ИИ и персональные данные: знает ли GPT-3 что-нибудь обо мне?
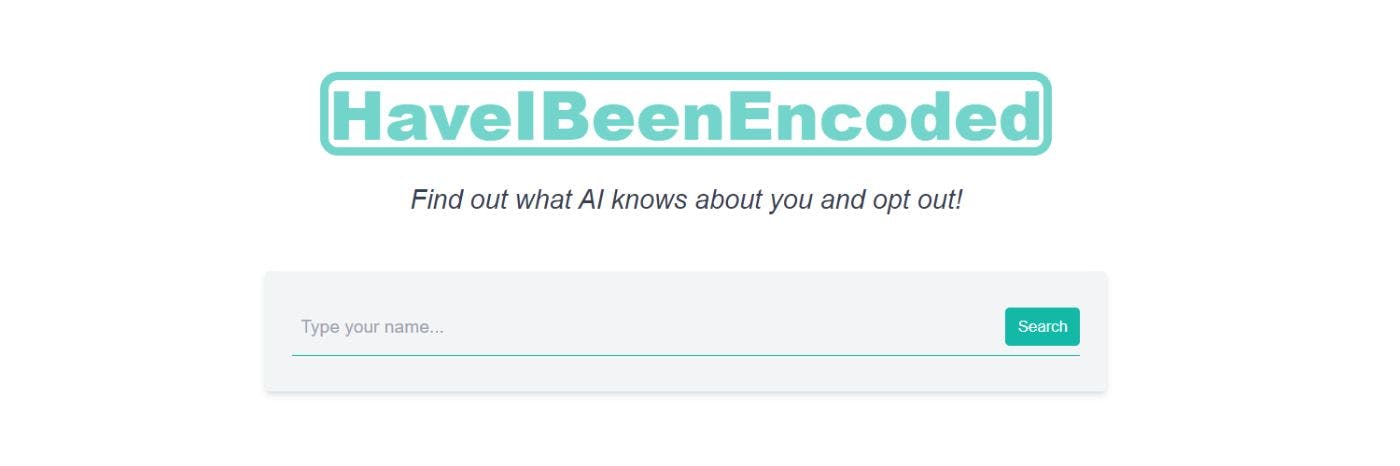
9 марта 2023 г.Я создал сайт, который позволяет вам отслеживать, что о вас знают разные модели большого языка. Вы достаточно важны, чтобы быть закодированными? Получите электронное письмо, когда вас добавят в модели ИИ, или сообщите гигантам больших технологий, что вы хотите отказаться.
Все началось с невинного вопроса в ChatGPT о компании, соучредителем которой я был.
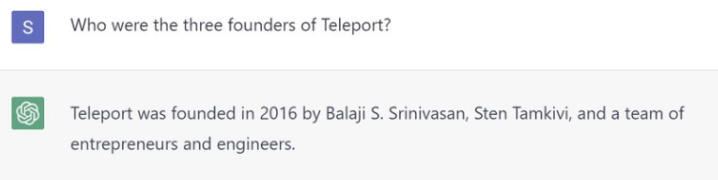
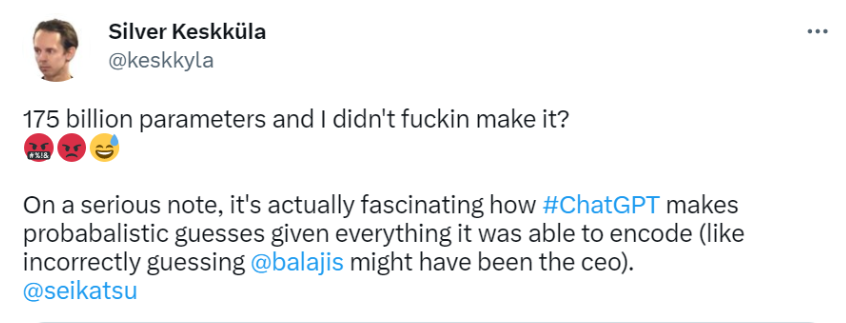
Несмотря на то, что меня огорчило то, что они недостаточно важны для кодирования, я был заинтригован природой того, как большие языковые модели кодируют информацию и генерируют выходные данные вероятностным образом.
Мне сразу захотелось узнать три вещи:
- Закодировано ли вообще мое имя или когда оно будет закодировано?
- Действительно ли я хочу, чтобы меня кодировали?
- Могу ли я как-то отказаться, если я не хочу, чтобы меня кодировали?
Я закодирован и буду ли когда-нибудь им?
Хотя мое имя не появлялось в обучающих данных достаточно часто, чтобы просто ответить на прямой вопрос обо мне, GPT-3 по-прежнему может выводить мое имя при подсказке правильных вопросов. Очевидно, что мы все будем кодироваться по мере роста размеров параметров модели, поэтому для меня интересен вопрос, КОГДА будет моя очередь?
Я опросила свою ближайшую сеть, чтобы узнать, был ли кто-то еще достаточно тщеславен, чтобы расспросить ChatGPT о себе, и оказалось, что это становится новым «погуглить». Каждый пятый человек, который пробовал использовать ChatGPT, спрашивал о себе.
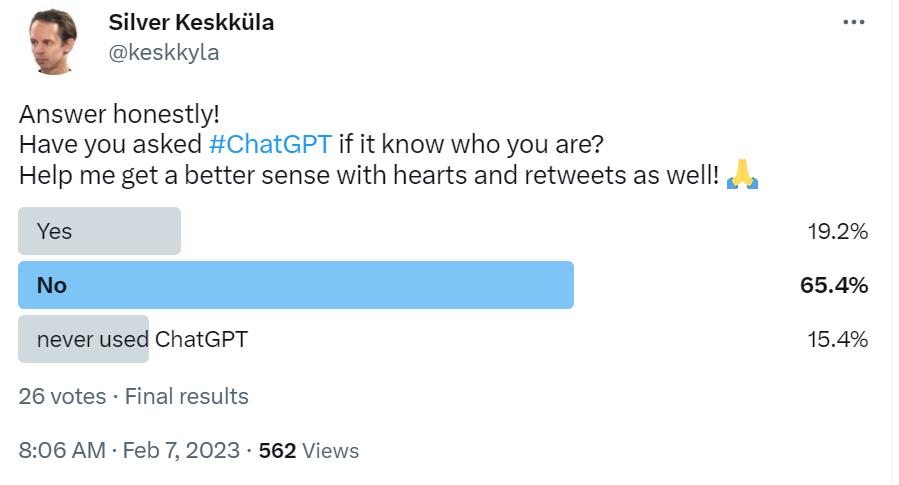
Поскольку это был не только я, я решил создать сервис, предназначенный для регулярного опроса API OpenAI GPT-3, и сделать его доступным для всех на haveibeenencoded.com. Я уверен, что многие из вас узнают источник вдохновения для названия haveibeenpwned.com.
Я также наткнулся на сайт haveibeentrained.com, посвященный визуальным медиа и, в частности, последним достижениям в стабильной диффузии. Это позволяет художникам как искать свои работы, используемые в обучающих данных ИИ, так и регистрироваться, чтобы указать, что они не согласны.
Увидев, что кто-то придумал подобное решение для художественного оформления, стало очевидно, что это то, что я хотел создать.
<цитата>Я хочу помочь людям отслеживать, что модели искусственного интеллекта знают о них (включая данные, позволяющие установить личность), и поддержать их усилия по обращению к крупным технологическим компаниям с просьбой НЕ включать их данные.
Почему? Читать дальше…
Хочу ли я, чтобы меня кодировали?
Поэкспериментировав с LLM, вы быстро поймете, насколько креативны эти модели. Например, ChatGPT знает, что я работаю в эстонском секторе стартапов и технологий, но будет приписывать моему имени всевозможные компании, несмотря на то, что это не соответствует действительности.
Поскольку LLM встроены в поисковые системы, пока мы говорим, все перестанет быть интересным, когда есть риск, что люди начнут серьезно относиться к некоторым из этих творческих результатов.
Фактически, сам LLM говорит об этом лучше всего:
<цитата>Последствия самостоятельного поиска в Google языковых моделей, таких как GPT-3 OpenAI, могут быть значительными. Эти модели невероятно эффективны и могут понимать и генерировать человекоподобный текст, поэтому, когда вы гуглите себя с помощью GPT-3, вы можете найти информацию, которая кажется написанной человеком, но на самом деле была сгенерирована моделью. Это может включать ложную или вводящую в заблуждение информацию, которая может нанести ущерб вашей репутации или вызвать путаницу.
<цитата>Еще один вывод заключается в том, что GPT-3 и другие языковые модели могут генерировать информацию в таком масштабе и со скоростью, за которой человеку сложно уследить, что может привести к информационной перегрузке и трудностям в определении того, что является точным, а что нет. не является. Кроме того, поскольку языковые модели могут генерировать информацию по любой теме, существует риск столкнуться с неприемлемым или оскорбительным содержанием, которое может нанести вред вашему благополучию.
В заключение, хотя поиск в Google языковых моделей, таких как GPT-3, может быть интересным и предоставить много информации, важно быть осторожным с информацией, которую вы найдете, и принять меры для проверки ее точности.
Я начну с OpenAI GPT3 с доступным официальным API и продемонстрирую, насколько творческими могут быть эти модели, но вы получите электронное письмо, когда будут добавлены другие модели или их ответы о вас изменятся.
Могу ли я отказаться?
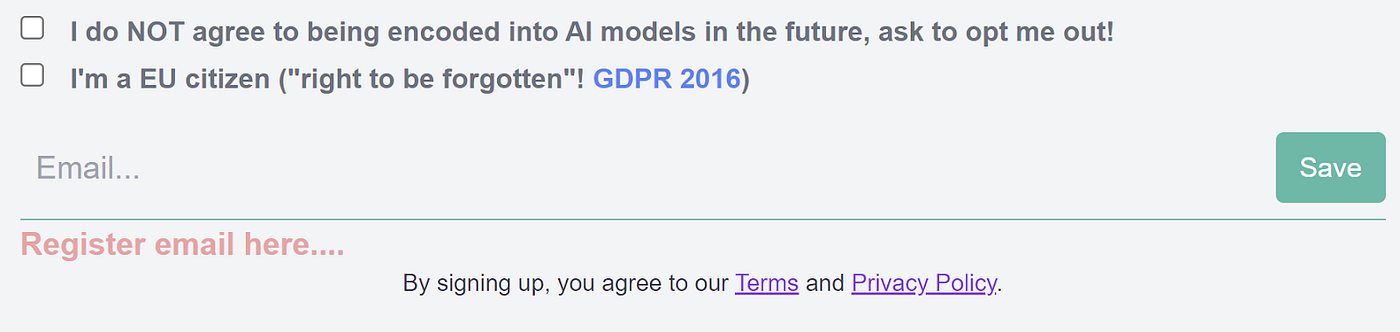
На данный момент мне неизвестны какие-либо «простые» способы отказа, поскольку эта технология является новой. В Европейском союзе, например, граждане имеют право на «забвение» и могут запросить удаление определенных персональных данных из поисковых систем. В настоящее время неясно, как эти законы будут применяться в контексте генеративных моделей, но нам лучше разобраться с этим, пока ситуация не вышла из-под контроля.
Количество всплывающих LLM будет значительным, и не имеет смысла просить каждого из них НЕ включать ваши данные, поэтому я выясню точные необходимые юридические шаги и автоматизацию, чтобы сделать это очень простым для всех. Я уже связался со своими контактами в Google, Stability.ai и Microsoft, чтобы убедиться, что мы начинаем прокладывать путь.
Если это звучит для вас хорошо, вы можете зарегистрироваться ниже и убедиться, что tp указывает, хотите ли вы просто знать, когда ваше имя будет добавлено в модели ИИ, или вы действительно хотите, чтобы мы связались с крупными технологическими компаниями, чтобы запросить ваши данные для быть удалены.
:::информация Отказ от ответственности:
Это первые шаги на моем пути, и HaveIBeenEncoded использует набор довольно консервативных параметров для создания более надежных выходных данных из модели. Не обижайтесь, если вы важны, а модели говорят, что не знают вас. Это только вопрос времени, в конце концов они это сделают. Если вы этого хотите.
:::
Зарегистрируйтесь, чтобы узнать, когда это произойдет, и попробуйте прямо сейчас!
Первоначально опубликовано в моем личном блоге.
Оригинал