

В одном приглашении будет то, что ИИ рэп и танцы
8 августа 2025 г.Авторы:
(1) Цзябен Чен, Университет штата Массачусетс Амхерст;
(2) Синь Ян, Университет Ухана;
(3) Ихан Чен, Университет Ухан;
(4) Сиюань Сен, Университет штата Массачусетс Амхерст;
(5) Qinwei MA, Университет Цинхуа;
(6) Хаою Чжэнь, Университет Шанхай Цзяо Тонг;
(7) Каижи Цянь, MIT-IBM Watson AI Lab;
(8) ложь Лу, Dolby Laboratories;
(9) Чуан Ган, Университет штата Массачусетс Амхерст.
Таблица ссылок
Аннотация и 1. Введение
Связанная работа
2.1 Текст на вокальное поколение
2.2 Текст на генерацию движения
2.3 Аудио до генерации движения
Раскоростный набор данных
3.1 Рэп-вокальное подмножество
3.2 Подмножество рэп-движения
Метод
4.1 Составление проблемы
4.2 Motion VQ-VAE Tokenizer
4.3 Vocal2Unit Audio Tokenizer
4.4 Общее авторегрессивное моделирование
Эксперименты
5.1 Экспериментальная установка
5.2 Анализ основных результатов и 5.3 исследование абляции
Заключение и ссылки
А. Приложение
Абстрактный
В этой работе мы представляем сложную задачу для одновременного генерации трехмерных целостных движений тела и поют вокал непосредственно из вводов текстовых текстов, выходя за рамки существующих работ, которые обычно рассматривают эти два модальности в изоляции. Чтобы облегчить это, мы сначала собираем Rapverse DataSet, большой набор данных, содержащий синхронный рэп-вокал, тексты и высококачественные 3D-целостные сетки. С помощью Rapverse DataSet мы исследуем степень, в которой масштабирование авторегрессивных мультимодальных трансформаторов по языку, аудио и движению может улучшить когерентное и реалистичное поколение вокала и человеческих движений всего тела. Для объединения модальности используется векторный вариационный автоэкодер для кодирования последовательностей движения целого тела в отдельные токены движения, в то время как модель вокала в единицу используется для получения квантованных звуковых токенов, сохраняющих содержание, просодическую информацию и идентичность певца. Совместно выполняя моделирование трансформатора в этих трех модальностях единым образом, наша структура обеспечивает бесшовную и реалистичную смесь вокала и человеческих движений. Обширные эксперименты демонстрируют, что наша структура объединенного поколения не только производит последовательные и реалистичные поющие вокалы наряду с человеческими движениями непосредственно из текстовых входов, но также конкурирует с помощью специализированных систем генерации с одной модальностью, устанавливая новые критерии для совместного генерации вокального движения. Страница проекта доступна для исследовательских целей по адресу https://vis-www.cs.umass.edu/rapverse.
1 Введение
В развивающемся ландшафте мультимодального генерации содержания с точки зрения звука и движения были сделаны значительные шаги в отдельных модальностях, включая текст к музыке [54, 1, 21], текстовые к Vocal [32], текст к движению [13, 69, 4, 23, 34] и поколение аудио-движения [68, 15, 31]. Эти разработки проложили путь для создания более динамичного и интерактивного цифрового контента. Несмотря на эти достижения, существующие работы преимущественно работают в бункерах, обращаясь к каждой модальности в изоляции. Тем не менее, существуют убедительные психологические доказательства того, что для людей генерация звука и движения тесно связана и связана [28]. Унифицированная система для совместной генерации допускает более выразительное и нюансированное общение эмоций, намерений и контекста, где генерация одной модальности может направлять и помочь другому последовательно и эффективно.
В этой статье мы решаем решающую проблему: может ли машина не только петь с эмоциональной глубиной, но и выполнять с человеческими выражениями и движениями? Мы предлагаем новую задачу для создания когерентного поющего вокала и человеческих движений всего тела (включая движения тела, жесты рук и выражения лица) одновременно, см. Рис. 1. Это стремление имеет практическое значение в стимулировании более захватывающих и натуралистических цифровых взаимодействий, тем самым повышая виртуальные выступления, интерактивные игры и реализованные аватары.
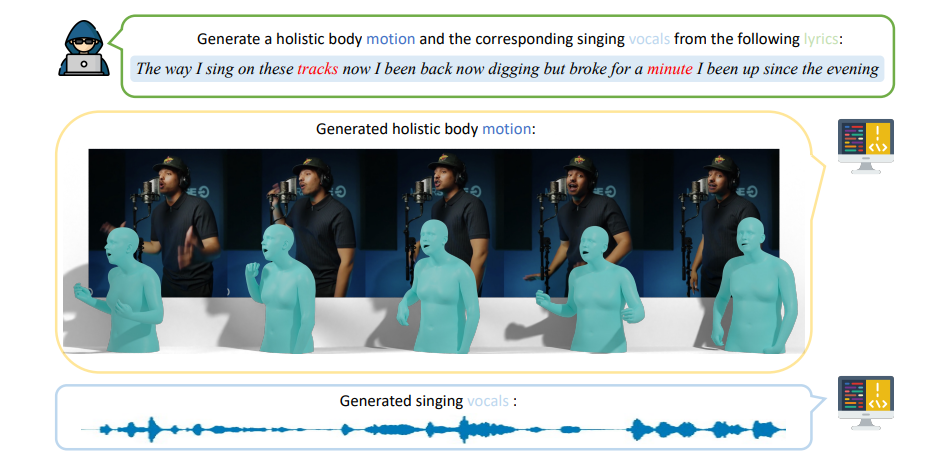
Естественно возникает важный вопрос: что является хорошей моделью для единого генерации звука и движения? Во -первых, мы рассматриваем текстовую лирику как правильную форму входных данных для единой системы, поскольку текст обеспечивает очень выразительные, интерпретируемые гибкие средства передачи информации людьми и может служить мостом между различными модальностями. Предыдущие усилия исследуют оценки [32], команды действий [69, 4, 23] или аудиосигналы [68] в качестве входных данных, которые уступают текстовым входам с точки зрения семантического богатства, выразительности и гибкой интеграции различных модальностей.
Во-вторых, мы считаем, что система совместной генерации, которая может создавать многомодальные выходы одновременно, лучше, чем каскадная система, которая последовательно выполняет одномодальную генерацию. Каскадная система, объединяющая модуль текста квокат с модулем вокала, рискует накапливать ошибки на каждом этапе генерации. Например, неверное толкование в фазе текста к -вокату может привести к неточной генерации движения, тем самым разбавляя предполагаемую когерентность выхода. Кроме того, каскадные архитектуры требуют множественных фаз обучения и вывода в разных моделях, что существенно увеличивает вычислительные требования.
Чтобы построить такую систему совместной генерации, основные проблемы включают: 1) одновременно нехватку наборов данных, которые предоставляют тексты, вокал и 3D-аннотации движения всего тела; и 2) необходимость в единой архитектуре, способной когерентно синтезировать вокал и движения из текста. В ответ на эти проблемы мы создали Rapverse, крупномасштабный набор данных, включающий полную коллекцию текстов, поют вокал и трехмерные движения всего тела. Несмотря на существование наборов данных, доступных для текста вдокаль, [32, 22, 8, 55], текста-к движению [44, 35, 13, 30] и аудио-движения [3, 15, 12, 9, 5, 65], в ландшафте не хватает единого набора данных, который инкапсуляет пение вокала, движение цельного и текста. В частности, крупные наборы данных текста к сводам [22, 70] в основном находятся в китайском языке, ограничивая их применимость для исследований на английском языке и отсутствуют какие-либо данные о движении. И наборы данных текста к мощности [44, 13, 30] обычно фокусируются на описаниях текста конкретных действий, в сочетании с соответствующими движениями без аудиоданных, часто не охватывающих движения всего тела. Более того, наборы данных по аудио-движению [32, 33] сосредоточены в первую очередь на речи, а не на пении. Сравнение существующих связанных наборов данных показано в таблице. 1РэпверсНабор данных разделен на две отличительные части, чтобы удовлетворить широкий спектр потребностей в исследованиях: 1) подмножество рэп-вокального, содержащее большое количество пар вокала и текстов, и 2) подмножество рэп-хода, охватывающее вокал, тексты человека и человеческие движения. Рэп-вокальное подмножество содержит 108,44 часа высококачественного английского поющего голоса в жанре рэпа без фоновой музыки. Парные тексты и вокал заполняются из Интернета от 32 певцов, с тщательной очисткой и пост-обработкой. С другой стороны, подмножество Rap-Motion содержит 26,8 часа видеопроизводительных видеороликов RAP с 3D-целостными аннотациями сетки тела в параметрах SMPL-X [42] с использованием конвейера аннотации Motion-X [30], синхронного поющего вокала и соответствующих текстов.
С помощью Rapverse DataSet мы исследуем, как далеко мы можем продвинуться, просто масштабируя авторегрессивные мультимодальные трансформаторы с языком, аудио и движением для последовательного и реалистичного поколения вокала и человеческих движений всего тела. С этой целью мы объединяем различные модальности как представления токена. В частности, три VQVA [63] используются для сжатия последовательностей движения всего тела в трехуровневые дискретные токены для головы, тела и руки соответственно. Для вокальной генерации предыдущие работы [37, 7, 32, 37] имеют общую парадигму, создавая мель-спектрограммы аудиосигналов из входных текстовых функций и дополнительной информации о музыкальной оценке, следующей за вокадром [40, 62, 67] для реконструкции фазы. Мы черпаем вдохновение в домене речевого ресинтеза [45] и изучаем самоотверженное дискретное представление, чтобы квантовать необработанный аудиосигнал в дискретные токены при сохранении вокального контента и просодической информации. Затем, со всеми входными данными в дискретных представлениях, мы используем трансформатор для прогнозирования дискретных кодов аудио и движения в авторегрессии. Обширные эксперименты демонстрируют, что эта простая единая структура генерации не только производит реалистичные пение вокала наряду с человеческими движениями непосредственно из текстовых входов, но и конкурентов специализированных систем генерации одномодальности.
Подводя итог, эта статья вносит следующие взносы:
• Мы выпускаем Rapverse, большой набор данных с синхронным поющем вокалом, текстами и высококачественными 3D-целостными параметрами SMPL-X.
• Мы разрабатываем простую, но эффективную унифицированную структуру для совместного поколения поющего вокала и человеческих движений из текста с мультимодальным трансформатором в авторегрессии.
• Чтобы объединить представления различных методов, мы используем модель вокала в единицу для получения квантованных аудиотоков и использования композиционных VQVAE для получения дискретных движений.
• Экспериментальные результаты показывают, что наша структура конкурирует с помощью специализированных систем генерации одномодальности, устанавливая новые критерии для совместного генерации вокала и движения.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)