Предисловие
В этом исследовании сравниваются системы реализации, подобные Ethereum, и анализируются трудности и возможности достижения параллельного выполнения транзакций.
Стоит отметить, что цепочки, проанализированные для этого исследования, основаны на схеме проектирования модели учетной записи, не включая схему UTXO.
Объекты исследования
- FISCO-BCOS, один из блокчейнов консорциума, который поддерживает параллельное выполнение проверки транзакций внутри блоков.
2. Публичная сеть Khipu, scala-реализация протокола Ethereum.
3. Общедоступная сеть Aptos, Перемещение виртуальной машины.
Проблемы с параллельным выполнением
Давайте рассмотрим традиционный процесс выполнения транзакции.
Исполнительный модуль извлекает каждую транзакцию из блока и выполняет ее последовательно.
Последнее состояние мира будет изменено в процессе выполнения, а затем состояние будет добавлено после завершения транзакции, чтобы достичь последнего состояния мира после завершения блока.
Выполнение следующего блока строго зависит от состояния мира текущего/предыдущего блока, поэтому этот последовательный однопоточный процесс выполнения не очень подходит для параллельного выполнения.
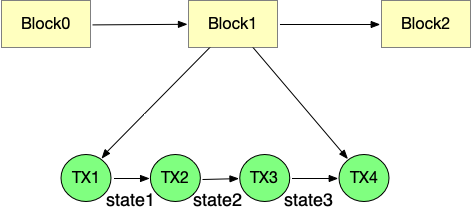
Ниже приведены основные конфликты в текущих методах параллельного выполнения Ethereum:
- Конфликт учетной записи. Если два потока одновременно обрабатывают баланс или другие атрибуты адресной учетной записи, как мы можем убедиться, что они согласуются с результатом последовательной обработки, т. е. мировое состояние является определенным конечным автоматом?
- Конфликт хранилища одного и того же адреса: оба контракта изменили хранилище одной и той же глобальной переменной.
3. Конфликт вызовов между контрактами. Если контракт A развертывается первым, контракту B необходимо дождаться завершения развертывания контракта A, чтобы вызвать контракт A. Однако, когда транзакции выполняются параллельно, возникает нет такой последовательности, что приводит к конфликту.
Схемы параллельного выполнения
FISCO-BCOS
Аннотация
FISCO-BCOS 2.0 использует структуру графа при обработке транзакций. Разработчики разработали исполнитель параллельных транзакций (PTE) на основе модели направленного ациклического графа (DAG).
PTE может помочь вам в полной мере использовать преимущества многоядерного процессора, чтобы транзакции в блоке могли выполняться параллельно, насколько это возможно.
В то же время он предоставляет пользователю простой и дружественный программный интерфейс, так что пользователю не нужно заботиться об утомительных деталях параллельной реализации.
Экспериментальные результаты программы эталонного тестирования показывают, что по сравнению с традиционной схемой выполнения последовательных транзакций, PTE, работающий на 4-ядерном процессоре, в идеальных условиях может обеспечить повышение производительности примерно на 200–300%, а улучшение вычислений пропорционально числу Конечно.
Чем больше ядер, тем выше производительность.
Общая схема
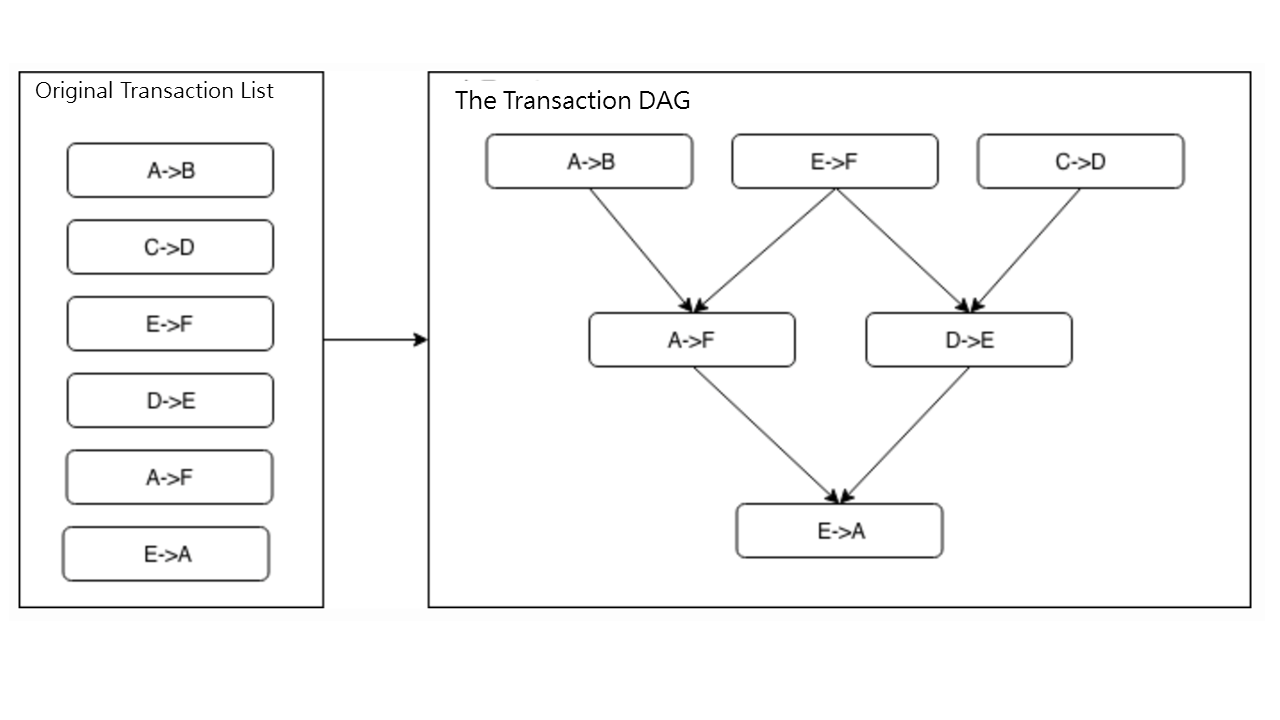
Ациклический ориентированный граф часто называют направленным ациклическим графом (DAG).
В пакете транзакций идентифицируются взаимоисключающие ресурсы, занимаемые каждой транзакцией; затем строится зависимая от транзакций DAG в соответствии с последовательностью транзакций в блоке и отношением занятости взаимоисключающих ресурсов.
Как показано на рисунке ниже, все транзакции с входящей степенью 0 (без зависимых задач предварительного заказа) могут выполняться параллельно. Транзакция DAG справа может быть получена путем топологической сортировки на основе порядка исходного списка транзакций слева.
Модульная архитектура
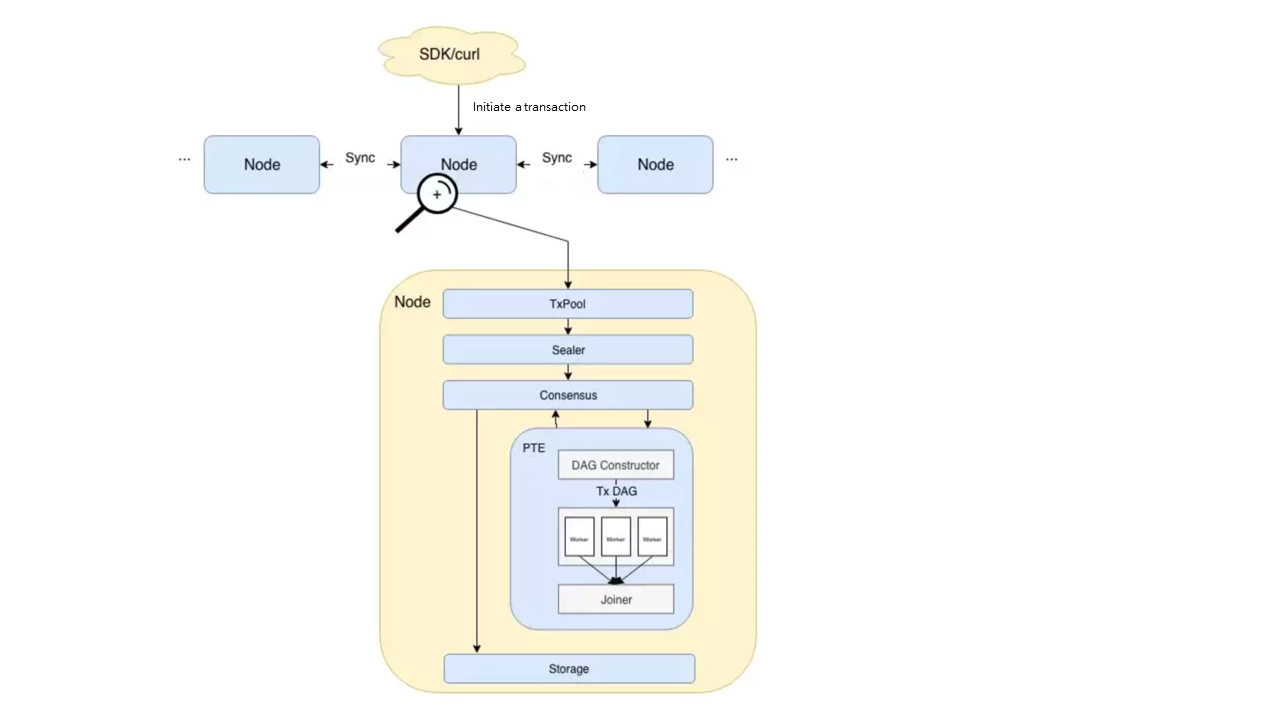
* Пользователи инициируют транзакции прямо или косвенно через SDK.
* Затем транзакция синхронизируется между узлами, и узел с одинаковыми правами на упаковку вызывает Sealer (TxPool), чтобы взять определенное количество транзакций из (txpool) и упаковать их в блок. После этого блоки отправляются в блок консенсуса для подготовки к консенсусу между узлами.
* Проверка транзакции выполняется до достижения консенсуса, и именно здесь PTE начинает свой рабочий процесс. Как видно из диаграммы архитектуры, PTE сначала считывает транзакции в блоке по порядку и вводит их в конструктор DAG, который создает DAG транзакции, содержащий все транзакции в соответствии с зависимостями каждой транзакции. Затем PTE пробуждает рабочий пул. Используйте несколько потоков для параллельного выполнения транзакции DAG. Столяр приостанавливает основной поток до тех пор, пока группа обеспечения доступности баз данных не будет выполнена всеми потоками в рабочем пуле. На этом этапе объект Joiner вычисляет корень состояния и корень получения на основе записи изменения состояния каждой транзакции и возвращает результат вызывающей стороне на верхнем уровне.
* После проверки блока он загружается в цепочку. После выполнения транзакции, если состояние каждого узла согласовано, достигается консенсус, и затем блок записывается в базовое хранилище, которое постоянно записывается в блокчейне.
Процесс построения транзакции DAG
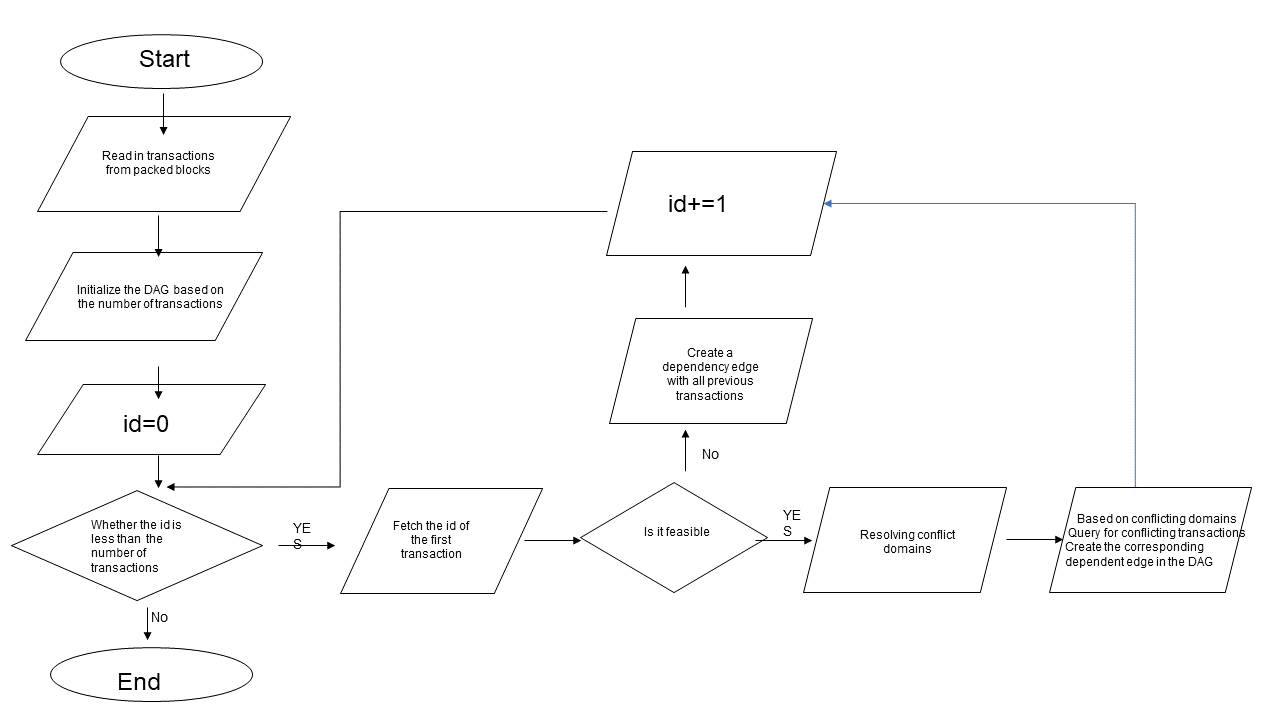
- Взять все транзакции в блоке из упакованного блока.
2. Инициализируйте экземпляр DAG, указав количество транзакций как максимальное количество вершин.
3. Прочитайте все транзакции по порядку. Если транзакция допускает слияние, разрешите ее конфликтное поле и проверьте, не конфликтуют ли с ней какие-либо предыдущие транзакции. Если это так, постройте ребро зависимости между соответствующими транзакциями. Если транзакция не является объединяемой, считается, что она должна быть выполнена после выполнения всех предыдущих транзакций, поэтому между транзакцией и всеми ее предшественниками создается граница зависимости.
Примечание. После создания всех зависимых ребер их нельзя объединить, их можно выполнять только последовательно.
Процесс выполнения DAG
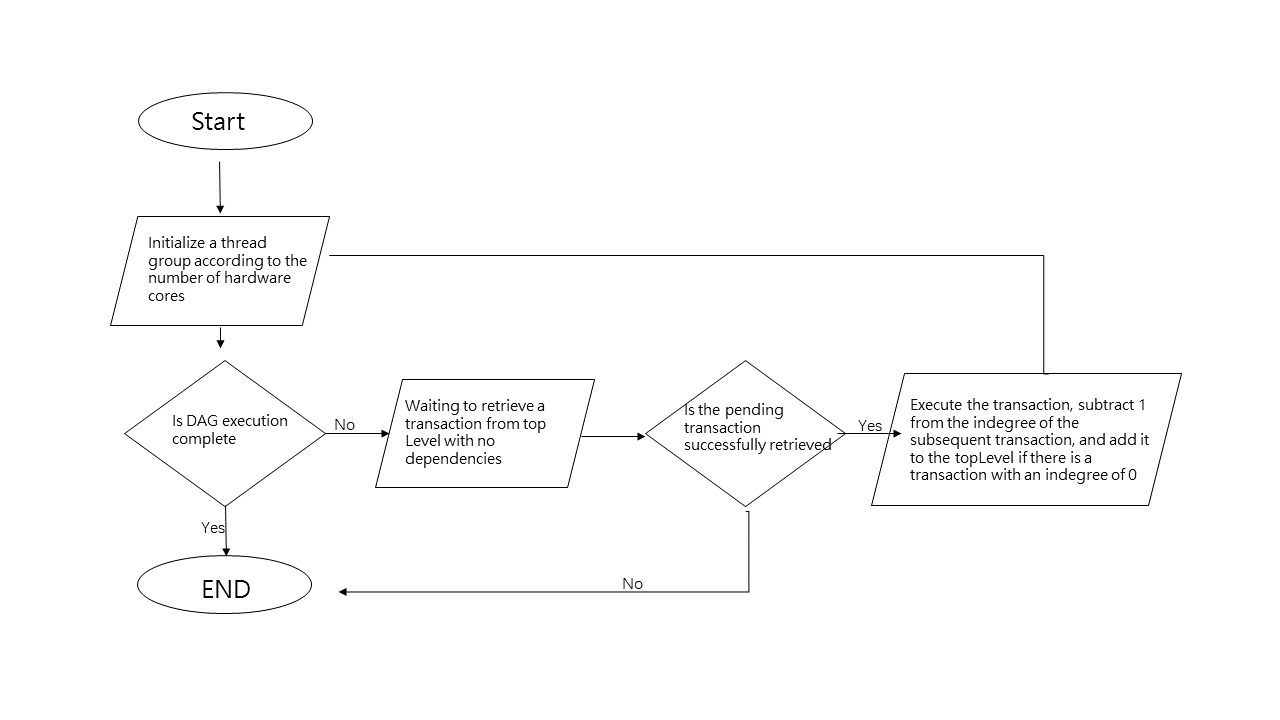
- Основной поток сначала инициализирует небольшую группу потоков в зависимости от количества аппаратных ядер, и если аппаратные ядра выходят из строя, другие потоки создаваться не будут.
2. Когда DAG не завершена, цикл потока ожидает, пока готовая транзакция со степенью входа 0 будет извлечена из метода waitPop группы DAG. Если транзакция, которая должна быть выполнена, успешно завершена, транзакция будет выполнена. Если это не удается, группа обеспечения доступности баз данных завершает выполнение и поток завершает работу.
Проблемы и решения
- Что касается одного и того же блока, как убедиться, что все узлы завершили выполнение и находятся в одинаковом состоянии (три корневых узла совпадают)?
FISCO BCOS проверяет, что тройки, то есть корень состояния, корень транзакции и корень квитанции, равны друг другу, чтобы определить, согласованы ли состояния. Корень транзакции — это хеш-значение, рассчитанное на основе всех транзакций в блоке.
Пока все узлы консенсуса обрабатывают одни и те же данные блока, корень транзакции должен быть одним и тем же, что относительно легко гарантировать. Ключевым моментом является обеспечение того, чтобы состояние и корень квитанции, сгенерированные после транзакции, были одинаковыми.
Хорошо известно, что порядок выполнения между инструкциями, выполняемыми параллельно на разных ядрах ЦП, нельзя предсказать заранее, и то же самое верно для транзакций, выполняемых параллельно.
В традиционной схеме выполнения транзакций корень состояния изменяется после выполнения каждой транзакции, и измененный корень состояния записывается в квитанцию транзакции.
После выполнения всех транзакций окончательный корень состояния представляет текущее состояние блокчейна. В то же время корень квитанции рассчитывается на основе всех квитанций по транзакциям.
Видно, что в традиционной реализации корень состояния действует как глобальная общая переменная.
Когда транзакции выполняются параллельно и не по порядку, традиционное вычисление корня состояния больше не применимо, поскольку транзакции выполняются в другом порядке на разных машинах, и конечный корень состояния не гарантируется непротиворечивостью, равно как и корень получения не гарантируется. быть последовательным.
В FISCO BCOS транзакции сначала выполняются параллельно, и записывается история изменения состояния каждой транзакции. После выполнения всех транзакций на основе истории вычисляется корень состояния.
В то же время корень состояния в подтверждении транзакции становится корнем окончательного состояния после выполнения всех транзакций, что гарантирует, что узлы консенсуса все еще могут прийти к соглашению, даже если транзакции выполняются параллельно.
- Как определить, являются ли две транзакции зависимыми?
Если две транзакции не являются зависимыми, но считаются таковыми, это приведет к ненужной потере производительности. И наоборот, если обе транзакции переписывают состояние одной и той же учетной записи, но выполняются параллельно, окончательное состояние учетной записи может быть неопределенным.
Таким образом, определение зависимости является важным вопросом, который влияет на производительность и может даже определить, может ли блокчейн работать должным образом.
В простой транзакции перевода мы можем судить о зависимости двух транзакций на основе адресов отправителя и получателя. В качестве примера возьмем следующие три транзакции перевода: A→B, C→D и D→E.
Легко видеть, что транзакция D→E зависит от результата транзакции C→D, но транзакция A→B не имеет ничего общего с двумя другими транзакциями, поэтому ее можно выполнять параллельно.
Такой анализ верен для блокчейна, который поддерживает только простые переводы, но он может быть не таким точным в тьюринг-полном блокчейне, который запускает смарт-контракты, потому что мы точно не знаем, что происходит в написанном пользователем контракте на передачу. . Вот что может произойти.
Кажется, что транзакция A→B не имеет ничего общего со статусом учетной записи C и D, но в базовой реализации пользователя A является специальной учетной записью, и определенная комиссия должна быть вычтена со учетной записи C для все деньги, переведенные через счет А.
В этом сценарии все три транзакции связаны между собой, поэтому их нельзя выполнять параллельно. Если транзакции разделены в соответствии с предыдущим методом анализа зависимостей, это неизбежно приведет к ошибкам.
Можем ли мы автоматически определить, какие зависимости действительно существуют в транзакции, исходя из содержания пользовательского контракта? Ответ - нет. Как упоминалось ранее, при статическом анализе сложно анализировать контрактные зависимости и процесс выполнения.
В FISCO BCOS назначение торговых зависимостей предоставлено разработчикам, которые лучше знакомы с содержанием контракта. В частности, взаимоисключающие ресурсы, от которых зависит транзакция, могут быть представлены набором строк.
FISCO BCOS предоставляет интерфейс разработчику, который определяет ресурсы, от которых зависит транзакция, в виде строк и информирует исполнителя о цепочке.
Исполнитель автоматически организует все транзакции в блоке в DAG транзакций в соответствии с зависимостями транзакций, указанными разработчиком.
Например, в простом контракте на передачу разработчик просто указывает, что зависимостью для каждой транзакции передачи является {адрес отправителя + адрес получателя}.
Кроме того, если разработчик вводит другой сторонний адрес в логику передачи, то зависимость должна быть определена как {адрес отправителя + адрес получателя + сторонний адрес}.
Этот подход интуитивно понятен, прост и универсален и применим ко всем смарт-контрактам, но он также увеличивает ответственность на плечах разработчика.
Разработчик должен быть очень осторожным при указании зависимостей транзакций. Если зависимости прописаны неправильно, последствия непредсказуемы.
Параллельный рамочный контракт
Чтобы разработчики могли использовать структуру параллельных контрактов, FISCO BCOS установила некоторые требования к составлению контрактов. Спецификации следующие:
Параллельные взаимоисключающие
Возможность параллельного выполнения двух транзакций зависит от того, являются ли эти две транзакции взаимоисключающими. Взаимное исключение относится к пересечению набора переменных хранения двух транзакций.
Например, в сценарии передачи активов транзакция — это операция передачи между пользователями. transfer(X, Y) представляет интерфейс передачи от пользователя X к пользователю Y, а взаимное исключение выглядит следующим образом.
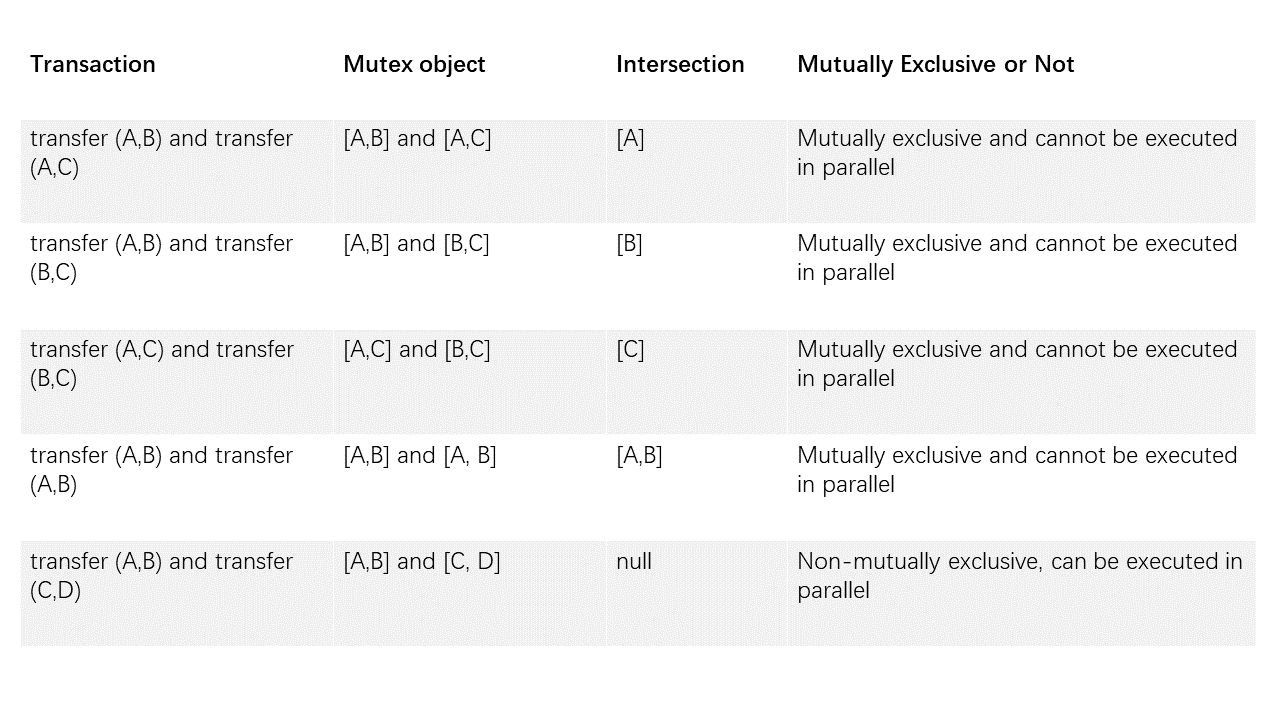
* Взаимоисключающий параметр: параметр, связанный с операцией «чтения/записи» переменной хранения контракта в интерфейсе контракта. Возьмем, к примеру, интерфейс передачи (X, Y). X и Y являются взаимоисключающими параметрами.
* Мьютекс: конкретное содержимое мьютекса, извлекаемое из транзакции в соответствии с параметрами мьютекса. Возьмем, к примеру, интерфейс передачи (X, Y). В транзакции передачи с использованием этого интерфейса конкретный параметр — передача (A, B), а мьютекс этой операции — [A, B]. Для другой транзакции вызывается transfer(A, C), а мьютексом для этой операции является [A, C].
Определить, могут ли две транзакции выполняться параллельно одновременно, значит определить, пересекается ли мьютекс двух транзакций. Транзакции, пересечения которых пусты, могут выполняться параллельно.
FFISCO-BCOS предоставляет два способа написания параллельных контрактов, предварительно скомпилированных контрактов и контрактов на солидность, только последний из которых описан здесь. То же самое касается предварительно составленных контрактов.
Параллельная структура контракта Solidity
Чтобы написать параллельный контракт Solidity, просто сделайте ParallelContract.sol базовым классом для контрактов, которые вы хотите распараллелить. Метод gisterParallelFunction() вызывается для регистрации интерфейсов, которые могут быть распараллелены.
Код параллельного контракта выглядит следующим образом:
pragma solidity ^0.4.25;
//Precompile the contract interface
contract ParallelConfigPrecompiled
{
function registerParallelFunctionInternal(address, string, uint256) public returns (int);
function unregisterParallelFunctionInternal(address, string) public returns (int);
}
//The parallel contract base class needs to be registered and the subcontract needs to be implement enable or disable interface
contract ParallelContract
{
ParallelConfigPrecompiled precompiled = ParallelConfigPrecompiled(0x1006);
function registerParallelFunction(string functionName, uint256 criticalSize) public
{
precompiled.registerParallelFunctionInternal(address(this), functionName, criticalSize);
}
function unregisterParallelFunction(string functionName) public
{
precompiled.unregisterParallelFunctionInternal(address(this), functionName);
}
function enableParallel() public;
function disableParallel() public;
}
Следующий пример представляет собой договор о передаче, написанный на основе параллельного рамочного договора:
pragma solidity ^0.4.25;
import "./ParallelContract.sol"; // Introduce ParallelContract.sol
contract ParallelOk is ParallelContract // useParallelContract as a base class
{
// Contract implementation
mapping (string => uint256) _balance; // Global mapping
// The mutually exclusive variables from and to are the first two parameters at the beginning of transfer (). It can be seen that the contract requirements are still very strict, which will make users uncomfortable to write
function transfer(string from, string to, uint256 num) public
{
_balance[from] -= num; // From is the key of the global mapping, and is a mutually exclusive parameter
_balance[to] += num; //// To is the key of the global mapping, and is a mutually exclusive parameter
}
// The mutex variable name comes first as an argument to the beginning of set()
function set(string name, uint256 num) public
{
_balance[name] = num;
}
function balanceOf(string name) public view returns (uint256)
{
return _balance[name];
}
// Register contract interfaces that can be parallel
function enableParallel() public
{
// The function definition string (note that there are no Spaces after ",") and the first few arguments are mutex arguments (mutex arguments must be first when designing a function)
//The number 2 indicates that the first two are mutex parameters, and the system decodes the mutex according to the function signature and abi
registerParallelFunction("transfer(string,string,uint256)", 2); // critical: string string
//
registerParallelFunction("set(string,uint256)", 1); // critical: string
}
// Deregister the parallel contract interface
function disableParallel() public
{
unregisterParallelFunction("transfer(string,string,uint256)");
unregisterParallelFunction("set(string,uint256)");
}
}
Определить, может ли интерфейс быть параллельным
Параллельный интерфейс контракта должен удовлетворять следующим требованиям:
- Внешние контракты не вызываются.
- Другие функциональные интерфейсы не вызываются.
Определить параметр мьютекса
Перед программированием интерфейса определите взаимоисключающие параметры интерфейса. Взаимоисключающие параметры интерфейса являются взаимоисключающими для глобальных переменных. Правила определения взаимоисключающих параметров следующие:
* Если к глобальному сопоставлению обращается интерфейс, ключ сопоставления является взаимоисключающим параметром.
* Если интерфейс обращается к глобальному массиву, нижний индекс массива является взаимоисключающим параметром.
* Если интерфейс обращается к глобальным переменным простого типа. Все глобальные переменные простого типа имеют общий параметр мьютекса и используют разные имена переменных в качестве объектов мьютекса.
:::подсказка Например, в контракте есть несколько глобальных переменных простых типов, и разные интерфейсы обращаются к разным глобальным переменным.
Если вы хотите распараллелить разные интерфейсы, вам необходимо определить параметр мьютекса в параметре интерфейса с измененной глобальной переменной, чтобы указать, какая глобальная переменная используется во время вызова.
При вызове параметру мьютекса активно передается измененное «имя переменной» глобальной переменной для идентификации мьютекса транзакции.
Например: если setA(int x) изменяет globalA как глобальный параметр, setA необходимо определить как set(string aflag , интервал x). При вызове передается setA("globalA", 10). Используйте имя переменной "globalA", чтобы указать, что мьютексом для этой транзакции является globalA.
:::
Определить тип и порядок параметров
После определения взаимоисключающих параметров определите тип и порядок параметров в соответствии с правилами. Правила следующие:
* Параметры интерфейса ограничены строкой, адресом, uint256 и int256 (в будущем будет поддерживаться больше типов).
* Все взаимоисключающие параметры должны быть указаны в параметрах интерфейса.
* Все взаимоисключающие параметры находятся на первом месте параметров интерфейса.
Видно, что параллельная транзакция FISCO-BCOS во многом зависит от спецификаций контрактов, написанных пользователями.
Если спецификации контрактов, написанных пользователями, не стандартизированы, система спешно выполняет параллельное исполнение, что может привести к коренной несогласованности бухгалтерских книг.
Кипу
Аннотация
Кипу считает нереальным, чтобы пользователи безошибочно определяли и помечали диапазон адресов, которые будут создавать статические конфликты во время написания контракта. Это противоречит точке зрения FISCO-BCOS.
О том, появится ли, где и при каких условиях состояние гонки, можно судить только тогда, когда приобретение определенности включает текущее состояние.
Такого рода суждения с современными контрактными языками программирования делают практически невозможным получение полностью правильных и неупущенных результатов при статическом анализе кода.
Компания Khipu предприняла более комплексную попытку решить эту проблему и завершила процесс ее реализации.
Общая схема
В Khipu каждая транзакция в одном и том же блоке начинается с мирового состояния предыдущего блока, а затем выполняется параллельно, регистрируя три вышеупомянутых состояния гонки, возникающие на всех идеальных путях опыта во время выполнения.
За фазой параллельного выполнения следует фаза слияния, когда состояния параллельного мира сливаются одно за другим. При объединении транзакции сначала оцените наличие конфликта с ранее объединенными условиями гонки по записанным статическим условиям.
Если нет, слейте напрямую. Если это так, транзакция выполняется снова, начиная с предыдущего состояния мира, которое было объединено.
Последнее объединенное мировое состояние сверяется с хешем блока. Это последняя линия обороны. Если проверка неверна, предыдущее слияние отменяется и блок выполняется снова.
Индекс параллелизма
Здесь Кипу вводит индекс параллелизма, который относится к доле транзакций в блоке, которые могут напрямую объединять результаты без повторного выполнения.
Наблюдение Кипу за воспроизведением Ethereum в течение нескольких дней от блока создания до самого нового блока показывает, что это соотношение (параллелизм) может достигать в среднем 80%.
В общем, если вычислительные задачи могут быть полностью распараллелены, масштабируемость одной цепочки бесконечна. Потому что вы всегда можете добавить больше процессорных ядер к узлу. Если это не так, то максимальная теоретическая скорость ограничена теоремой Андала:
Предел, до которого вы можете ускорить систему, зависит от обратной величины частей, которые нельзя распараллелить. Итак, если вы можете распараллелить 99%, вы можете ускориться до 100 раз. Но если вы можете добиться распараллеливания только на 95 %, то вы сможете работать только в 20 раз быстрее.
Из всех транзакций в Ethereum около 80% могут быть распараллелены, а 20% — нет, поэтому ограничение скорости Khipu составляет примерно 5 раз.
Маркеры конфликтов
Изучив инструкции в коде evm, было обнаружено, что ограниченное количество инструкций создало процессы чтения и записи для хранилища, поэтому можно было записать эти процессы чтения и записи для формирования коллекции чтения и записи, но статический анализ кода не мог обеспечить запись этих процессов.
Поэтому необходимо предварительно выполнить каждую транзакцию один раз при обработке каждого блока. Процесс перед выполнением сообщает нам, являются ли транзакции чтением и записью в одну и ту же учетную запись или хранилище, и создает readSet и writeSet для каждой транзакции.
Если в блокчейне 100 транзакций, то эти 100 транзакций могут выполняться параллельно через пул потоков. Каждый контракт имеет одинаковое начальное мировое состояние, и во время выполнения будет создано 100 наборов чтения и записи, а также по 100 новых состояний каждый.
Когда предварительное выполнение закончено, начинается следующий этап обработки. В идеале, если 100 записей readSet и writeSet не конфликтуют, их можно объединить напрямую, чтобы получить окончательное мировое состояние всех транзакций в блоке. Однако сделка часто не так идеальна.
Правильный способ справиться с этим — сравнить readSet и writeSet после выполнения первой транзакции с readSet и writeSet после выполнения второго контракта и посмотреть, читали и записывали ли они одну и ту же учетную запись или хранилище.
Если это так, это означает, что две сделки конфликтуют. Затем вторая транзакция начнется после завершения первой транзакции и будет выполнена снова.
Точно так же, по мере того, как конечный автомат слияния продолжает работу, набор конфликтов будет продолжать накапливаться, и пока последующие транзакции конфликтуют с предыдущими транзакциями, они будут выполняться последовательно, пока не будут выполнены все транзакции.
При воспроизведении транзакций в основной сети Ethereum обнаруживается, что там, где много конфликтов, в большинстве случаев происходит обмен в одном блоке со взаимосвязанными транзакциями, что также согласуется с этим процессом.
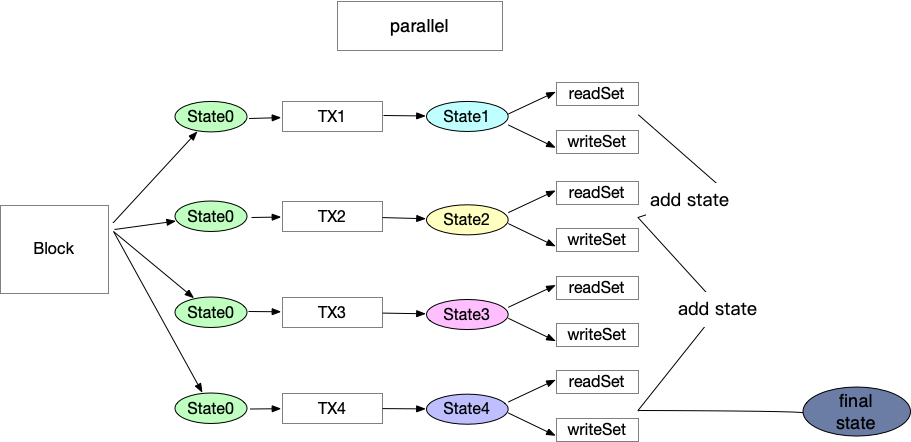
Общий процесс
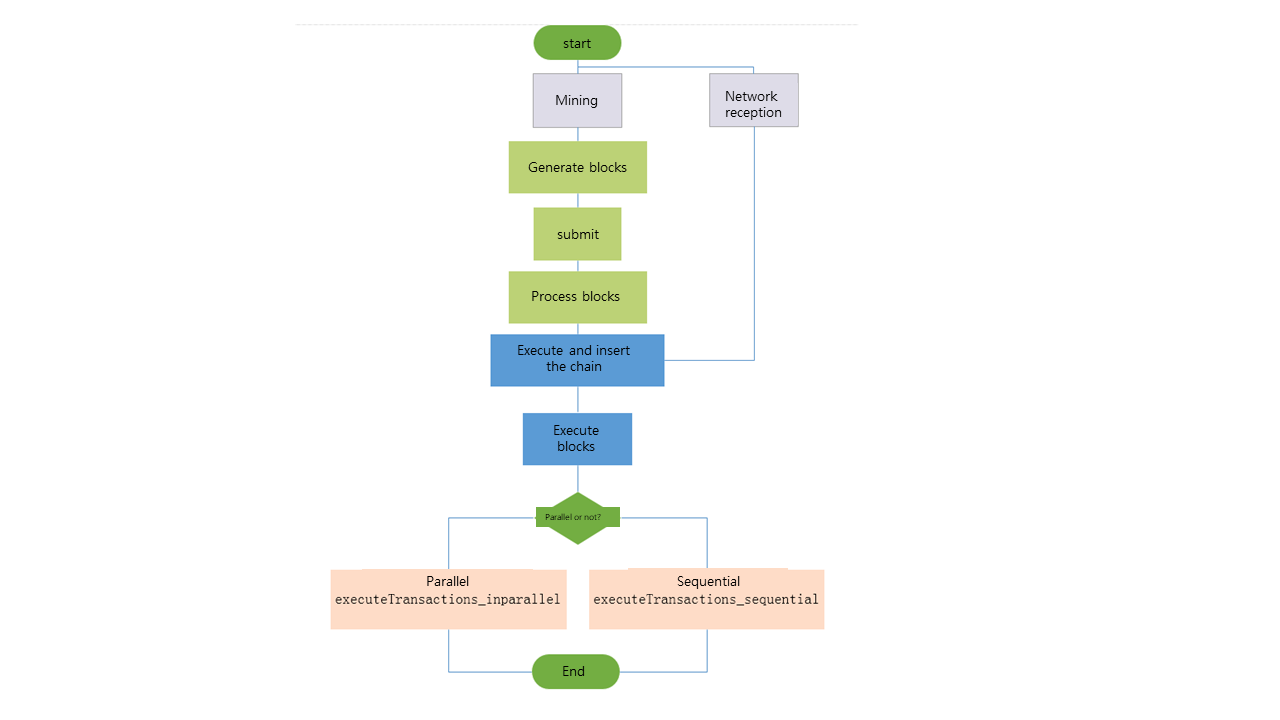
Конкретный параллельный процесс
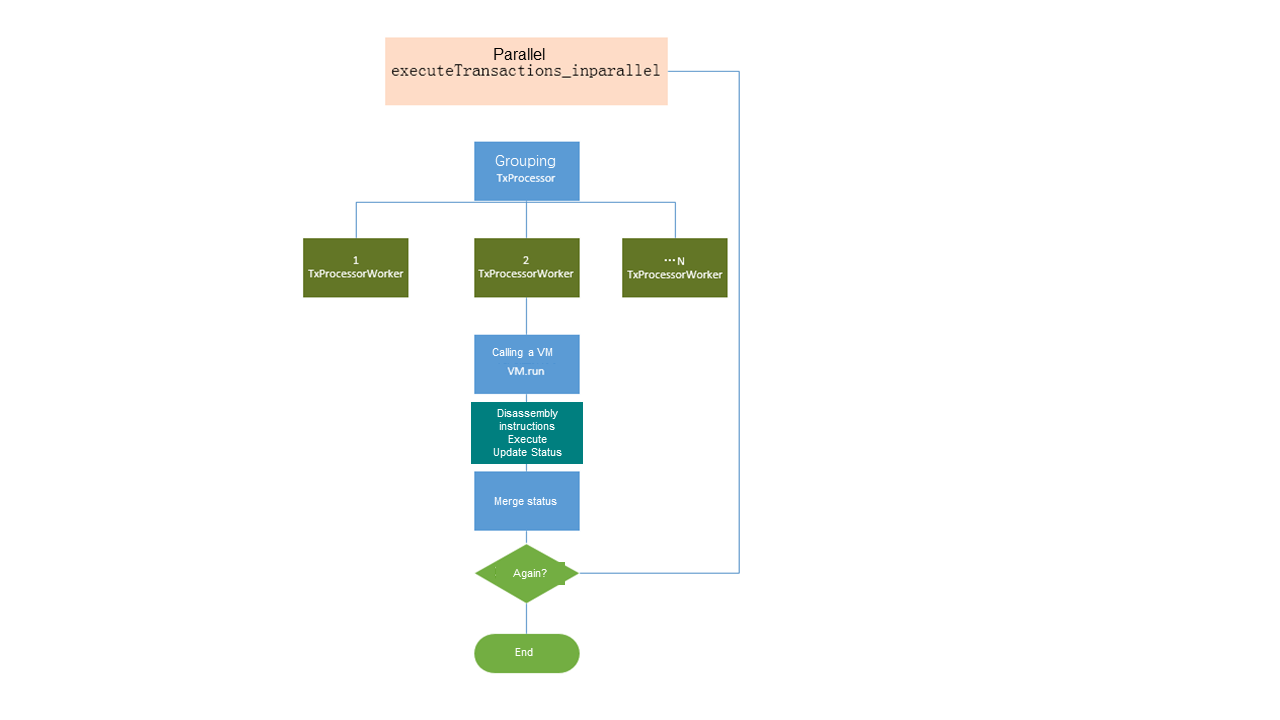
Аптос
Аннотация
Aptos построен на языке Diem's Move и MoveVM для создания цепочки с высокой пропускной способностью, обеспечивающей параллельное выполнение. Подход Aptos заключается в обнаружении ассоциаций, при этом будучи прозрачным для пользователей/разработчиков.
То есть от транзакций не требуется явно указывать, какую часть состояния (область памяти) они используют.
Общая схема
Aptos использует модифицированную версию программной памяти транзакций под названием Block-STM и реализует механизм параллельного выполнения на основе Block-STM.
Block-STM использует MVCC (управление параллелизмом нескольких версий), чтобы избежать конфликтов записи и записи. Все записи в одно и то же место сохраняются с их версиями, которые содержат их TX-ID и количество раз, когда запись tx выполнялась повторно.
Когда транзакция (tx) считывает значение для ячейки памяти, она получает значение, записанное из MVCC в эту ячейку, которая произошла до tx, вместе со связанной версией, чтобы определить, есть ли конфликт чтения/записи.
В Block-STM транзакции предварительно сортируются внутри блоков и делятся между потоками процессора для параллельного выполнения во время выполнения. При параллельном выполнении предполагается, что для выполнения транзакции нет зависимостей.
Ячейки памяти, измененные транзакцией, записываются. После выполнения проверьте все результаты транзакции. Если во время проверки обнаруживается, что транзакция обращается к ячейке памяти, измененной предыдущей транзакцией, транзакция считается недействительной.
Обновите результат сделки, а затем повторите сделку. Этот процесс повторяется до тех пор, пока не будут выполнены все транзакции в блоке. Block-STM ускоряет выполнение при использовании нескольких процессорных ядер. Ускорение зависит от того, насколько взаимозависимы транзакции.
Видно, что схема, используемая Aptos, примерно аналогична упомянутой выше Khipu, но есть некоторые отличия в реализации, которые детализированы следующим образом:
* Khipu использует параллельное выполнение и последовательную проверку для транзакций внутри блока. Однако Aptos реализует параллельное выполнение и проверку транзакций внутри блока. Эти две схемы имеют преимущества и недостатки. Хипу легко реализовать, а эффективность несколько ниже. С помощью Block-STM Aptos использует синхронизацию и работу с сигналами во многих потоках, что очень эффективно, но сложно реализовать в коде.
* Поскольку Move изначально поддерживает глобальную адресацию ресурсов, Aptos будет переупорядочивать транзакции даже между блоками, если это способствует параллельному выполнению. Aptos утверждает, что эта схема может не только повысить эффективность параллелизма, но и решить проблему MEV. Однако еще предстоит решить, повлияет ли это на взаимодействие с пользователем.
* Aptos сохраняет результирующий набор записей в памяти во время выполнения для достижения максимальной скорости выполнения, а затем использует его в качестве кеша для следующего выполняемого блока. Любые повторные записи должны быть записаны в стабильную память только один раз.
Эталонный тест
Компания Aptos провела соответствующий эталонный тест после интеграции блочного STM и сравнила последовательное и параллельное выполнение блока из 10 000 транзакций. Результат сравнения показан следующим образом:
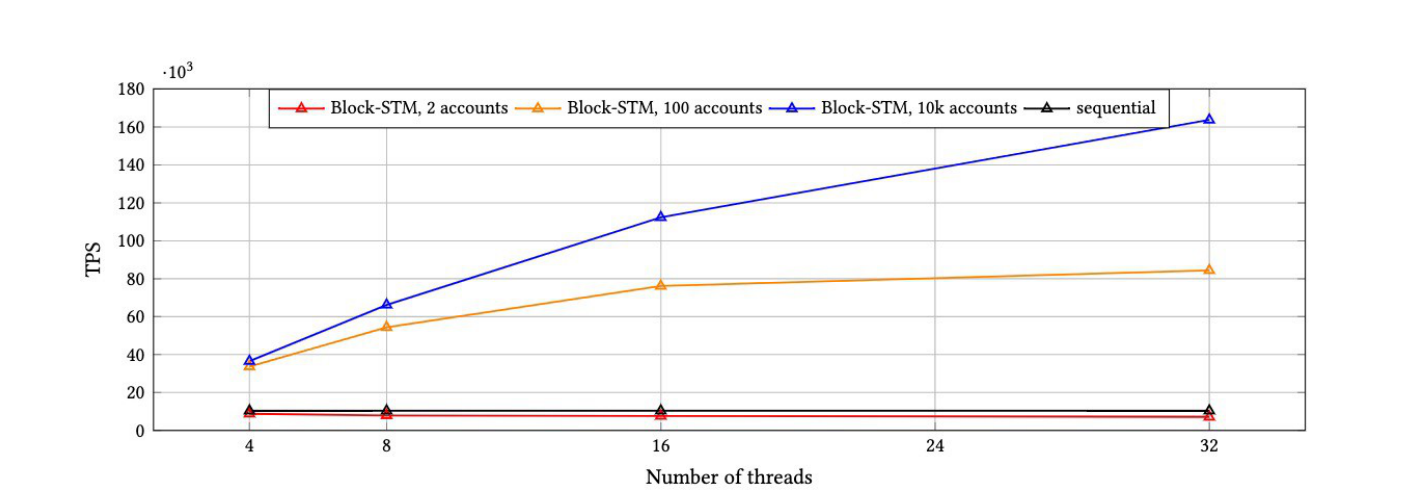
Из рисунка выше видно, что Block STM работает в 16 раз быстрее, чем последовательное выполнение с 32 параллельными потоками, и более чем в 8 раз быстрее при высокой конкуренции.
Заключение
На основании приведенного выше сравнения и анализа можно сделать вывод, что некоторые схемы требуют от пользователей записи хранилища в соответствии с установленными правилами при написании контрактов, чтобы можно было найти зависимости путем статического и динамического анализа.
Солана и Суи используют схожие схемы, но восприятие пользователей отличается. Эта схема представляет собой изменение модели хранения для получения более качественных результатов анализа.
Хипу и Аптос не зависят от пользователя. Накладные расходы на параллельное выполнение не ложатся на плечи разработчиков, и им не нужно думать об этом при составлении контрактов.
Виртуальная машина динамически анализирует отношения зависимости перед выполнением, тем самым реализуя параллельное выполнение без отношений зависимости.
Это сложно реализовать, и степень параллелизма в некоторой степени зависит от разделения счетов транзакции. Когда много конфликтов транзакций, производительность значительно ухудшается из-за постоянного повторного выполнения.
Aptos упомянул, что в будущем они проведут оптимизацию контрактов, созданных пользователями, чтобы лучше анализировать зависимости и, таким образом, добиться более быстрого выполнения.
Простое преобразование последовательной схемы в параллельную может привести к увеличению пропускной способности транзакций в среде общедоступной сети в 3–16 раз, и если это можно комбинировать с большими блоками и большими лимитами газа, пропускная способность L2 будет дополнительно оптимизирована, потенциально примерно 100 раз.
С инженерной точки зрения, касающейся реализации и эффективности, OlaVM, скорее всего, примет схему Khipu плюс решение с индивидуальной моделью хранения, которое может повысить производительность, избегая сложности, вызванной введением Block-STM, и способствовать лучшей инженерной оптимизации.
Ссылки
- FISCO-BCOS Github, FISCO-BCOS
- Khipu GitHub, GitHub — khipu-io/khipu: корпоративная блокчейн-платформа на базе Ethereum
- Aptos GitHub, GitHub — aptos-labs/aptos-core: Aptos — это блокчейн уровня 1, созданный для поддержки широкое использование блокчейна благодаря улучшенным технологиям и пользовательскому опыту.
О нас
Компания Sin7y, основанная в 2021 году и поддерживаемая первоклассными разработчиками блокчейнов, представляет собой инкубатор проектов и группу исследователей технологий блокчейн, которая исследует наиболее важные и передовые технологии, включая EVM, Layer2, кросс-чейн, конфиденциальные вычисления, автономные платежи. решения и т. д.
В настоящее время мы работаем над EVM-совместимой, быстрой и масштабируемой ZKVM под названием OlaVM. Если вы заинтересованы в общении с нами, присоединяйтесь к нашей группе TG или напишите нам по адресу contact@sin7y.com.