
Мультимодальный набор данных для синтеза рэп -вокала и трехмерного движения
8 августа 2025 г.Таблица ссылок
Аннотация и 1. Введение
Связанная работа
2.1 Текст на вокальное поколение
2.2 Текст на генерацию движения
2.3 Аудио до генерации движения
Раскоростный набор данных
3.1 Рэп-вокальное подмножество
3.2 Подмножество рэп-движения
Метод
4.1 Составление проблемы
4.2 Motion VQ-VAE Tokenizer
4.3 Vocal2Unit Audio Tokenizer
4.4 Общее авторегрессивное моделирование
Эксперименты
5.1 Экспериментальная установка
5.2 Анализ основных результатов и 5.3 исследование абляции
Заключение и ссылки
А. Приложение
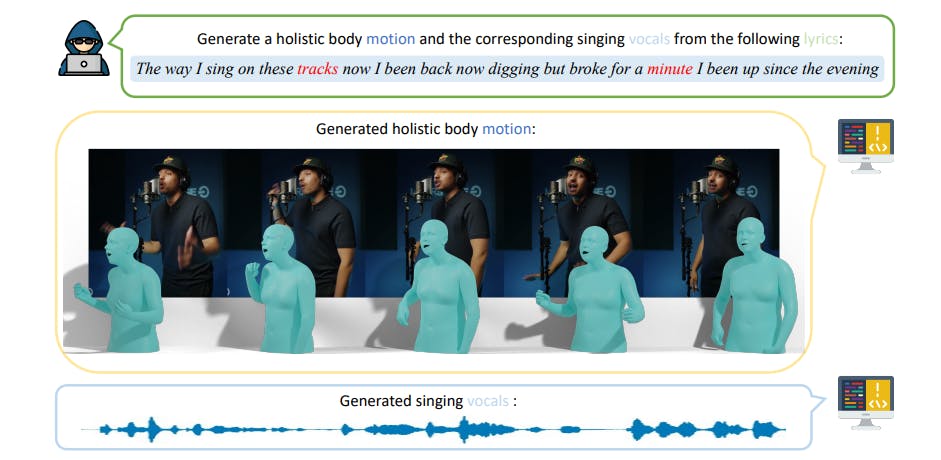
В этом разделе мы вводим Rapverse, большой набор данных о движении рэп-музыки, содержащий синхронизированный поющий вокал, текстовые тексты и человеческие движения всего тела. Сравнение нашего набора данных с существующими наборами данных показан в таблице. 1. Рэкверс-набор данных разделен на два подмножества, чтобы удовлетворить широкий спектр потребностей в исследованиях: подмножество рэп-вокала и подмножество перемещения рэпа. Общий конвейер сбора Rapverse показан на рис. 2.
3.1 Рэп-вокальное подмножество
Рэп-вокальное подмножество содержит 108,44 часа высококачественного английского поющего голоса в жанре рэпа с парными текстами. Мы введем каждый шаг в деталях.
Полнование данных.Стремясь получить большое количество рэп -песен и соответствующих текстов из Интернета, мы используем SpotDL и Spotipy для сбора песен, текстов и метаданных различных рэп -певцов. Чтобы обеспечить качество набора данных, мы выполняем чистку на ползанных песнях, удаляя песни с неправильно вычисленной текстами и фильтрации песен, которые слишком длинные или слишком короткие.
Вокальное и фоновое разделение музыки.Поскольку песни ползания смешаны с рэп-вокалом и фоновой музыкой, и мы стремимся синтезировать пение вокала из отдельных чистых данных, мы используем селетер [18], современный инструмент разделения источника вокала с открытым исходным кодом для раздела и извлечения рэп-голоса и сопровождающего фоновую музыку из собранных песен. После [53] мы нормализуем громкость вокальных голосов до фиксированного уровня громкости.
Обработка голосовых данных.Сырые лирики ползания из Интернета находятся в непоследовательных форматах, мы проводим очистку данных по текстам, удаляя мета -информацию (певец, композитор, имя песни, соединительные слова и специальные символы). Чтобы гарантировать, что тексты выровнены с поющим вокалом, мы собираем тексты лирики только с правильными временными метками каждого предложения, и мы разделяем каждую песню на 10 секунд до 20 секунд для обучения модели.
3.2 Подмножество рэп-движения
Подмножество RAP-Motion содержит 26,8 часа видеопровода RAP с 3D-целостными сетчатыми сетчатыми аннотациями в параметрах SMPL-X [42], синхронным поющим вокалом и соответствующими текстами. Мы представляем конвейер сбора этого подмножества следующим образом.
Полнование данных.Мы заполнили более 1000 студийных видеопроизводительных видео с YouTube по общей креативной лицензии. Мы отфильтровываем низкокачественные видео вручную, чтобы обеспечить, чтобы видео соответствовали следующим критериям: стабильная работа камеры, исполнители, ориентированные на кадр, четкую видимость всего тела исполнителя для сбора подробных данных движения и высококачественного звука для точного вокального анализа.
Обработка аудиоданных.Подобно подмножеству рэп-вокала, мы используем Sleeter [19] для изоляции поющего вокала от сопровождающей музыки. Учитывая, что в видео на YouTube обычно не хватает парных текстов, мы используем модель ASR, Whisper [47], чтобы точно транскрибировать вокал в соответствующий текст.
Обработка видеоданных.Чтобы обеспечить сбор высококачественных видеоклипов для аннотации движения, мы внедрили полуавтоматический процесс для фильтрации нежелательного контента, такого как реклама, переходные рамы, изменения в снимках и мигающие огни. Первоначально мы применили Йоло [50] для обнаружения человека, чтобы отказаться от кадров, где не было обнаружено людей. Впоследствии мы использовали RAFT [60] для оценки величины движения, используя порог для устранения кадров, затронутых нестабильностью камеры. Затем мы выполняем тщательное ручное курирование на извлеченных клипах, сохраняя только таковые высочайшего качества. Наконец, мы следим за конвейером оптимизированного метода Motion-X [30], чтобы извлечь трехмерные сетки всего тела из монокулярных видео. В частности, мы принимаем SMPL-X [42] для представлений движения с учетом видеоклипа T-Frame, соответствующие состояния позы M представлены как:
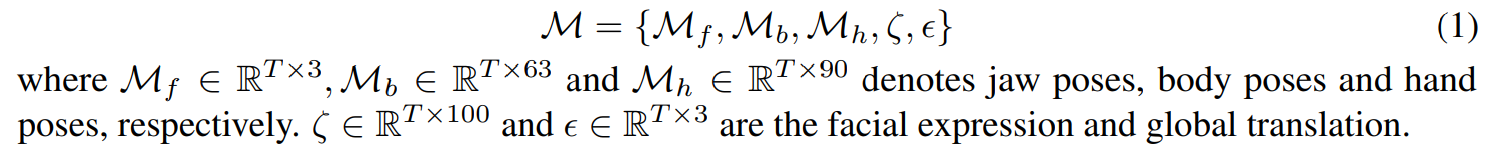
Авторы:
(1) Цзябен Чен, Университет штата Массачусетс Амхерст;
(2) Синь Ян, Университет Ухана;
(3) Ихан Чен, Университет Ухан;
(4) Сиюань Сен, Университет штата Массачусетс Амхерст;
(5) Qinwei MA, Университет Цинхуа;
(6) Хаою Чжэнь, Университет Шанхай Цзяо Тонг;
(7) Каижи Цянь, MIT-IBM Watson AI Lab;
(8) ложь Лу, Dolby Laboratories;
(9) Чуан Ган, Университет штата Массачусетс Амхерст.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)