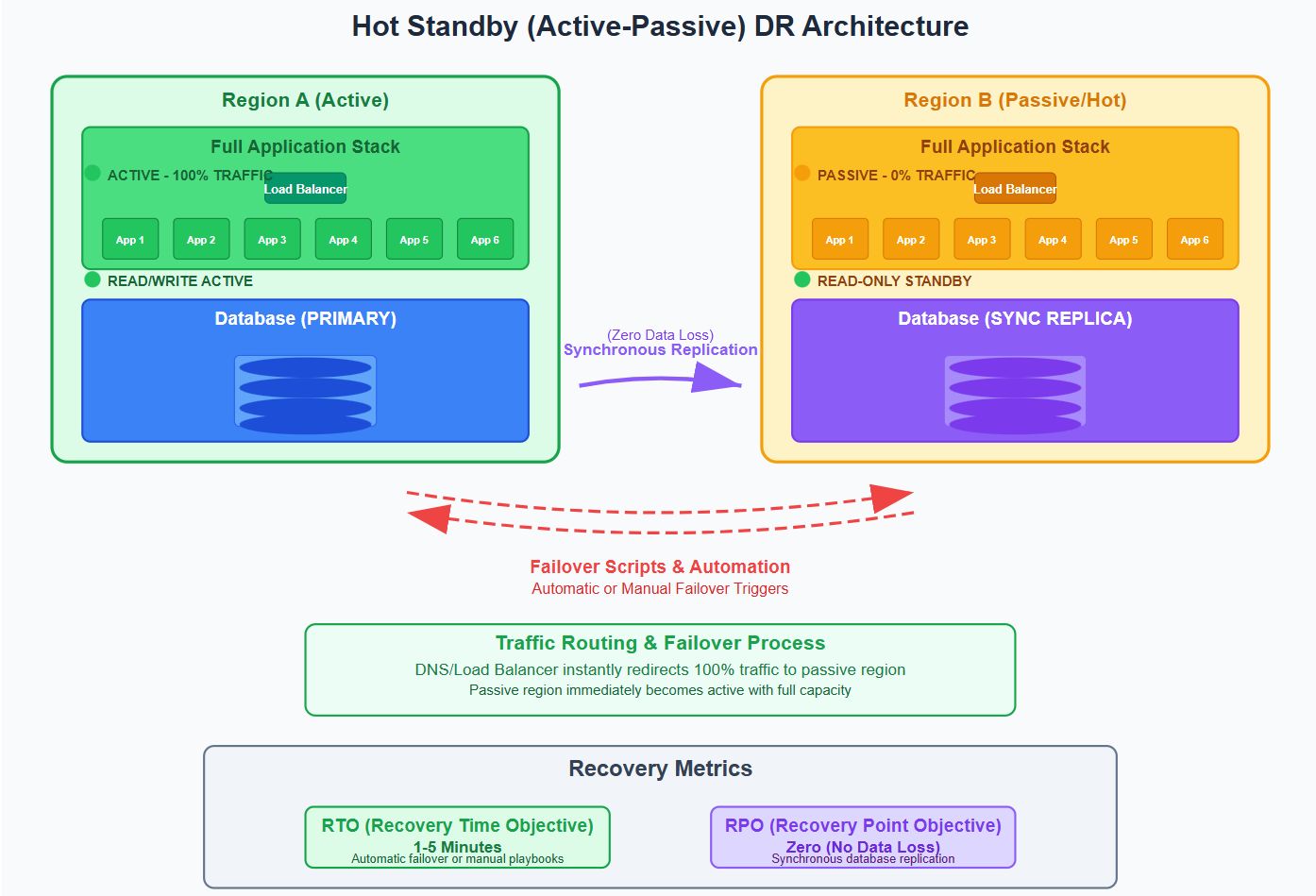
Вариант использования: Здравоохранение, банковское дело, регулируемые отрасли.
Плюс: Почти бесшовный аварийный переключение, без потери данных.
Минусы: High infrastructure costs for unused capacity.
Активно-активный (многосайт)Архитектура
Обзор: Два или более регионов обрабатывают живой трафик. Каждый регион имеет полностью операционные услуги.
Архитектура:
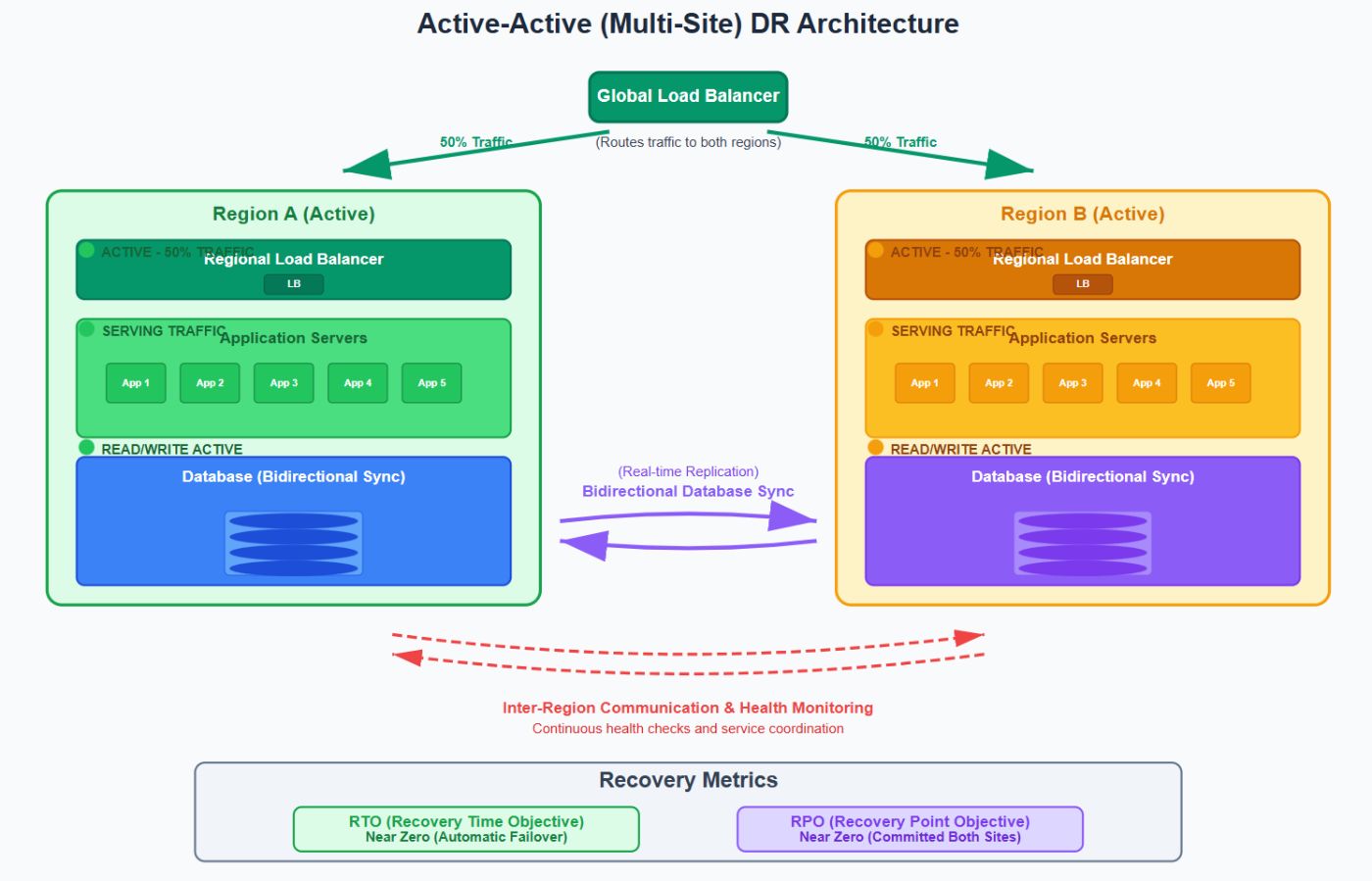
Вариант использования: Глобальные платформы SaaS, электронная коммерция, 24/7 услуг.
Плюс: Непрерывная доступность, беспрепятственный пользовательский опыт.
Минусы: Высокая сложность, проблемы с согласованностью данных, дорогостоящие.
Лучшие практики для аварийного восстановления
- Доктор должен работать вОтдельные облачные учетные записиили проекты, чтобы остановить распространение случайных удалений.
- Реализация блокировки и управления объектами включаетнеизменные резервные копиизащитить от фальсификации.
- Первым шагом должен бытьавтоматизацияПоскольку такие инструменты, как Terraform, Ansible и Pulumi позволяют развернуть полную среду DR в течение нескольких минут.
- Организация должна поддерживать точную и текущую документацию дляrunbooks и DR -процедурыи контактные списки.
- Практика моделирования сценариев неудачи черезТестирование хаосаследует выполнять на регулярной основе. Учиться и улучшать.
- Используйте configсканеры или конвейеры CI/CDЧтобы обеспечить паритет между Prod и DR.
- Обеспечить отслеживание, выставление счетов и очистки ресурсов дляОбъединить и проверять всеПолем
Заключение
Организации должны рассматривать аварийное восстановление, чтобы функционировать в качестве основной компетенции, помимо базовых резервных операций, поскольку инфраструктура становится все более распределенной, а угрозы увеличиваются, наличие зрелой осанки DR не подлежит обсуждению. Высокая доступность имеет дело с ожидаемыми ситуациями, но аварийное восстановление позволяет организациям столкнуться с неожиданными бедствиями.
Начните с малого. Выберите модель DR, которая подходит для вашего бизнеса и со временем расширяется. Стоимость профилактики всегда ниже стоимости отказа.
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Предстоящие эксклюзивы для PS5 — график выхода подтвержденных игр
24 октября 2023 г. -
Как подключить беспроводную клавиатуру Apple к Windows 10
18 апреля 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
Categories
- Технологии и IT (25551)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (271)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)
