
Практическое руководство по масштабируемому планированию работы для облака и больших данных
13 августа 2025 г.Если вы когда -либо работали над проблемами с большими данными или ИИ, вы узнаете, что количество времени, необходимое для решения проблемы, пропорционально размеру/стоимости данных оборудования. Чтобы сократить время, мы либо уменьшаем размер данных (что невозможно), либо увеличиваем вычислительные средства - более широкие компании могут делать это с миллионами долларов, выпущенных каждый год, но небольшие компании не имеют такой роскоши. По крайней мере, не до того, как они достигнут порога, где облачные сервисы имеют больше смысла для масштабирования (они также могут арендовать оборудование заранее, чтобы обойти почасовые затраты).
В этой статье будет распространена оптимизации инфраструктуры, которые компания может использовать для эффективного повторного использования и максимизации мощности. Я рассмотрю настройку планировщика и различные параметры для планирования.
Необходимость в эффективном планировании
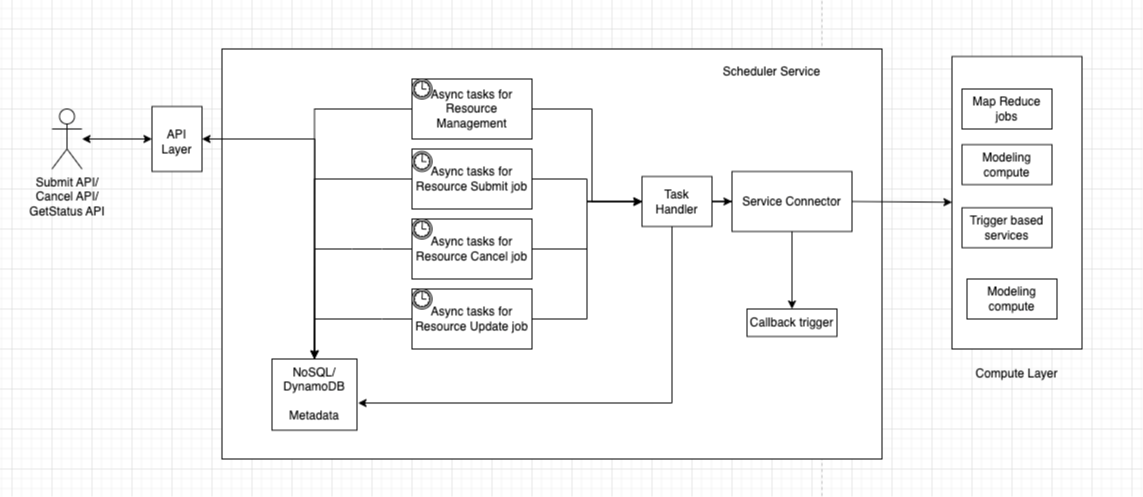
Как подчеркивается, основной задачей является сокращение вычислительного времени и затрат без жертв, особенно для команд, работающих с большими наборами данных, но работая с ограниченными бюджетами. Чтобы решить эту проблему, нам нужен планировщик, который может принять задание в качестве ввода, хранить информацию о работе, отправлять и отслеживать эти задания, обновлять метаданные и предоставлять механизм обратного вызова, если это необходимо. На приведенной ниже диаграмме показан вид высокого уровня базового дизайна планировщика, который может обрабатывать 90% случаев использования, которые встречаются в большинстве команд. Чтобы сделать его более масштабируемым, вы можете расширить несколько компонентов (учитывайте, что ваши учебные упражнения).
Прежде чем погрузиться в дизайн, мы должны сначала понять требования и проблему, которую мы пытаемся решить. В большинстве случаев, для больших данных ML, речь идет о эффективном выполнении больших заданий MapReduce. Мы определили ресурсы - такие как 100 больших кластеров или машин с 10 ГБ памяти - и мы должны соответствующим образом скорректировать наши задания. Мы также можем расширить этот дизайн до масштабируемого поставщика экземпляров облака. Например, если пользователь запрашивает определенную виртуальную машину, мы можем предоставить одну из нашего пула машин и раскрутить его для клиента. Это может служить стартовым проектом, если вы новичок в облачных сервисах и хотите его построить.
Внутренние
Поддерживается API
Этот дизайн служит отправной точкой, поэтому не стесняйтесь расширять его на основе ваших конкретных потребностей. Мы хотим поддерживать три API (вы можете использовать облачные API для размещения этого и использовать Server Bless Compute для обработки запросов). Для AWS они включают API Gateway и Services AWS. Мы хотим поддержать отправку, отменить, GetStatus API, чтобы мы знали, где находится наша работа, и вы можете добавить обратный вызов, если это необходимо. В некоторых случаях нам нужны обратные вызовы, потому что, если у нас есть тысячи рабочих мест, мы логически не можем опросить базу данных тысячи раз. Но если у нас есть обратные вызовы и SLA для службы, то нам нужно только опросить на тех, которые задерживаются или не удалены, а затем автоматически получить вызов обновления, когда задание не удалено/отменено/завершено. Таким образом, мы можем избежать значительных вызовов API.
Вычислить слой
В конце концов, именно здесь работает ваша работа с большими данными. Для борьбы с вычислительным слоем он должен определить несколько вещей - например, количество вычислительного управления, он может обрабатывать, пользовательская информация (если возможно) и настройка аутентификации (которая должна быть завершена перед встроенной). Если таковые имеются, также должны быть настройки Gamma/Beta/Prod. Кроме того, должен быть способ узнать, сколько ресурсов работает (и если этого не существует, мы можем создать модуль для сбора этой информации).
Если у нас есть вся эта поддержка, мы можем легко управлять нашим вычислением. Примеры вычислительных слоев в AWS включают EMR (Elastic MapReduce), SWF (простой сервис рабочего процесса) и задания SageMaker.
Сервис планировщика
Основным компонентом нашего решения является эта служба. Для хранения всех соответствующих деталей для хранения всех соответствующих деталей для хранения всех соответствующих деталей, а также способ запустить асинхронные задания (бонусные точки, если мы можем сделать его подготовленным во время борьбы с пользователем), поскольку каждый пользователь хочет опросить с разными промежутками. Мы можем использовать AWS Eventbridge для этого и зарегистрировать наши задания там.
Нам нужны четыре различных типа заданий: один для получения доступных ресурсов, другой для проверки статуса работы, другой для отмены звонков, а другой для обновления статуса работы на основе обратных вызовов. Каденция этих заданий спорна и должна быть скорректирована в соответствии с потребностями пользователей. В этом дизайне есть условия гонки - принесите комментарий, если вы хотите узнать о них больше или если вы нашли его.
Обработчик задач управляет логикой и может быть реализован с использованием задания без сервера, чтобы сделать все просто. Сервисный разъем действует больше как адаптер, связывая различные услуги с нашей службой планировщика. Вот почему хороший интерфейс всегда важен для проблем такого рода.
Заключение
Мы прошли несколько масштабируемого дизайна, которая рассматривает большинство случаев использования планирования, предоставляя услуги с точки зрения высокого уровня. Это должно помочь вам начать, если вы хотите решить эту проблему. Решение также поддерживает обработку рабочих мест ML в масштабе и, как было доказано, работает в крупной команде в компании FAANG.
Оставьте комментарий, если что -то подобное уже существует, что может интегрироваться с различными облачными поставщиками. Если интереса будет достаточно, я поделюсь более подробной информацией о создании этой услуги вместе с кодом.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)