

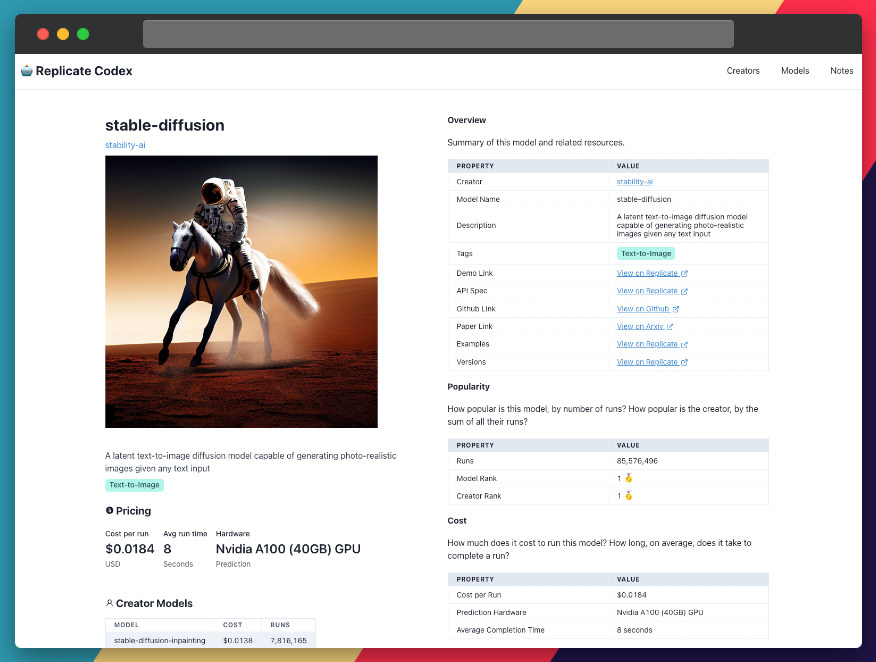
Пошаговое руководство по бесплатному запуску Stable Diffusion Online
21 апреля 2023 г.Представьте себе: вы просматриваете свой любимый технический блог и натыкаетесь на эту невероятную новую модель искусственного интеллекта под названием Стабильная диффузия, которая может волшебным образом превратить текстовые описания в потрясающие изображения. Если вы чем-то похожи на меня, ваша первая мысль: "МНЕ НУЖНО попробовать!"
Но потом начинаешь копаться. Вы обнаружите, что для запуска Stable Diffusion обычно требуется сложная настройка оборудования или загрузка поверхностного настольного приложения, которое может дать вашему компьютеру цифровую версию гриппа. Поговорим о buzzkill, верно?
Итак, мои дорогие поклонники искусственного интеллекта, у меня есть потрясающие новости. Компания под названием Replicate представила Stable Diffusion в массы наиболее доступным способом: через гладкий, удобный графический интерфейс, который вы можете использовать прямо в своем браузере! А вишенка сверху? Вы можете играть с ним бесплатно, пока не достигнете платного порога.
Теперь вы можете задаться вопросом: "Но зачем мне запускать Stable Diffusion в моем браузере?"
Позвольте мне сказать вам, это меняет правила игры. Вы можете не только получить доступ к этой умопомрачительной модели искусственного интеллекта в любом месте, в любое время и на любом устройстве, но вам также не нужно беспокоиться о настройке сложного оборудования или доверять какому-то случайному настольному приложению. Это похоже на то, как если бы у вас под рукой была сила тысячи художников, которые просто ждут, когда вы наберете несколько слов и раскроете их коллективное творчество.
Так что, если вы похожи на меня и жаждете погрузиться в мир создания изображений на основе ИИ без хлопот с дорогим оборудованием или сомнительных загрузок, не ищите дальше. В этом руководстве я покажу вам, как бесплатно запустить Stable Diffusion в браузере с помощью Replicate. Я также покажу вам, как использовать бесплатный инструмент сообщества под названием Replicate Codex. чтобы открыть для себя дополнительные крутые модели, которые могут превращать текст в изображения, преобразовывать фотографии вашего профиля в стилизованные селфи, создавать аниме-вайфу или помогать вам придумывать нового любимого покемона.
Поверьте мне, как только вы начнете создавать изображения всего за несколько нажатий клавиш, вы никогда не захотите возвращаться к старым способам. Так что вперед, направьте свой внутренний творческий гений и приготовьтесь отправиться в самое захватывающее художественное путешествие в вашей жизни (на данный момент). Начнем!
О модели: синтез изображений высокого разрешения со стабильной диффузией
Прежде чем мы начнем создавать изображения, давайте на секунду поймем, как работает Stable Diffusion. Однако, если вам не терпится приступить к работе, вы можете пропустить этот раздел и перейти к следующему, чтобы узнать, как запустить Stable Diffusion в браузере. Если, с другой стороны, вы останетесь здесь, что ж... вы можете чему-то научиться!
Стабильная диффузия — это тип модели скрытой диффузии. Модели скрытой диффузии (LDM), предложенные Робином Ромбахом, Андреасом Блаттманном, Домиником Лоренцем, Патриком Эссером и Бьорном Оммером, представляют собой усовершенствованные модели искусственного интеллекта, позволяющие синтезировать изображения с высоким разрешением. Основная идея состоит в том, чтобы объединить сильные стороны диффузионных моделей (DM) и автокодировщиков, чтобы получить мощный и эффективный процесс создания изображений.
Ниже я объясню подробнее, как работают эти типы моделей. Сначала я дам вам более техническое объяснение, а затем я объясню его для вас на языке для начинающих. Не пугайтесь жаргона, которого не понимаете. Скоро все станет ясно.
Технический обзор стабильной диффузии
Модели диффузии позволили достичь самых современных результатов синтеза данных изображения и других данных за счет разложения формирования изображения на последовательное применение шумоподавляющих автоэнкодеров. Эта формулировка также позволяет управляющему механизму управлять процессом генерации изображения без необходимости переобучения. Однако DM часто требуют большого количества вычислительных ресурсов для оптимизации и требуют дорогостоящих выводов из-за последовательных вычислений.
Чтобы устранить эти ограничения, исследователи применили модели диффузии в скрытом пространстве мощных предварительно обученных автоэнкодеров. Этот подход сохраняет качество и гибкость DM при значительном снижении их вычислительных требований. Обучив мастеров на таком представлении, они достигли почти оптимального баланса между снижением сложности и сохранением деталей, что привело к существенному улучшению визуальной точности.
Кроме того, введение слоев перекрестного внимания в архитектуру модели позволило моделям распространения стать мощными и гибкими генераторами общих вводных данных, таких как текст или ограничивающие рамки. Это нововведение позволяет выполнять синтез с высоким разрешением сверточным способом.
Модели скрытой диффузии достигли нового уровня развития искусства рисования изображений и продемонстрировали высокую конкурентоспособность в различных задачах, включая безусловную генерацию изображений, синтез семантической сцены и сверхвысокое разрешение.
Как работает стабильная диффузия на простом английском языке (для начинающих)
Проще говоря, модели скрытой диффузии (LDM) – это передовой метод искусственного интеллекта, который сочетает в себе лучшие черты двух существующих методов: моделей распространения и автоэнкодеров. Диффузионные модели отлично подходят для создания изображений, но они могут быть медленными и ресурсоемкими. С другой стороны, автокодировщики отлично сжимают и реконструируют изображения.
Объединив эти два метода, исследователи, создавшие Stable Diffusion, создали новую модель, которая быстро и эффективно генерирует изображения с высоким разрешением. Они добились этого путем обучения модели распространения на сжатых данных (или скрытом пространстве) из автоэнкодера, что значительно ускорило процесс без ущерба для качества изображения.
Кроме того, исследователи добавили в модель слои перекрестного внимания, что позволило ей хорошо работать с различными типами ввода, такими как текст или ограничивающие рамки. Это новшество сделало LDM еще более универсальным и способным создавать высококачественные изображения в различных сценариях.
Таким образом, модели скрытой диффузии (LDM) — это передовой метод искусственного интеллекта, который быстро и эффективно генерирует изображения с высоким разрешением, сочетая сильные стороны моделей диффузии и автоэнкодеров. Эти модели добились впечатляющих результатов в различных задачах создания изображений, будучи менее ресурсоемкими, чем традиционные диффузионные модели.
Понимание входных и выходных данных модели стабильной диффузии
Входные данные
Основным входом в модель стабильной диффузии является текстовое приглашение. Эта текстовая подсказка — это то, что модель будет использовать для создания желаемого изображения. Текстовая подсказка должна быть на английском языке, так как модель обучалась в основном с английскими подписями и лучше всего работает с этим языком.
Вот полный обзор всех допустимых входных данных:
- строка подсказки: это подсказка для ввода, описывающая желаемое содержимое изображения. По умолчанию установлено "видение рая. Нереальный движок".
- image_dimensions string: этот вход определяет размеры выходного изображения в пикселях. Вы можете выбрать между "512 x 512" и "768 x 768" со значением по умолчанию "768 x 768".
- negative_prompt string: этот ввод позволяет вам указать элементы, которые вы не хотите видеть в выходном изображении.
- num_outputs integer: этот ввод определяет количество изображений, которые будут созданы в качестве вывода. Значение по умолчанию – 1.
- num_inference_steps integer: этот вход указывает количество шагов шумоподавления, которые должны быть выполнены в процессе создания изображения. Значение по умолчанию – 50.
- число guidance_scale: этот вход устанавливает масштаб для навигации без классификатора, что помогает контролировать процесс создания изображения. Значение по умолчанию – 7,5.
- строка планировщика: этот вход позволяет выбрать планировщик для процесса создания изображения. Доступны следующие параметры: DDIM, K_EULER, DPMSolverMultstep, K_EULER_ANCESTRAL, PNDM и KLMS. Значение по умолчанию — Дпмсолвермультистеп.
- целочисленное начальное число: этот ввод задает случайное начальное число, используемое для процесса создания изображения. Оставьте это поле пустым, чтобы рандомизировать начальное число.
Результаты
Выход модели стабильной диффузии представляет собой фотореалистичное изображение, основанное на предоставленной текстовой подсказке. Сгенерированное изображение будет иметь фиксированный размер 512 x 512 или 768 x 768, в зависимости от версии используемой модели.
Теперь, когда мы понимаем входные и выходные данные модели, давайте углубимся в использование модели для создания изображений на основе наших текстовых подсказок.
Пошаговое руководство по использованию модели стабильной диффузии
Если вы не готовы к программированию, вы можете напрямую взаимодействовать с «демо» модели стабильного распространения на Replicate через их пользовательский интерфейс. Это отличный способ поэкспериментировать с параметрами модели и быстро получить обратную связь и подтверждение. Кроме того, Replicate предлагает бесплатное использование до определенного количества запросов, поэтому вам даже не нужно платить за использование модели.
И, конечно же, если вы можете запустить Stable Diffusion в своем браузере, вам не нужно загружать схематичное приложение и пытаться установить его на свой компьютер.
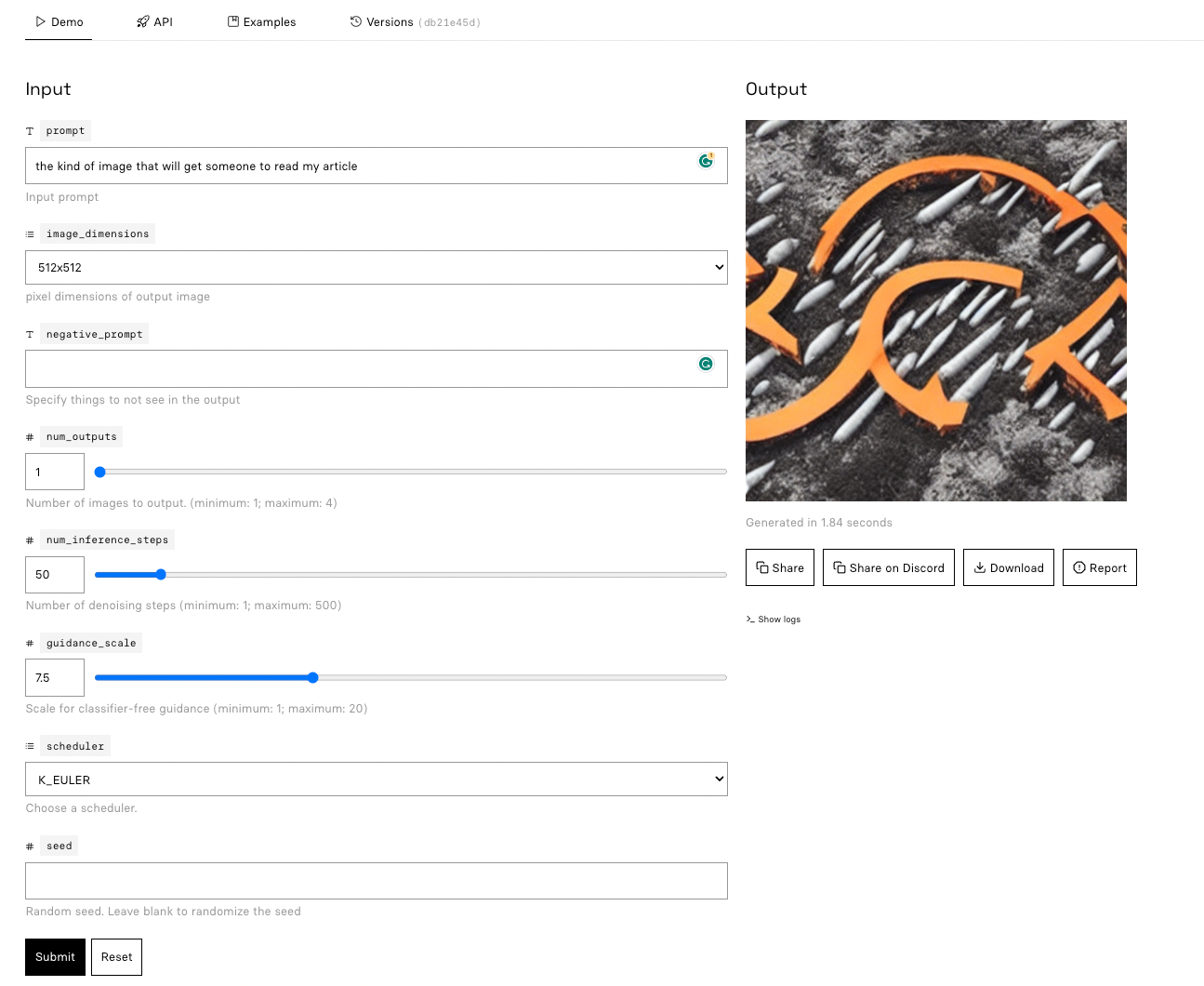
Шаг 1. Найдите страницу Stable Diffusion Model в репликации
Перейдите на страницу Stable Diffusion. на Репликате. По умолчанию вы будете на вкладке «демо». Эта вкладка позволит вам запустить Stable Diffusion в вашем браузере. Согласно веб-сайту Replicate:
<цитата>"Веб-интерфейс – это хорошее место для первого знакомства с моделью. Он дает визуальное представление обо всех входных данных модели и создает форму для запуска модели прямо из браузера"
Шаг 2. Предоставьте текстовое приглашение
Введите текстовое приглашение в соответствующее поле ввода. Эта подсказка поможет модели создать изображение. Будьте максимально описательными, чтобы помочь модели более точно представить вашу идею.
Например, подсказка: «джентльмен выдра на портрете 19 века» с настройками по умолчанию дает...

Шаг 3. Настройте параметры модели (необязательно)
Если вы хотите точно настроить сгенерированное изображение, вы можете настроить параметры модели, такие как шкала навигации или количество шагов выборки. Имейте в виду, что изменение этих параметров может повлиять на качество изображения и время генерации. Например, если я изменю шкалу навигации на «2» вместо «7,5» с той же подсказкой, что и выше, я получу...

Шаг 4. Создайте изображение
После того как вы ввели текстовое приглашение и настроили все параметры модели, нажмите кнопку "Отправить". Модель создаст изображение в течение нескольких секунд, после чего вы сможете просмотреть полученное фотореалистичное изображение на основе введенных вами данных.
Дальше: поиск других моделей преобразования текста в изображение с помощью Replicate Codex
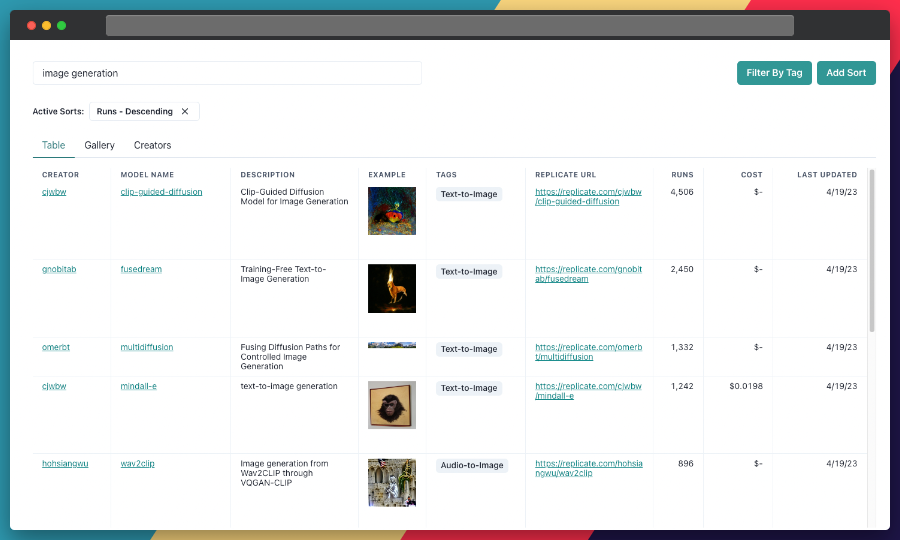
Replicate Codex — это фантастический ресурс для поиска моделей ИИ, отвечающих различным творческим потребностям, включая создание изображений, преобразование изображений в изображения и т. д. Это полностью доступная для поиска, фильтруемая, помеченная база данных всех моделей в репликации, а также позволяет сравнивать модели и сортировать по цене или исследовать по создателю. Это бесплатно, а также содержит сводку по электронной почте, которая будет уведомлять вас о выходе новых моделей, чтобы вы могли их опробовать.
Если вам интересно найти модели, похожие на Stable Diffusion...
Шаг 1. Посетите Replicate Codex
Перейдите на страницу Replicate Codex, чтобы начать поиск похожих модели.
Шаг 2. Используйте панель поиска
Используйте панель поиска в верхней части страницы для поиска моделей по определенным ключевым словам, таким как "преобразование текста в изображение" или "генерация изображения". Это покажет вам список моделей, связанных с вашим поисковым запросом.
Шаг 3. Отфильтруйте результаты
В левой части страницы результатов поиска вы найдете несколько фильтров, которые помогут вам сузить список моделей. Вы можете фильтровать и сортировать модели по типу (преобразование изображения в изображение, преобразование текста в изображение и т. д.), стоимости, популярности или даже по конкретным создателям.
Применяя эти фильтры, вы можете найти модели, которые наилучшим образом соответствуют вашим конкретным потребностям и предпочтениям. Например, если вы ищете самую дешевую или самую популярную модель преобразования текста в изображение, вы можете просто выполнить поиск, а затем отсортировать по соответствующему показателю.
Заключение
В этом руководстве мы подробно погрузились в мир Stable Diffusion, удивительной модели искусственного интеллекта, способной генерировать фотореалистичные изображения из текстовых подсказок. Мы узнали о его происхождении, архитектуре и о том, как эффективно использовать его для создания впечатляющих изображений в наших браузерах. Мы также обсудили, как использовать функции поиска и фильтрации в Replicate Codex, чтобы найти похожие модели и сравнить их результаты, что позволит нам расширить наши горизонты в мире создания изображений с помощью ИИ.
Я надеюсь, что это руководство вдохновило вас на изучение творческих возможностей ИИ и воплощение вашего воображения в жизнь. Не забудьте подписаться, чтобы получать дополнительные руководства, новости о новых и улучшенных моделях искусственного интеллекта и море вдохновения для вашего следующего творческого проекта. Спасибо за прочтение!
:::информация Также опубликовано здесь.
:::
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27664)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)