

Предыстория и сопутствующие работы по расчету справедливости для систем машинного обучения с сохранением конфиденциальности
4 января 2024 г.:::информация Этот документ доступен на arxiv по лицензии CC BY 4.0 DEED.
Авторы:
(1) Эхсан Торейни, Университет Суррея, Великобритания;
(2) Марьям Мехрнежад, Лондонский университет Ройал Холлоуэй;
(3) Аад Ван Мурсел, Бирмингемский университет.
:::
Таблица ссылок
Справочная информация и сопутствующая работа
Анализ внедрения и производительности
2 Предыстория и сопутствующая работа
Одно из преимуществ аудита продуктов на основе машинного обучения связано с доверием. Доверие и надежность (в социотехническом плане) — сложные вопросы. Торейни и др. al [32] предложили основу для технологий надежности в ИИ-решениях, основанную на существующих социальных основах доверия (т.е. демонстрации способностей, доброжелательности и честности, также известных как ABI и ABI+ frameworks) и технологической надежности [30]. Они всесторонне рассмотрели политические документы по регулированию ИИ и существующую техническую литературу и вывели выводы на основе ОД.
Таблица 1. Характеристики FaaS и сравнение с другими предложениями честного машинного обучения, ориентированными на конфиденциальность (поддержка: полная: ✓, частичная: ✙, нет: ✗)
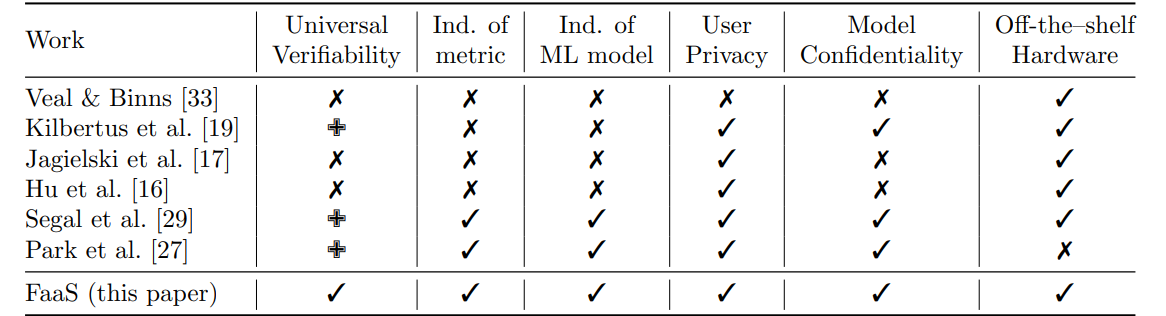
Решение должно демонстрировать справедливость, объяснимость, возможность проверки, а также безопасность и защищенность для установления социального доверия. При использовании решений искусственного интеллекта нельзя быть уверенным в справедливости таких систем, не доверяя репутации поставщика технологий (например, наборов данных и моделей машинного обучения). Принято считать, что ведущие технологические компании не допускают ошибок при их внедрении [8]; однако на практике мы часто наблюдаем, что такие продукты действительно страдают от систематической ошибки в ОД [28, 23].
2.1 Показатели справедливости
В литературе существует несколько определений справедливости. Разработка справедливого алгоритма требует измерения и оценки справедливости. Исследователи долгое время работали над формализацией справедливости. Нарайанан [24] перечисляет в литературе как минимум 21 различное определение справедливости, и это число растет, например, [5, 6].
Справедливость обычно выражается как дискриминация в отношении характеристик данных. Эти функции, по которым может произойти дискриминация, известны как защищенные атрибуты (PA) или конфиденциальные атрибуты. К ним относятся, помимо прочего, этническая принадлежность, пол, возраст, образование, национальность, религия и социально-экономическая группа.
Большинство определений справедливости отражают справедливость по отношению к ООПТ. В этой статье мы рассматриваем групповую справедливость, которая относится к семейству определений, каждое из которых учитывает эффективность модели на уровне групп населения. Определения справедливости в этой группе направлены на обеспечение единообразия решений в разных группах и применимы как к несопоставимому обращению, так и к несопоставимым понятиям воздействия, как это определено в [9, 15].

В этой статье мы сосредоточимся на вычислениях, основанных на трех вышеупомянутых показателях справедливости. Для этого расчета аудитору необходимо иметь доступ к трем частям информации для каждого элемента набора данных: (1) членство в конфиденциальной группе (двоичное значение для A, показывающее, принадлежит или не принадлежит образец к группе с PA) (2) фактическая маркировка образца (двоичное значение Y ) (3) прогнозируемая маркировка образца (двоичное значение Yˆ ). Система ML передает эту информацию для каждого образца из их тестового набора. Затем аудитор использует эту информацию для расчета вышеуказанных показателей справедливости.
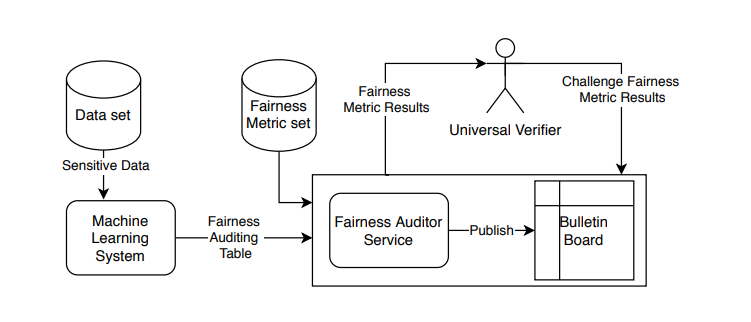
Обратите внимание, что хотя мы рассматриваем приведенные выше метрики для нашего протокола и реализации концепции в следующих разделах, наша базовая архитектура не зависит от метрик, и набор метрик также может быть заменен другими метриками (рис. 1).
2.2 Проверка справедливости моделей ML
Существующие исследования в области честного машинного обучения обычно предполагают, что вычисление показателя справедливости должно выполняться локально системой машинного обучения с полным доступом к данным, включая частные атрибуты [15, 6, 5]. Однако этим подходам недостает проверяемости и независимости, что не обязательно приведет к надежности. Чтобы повысить доверие к продуктам МО, поставщики могут сделать обученную модель самообъясняющей (то есть прозрачной или объяснимой). Существует также подход «прозрачность по замыслу» [12, 2, 34]. Хотя этот подход имеет свои преимущества, он зависит как от модели, так и от сценария [25]; поэтому его нельзя обобщать. Также нет доверенного органа для проверки таких утверждений и объяснений. Более того, на самом деле обученная модель, наборы данных и механизмы извлечения признаков являются активами компании. После раскрытия это может сделать их уязвимыми для конкурентов. Другой подход к обеспечению прозрачности реализации справедливости заключается в аудите «черного ящика», также известном как adhoc [12, 22, 26]. Таким образом, модель обучается и проверяется для различных целей [1]. Это решение аналогично налоговому аудиту и составлению финансовых регистров, где бухгалтеры проверяют и гарантируют законность этих расчетов. не существует каких-либо устоявшихся процессов и ресурсов для расчета справедливости в AI и ML.
Концепция сервиса, рассчитывающего справедливость, была предложена ранее, например, в [33]. Авторы представили архитектуру, позволяющую делегировать вычисление справедливости доверенной третьей стороне, которая выступает гарантом ее алгоритмической справедливости. В этой модели службе справедливости доверяют как система МО, так и другие заинтересованные стороны (например, пользователи и активисты). В частности, система МО должна доверять сервису для обеспечения конфиденциальности данных и секретности своей модели, одновременно раскрывая доверенной третьей стороне результаты алгоритма, конфиденциальные входные данные и даже внутренние параметры модели. Уверенность в том, что третья сторона не будет использовать информацию не по назначению, является большим предположением, и, следовательно, утечка данных и информации о моделях не представляет угрозы.
Чтобы устранить эти ограничения, Kilbertdus et al. [19] предложили систему, известную как «слепое правосудие», которая использует протоколы многосторонних вычислений для обеспечения справедливости в модели МО. В их предложении рассматриваются три группы участников: пользователь (владелец данных), модель (владелец модели ML) и регулятор (который обеспечивает соблюдение показателей справедливости). Эти три группы сотрудничают друг с другом, чтобы обучить справедливую модель МО, используя подход федеративного обучения [35]. Результатом является справедливая модель, обученная с участием этих трех групп с соблюдением конфиденциальности. Они обеспечивают лишь ограниченную степень проверяемости, при которой обученная модель после обучения подвергается криптографической сертификации, и каждый из участников может убедиться, что алгоритм не был модифицирован. Следует отметить, что, поскольку они работают на этапе обучения конвейера ML, их подход сильно зависит от деталей реализации самой модели ML. Ягельский и др. [17] предложили дифференцированный подход к конфиденциальности для обучения справедливой модели. Аналогичным образом, Ху и др. [16] использовали распределенный подход к справедливому обучению, используя только демографическую информацию. Сигал и др. [29] использовали аналогичные криптографические примитивы, но использовали более целостный подход к вычислениям и проверке честности. Они предложили подход, ориентированный на данные, при котором верификатор проверяет обученную модель через зашифрованный и сертифицированный в цифровой форме набор данных с использованием дерева Меркла и других криптографических примитивов. Кроме того, регулирующий орган подтвердит, что модель является справедливой, на основе данных, полученных от клиентов, и набора данных, предоставленных модели. Их подход не обеспечивает универсальной проверяемости, поскольку регулирующий орган является единственной стороной, участвующей в расчете справедливости. Совсем недавно Парк и др. [27] предложили Доверенную среду выполнения (TEE) для безопасного расчета справедливости. Их предложение требует специальных аппаратных компонентов, которые являются криптографически безопасными и обеспечивают достаточные гарантии и проверки для правильного выполнения кода.
Предыдущие исследования обычно интегрировали справедливость в алгоритмы машинного обучения; поэтому такие алгоритмы следует перепроектировать, чтобы использовать другой набор показателей справедливости. Как видно из таблицы 1, FaaS — единственная работа, которая не зависит от модели ML и показателя справедливости и имеет универсальную проверяемость и, следовательно, может использоваться как услуга.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)