

Краткое руководство по очистке данных
21 октября 2022 г.Предположим, вы хотите как можно быстрее получить большие объемы информации с веб-сайта. Как это может быть сделано? В этой статье мы поговорим о парсинге данных и о том, как парсить Интернет. Кроме того, мы рассмотрим, что такое парсинг данных, почему вы хотели бы это сделать, как работают парсеры данных, и, наконец, мы рассмотрим различные процессы парсинга в Интернете. Я также включу краткий пример для справки.
Что такое парсинг данных?
Если вы когда-либо копировали контент с веб-сайта и вставляли его в другое место, вы выполняете очень ручную очистку данных. В этой статье мы будем использовать программные приложения для извлечения данных за нас.
Очистка данных — это процесс использования приложения для извлечения ценной информации с веб-сайта. Это позволит нам получать большие объемы данных с веб-сайтов за короткий промежуток времени. Многие крупные веб-сайты, такие как Google, Facebook и GitHub, имеют API-интерфейсы, которые позволяют вам получать доступ к их данным. Это очень удобно, потому что данные будут предоставлены вам в структурированном формате, удобном для использования.
К сожалению, это не всегда так. В других случаях вам придется собирать контент и данные для вашего конкретного варианта использования. Здесь пригодятся веб-приложения и приложения для очистки данных. Вы можете запрограммировать эти приложения для очистки, чтобы посещать веб-сайты и извлекать контент/данные, которые вы хотите. Очевидным преимуществом этого является возможность легко и эффективно получать точные данные, которые вам нужны.
Парсинг данных состоит из двух частей: сканера и парсера. Сканер — это алгоритм, который мы можем создать, чтобы просматривать веб-страницы и находить именно те данные, которые нам нужны. Примером этого может быть переход на определенный веб-сайт и нажатие на страницу, на которой находится нужный контент. Как только вы найдете эти данные, мы воспользуемся парсером. Скрапер используется для «очистки» данных с веб-сайта. С помощью парсера вы можете обнаружить нужные точки данных и экспортировать их в формат, который лучше всего подходит для вас.
Как только данные будут экспортированы, самое интересное может начаться. Вы можете использовать эти данные по своему усмотрению.
Случаи использования для извлечения данных
При чтении этой статьи вы, вероятно, задавались вопросом: "Какие есть хорошие варианты использования парсинга веб-страниц или данных?" Давайте рассмотрим пару таких вариантов использования.
Первый, о котором мы будем говорить, мой любимый, мониторинг цен. Вы можете использовать мониторинг цен, чтобы отслеживать цены и убедиться, что вы находите лучшее предложение. Кто не хочет сэкономить? Я написал предыдущий сообщение в блоге о парсинге Amazon.com для отслеживания цен на определенные товары. Компании также могут использовать анализ цен, чтобы узнать, какие цены на аналогичные продукты у конкурентов. Это дает им возможность устанавливать оптимальные цены на свои продукты и получать максимальный доход.
Очистка контактов — это еще один способ очистки данных. Многие компании и частные лица могут просматривать в Интернете контактную информацию для использования в маркетинге по электронной почте. Хорошим примером этого может быть парсинг мест, таких как онлайн-каталог сотрудников или список массовой рассылки. Этот вариант использования очень спорный и часто требует разрешения на сбор такого рода данных. Если вы когда-либо посещали веб-сайт и предоставляли им доступ к вашей контактной информации в обмен на использование их программного обеспечения, вы разрешали им собирать личные данные, такие как ваш адрес электронной почты и номер телефона.
Последний вариант использования, который мы рассмотрим, — это мониторинг новостей. Многие люди и компании могут парсить новостные сайты, чтобы оставаться в курсе новостей и вопросов, имеющих отношение к ним. Это может быть особенно полезно, если вы пытаетесь создать фид какого-либо типа или вам просто нужно быть в курсе ежедневных отчетов.
Как работают парсеры данных?
Далее рассмотрим, как работают парсеры данных. Парсеры могут брать все содержимое веб-страниц или только определенные данные, которые вам нужны. Во многих ситуациях лучше всего указать конкретные данные, которые вам нужны, чтобы парсер данных мог быстро их извлечь. Например, в сообщении в блоге об очистке веб-страниц от Amazon, о котором я упоминал ранее, мы смотрим на цены на офисные стулья. В этом случае мы только пытаемся определить цену стульев и название предмета. Это позволило парсеру данных быстро отфильтровать любой ненужный беспорядок, в результате чего скрипт выполнялся относительно быстро.
Теперь, когда процесс парсинга сайта начинается впервые, должен быть URL-адрес, который предоставляется сценарию или прикладному программному обеспечению. На основе предоставленного URL-адреса парсер перейдет на эту веб-страницу. Затем он загрузит HTML-код этого сайта. После того, как этот код был загружен, парсер может начать собирать данные, которые требуются/необходимы. Наконец, собранные данные выводятся в предварительно определенном формате, определяемом пользователем. Обычно это файл JSON, но его также можно сохранить в других форматах, таких как электронная таблица Excel или файл CSV.
Пошаговый процесс парсинга
Теперь, когда мы знаем, как работает парсер данных, давайте определим некоторые предварительные шаги, которые необходимо выполнить, прежде чем пытаться самостоятельно парсить веб-сайт. Есть много интересных инструментов и программных приложений, которые помогают парсить веб-сайты. Поэтому мы останемся на высоком уровне и сосредоточимся на основах.
Во-первых, вам нужно найти URL-адреса, которые вы хотите очистить. Это может показаться очевидным, но это ключевой фактор и то, насколько хорошо будет работать ваш анализ данных. Если URL-адрес, который вы даете парсеру, хоть немного неверен, данные, которые вы получите обратно, будут не такими, как вы хотите, или, что еще хуже, ваш парсер вообще не будет работать. Например, если вы пытаетесь выполнить очистку данных мониторинга цен вы хотите убедиться, что ваш URL ведет на соответствующий сайт, такой как Amazon или Google.
Во-вторых, вы хотите проверить веб-страницу (f12 на большинстве клавиатур), чтобы определить, что ваш парсер должен очистить. Если мы используем тот же пример мониторинга цен на Amazon, вы можете перейти на страницу результатов поиска на Amazon, изучить эту страницу и определить, где в HTML-коде находится цена.
После этого вы хотите определить уникальные теги, связанные с ценой, чтобы использовать их в парсере данных. Некоторыми хорошими тегами будут теги div с идентификаторами или очень конкретными именами классов.
<div id="price">$1.99</div>
Найдя код, который вы хотите собрать и использовать, вы захотите включить его в свою очистку данных. Это может быть написание сценария с идентификаторами или именами классов, которые вы нашли на предыдущем шаге, или просто ввод тегов в программное обеспечение для очистки. Вы также, вероятно, захотите добавить вспомогательную информацию, которая поможет при отображении ваших данных. Придерживаясь нашего примера с Amazon, если вы собираете цены на офисные стулья на Amazon, было бы неплохо также указать название товара, сопровождающее цену.
После того, как вы указали теги в своем скрипте или приложении для очистки, вы захотите выполнить код. Здесь происходит вся магия. Все, о чем мы говорили в предыдущем разделе о том, как работают парсеры данных, вступает в игру здесь.
Надеюсь, теперь у вас есть данные, необходимые для создания приложения. Будь то информационная панель с диаграммами, крутая таблица или приятный фид контента, данные принадлежат вам, и вы можете делать с ними то, что вам нравится. Много раз вы можете получить данные, которые вы не ожидаете. Это совершенно нормально. Как и во всем остальном в инженерном мире, если одна крошечная деталь не работает, это часто может привести к неправильной работе. Не расстраивайтесь! Практика ведет к совершенству, и вы поймете.
Извлечение данных с помощью браузера
Мы рассмотрели все основы парсинга веб-страниц. Прежде чем мы закончим, я хочу упомянуть классный инструмент, который позволяет вам делать парсинг данных. Browserless – это безголовый браузер Chrome как услуга. Вы можете использовать браузер без браузера с такими библиотеками, как puppeteer или Selenium. для автоматизации веб-задач, таких как сбор данных. Чтобы узнать больше, посетите веб-сайт без браузера, где можно найти сообщения в блогах, документацию, отладчики и другие ресурсы.
Пример извлечения данных с помощью браузера
В этом примере мы собираемся выполнить простую очистку данных ленты Y Combinator Hacker News. Вы также можете запустить этот пример в отладчике без браузера. Для этого мы будем использовать два основных инструмента: Puppeteer и Browserless. В предыдущем абзаце я упомянул эти инструменты с соответствующими ссылками. Я настоятельно рекомендую вам ознакомиться с ними, прежде чем погрузиться в пример.
Первоначальная настройка
Хорошо, приступим! Начнем с первоначальной настройки. К счастью для нас, нам нужно установить не так много зависимостей. Есть только один... Кукольник.
npm i puppeteer
После того как вы запустите эту команду, все готово! 👍
Настройка без браузера
Давайте посмотрим, как быстро настроить без браузера.
Для начала вам необходимо настроить учетную запись. Как только вы настроите свой аккаунт, вы будете перенаправлены на панель инструментов без браузера.
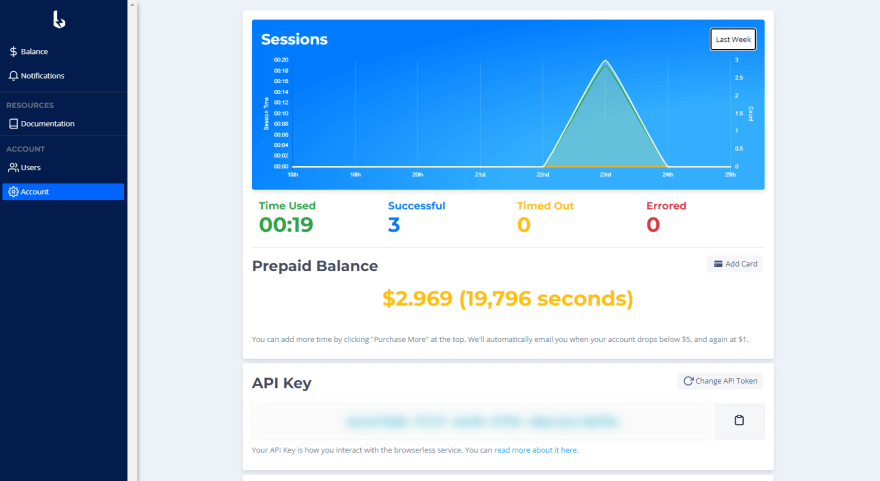
Здесь вы можете найти диаграмму использования вашего сеанса, предоплаченный баланс, ключ API и все другие полезные свойства учетной записи.
Держите ключ API под рукой, так как мы будем использовать его, как только начнем писать наш скрипт. В остальном мы готовы начать программировать!
Код
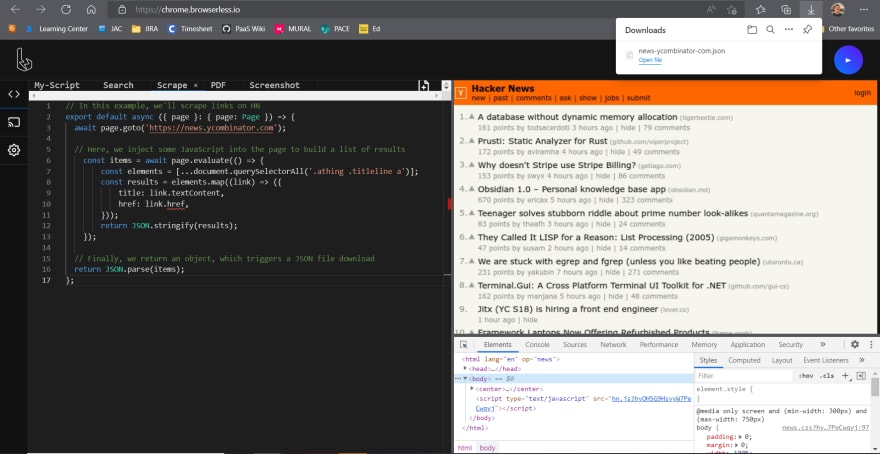
А теперь самое интересное! Вот пример кода:
const puppeteer = require("puppeteer");
const scrape = async () => {
const browser = await puppeteer.launch({ headless: false });
// const browser = await puppeteer.connect({ browserWSEndpoint: 'wss://chrome.browserless.io?token=[ADD BROWSERLESS API TOKEN HERE]' })
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com');
// Here, we inject some JavaScript into the page to build a list of results
const items = await page.evaluate(() => {
const elements = [...document.querySelectorAll('.athing .titleline a')];
const results = elements.map((link) => ({
title: link.textContent,
href: link.href,
}));
return JSON.stringify(results);
});
// Finally, we return an object, which triggers a JSON file download
return JSON.parse(items);
};
scrape();
Строки 4 и 5 очень важны в этом примере. Строка 4 использует Puppeteer при запуске вашего скрипта. Это удобно для тестирования, так как вы можете посмотреть, как браузер взаимодействует с вашим скриптом.
Строка 5 — подключение без браузера. Здесь вы можете добавить свой ключ API, который будет связан с вашей учетной записью без браузера и позволит вам запускать скрипт без браузера.
Убедитесь, что одна из этих двух строк закомментирована. Вам нужен только один.
Конечный продукт
Хорошо, это все, что вам нужно для этого примера. После того, как все будет установлено и код реализован, вы можете открыть предпочтительный интерфейс командной строки в своем проекте и запустить node [вставьте здесь имя js-файла].
На выходе должен быть файл JSON с заголовками в реальном времени и ссылками из ленты Hacker News!
Я надеялся, что эта статья о парсинге данных окажется интригующей и захватывающей. Есть бесконечные возможности того, что вы можете сделать с помощью очистки веб-страниц и данных. Надеюсь, это вдохновит некоторых из вас на фантастические проекты.
Удачного кодирования! ❤️
Также опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)