
Двигатель Zeta Apache Seatunnel получает значительное повышение скорости через более умное планирование потоков
26 июня 2025 г.Apache Seatunnel Zeta Engine представляет собой специальный двигатель интеграции данных и синхронизации, независимо спроектированный сообществом.
Выпуск № 2279 на Dolphinscheduler Github Repo фокусируется на оптимизированном дизайнеTaskExecutionServiceи модель планирования задач в двигателе Zeta. Благодаря этой замечательной конструкции, Zeta приводит к скачке в результате производительности, которая на скорости быстрее, чем другие вычислительные двигатели с большими данными. Этот дизайн охватывает коммуникационный подходTaskGroup,call()-Дученная модель выполнения, а также две стратегии оптимизации ресурсов потока: статическое теги и динамический обмен потоками.
Теперь давайте глубоко погрузимся в то, как эти инновационные механизмы позволяют Zeta Engine достичьМногократные улучшения производительностиПолем
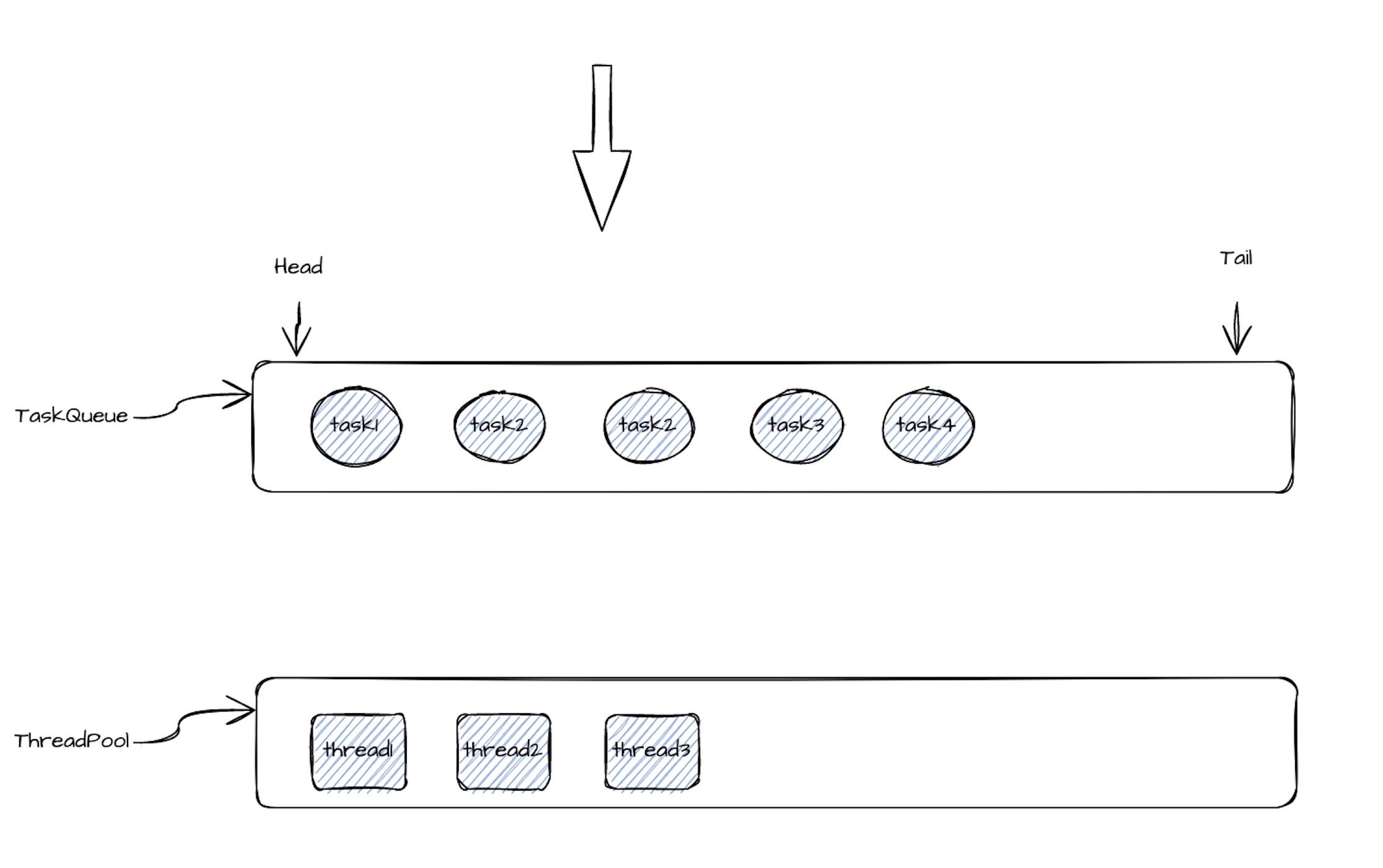
Описание
Taskexectionserver - это служба, которая выполняет задачи и запустит экземпляр на каждом узле. Он получает группу задач от Jobmaster и выполняет задачу в ней. И сохранить TaskId-> TaskContext, и конкретные операции на задаче инкапсулируются в TaskContext. И задача удерживает операционную службу внутри страны, что означает, что задача может удаленно звонить и общаться с другими задачами или Jobmaster через Operationservice.
- Дизайн задач: задачи в группе задач выполняются на одном узле.
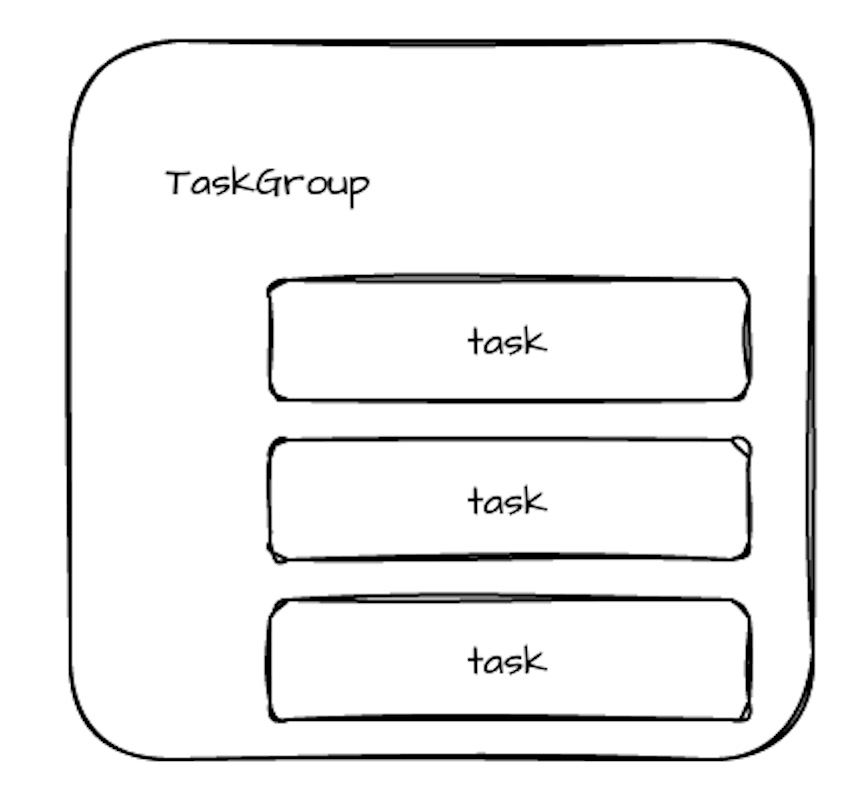
- Точка оптимизации: канал данных между задачами в одной и той же задаче использует локальную очередь. И канал данных между различными группами задач может использовать распределенную очередь (Hazelcast Ringbuffer), потому что он может быть выполнен на разных узлах.
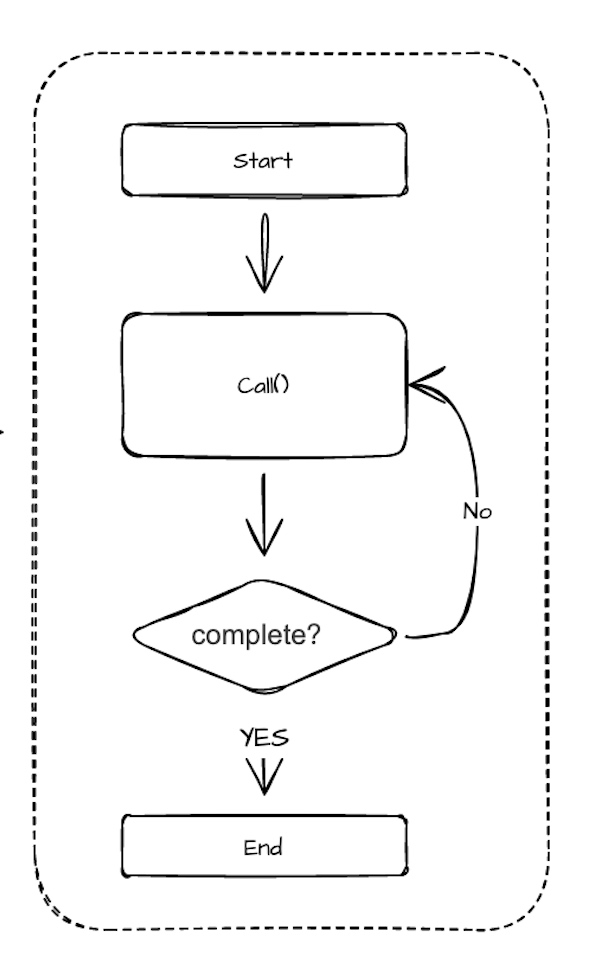
- Проектирование задач: Одним из наиболее важных методов задачи является Call (), и исполнитель управляет операцией задачи, вызывая Call () задачи. Call () будет иметь возвращаемое значение ProgressState, через которое исполнитель может определить, закончилась ли задача, и необходимо ли продолжить вызов Call (). Следующее.
- Оптимизация обмена потоком: фон обмена потоком: в сценарии, где синхронизируется большое количество небольших задач, будет создано большое количество задач. Если каждая задача несет ответственность за одну потоку, она будет тратить ресурсы, запустив большое количество потоков. В настоящее время, если один поток может выполнять несколько задач, эта ситуация будет значительно улучшена. Но как один поток может выполнить несколько задач одновременно? Поскольку задача внутренне управляется вызовом Call () снова и снова, поток может вызовать Call () всех задач, за которые она отвечает по очереди. Следующее.
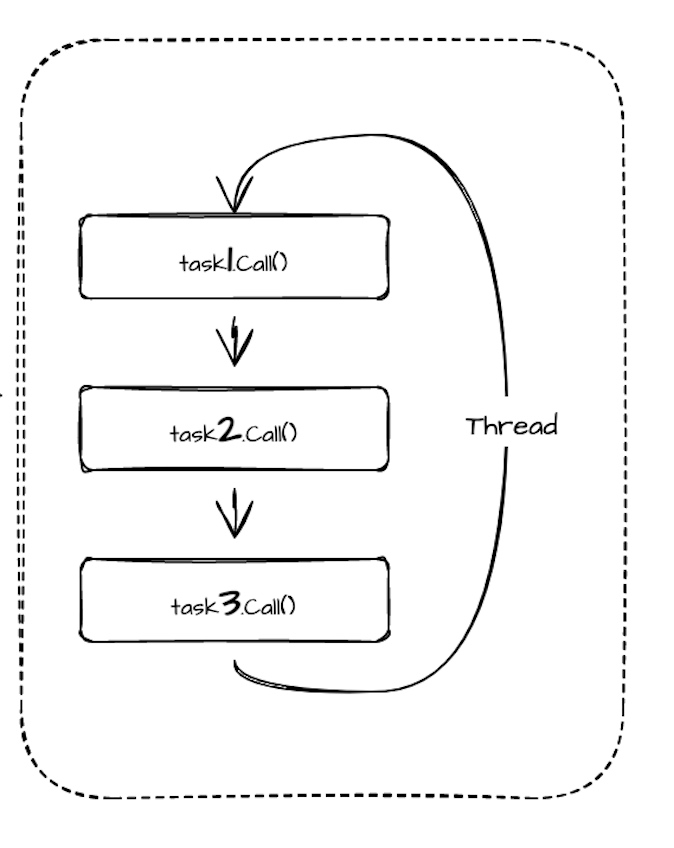
Это также принесет проблему, то есть время выполнения Call () задачи очень длинное. Таким образом, этот поток будет использоваться все время, что приводит к тому, что задержка других задач будет очень серьезной.
Для такой проблемы я временно думаю о двух двух решениях по оптимизации:
- Вариант 1: Маркировка потока.
Предоставьте маркировку задачи и отметьте эту задачу для поддержки обмена потоками. В конкретной реализации задачи отмечает, поддерживает ли задача обмен потоками. Задачи, которые можно обмениваться, поделиться потоком для выполнения, а задачи, которые не могут быть обменом, будут выполняться исключительно потоком.
Поддерживает ли задача обмен потоками, оценивается конкретным исполнителем задачи. В соответствии с временем выполнения метода вызова, если реализация выполнения метода вызова все на уровне MS, то задача может быть помечена как поддерживающий обмен потоками.
- Вариант 2: Динамический поток потока
Существует фундаментальная проблема с вышеупомянутым решением, то есть время выполнения метода вызова часто не исправлено, и сама задача не очень ясна в отношении времени вызова его метода Call (). Потому что разные этапы, разные объемы данных и т. Д., Повлияют на время выполнения Call (). Для того, чтобы такая задача была помечена как поддержка общих потоков или нет. Потому что, если поток помечен как общий поток, если время выполнения вызова метода вызова очень длинное, это приведет к задержке других задач, которые имеют очень высокую текущую поток. Если совместное использование не поддерживается, проблема отходов ресурсов все еще не решается.
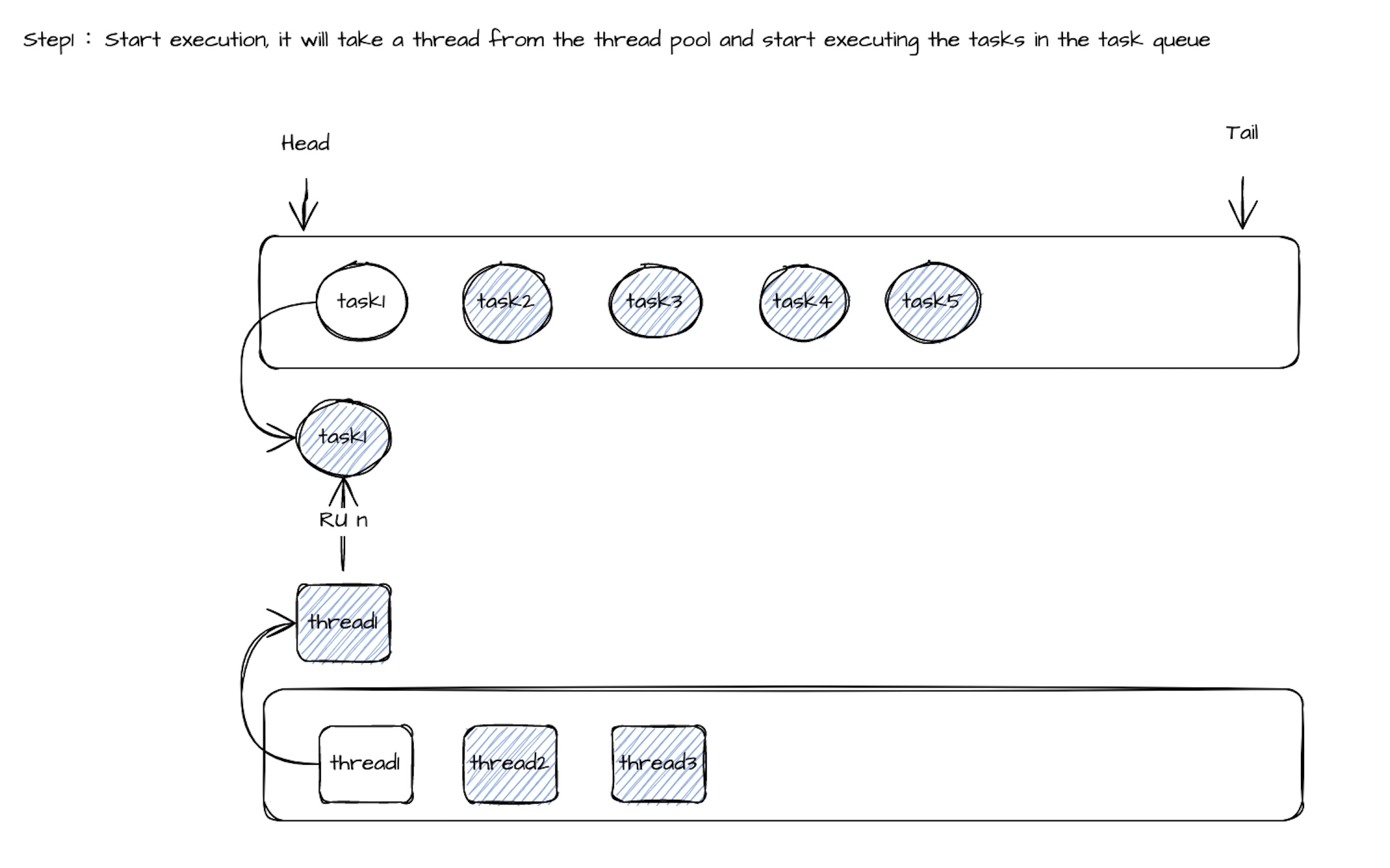
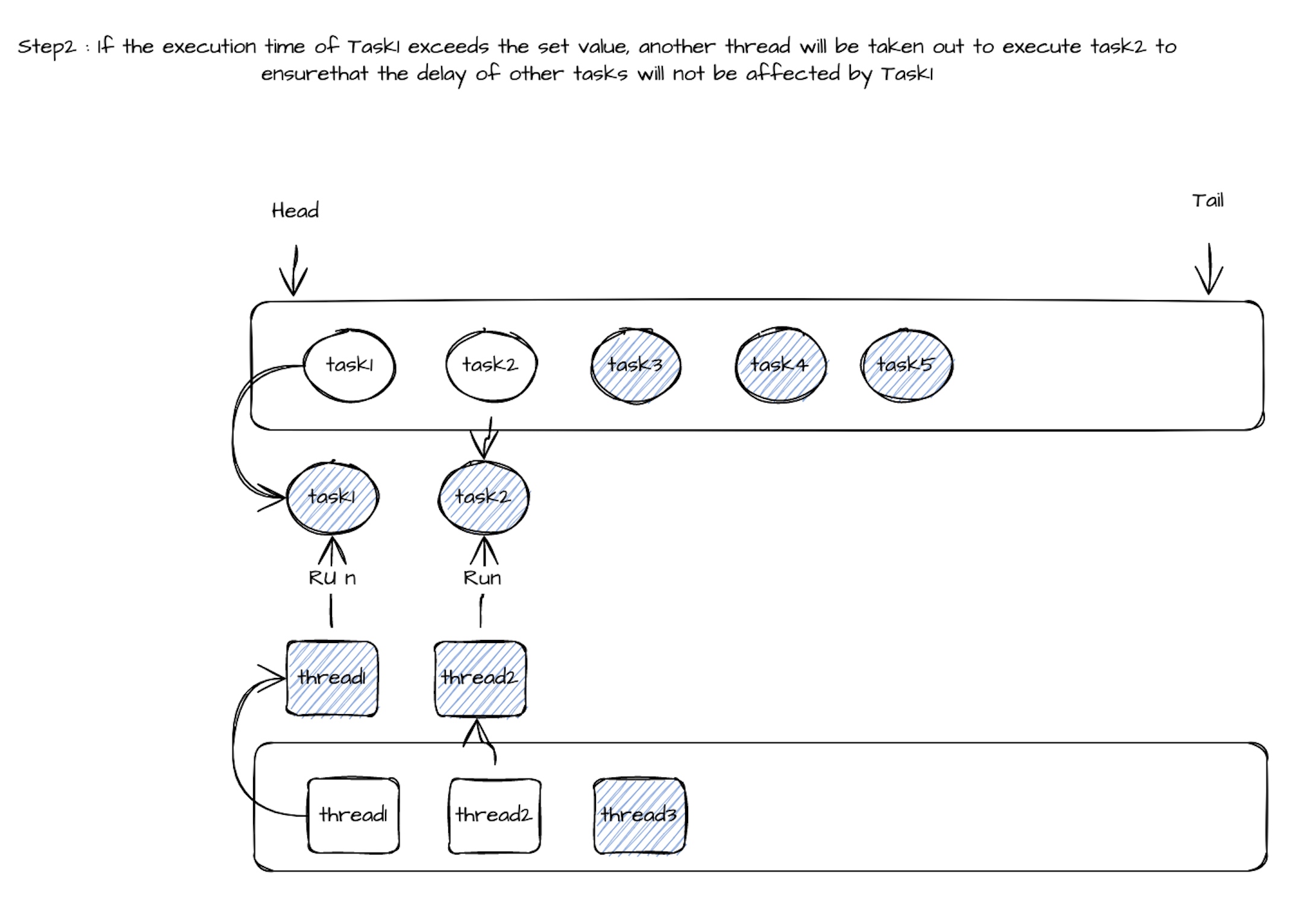
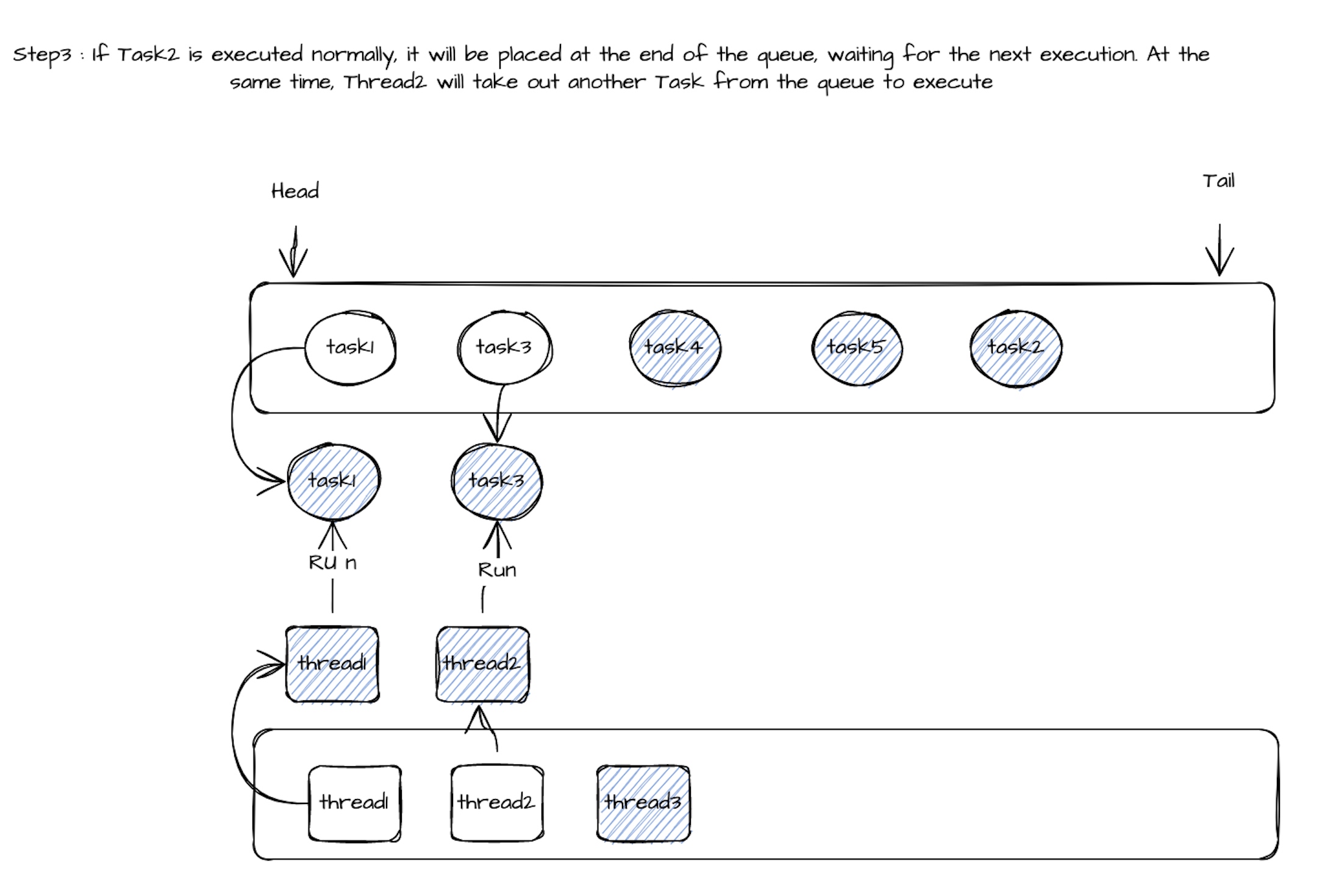
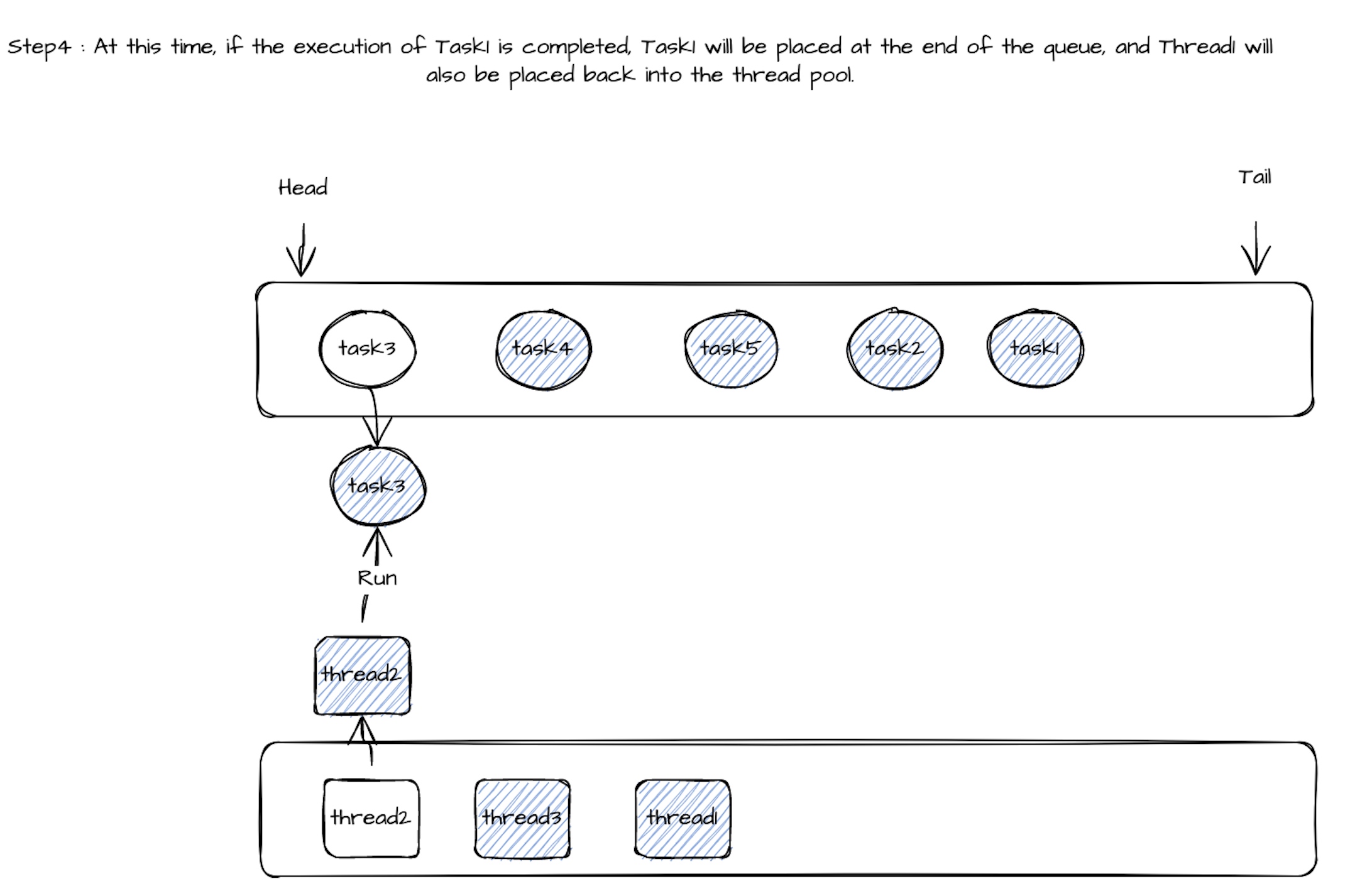
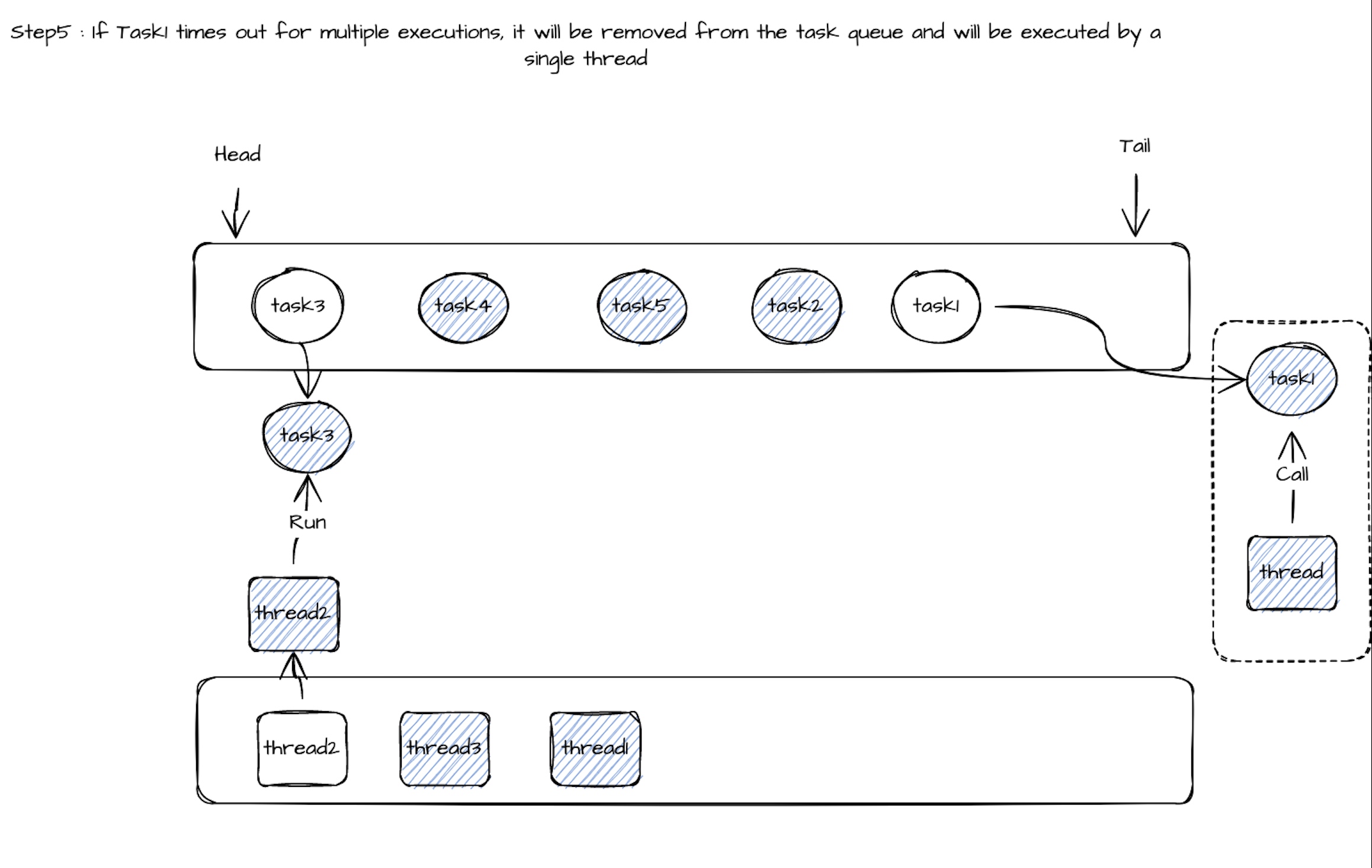
Таким образом, совместное использование потока задачи может быть динамично, а группа задач выполняется пулом потоков (количество задач >> количество потоков). Во время выполнения потока 1, если время выполнения Call () Task1 превышает установленное значение (100 мс), из пула потоков будет выведено потоковое поток2 для выполнения метода вызова следующего Task2. Гарантируется, что задержка других задач не будет слишком высокой из -за длительного времени выполнения задачи 1. Когда метод вызова Task2 обычно выполняется в течение периода времени ожидания, он вернет Task2 в конце очереди задачи, и Thread2 будет продолжать снимать Task3 из очереди задачи, чтобы выполнить метод вызова. Когда метод вызова Task1 будет выполнен, Thread1 будет помещен обратно в пул потоков, а Task1 будет отмечен как раз времени. Когда метод вызова определенной задачи выполняет время ожидания, достигает определенного предела, задача будет удалена из очереди задачи общего потока, а поток будет использоваться исключительно.
Связанный процесс выполнения следующим образом:
Ссылка:https://github.com/apache/seatunnel/issues/2279
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)