

Проанализируйте почти 1 миллиард биткойн-транзакций менее чем за 1 минуту с помощью этого инструмента
27 мая 2023 г.Главное изображение для этой статьи было создано HackerNoon Генератор изображений AI с помощью подсказки «хэши транзакций блокчейна на доске»
В этой статье мы поговорим о секретном инструменте с открытым исходным кодом, о котором никто не знает, который позволяет запрашивать полезные данные из блокчейнов с молниеносной скоростью.
Мы приведем примеры запросов, которые можно сделать, чтобы получить полезные данные из блокчейна, и мы поговорим об архитектуре инструмента, которая позволяет ему выполнять анализ на таких высоких скоростях.
Но перед этим давайте поговорим о том, зачем вообще нужно анализировать транзакции из блокчейна.
Каждая биткойн-транзакция содержит
- адрес отправителя
- адрес получателя
- сумма отправлена
но также
- баланс отправителя
- как долго монеты бездействовали в кошельке отправителя
- баланс получателя
Исходя из вышеизложенного, вы можете экстраполировать и получить информацию о
* Как долго отправитель обычно хранит свои биткойны перед отправкой * Каков средний баланс всех кошельков на блокчейне * Средний размер транзакции
и более 100 других аналитических данных.
Как видите, данные, которые мы можем получить о рынке биткойнов, гораздо более полны по сравнению с традиционными рынками. И самое главное, доступ к нему может получить обычный человек. Напротив, только хедж-фонды и банки имеют доступ к подобным данным на устаревших рынках.
<цитата>Следовательно, анализируя транзакции в блокчейне биткойнов, можно лучше понять рынок биткойнов и принимать более обоснованные инвестиционные решения на основе этих данных.
Помимо применения аналитики блокчейна в торговле и инвестировании, существует множество других способов использования анализа блокчейна:
* Деанонимизация адресов кошельков * Выявление незаконной деятельности * Соответствие
Так как же работает этот инструмент?
Архитектура BlockSci
BlockSci направлен на устранение трех проблем существующих инструментов анализа блокчейна:
- плохая производительность,
- ограниченные возможности
- и громоздкий программный интерфейс.
Низкая производительность — это проблема, которую BlockSci решает лучше всего. Например, подход грубой силы к анализу биткойн-транзакций также сработает. Вы можете запустить биткойн-узел на своем компьютере/сервере и напрямую запрашивать свой собственный узел. Но этот подход настолько медленный, что для обработки всех 1 миллиарда биткойн-транзакций могут потребоваться годы.
Другие существующие инструменты также страдают от низкой производительности, особенно при использовании графовых баз данных общего назначения, что делает их медленнее в сотни раз для последовательных запросов и существенно медленнее для всех запросов, включая запросы обхода графа.
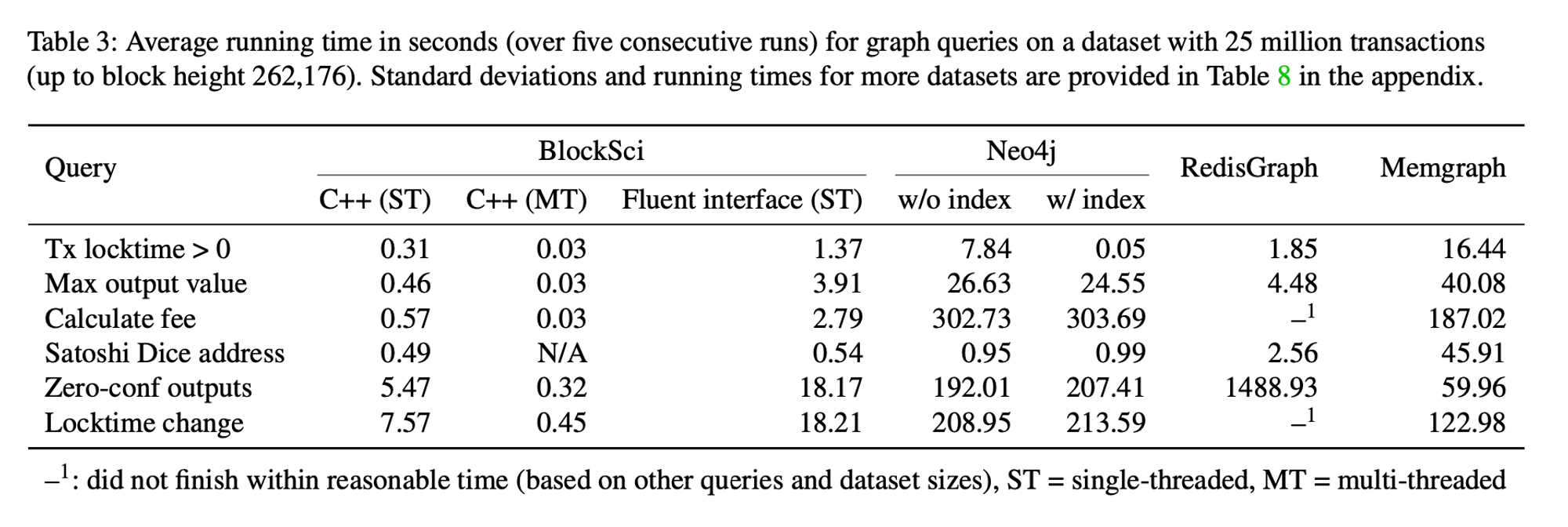
Дизайн BlockSci в основном основан на том факте, что в блокчейнах блоки в прошлом не могут быть изменены, а все новые данные, которые появляются в блокчейне, доступны только для добавления.
Это означает, что свойства ACID транзакционных баз данных не нужны, что делает естественным выбором аналитическую базу данных в памяти. Использование памяти вместо дискового хранилища значительно ускоряет обработку данных, что нам и нужно.
Фактически, BlockSci загружает в память весь блокчейн для выполнения вычислений и избегает подхода распределенной обработки. Это мотивировано тем фактом, что данные блокчейна имеют графическую структуру, и поэтому их трудно эффективно разделить.
Его разработчик предположил, что использование традиционной распределенной базы данных транзакций для анализа цепочки блоков имеет бесконечные СТОИМОСТИ (конфигурация, которая превосходит один поток) в том смысле, что ни один уровень параллелизма не может превзойти оптимизированную однопоточную реализацию.
Он также применяет несколько методов, таких как преобразование хэш-указателей в фактические указатели и дедупликацию адресных данных, чтобы еще больше увеличить скорость и уменьшить размер данных.
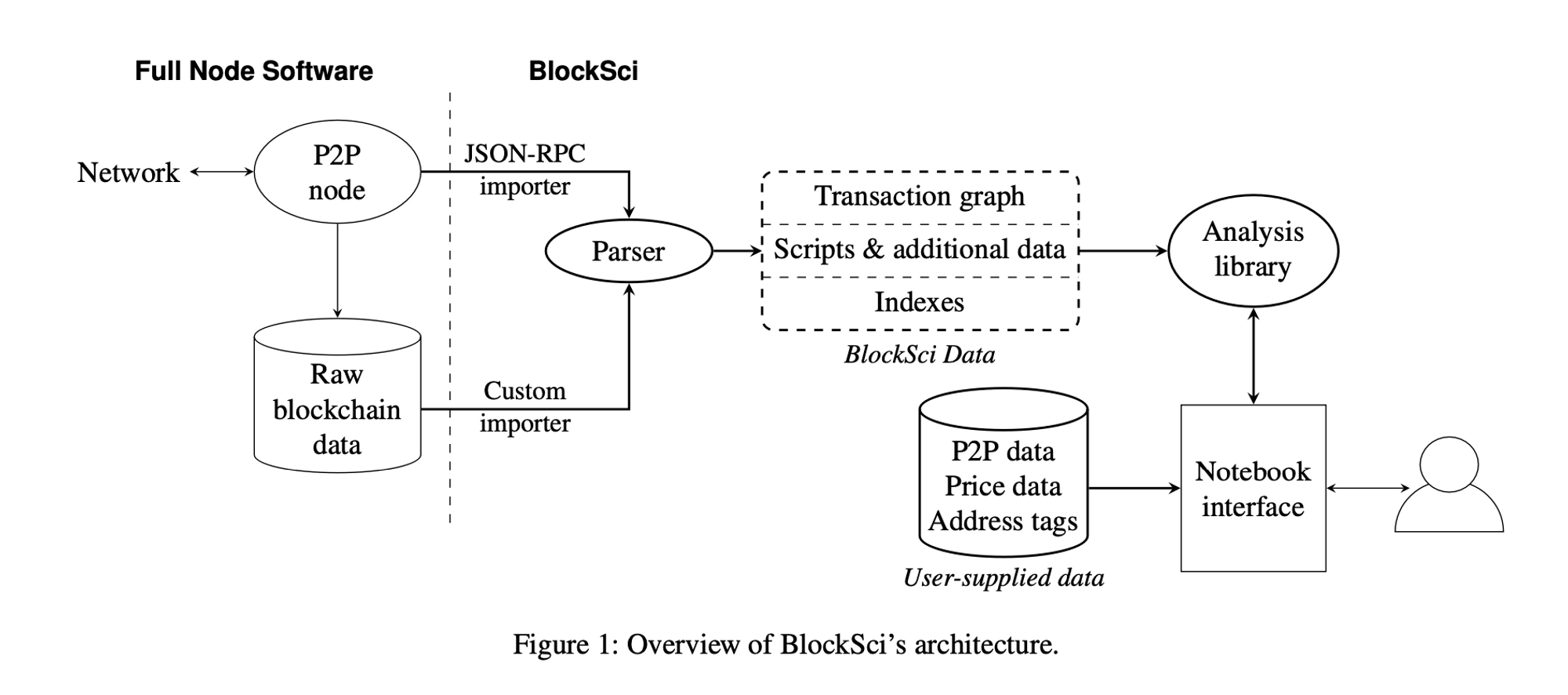
Для импорта данных из узла BlockSci использует собственный высокопроизводительный импортер, который напрямую считывает необработанные данные с диска, а НЕ из встроенного интерфейса JSON-RPC. Даже в этом случае импорт и индексация всех данных с узла обычно занимает 24 часа. Однако после того, как данные проанализированы, фактическая аналитика выполняется быстро.
То, как блокчейны хранятся на дисках, непросто проанализировать. Они созданы для других целей, таких как проверка транзакций и поиск данных в большой сети. Они также созданы для экономии места в памяти за счет сохранения блоков на диске в базовом формате. Но нам нужно изменить данные, чтобы они поместились в памяти, поэтому у BlockSci есть парсер, который справится с этим шагом. Мы убедились, что этот парсер хорошо оптимизирован.
Еще один способ, с помощью которого инструмент достигает таких высоких скоростей, — это «оптимизация фильтра Блума». Фильтр Блума — это вероятностная структура данных, которая позволяет проверять принадлежность к множеству. В контексте блокчейн он сохраняет все просмотренные адреса и обеспечивает правильность поиска существующих адресов, сводя к минимуму количество запросов к базе данных для несуществующие. Это достигается за счет того, что около 88 % входных данных расходуют выходные данные, созданные в последних 4 000 блоков, и что только 8,6 % биткойн-адресов используются более одного раза.
Последней наиболее важной оптимизацией, которая позволяет BlockSci достичь высокой скорости анализа, является структура макета данных, которая обеспечивает высокую скорость анализа и не требует слишком большого объема памяти.
Структура данных BlockSci делит доступные данные на три категории и объединяет их в гибридной схеме. Основной граф транзакций требуется для большинства анализов и всегда загружается в память и хранится в построчном формате. Скрипты и дополнительные данные, необходимые только для части анализов, хранятся в гибридном формате (частично на основе столбцов, частично на основе строк) и загружаются по требованию. Индексы для поиска отдельных транзакций или адресов по хешу хранятся в отдельной базе данных на диске.
Кроме того, он использует кодировку фиксированного размера для полей данных, где это возможно, оптимизирует структуру памяти для локальности ссылок, связывает выходные данные с входными данными для эффективного обхода, а также использует сопоставление памяти и параллелизм.
Наконец, вот запрос, который находит все транзакции с комиссией> 0,1 биткойна менее чем за минуту.
chain.blocks.txes.where(lambda tx: tx.fee > 10**7).to_list()
Обзор
BlockSci – это инструмент для анализа блокчейнов, который позволяет молниеносно запрашивать полезные данные из блокчейнов. Анализируя биткойн-транзакции, можно лучше понимать рынок и принимать более обоснованные инвестиционные решения.
Архитектура BlockSci основана на том факте, что данные блокчейна имеют графическую структуру и их трудно эффективно разделить, поэтому он загружает весь блокчейн в память для выполнения вычислений. Он применяет несколько методов для увеличения скорости, включая преобразование хэш-указателей в фактические указатели, дедупликацию адресных данных и использование оптимизации фильтра Блума. Структура макета данных обеспечивает высокую скорость аналитики и не требует слишком большого объема памяти.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27702)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)