

Развитие платформ наблюдения: модернизация обработки данных и сокращение затрат с помощью Apache Doris
29 декабря 2023 г.Платформы наблюдения сродни иммунной системе. Подобно тому, как иммунные клетки присутствуют повсюду в организме человека, платформа наблюдения патрулирует каждый уголок ваших устройств, компонентов и архитектур, выявляя любые потенциальные угрозы и активно их снижая. Однако я, возможно, зашел слишком далеко с этой метафорой, потому что до сих пор мы никогда не изобрели столь сложную систему, как человеческое тело, но мы всегда можем добиться прогресса.
Ключом к обновлению платформы наблюдения является увеличение скорости обработки данных и снижение затрат. Это обусловлено двумя причинами:
- Чем быстрее вы сможете выявить отклонения в своих данных, тем больше вы сможете сдержать потенциальный ущерб.
2. Платформа наблюдения должна хранить море данных, и низкая стоимость хранения — единственный способ сделать это устойчивым.
Этот пост посвящен тому, как GuanceDB, платформа наблюдения, добилась прогресса в этих двух аспектах, заменив Elasticsearch на Apache Doris в качестве механизма запросов и хранения. Результат: затраты на хранение данных сокращаются на 70 %, а производительность запросов данных увеличивается на 200–400 %.
БД данных Guance
GuanceDB — это универсальное решение для наблюдения. Он предоставляет услуги, включая анализ данных, визуализацию данных, мониторинг и оповещение, а также проверку безопасности. С помощью GuanceDB пользователи могут получить представление о своих объектах, производительности сети, приложениях, пользовательском опыте, доступности системы и т. д.
С точки зрения конвейера данных GuanceDB можно разделить на две части: прием данных и анализ данных. Я доберусь до них один за другим.
Интеграция данных
Для интеграции данных GuanceDB использует собственный инструмент DataKit. Это универсальный сборщик данных, который извлекает данные из различных конечных устройств, бизнес-систем, промежуточного программного обеспечения и инфраструктуры данных. Он также может предварительно обрабатывать данные и связывать их с метаданными. Он обеспечивает обширную поддержку данных: от журналов и показателей временных рядов до данных распределенной трассировки, событий безопасности и поведения пользователей из мобильных приложений и веб-браузеров. Чтобы удовлетворить разнообразные потребности в различных сценариях, он обеспечивает совместимость с различными зондами и сборщиками с открытым исходным кодом, а также с источниками данных пользовательских форматов.
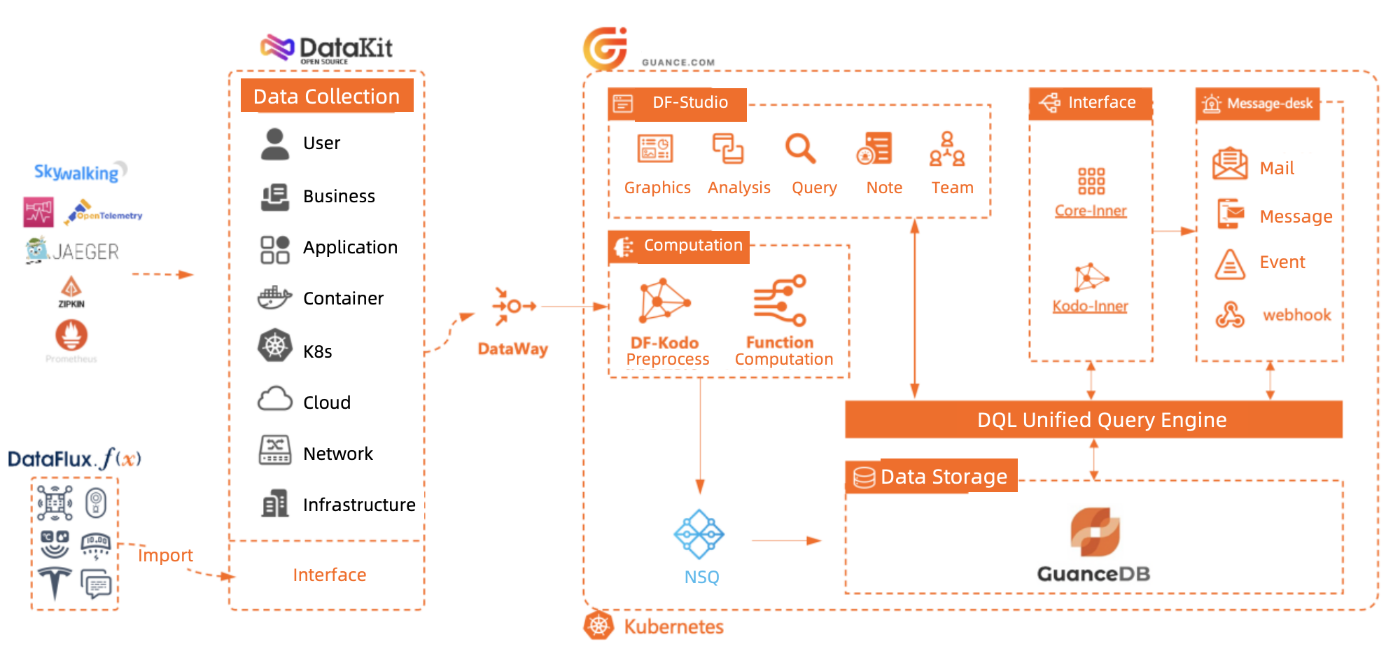
Запрос & механизм хранения
Данные, собранные с помощью DataKit, проходят через основной уровень вычислений и поступают в GuanceDB, которая представляет собой многомодельную базу данных, сочетающую в себе различные технологии баз данных. Он состоит из уровня механизма запросов и уровня механизма хранения. Разделяя механизм запросов и механизм хранения, он обеспечивает подключаемую и взаимозаменяемую архитектуру.
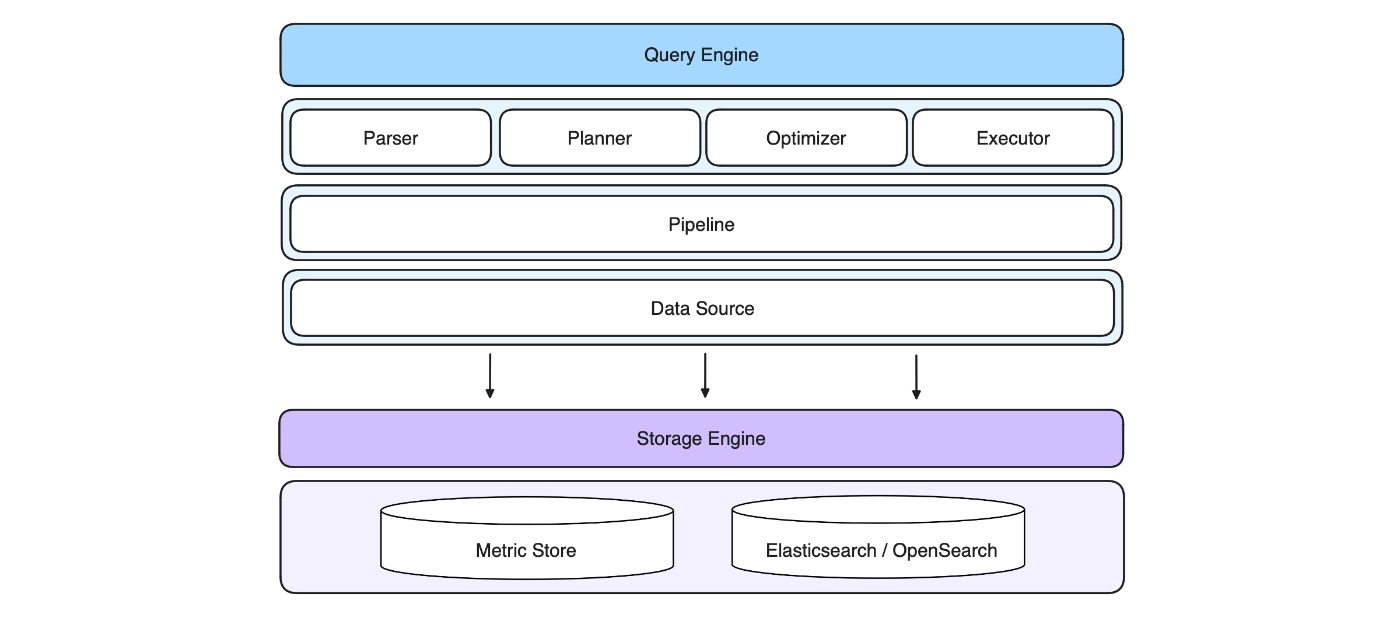
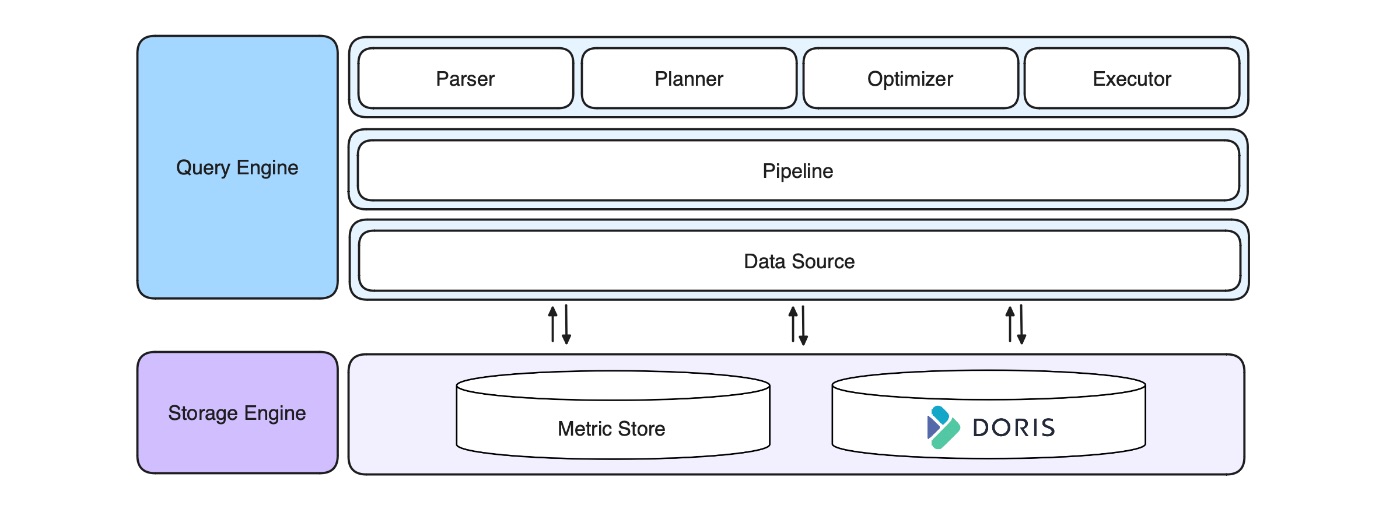
Для данных временных рядов они создали Metric Store — механизм хранения собственной разработки на основе VictoriaMetrics. Для журналов они интегрируют Elasticsearch и OpenSearch. GuanceDB демонстрирует высокую производительность в этой архитектуре, а Elasticsearch демонстрирует возможности для улучшения:
* Запись данных: Elasticsearch потребляет большую часть ресурсов ЦП и памяти. Выполнение запроса не только затратно, но и мешает.
* Поддержка без схемы. Elasticsearch обеспечивает поддержку бессхемного типа с помощью динамического сопоставления, но этого недостаточно для обработки большого количества пользовательских полей. В этом случае это может привести к конфликту типов полей и, как следствие, к потере данных.
* Агрегация данных. Большие задачи агрегирования часто вызывают ошибку тайм-аута в Elasticsearch.
Здесь происходит обновление. GuanceDB попыталась заменить Elasticsearch на Apache Doris.
DQL
На платформе наблюдения GuanceDB почти все запросы включают фильтрацию меток времени. Между тем, большинство агрегаций данных необходимо выполнять в течение определенных временных интервалов. Кроме того, существует необходимость выполнять объединение данных временных рядов по отдельным последовательностям во временном окне. Выражение этой семантики с помощью SQL часто требует вложенных подзапросов, что приводит к сложным и громоздким операторам.
Вот почему GuanceDB разработала собственный язык запросов данных (DQL). Благодаря упрощенным элементам синтаксиса и вычислительным функциям, оптимизированным для случаев использования с возможностью наблюдения, этот DQL может запрашивать метрики, журналы, данные объектов и данные распределенной трассировки.
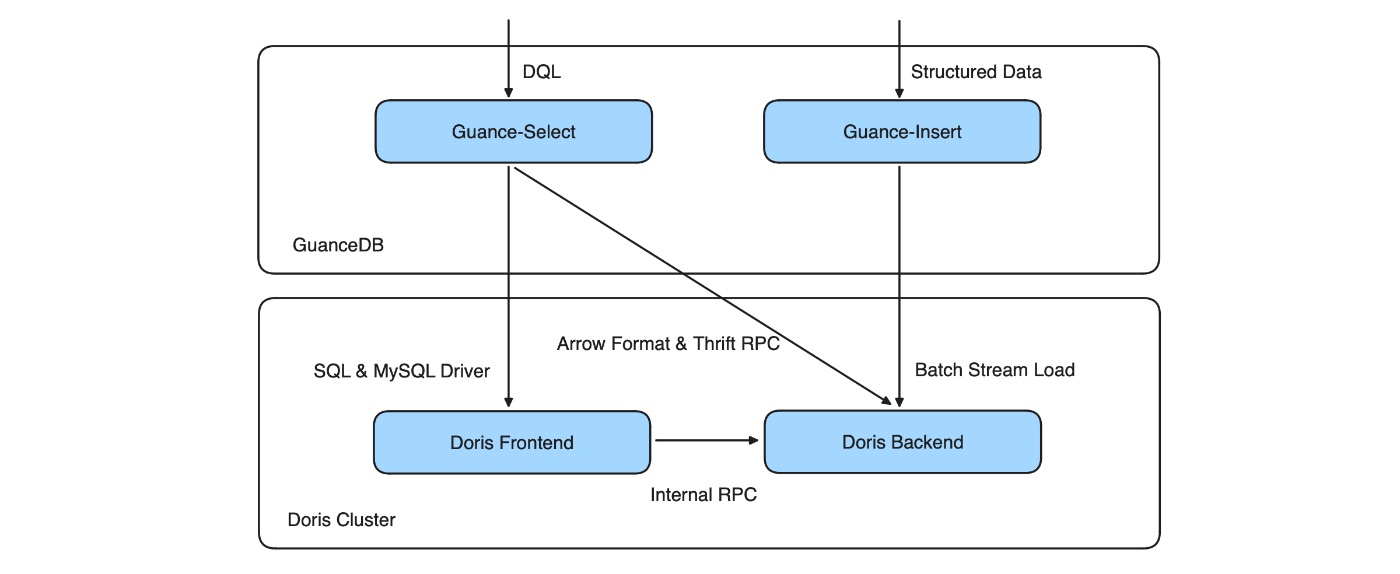
Вот как DQL работает вместе с Apache Doris. GuanceDB нашла способ в полной мере использовать аналитические возможности Doris, дополняя при этом ее функциональные возможности SQL.
Как показано ниже, Guance-Insert — это компонент записи данных, а Guance-Select — это механизм запросов DQL.
* Guance-Insert: позволяет накапливать данные разных арендаторов в разных пакетах и обеспечивает баланс между пропускной способностью записи и задержкой записи. Когда журналы генерируются в больших объемах, задержка данных может составлять 2–3 секунды.
* Guance-Select: при выполнении запроса, если семантика или функция SQL запроса поддерживается в Doris, Guance-Select передает запрос во внешний интерфейс Doris для вычислений; в противном случае будет использован запасной вариант: получить столбцовые данные в формате Arrow через интерфейс Thrift RPC, а затем завершить вычисления в Guance-Select. Загвоздка в том, что он не может передать логику вычислений в Doris Backend, поэтому он может быть немного медленнее, чем выполнение запросов в Doris Frontend.
Наблюдения
Стоимость хранилища снижена на 70 %, скорость запросов увеличена на 300 %.
Раньше в кластерах Elasticsearch использовалось 20 облачных виртуальных машин (16 виртуальных ЦП, 64 ГБ) и были независимые службы записи индексов (это еще 20 облачных виртуальных машин). Теперь, благодаря Apache Doris, им нужно всего лишь 13 облачных виртуальных машин одной и той же конфигурации, что означает снижение затрат на 67 %. Этому способствуют три возможности Apache Doris:
* Высокая пропускная способность записи. При постоянной скорости записи 1 ГБ/с Doris поддерживает загрузку ЦП на уровне менее 20 %. Это соответствует 2,6 облачным виртуальным машинам. Благодаря низкой загрузке ЦП система становится более стабильной и лучше подготовлена к внезапным пикам записи.
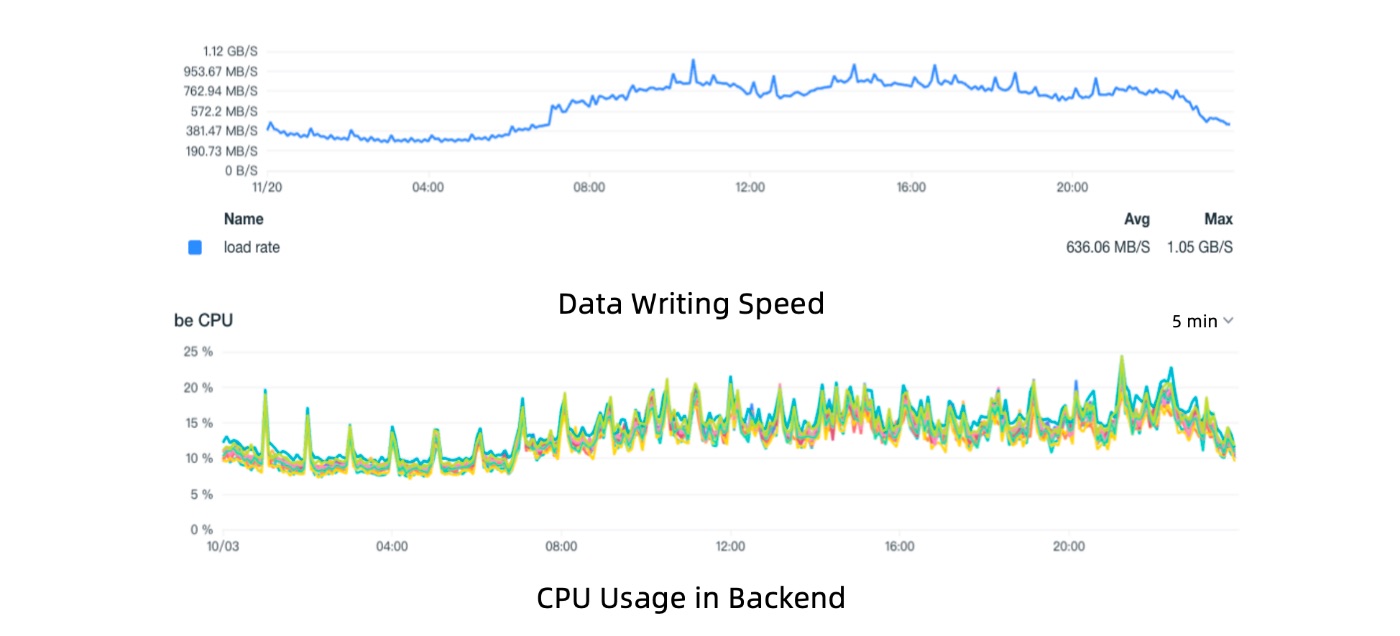
* Высокая степень сжатия данных: Дорис использует алгоритм сжатия ZSTD поверх столбчатого хранилища. Он может реализовать степень сжатия 8:1. По сравнению с соотношением 1,5:1 в Elasticsearch, Doris может сократить затраты на хранение примерно на 80 %.
* Многоуровневое хранилище : Doris предлагает более экономичный способ хранения данных: размещение «горячих» данных на локальных дисках и «холодное» хранилище объектов данных. После настройки политики хранения Doris может автоматически управлять процессом «перезарядки» горячих данных и перемещать холодные данные в объектное хранилище. Такой жизненный цикл данных прозрачен для уровня приложения данных, поэтому он удобен для пользователя. Кроме того, Дорис ускоряет холодные запросы данных с помощью локального кэша.
Благодаря более низким затратам на хранение Doris не снижает производительность запросов. Это удваивает скорость выполнения запросов, возвращающих одну строку, и запросов, возвращающих набор результатов. Для агрегирующих запросов без выборки Doris работает в четыре раза быстрее, чем Elasticsearch.
Подводя итог, Apache Doris обеспечивает производительность запросов в 2–4 раза выше, чем Elasticsearch, потребляя всего 1/3 затрат на хранилище.
Инвертированный индекс для полнотекстового поиска
Инвертированный индекс – это волшебное средство для анализа журналов, поскольку оно может значительно повысить производительность полнотекстового поиска и сократить накладные расходы на запросы.
Это особенно полезно в следующих сценариях:
* Полнотекстовый поиск по MATCH_ALL, MATCH_ANY и MATCH_PHRASE. MATCH_PHRASE в сочетании с инвертированным индексом является альтернативой функции полнотекстового поиска Elasticsearch.
* Запросы эквивалентности (=, ! =, IN), запросы диапазона (>, >=, <, <=) и поддержка числовых значений, даты и времени и строк.
Будучи мощным ускорителем полнотекстового поиска, инвертированный индекс в Doris является гибким, поскольку мы наблюдаем необходимость корректировок по требованию. В Elasticsearch индексы фиксируются при создании, поэтому необходимо тщательно спланировать, какие поля необходимо индексировать; в противном случае любые изменения в индексе потребуют полной перезаписи.
Напротив, Doris допускает динамическое индексирование. Вы можете добавить инвертированный индекс к полю во время выполнения, и он вступит в силу немедленно. Вы также можете решить, для каких разделов данных создавать индексы.
Новый тип данных для динамического изменения схемы
По своей природе платформа наблюдения требует поддержки динамической схемы, поскольку собираемые ею данные подвержены изменениям. Каждый клик пользователя на веб-странице может добавить в базу данных новый показатель.
Осмотрев среду баз данных, вы обнаружите, что статическая схема является нормой. Некоторые базы данных идут еще дальше. Например, Elasticsearch реализует динамическую схему путем сопоставления. Однако эта функциональность может быть легко нарушена из-за конфликтов типов полей или неистекших исторических полей.
Решение Doris для динамической схемы — это недавно представленный тип данных Variant, и GuanceDB одной из первых опробовала его. (Официально он будет доступен в Apache Doris V2.1.)
Тип данных Variant — это шаг Дорис к использованию полуструктурированного анализа данных. Это может решить множество проблем, которые часто беспокоят пользователей баз данных:
* JSON хранилище данных: столбец Variant в Doris может содержать любые допустимые данные JSON и автоматически распознавать подполя и типы данных.
* Разрыв схемы из-за слишком большого количества полей: часто встречающиеся подполя будут храниться в виде столбцов для облегчения анализа, а менее часто встречающиеся подполя будут объединены в один столбец для оптимизации данных. схема.
* Ошибка записи из-за конфликта типов данных. Столбец Variant допускает использование разных типов данных в одном и том же поле и применяет разное хранилище для разных типов данных.
Разница между вариантным и динамическим сопоставлением
С функциональной точки зрения самая большая разница между Variant в Doris и динамическим сопоставлением в Elasticsearch заключается в том, что область действия динамического сопоставления распространяется на весь жизненный цикл текущей таблицы, тогда как область действия Variant может быть ограничена текущим разделом данных.
Например, если сегодня пользователь изменил бизнес-логику и переименовал некоторые поля вариантов, старое имя поля останется в разделах до сегодняшнего дня, но не появится в новых разделах с завтрашнего дня. Таким образом, риск конфликта типов данных снижается.
В случае конфликта типов полей в одном разделе два поля будут изменены на тип JSON, чтобы избежать ошибок или потери данных. Например, в бизнес-системе пользователя есть два поля status: одно — строки, а другое — числовые значения, поэтому в запросах пользователь может решить, запрашивать ли строковое поле, числовое поле, или оба. (Например, если вы укажете status = "ok" в фильтрах, запрос будет выполнен только для строкового поля.)
С точки зрения пользователей, они могут использовать тип Variant так же просто, как и другие типы данных. Они могут добавлять или удалять поля вариантов в зависимости от своих бизнес-потребностей, при этом дополнительный синтаксис или аннотации не требуются.
В настоящее время тип Variant требует дополнительного утверждения типа; мы планируем автоматизировать этот процесс в будущих версиях Doris. GuanceDB в этом аспекте на шаг быстрее. Они реализовали утверждения автотипа для своих запросов DQL. В большинстве случаев утверждение типа основано на фактическом типе данных полей Variant. В некоторых редких случаях, когда возникает конфликт типов, поля Variant будут обновлены до полей JSON, а затем утверждение типа будет основано на семантике операторов в запросах DQL.
Заключение
Переход GuanceDB с Elasticsearch на Apache Doris демонстрирует большой шаг в повышении скорости обработки данных и сокращении затрат. Для этих целей Apache Doris оптимизировал два основных аспекта обработки данных: интеграцию данных и анализ данных. Он расширил поддержку бессхем для гибкого размещения большего количества типов данных и представил такие функции, как инвертированный индекс и многоуровневое хранилище, чтобы обеспечить более быстрые и экономичные запросы. Эволюция – это непрерывный процесс. Apache Doris никогда не переставала совершенствоваться. Мы разрабатываем множество новых функций, и сообщество Дорис примет любой вклад. и обратная связь.
Также опубликовано здесь.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27234)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)