
Практическое руководство из 5 шагов для выполнения семантического поиска в ваших личных данных с помощью LLM
5 мая 2023 г.Если у вас есть много частных корпоративных данных, как вы можете использовать систему искусственного интеллекта, подобную ChatGPT, чтобы ускорить поиск нужной информации? Или, если у вас есть много личной информации, как вы можете найти старые воспоминания без точных ключевых слов?
В этом практическом руководстве я покажу вам 5 простых шагов для реализации семантического поиска с помощью LangChain, векторных баз данных и больших языковых моделей. Лучше всего то, что я буду использовать все компоненты с открытым исходным кодом, которые можно запускать локально на вашем компьютере.
Нет необходимости в каких-либо облачных ключах SaaS или API, и ваши данные никогда не покинут ваш офис или дом.
Анализ вариантов использования
В нашем сообществе есть форум на основе Discourse, работает более 5 лет. Существует огромное количество информации, но иногда новичкам сложно быстро и лаконично найти правильные ответы на свои вопросы.
Есть несколько причин, которые очень распространены для поисковых решений Google/pagerank:
- Поиск основан на ключевых словах, и часто пользователи не знают правильных терминов или точных формулировок.
2. Даже если пользователь вычислил лучшие условия поиска для своего конкретного вопроса, возвращаемым результатом будет список самых популярных тем обсуждения. И ответ на вопрос может быть не в первых нескольких сообщениях или может быть скрыт глубоко в затянувшейся ветке обсуждения.
3. Как правило, поисковые системы не очень хорошо понимают длинные предложения, если вы задаете многословный вопрос или два вопроса в одном предложении.
Вы можете задать другой вопрос: «ChatGPT v4 уже настолько хорош, почему бы вам не задавать вопросы напрямую из chatGPT?» Опять же, есть несколько веских причин:
* Модель ChatGPT (v3.5 или v4) была обучена на данных до ноября 2021 г., поэтому с тех пор у нее нет последней информации.
* Последний подключаемый модуль OpenAI для поиска на веб-сайте может выполнять поиск последней информации по веб-сайту, но он по-прежнему работает довольно медленно и часто зависает.
* Это неэффективно и нерентабельно для внутреннего использования вашего предприятия.
* Вы не хотите, чтобы OpenAI и Microsoft получали доступ к вашим корпоративным данным или вашим личным данным.
Итак, моя цель состоит в том, чтобы, если кто-то придет и спросит: «Как проще всего запустить узел NKN?», он сможет получить прямой ответ в нескольких предложениях.
Я использую этот общедоступный форум NKN только в качестве примера, чтобы показать вам типичный набор данных и типичные вопросы и ответы для специальной корпоративной базы знаний.
Подход к дизайну
После некоторых исследований и экспериментов я сузил свой план до пяти шагов:
- Проведите быструю проверку концепции с помощью облачного сервиса и API.
2. Очистите и подготовьте мои данные
3. Преобразовать весь мой набор данных в векторную базу данных
4. Используйте векторную базу данных, чтобы найти наилучшие совпадения с моим запросом
5. Используйте LLM, чтобы выделить лучший ответ на исходный вопрос
Если вы хотите сделать здесь паузу и узнать некоторые основы LangChain, векторных баз данных, больших языковых моделей и того, как они работают вместе, я рекомендую это видео и это видео. А ниже приведено краткое введение в эти концепции.
Ключевые компоненты
Langchain. LangChain — это платформа для разработки приложений на основе языковых моделей. Это связующее или промежуточное ПО, которое связывает все различные компоненты вместе для полуавтономного выполнения сложных задач.
Самые мощные и дифференцированные приложения будут не только обращаться к языковой модели через API, но и:
* Будьте осведомлены о данных: связывайте языковую модель с другими источниками данных.
* Будьте активны: позвольте языковой модели взаимодействовать с окружающей средой.
Векторная база данных. База данных векторов — это специализированная система хранения и поиска, предназначенная для эффективной обработки многомерных векторных данных и часто используемая в приложениях для машинного обучения, искусственного интеллекта и анализа данных.
Эти базы данных позволяют пользователям выполнять поиск сходства или ближайших соседей, что позволяет им находить наиболее похожие элементы в базе данных на основе их векторных представлений. Сосновая шишка — одна из ведущих коммерческих баз данных векторов.
Существуют альтернативы с открытым исходным кодом, такие как FAISS, Chroma и Supabase.
Большая языковая модель. Большая языковая модель, такая как GPT (Generative Pre-trained Transformer), представляет собой усовершенствованную модель искусственного интеллекта, которая использует методы глубокого обучения для обработки и создания текста, похожего на человеческий.
Имея миллиарды параметров, GPT-3/4 обучается на огромных объемах данных из разных источников, что позволяет ему понимать контекст, семантику и синтаксис.
В результате GPT-3/4 может выполнять различные задачи обработки естественного языка, такие как генерация текста, перевод, обобщение и ответы на вопросы, с поразительной точностью и беглостью.
Существует несколько управляемых сообществом моделей LLM, основанных на LLaMA от Meta, например, Alpaca, Vicuna, Koala и GPT4All, которые можно запускать локально на ноутбуке (см. мое руководство здесь).
Шаг 1. Проверка концепции
Прежде чем вы потратите больше усилий на собственное решение, давайте сначала познакомимся с ключевой платформой LangChain и компонентами игровой площадки. Благодаря графическому пользовательскому интерфейсу flowise.ai теперь вы можете работать со всем этим решением без какого-либо кода.
Этот шаг не является обязательным, и вы можете перейти к шагу 2, если хотите сразу перейти к локальному программированию или если у вас нет ключей API для OpenAI или Pinecone.
Предпосылки:
- Вы заранее получаете ключ API OpenAI и ключ API Pinecone. Оба они полезны не только для этого упражнения, но и для других экспериментов, связанных с ИИ.
2. В Pinecone вам нужно создать новый индекс под названием «test» с размером 1536. Обратите внимание, что имя среды, автоматически сгенерированное Pinecone для обозначения места запуска этого экземпляра индекса: «us-west1-gcp-free.». Вы можете использовать метрику по умолчанию «Косинус. ”
3. Небольшой набор данных в формате текстового файла (скажем, test.txt): это может быть так же просто, как скопировать и вставить несколько абзацев из документа Word или PDF. Кроме того, из соображений конфиденциальности вы хотите использовать очень небольшой набор данных и желательно общедоступную информацию. Поскольку оба API являются облачными.
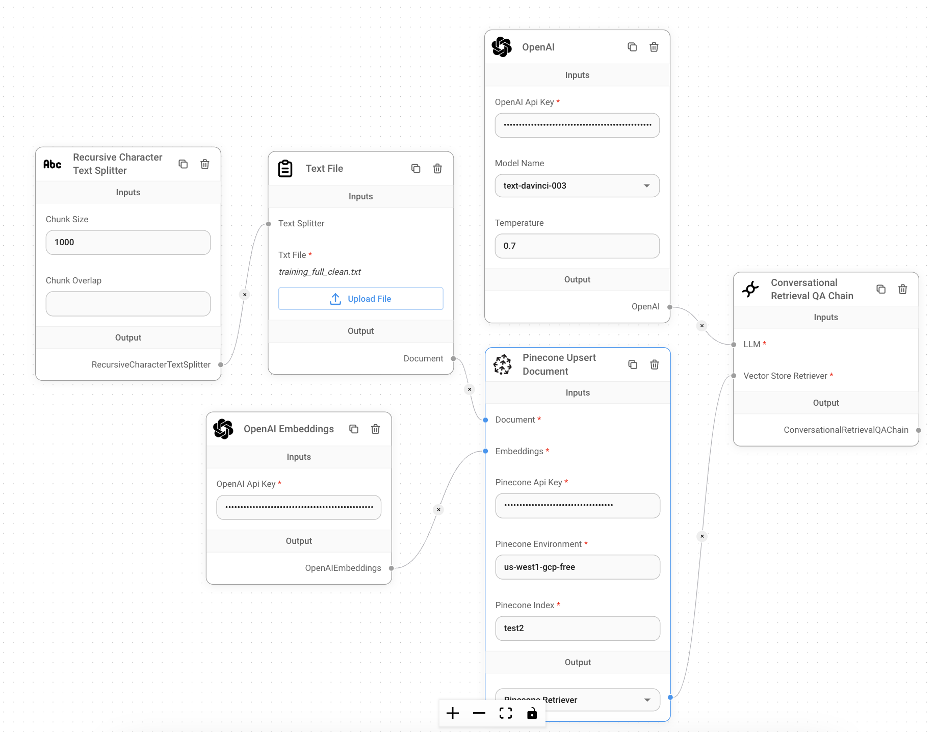
Сейчас. перейдите на Flowise AI, загрузите код с их Github, а также установить и запустить локально (у вас должен быть установлен Node Javascript). Вы можете получить к нему доступ из браузера: http://localhost:3000/marketplaces.
А в Marketplace вы можете выбрать шаблон под названием «Диалоговая цепочка поиска QA» и использовать этот шаблон. Пользовательский интерфейс говорит сам за себя: вы дважды вводите ключ API OpenAI (один для встраивания и один для LLM), ключ API Pinecone, имя индекса, среду и показатели.
И загрузите текстовый файл набора данных. Это может занять пару минут в зависимости от размера вашего текстового фильма. Затем вы нажимаете на маленькое облачко чата в правом верхнем углу и можете начинать задавать любые вопросы!
Так что это даст вам визуальное представление о конвейере обработки данных в сценарии использования нашего форума и поможет вам реализовать собственное решение, заменив все облачные API локальным сервисом с использованием программного обеспечения с открытым исходным кодом.
LangChain останется на месте, так как это программное обеспечение с открытым исходным кодом, которое нам нужно.
* Большая языковая модель: OpenAI -> LLaMA/Альпака
* База данных векторов: Сосновая шишка -> ФАИСС
Но прежде чем мы это сделаем, нам сначала нужно очистить и подготовить корпоративные данные для загрузки в векторную базу данных.
Шаг 2. Очистка и подготовка данных
Форум NKN использует программное обеспечение Discourse, популярное решение с открытым исходным кодом для обсуждения и форума сообщества. В качестве основного хранилища данных он использует базу данных Postgres SQL, в которой есть две таблицы, особенно актуальные для наших постов с вопросами и ответами на темы, посвященные примерам использования.
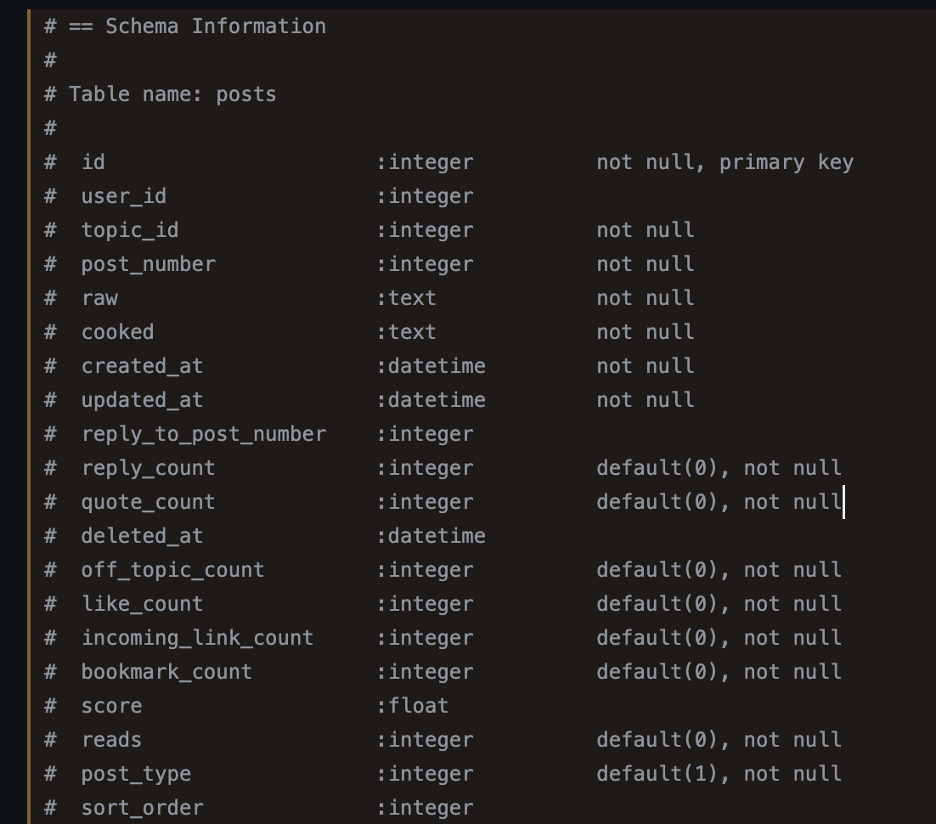
Например, схема базы данных «posts» частично приведена ниже. Наиболее релевантными для нас столбцами являются: «topic_id» (соответствует таблице тем), «необработанный» (исходный контент публикации в тексте без форматирования) и «< strong>оценка» (насколько этот пост популярен или читаем).
Вполне естественно сопоставлять «темы» с вопросами (или «подсказками»), а «posts::raw» — с ответами (« завершение"). Термины в скобках относятся к GPT-подобным LLM. Здесь есть много соображений по реализации и оптимизации, которых хватит для отдельной статьи.
Но я хотел бы не усложнять и выбрать только лучший пост из всей ветки, соответствующий исходной теме.
Итак, прежде всего, нам нужно получить обе таблицы из базы данных и в файлы JSON. Для этого я сделал дамп БД в Discourse, а затем импортировал его в автономную базу данных SQL Postgres, работающую на моем Macbook Pro M1.
Из автономного Postgres SQL я могу экспортировать файлы JSON для двух таблиц: posts и topics.
Затем я написал простой скрипт на Python, чтобы сделать следующее:
* Для каждой темы используйте SQL, чтобы выбрать сообщения с наивысшим «баллом».
* Результирующие «тема» и «post::raw» становятся одной парой «подсказка» и «завершение».
* Сохраните приведенное выше в файл JSON с именем training.json (вы можете использовать его для многих других целей обучения, например, для точной настройки модели LLM, использования API тонкой настройки GPT-3 и т. д.)
* Запишите в текстовый файл с именем training.txt: одну строку для подсказки и одну строку для завершения, и разделите каждую пару двумя новыми строками.
Теперь ваш файл должен выглядеть примерно так:
Шаг 3. Преобразование всего моего набора данных в векторную базу данных
Я вставил приведенный ниже скрипт Python, который в основном говорит сам за себя. Несколько замечаний:
- Вам необходимо загрузить или найти веса для вашей локальной модели LLM. В моем случае я использовал параметр Alpaca 7B с 4-битной квантованной версией. Вы можете найти их на Huggingface. Есть много подобных, которые точно настроены на основе моделей Meta LLaMA 7B/13B, например, Alpaca, Vicuna, Koala, GPT4All. Вы можете использовать любой из них.
2. При желании вы следовали моим инструкциям< /a> и установил Llama.cpp локально и успешно запустил Llama.cpp с указанными выше весами. Итак, вы знаете, что веса хороши.
3. Разделитель текста разделит ваш длинный текстовый файл на фрагменты, каждый из которых имеет максимальную длину 1000.
4. Затем этот фрагмент текста передается в LLM для встраивания, который в основном размечает слова и преобразует их в векторы на основе их значения. Каждый фрагмент после токенизации может стать до 1400 токенов. Так как в среднем 3 слова создают около 4 токенов. По этой же причине у меня n_ctx = 2048 (по умолчанию 512), чтобы иметь достаточно большое контекстное окно для встраивания.
5. Наконец, векторы вставляются в векторную базу данных FAISS и индексируются. База данных сохраняется как локальный файл в каталоге с именем «faiss_index».
from langchain.embeddings import LlamaCppEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
embeddings = LlamaCppEmbeddings(model_path="./ggml-alpaca-7b-q4.bin", n_ctx= 2048)
from langchain.document_loaders import TextLoader
loader = TextLoader('./training_full_clean.txt')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 50,
length_function = len)
docs = text_splitter.split_documents(documents)
db = FAISS.from_documents(docs, embeddings)
db.save_local("faiss_index")
# Now let's test it out
query = "Who is Whitfield Diffie?"
docs = db.similarity_search(query)
for doc in docs:
print(doc.page_content)
Я настоятельно рекомендую вам начать с очень маленького текстового файла набора данных для тестирования. Если ваш набор данных большой, это займет много времени. Мой локально запущенный файл Llama.cpp может внедрять около 20 токенов в секунду, поэтому внедрение каждой части из 1000 текстовых слов может занять около 1 минуты.
В моей векторной БД около 7500 записей, и на Macbook Pro M1 у меня уйдет около 100 часов. Хорошей новостью является то, что вам нужно сделать это только один раз. [Примечание автора: пожалуйста, смотрите комментарии, чтобы использовать другой модуль встраивания, такой как Huggingface, для гораздо более быстрой работы с большими наборами данных]
Шаг 4. Использование векторной базы данных для поиска наилучших совпадений с моим запросом
И снова я предоставляю простой код Python для выполнения запроса и суммирования. Поскольку мы используем цепочку шаблонов под названием «RetrievalQA», некоторые детали могут быть не очевидны. Но под капотом это включало следующие шаги:
* Когда пользователь вводит запрос, большая языковая модель преобразует текст во встраивание и вектор (по сути, массив чисел с плавающей запятой), представляющий запрос.
* Затем база данных векторов выполняет поиск по сходству, чтобы найти векторы результатов-кандидатов, которые наиболее близки к вектору запроса.
* Теперь мы возвращаем те векторы результатов-кандидатов, которые уже закодированы так, как понимает LLM, в LLM для окончательной обработки.
from langchain.vectorstores import FAISS
from langchain.llms import LlamaCpp
from langchain.embeddings import LlamaCppEmbeddings
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.chains import RetrievalQA
# Load DB from local file
embeddings = LlamaCppEmbeddings(model_path="./ggml-alpaca-7b-q4.bin")
new_db = FAISS.load_local("faiss_index", embeddings)
# Use llama-cpp as the LLM for langchain
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
llm = LlamaCpp(
model_path="./ggml-alpaca-7b-q4.bin",
n_ctx= 2048,
callback_manager=callback_manager,
verbose=True,
use_mlock=True
)
retriever = new_db.as_retriever()
# Conversational QA retrieval chain
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
break
response = qa.run(user_input)
print(f"AI: {response}")
Шаг 5. Используйте LLM, чтобы выделить лучший ответ на исходный вопрос
На последнем этапе и снова внутри шаблон «RetrieverQA» автоматически создает специальную подсказку, которая включает следующее:
* Системное сообщение: проинструктируйте LLM, какую задачу ему нужно выполнить, и в этом случае: «Используйте следующие фрагменты контекста, чтобы ответить на вопрос в конце. Если вы не знаете ответа, просто скажите, что не знаете, не пытайтесь придумать ответ.”
* Сообщение пользователя: добавьте в качестве контекста лучшие векторы результатов-кандидатов, а также вектор запроса в конце.
Как только LLM получит такое приглашение, он сделает все возможное, чтобы просеять результаты кандидатов и найти лучший ответ на исходный вопрос. Он суммирует, перефразирует и даже находит отдельные ответы на два отдельных вопроса в исходном запросе (например, «Кто такой Стивен Вольфрам и как он связан с NKN?»).
Иногда мы можем быть весьма удивлены тем, насколько способными LLM стали справляться с такого рода задачами вопросов и ответов.
Что дальше?

Поздравляем, вы только что успешно создали свой первый инструмент семантического поиска по своим личным данным, используя набор инструментов с полностью открытым исходным кодом! Теперь вы уже на пути в конференц-зал своего офиса, чтобы продемонстрировать свою новую демонстрацию. ! И что вы можете сделать дальше?
* Попробуйте альтернативные компоненты для векторных баз данных или больших языковых моделей, которые лучше всего соответствуют вашим потребностям в данных.
* Оптимизируйте, масштабируйте и внедрите решение семантического поиска для всей компании.
* Копните глубже в LangChain и его бесконечные возможности для решения других неотложных рабочих или жизненных проблем. Возможно, вы даже можете добавить свою собственную цепочку в качестве шаблона для других людей.
Удачного взлома! 🙂
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27385)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)