
Учебник по экономике ИИ
31 декабря 2022 г.Каждый раз, когда формируется новая бизнес-экосистема, мы должны задать простой вопрос: где создается ценность?
И как только мы сможем классифицировать экосистему на основе того, где создается ценность, мы можем задаться вопросом: как создается ценность?
Исходя из вышеизложенного, мы понимаем бизнес-модели, построенные на основе этой экосистемы.
С момента выпуска ChatGPT в конце ноября ясно одно: коммерческая жизнеспособность ИИ растет, что дает нам представление о том, как развивается экосистема ИИ.
Позвольте мне объяснить.
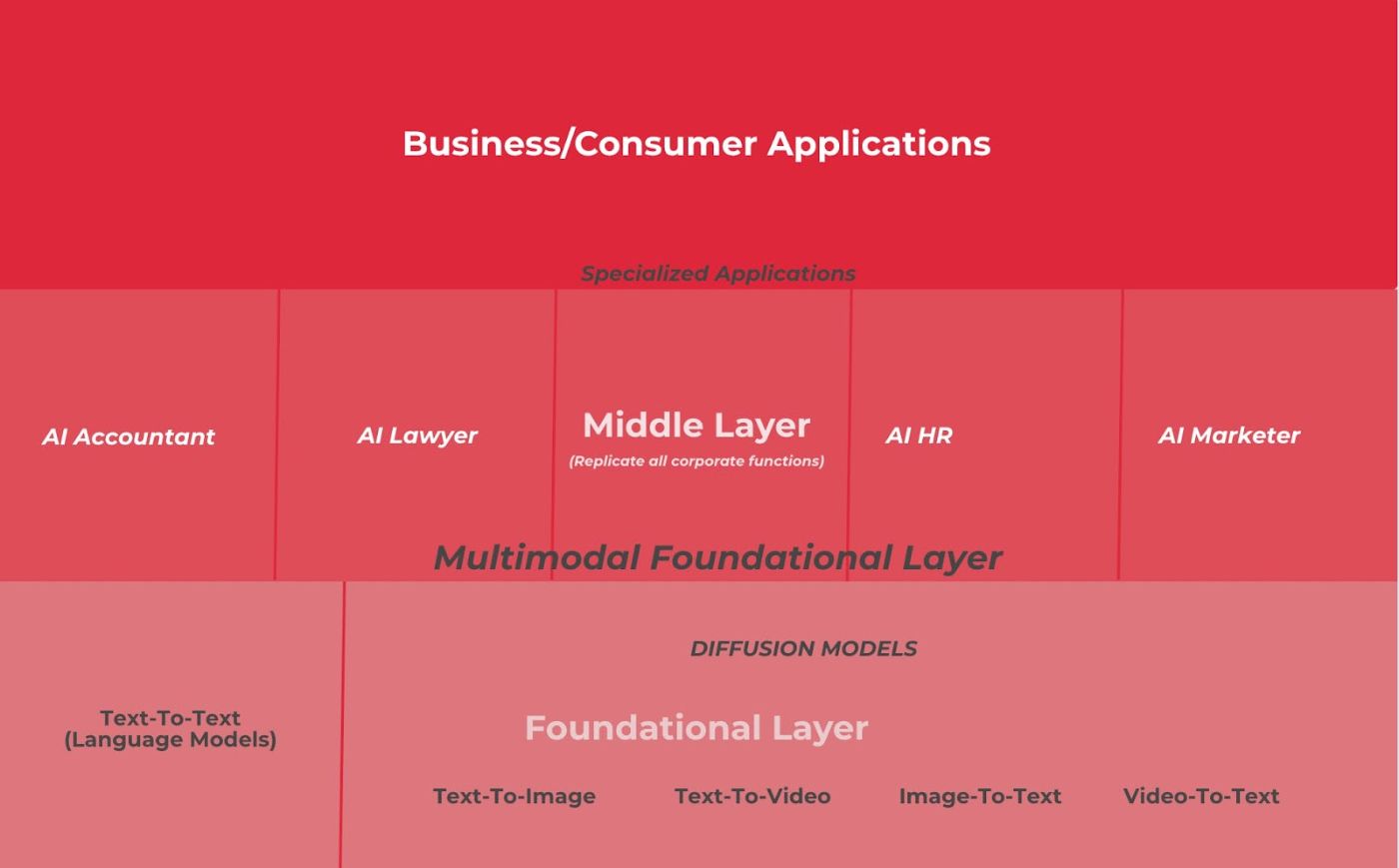
Основной слой
Это могут быть механизмы общего назначения, такие как GPT-3, DALL-E, StableDiffusion и т. д.
Этот слой может иметь следующие ключевые особенности:
Общее назначение: он будет создан для предоставления более общих решений для любых конкретных потребностей.
Этот уровень может быть в основном уровнем B2B/Enterprise, с одной стороны, поддерживающим множество предприятий.
Так же, как AWS в 2010-х годах, на базе приложений, созданных на основе Web 2.0 (Netflix, Slack, Uber и многих других).
Базовый уровень искусственного интеллекта (по-прежнему основанный на централизованных облачных инфраструктурах) может дать толчок следующей волне потребительских приложений.
Это будет коммерческий кембрийский взрыв…
Мультимодальные: эти механизмы общего назначения будут мультимодальными.
Это означает, что они могут обрабатывать любые виды взаимодействия, будь то текст в текст, текст в изображение, текст в видео и наоборот.
Таким образом, он может двигаться в двух направлениях.
С одной стороны, UX может в первую очередь управляться инструкциями на естественном языке.
С другой стороны, искусственный интеллект, встроенный во множество веб-инструментов, сможет считывать, классифицировать и изучать закономерности во всех форматах, доступных в Интернете.
Эта двусторонняя система может привести к следующему этапу эволюции базовой модели, превратившись в механизмы общего назначения, способные делать множество вещей.
Интерфейс на естественном языке. Основной интерфейс для этих универсальных движков может быть на естественном языке.
Сегодня это выражается в виде подсказки (или инструкции на естественном языке).
Однако подсказка может оставаться ключевой чертой фундаментального слоя; вместо этого он может исчезнуть на уровне приложений, где эти механизмы ИИ могут в основном работать как механизмы обнаружения на основе push (ИИ будет обслуживать то, что, по его мнению, важно для пользователей).
В режиме реального времени. Эти механизмы могут адаптироваться в режиме реального времени, имея возможность считывать шаблоны по мере того, как мы ориентируемся в реальном мире.
Я утверждаю, что это будет ключевой функцией, позволяющей интегрировать эти интерфейсы общего назначения в дополненная реальность!
Средний слой
Это могут быть вертикальные механизмы (представьте, что здесь вы найдете своего ИИ-юриста, бухгалтера, ИИ-помощника по кадрам или ИИ-маркетолога).
Этот средний уровень может быть построен поверх базового уровня, объединяя другие механизмы "среднего уровня", способные стать лучшими в очень специфических задачах.
Этот средний слой может:
Репликация корпоративных функций. Таким образом, первым шагом в этом направлении может стать ИИ, способный воспроизводить каждую из соответствующих корпоративных функций.
От бухгалтерии до отдела кадров, маркетинга и продаж.
Этот средний уровень улучшит компанию, позволяя управлять отделами, состоящими из людей и машин.
Рвы данных. Здесь дифференциация может быть построена поверх рвов данных.
Это означает, что благодаря постоянной тонкой настройке механизмов базового уровня для адаптации к функциям среднего уровня эти специализированные ИИ станут актуальными для конкретных задач.
движки искусственного интеллекта. Эти игроки среднего уровня могут также иметь возможность добавлять другие механизмы поверх существующих базовых уровней при создании определенных конвейеров данных для обучения моделей конкретным задачам.
И возможность адаптировать эти модели, чтобы сделать их все более и более подходящими для специализированных функций.
И слой приложения
Это может привести к появлению множества небольших и гораздо более специализированных приложений, построенных поверх среднего уровня.
Они будут развиваться на основе следующего:
Сетевые эффекты: здесь увеличение пользовательской базы будет иметь решающее значение для создания сетевых эффектов.
Петли обратной связи: петли обратной связи пользователей могут стать критически важными для обеспечения сетевых эффектов.
Какие бизнес-модели мы увидим?
На мой взгляд, базовый уровень может быть связан с новым App Store и AWS!
С одной стороны, он будет служить базовой инфраструктурой для создания новых приложений.
С другой стороны, это может быть торговая площадка, на которой создаются эти приложения!
Средний уровень изначально может работать как корпоративная бизнес-модель.
Таким образом, мы предоставляем организациям очень индивидуальные решения, которые будут соответствовать целям компании.
Компании могут получать эти движки искусственного интеллекта на зарплату, как если бы это была сила нового работодателя.
Уровень приложений может следовать трем основным типам бизнес-моделей: на основе рекламы, на основе подписки и на основе потребления.
Если мы все создадим инструменты на основе ChatGPT или аналогичных моделей, как мы сможем построить конкурентный ров?
Другими словами, как мы можем построить компанию на основе ИИ, которая будет иметь долгосрочное преимущество и которую нельзя легко превратить в товар?
Это очень важный вопрос, и я много думал об этом!
Итак, позвольте мне ответить на несколько вопросов.
На трех уровнях ИИ я объяснил, как может выглядеть бизнес-экосистема ИИ.
Теперь, когда вы это поняли, давайте посмотрим, что — я утверждаю — может создать конкурентный ров в ИИ.
Обновление базовых моделей (GPT-3, DALL-E, Stable Diffusion, Midjourney и т. д.)
Сейчас еще есть возможности для арбитража.
Это означает, что базовые модели (движки общего назначения, такие как GPT-3 или Stable Diffusion) по-прежнему хорошо справляются со специфическими модальностями.
Например, GPT-3 отлично справляется с преобразованием текста в текст, но плохо работает с изображениями.
DALL-E отлично справляется с преобразованием текста в изображение, но плохо, когда речь идет о создании текста, который имеет смысл поверх этих изображений.
Так, например, если вы создаете продукт с искусственным интеллектом, вы также можете смешать эти модели:
* Улучшить их способность обрабатывать больше модальностей. Так, например, вы можете объединить возможности GPT-3 и DALL-E, чтобы инструмент правильно обрабатывал как текст, так и изображения для пользователя. * Кроме того, вы можете настроить свою модель на основе более фундаментальных моделей. Например, представьте, что вы создаете рынок ИИ; вместо того, чтобы полагаться только на DALL-E, Stable Diffusion или Midjourney, вы можете смешать эти три модели, чтобы сделать изображения более интересными на протяжении многих лет. * Третий элемент: как мы увидим, вы можете добавить что-то поверх этих базовых слоев, чтобы сделать окончательный результат намного более безупречным.
Конечно, велика вероятность того, что этот рынок может стать олигополией, где несколько игроков могут контролировать большую его часть и, таким образом, получать значительную долю стоимости, что создает для них невероятный ров.
Это потому, что если вы работаете с OpenAI, вы можете работать с большой генеративной моделью, такой как GPT-3, вперед.
Если вы представляете небольшой стартап, сделать это с нуля может быть намного сложнее.
И чем больше будут развиваться эти основополагающие модели, тем труднее будет преодолеть входные барьеры, что приведет к скачку вперед для игроков фундаментального уровня, таких как OpenAI и остальных.
Способ, которым OpenAI и другие организации базового уровня могут получать прибыль, может быть в форме открытых API, как это происходит сегодня.
Или они действительно могут стать своего рода App Store для приложений ИИ, где они смогут облагать налогом каждый из инструментов ИИ, разработанных поверх каждой экосистемы, таким образом извлекая выгоду из этого, подобно тому, что происходит сегодня с Apple App Store.< /p>
Рвы данных
Модели искусственного интеллекта прямо сейчас могут быть очень хороши для решения многих задач.
Однако, чтобы сделать их актуальными для компаний на уровне предприятия или для пользователей в конкретных приложениях, данные становятся критически важными, чтобы позволить настраивать модель на основе технологического стека (для корпоративных компаний) и контекста (для пользователей). вкл.
Например, представьте себе организацию, которая хочет использовать искусственный интеллект для предоставления своим пользователям персонализированных возможностей.
Для этого ему потребуется использовать собственные данные, которые будут интегрированы в эти модели.
Например, предположим, что компания хочет создать очень специализированного чат-бота для поддержки.
Конечно, это можно сделать разными способами,
* Тренируйтесь на контенте, который компания создавала годами. * Создайте набор данных вопросов и ответов на основе наиболее частых запросов пользователей. * Ответьте на гораздо более точные вопросы, связанные с конверсией, на основе данных CRM.
Короче говоря, корпоративная организация будет использовать эти собственные данные, чтобы интегрировать их в модель ИИ, чтобы сделать их максимально актуальными.
Вот как это приложение ИИ становится ценным.
Для этого становится критически важным:
Интеграция данных: понять, какие данные действительно важны для ИИ, чтобы лучше справляться с конкретными задачами.
Курирование данных: чтобы понять, как очистить соответствующие сторонние проприетарные данные, которые можно использовать для обучения модели.
Точная настройка: базовые модели очень эффективны. Тем не менее, они были обучены выполнять множество задач. Вы можете точно настроить базовую модель (загрузив контекстные данные и настроив эти модели) для получения более качественных результатов. Таким образом, тонкая настройка становится критически важной для того, чтобы вы могли создать ценный продукт искусственного интеллекта поверх существующих базовых слоев.
Подсистемы искусственного интеллекта среднего уровня. Еще одним интересным моментом является тот факт, что компания, занимающаяся искусственным интеллектом среднего уровня, по-прежнему может создавать усовершенствованные механизмы на основе существующих базовых моделей. Возьмем, к примеру, компанию, которая создает инструмент искусственного интеллекта для создания резюме. Вы все еще можете добавить поверх него движок ИИ, который выполняет перефразирование, дальнейшую проверку грамматики, плагиат и многое другое, что будет дополнительным слоем поверх базового слоя! Вот как вы можете преобразовать стандартизированный вывод из основного механизма общего назначения во что-то более конкретное.
Быстрый взлом (новая парадигма кодирования, скрытая в бэкенде)
В течение многих лет нейронные сети застревали, пока не начали делать невероятные вещи.
И самое интересное?
Большинство из этих интересных вещей были результатом масштабирования этих сетей.
Другими словами, после применения новой архитектуры (архитектуры на основе преобразователя) остальная работа выполняется за счет масштабирования.
Теперь в масштабировании есть непредсказуемый компонент.
Точно так же, когда вы масштабируете компанию после определенного порога, вы не знаете, как эта компания может измениться и какие свойства могут появиться.
При масштабировании нейронных сетей на основе одних и тех же архитектур возникают различные свойства.
В биологии эмерджентность (или то, как сложная система ведет себя совершенно иначе, чем ее части, поскольку система в целом зависит от взаимодействия между ее частями) чрезвычайно важна.
Ведь даже в реальном мире, который часто выглядит фрактальным (меньшее похоже на большее), на самом деле гораздо большее обладает совершенно другими свойствами!
Это одна из тем, которая меня больше всего интересует в бизнесе.
И это также то, что делает ИИ таким интересным для меня сейчас.
Масштабируя системы ИИ, мы получаем непредсказуемые новые свойства, которые, к лучшему или к худшему, могут повлиять на эволюцию ИИ.
Например, подсказки или возможность изменять вывод моделей ИИ на основе естественного языка стали новым свойством.
Никто не закодировал его в систему; это только что получилось в результате масштабирования этих моделей ИИ.
И еще один интересный аспект, я утверждаю, заключается в том, что подсказки больше похожи на программирование, чем на поиск или запрос.
На мой взгляд, те, кто сравнивает подсказку с поиском, ошибаются.
Подсказки намного мощнее, и со временем они могут быть скрыты в пользовательском интерфейсе, а не отображаться для конечных пользователей.
В этом контексте быстрый взлом или процесс настройки инструкции на естественном языке, чтобы модель ИИ полностью обновила ее вывод, может быть чрезвычайно эффективным.
Вот почему я добавляю быстрый взлом ключевых элементов для создания искусственного рва.
Мой главный аргумент заключается в том, что в кодовой базе, которая становится гораздо более товарной (сегодня ChatGPT может генерировать код, а также исправлять ошибки в коде), быстрый взлом может быть основной ценностью программного обеспечения, поскольку он позволяет модели ИИ немного улучшить его производительность!
Конечно, для приложений ИИ корпоративного уровня подсказки могут по-прежнему быть частью интерфейса, поскольку они дают корпоративному клиенту возможность в высшей степени настроить вводимые данные.
Тем не менее, будет часть подсказки (подсказка взлома), которая может быть скрыта в пользовательском интерфейсе.
В то время как для потребительских приложений взлом подсказок может быть полностью скрыт в интерфейсе, предоставляя пользователям стандартные возможности для настройки своих выходных данных.
Оставшаяся часть настройки будет зависеть от контекста и интересов пользователя.
Сетевые эффекты и циклы быстрой итерации
Практика интернет-бизнеса учит нас тому, что ценность веб-приложения может заключаться не только в его технологии, но и в его способности улучшаться в зависимости от масштаба.
Возможно, вы каждый день используете такие приложения, как Netflix, Uber, Airbnb, LinkedIn, YouTube, TikTok и т. д., ценность которых заключается в их способности становиться все лучше и лучше по мере того, как к ним присоединяются все больше пользователей.
Это называется сетевым эффектом.
Вы бы продолжали пользоваться YouTube, если бы у вас не было такой обширной библиотеки контента и механизма поиска, который постоянно рекомендует вам интересные и увлекательные материалы?
Точно так же, как цифровые компании могут создавать свои рвы с помощью сетевых эффектов, компании, использующие искусственный интеллект, могут делать то же самое.
Здесь нет ничего нового, поскольку такие компании, как Meta, Google, Netflix, TikTok и многие другие, используют взаимодействие людей в сочетании с алгоритмами искусственного интеллекта для масштабного улучшения своих продуктов.
Например, в 2019 году я утверждал, что TikTok такой интересный не потому, что это новое приложение для социальных сетей.
Как раз наоборот.
Это было так интересно, потому что вышло за пределы социальной сети, используя алгоритмы искусственного интеллекта, чтобы пользователи могли находить контент за пределами своих связей!
Вот что сделало TikTok таким прилипчивым...
Рабочий процесс
То, как компания комбинирует все вышеперечисленное для создания быстрых итерационных циклов разработки, запуска, итерации, обслуживания и расширения приложений ИИ, станет критическим рвом для компании!
У каждой масштабной компании, занимающейся ИИ, будет собственный рабочий процесс, который будет барьером для входа, а не эффектом масштаба.
Это будет эквивалентно экономии за счет масштаба (благодаря более эффективному рабочему процессу ИИ-компании смогут создавать все больше и больше функций и объединять различные продукты для создания более комплексного опыта).
Таким образом, другим компаниям становится все труднее и труднее копировать!
Бренд и распространение
Там, где технологии могут превратиться в товар, брендинг создает сильную дифференциацию.
Это верно для технологических компаний эпохи Интернета, и это будет верно для компаний, занимающихся искусственным интеллектом, которые станут расширенной версией технологических компаний.
Кроме того, точно так же, как распространение играло ключевую роль для первых технологических игроков (я подробно рассказал о таких сделках, как < strong>Google-AOL или Apple-AT&T ), это будет так, когда дело доходит до ИИ-игроков.
Действительно, мы уже видели, как уже сложились некоторые ключевые партнерские отношения:
* OpenAI/Майкрософт * ДипМинд/Гугл * Стабильность AI/Apple * Amazon AWS использует собственный стек. * И так далее...
То, как будут формироваться эти партнерские отношения, будет важно не только с технологической точки зрения.
Они будут иметь значение с точки зрения распространения.
Действительно, парадокс этих моделей ИИ в настоящее время заключается в том, что они очень хорошо работают в качестве универсальных механизмов.
Однако предположим, что мы должны ограничить их, добавив слишком много ограждений.
В этом случае они вполне могут в конечном итоге потерять актуальность и для конкретных задач (например, ограничение способности ChatGTP давать ответы на темы, где он может ввести в заблуждение, а фактически изношенные ответы могут на самом деле ограничить его возможности!)
Таким образом, это означает, что с этими ИИ-компаниями мы можем увидеть другой тип модели распространения, где для того, чтобы эти модели стали отличными для конкретных задач, их сначала нужно будет использовать для гораздо более широких задач.
Это изменение парадигмы с точки зрения распространения.
Если в прошлом мы видели, как технологические игроки начинали с ниши, а затем масштабировались оттуда (Amazon был книжным онлайн-магазином, Facebook был социальной сетью для студентов Гарварда), мы можем увидеть, как эти компании ИИ расширяются, сразу, а затем сузить спектр их применения!
Например, прямо сейчас ChatGPT может быть движком общего назначения.
Тем не менее, со временем, как только они выяснят, какие приложения хорошо подходят, они также могут быть выпущены для определенных вертикалей.
Такое широкое распространение требует прочных партнерских отношений с другими крупными технологическими игроками, которые могут взять на себя это бремя!
Развертывание капитала
Вся новая область может потребовать значительных капиталовложений для масштабирования, а не для запуска на фундаментальном уровне.
Это значительно удешевит создание базовых (сначала) и более сложных (позже) приложений.
Таким образом, затраты на ведение бизнеса существенно снижаются.
Тем не менее, создание мощных фундаментальных механизмов искусственного интеллекта может потребовать огромных капиталовложений.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27740)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)