

Руководство по использованию Apache Cassandra в качестве хранилища функций в реальном времени
31 марта 2023 г.Это практическое руководство по использованию Apache Cassandra в качестве хранилища функций в реальном времени. Мы изучаем ИИ в реальном времени и уникальные характеристики производительности и стоимости Cassandra, которые делают ее отличной базой данных для хранилища функций, а затем углубимся в основы хранилищ функций и их роль в приложениях реального времени. Cassandra используется в качестве хранилища функций крупными компаниями, включая Uber и Нетфликс; в реальных условиях он может использоваться для логического вывода в реальном времени с помощью tp99 < 23 мс.
Руководство разделено на несколько ключевых разделов. Мы начнем с представления Cassandra и ее функций, которые делают ее идеальным выбором для магазина функций. Затем мы объясним основы хранилищ функций, в том числе, что они из себя представляют и как их можно использовать в приложениях реального времени. После этого мы изучим детали реализации создания хранилища функций с помощью Cassandra. Сюда входит моделирование данных, получение и извлечение функций, а также обработка обновлений данных. Наконец, мы предлагаем рекомендации и советы по использованию Cassandra в качестве хранилища функций для обеспечения оптимальной производительности и масштабируемости — от требований к задержке до расчетных требований к показателям производительности до эталонных архитектур и совместимости с экосистемами.
n В этом руководстве не рассматриваются научные аспекты машинного обучения в реальном времени или аспекты управления жизненным циклом функций в магазине функций< /а>. Лучшие практики, которые мы рассмотрим, основаны на технических беседах со специалистами-практиками из крупных технологических компаний, таких как Google, Facebook, Uber, AirBnB и Netflix о том, как они предоставляют своим клиентам возможности ИИ в реальном времени в своих облачных инфраструктурах. Хотя мы специально сосредоточимся на том, как реализовать хранилище функций в реальном времени с помощью Cassandra, рекомендации по архитектуре действительно применимы к любой технологии баз данных, включая Redis, MongoDB и Postgres.
Что такое ИИ в реальном времени?
Искусственный интеллект в реальном времени делает выводы или модели обучения на основе недавних событий. Традиционно модели обучения и выводы (прогнозы) на основе моделей выполнялись в пакетном режиме — обычно в течение ночи или периодически в течение дня. Сегодня современные системы машинного обучения делают выводы из самых последних данных, чтобы обеспечить максимально точный прогноз. Небольшая группа компаний, таких как TikTok и Google, продвинула парадигму реального времени дальше, включив обучение моделей на лету по мере поступления новых данных.
Из-за этих изменений в выводе и изменений, которые, вероятно, произойдут в обучении модели, необходимо адаптировать и постоянство данных признаков — данных, которые используются для обучения и выполнения выводов для модели ML. Когда вы закончите читать это руководство, у вас будет более четкое представление о том, как Cassandra и DataStax Astra DB, управляемая служба, построенная на Cassandra, удовлетворяют потребности ИИ в реальном времени и как их можно использовать в сочетании с другими технологиями баз данных. для вывода модели и обучения.
Что такое магазин функций?
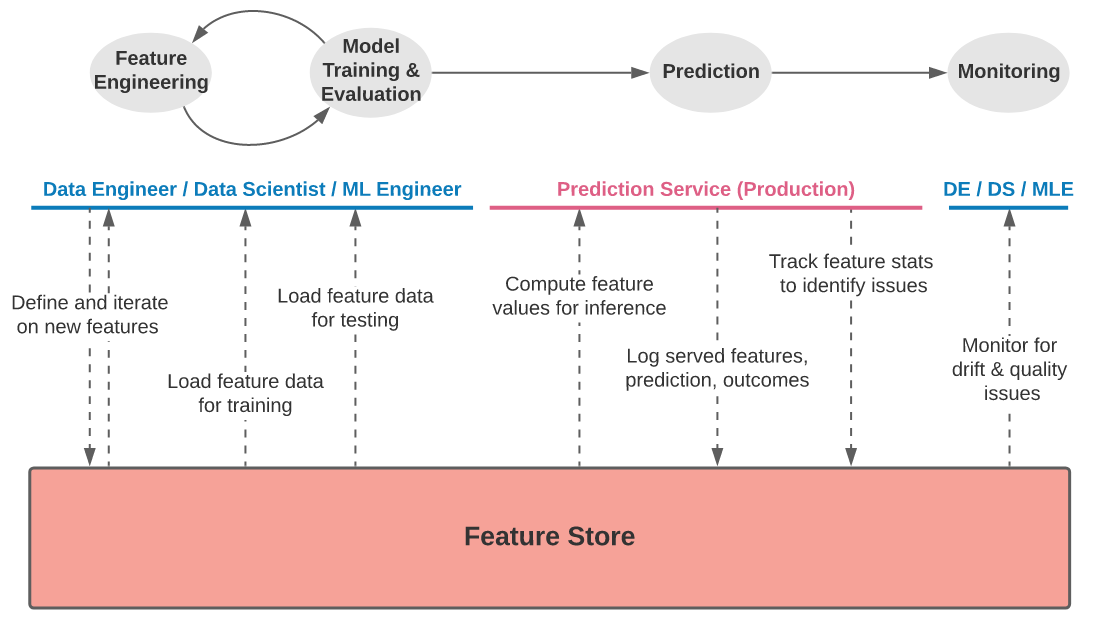
Хранилище функций – это система данных, предназначенная для машинного обучения (ML), которая:
- Запускает конвейеры данных, которые преобразуют необработанные данные в значения характеристик.
- Хранит сами данные объекта и управляет ими, а также
- Последовательно предоставляет данные о функциях для обучения и получения выводов.
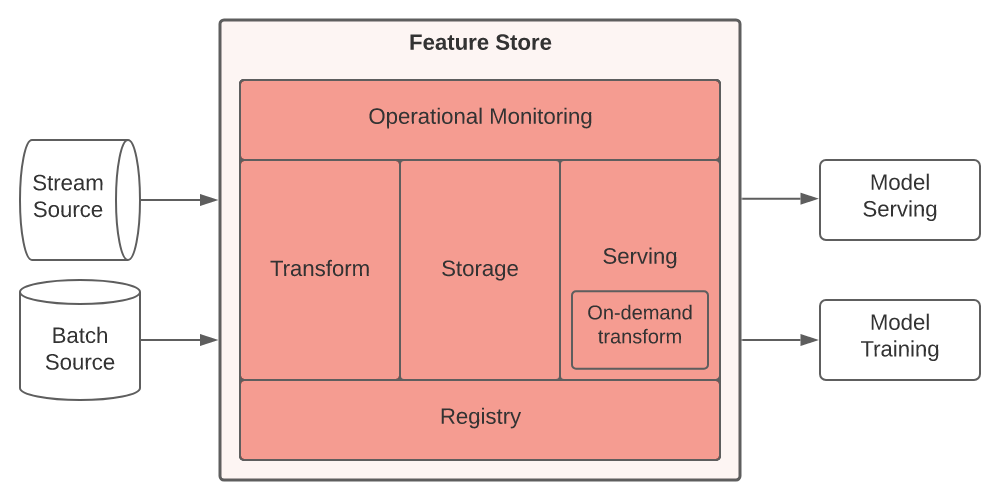
ИИ в реальном времени предъявляет особые требования к хранилищу функций, для выполнения которых Cassandra обладает уникальными возможностями, в частности, когда речь идет о хранении и обслуживании функций для обслуживания моделей и обучения моделей. .
Рекомендации
**Внедрение запросов с малой задержкой для обслуживания функций
Для логического вывода в реальном времени функции должны возвращаться в приложения с малой задержкой в масштабе. Типичные модели включают около 200 функций, распределенных по примерно 10 объектам. Для выводов в реальном времени требуется время, которое необходимо заложить в бюджет для сбора функций, облегченных преобразований данных и выполнения логических выводов. Согласно последующему опросу (также подтвержденному нашими беседами с практиками), хранилища функций должны возвращать функции в приложение. выполнение логического вывода менее чем за 50 мс.
Как правило, модели требуют «внутренних соединений» между несколькими логическими объектами — объединения значений строк из нескольких таблиц, которые имеют общее значение; это представляет серьезную проблему для обслуживания функций с малой задержкой. Возьмите случай с Uber Eats, который предсказывает время доставки еды. Данные должны быть объединены из информации о заказе, которая объединяется с информацией о ресторане, к которой далее добавляется информация о трафике в районе ресторана. В этом случае необходимы два внутренних соединения (см. рисунок ниже).
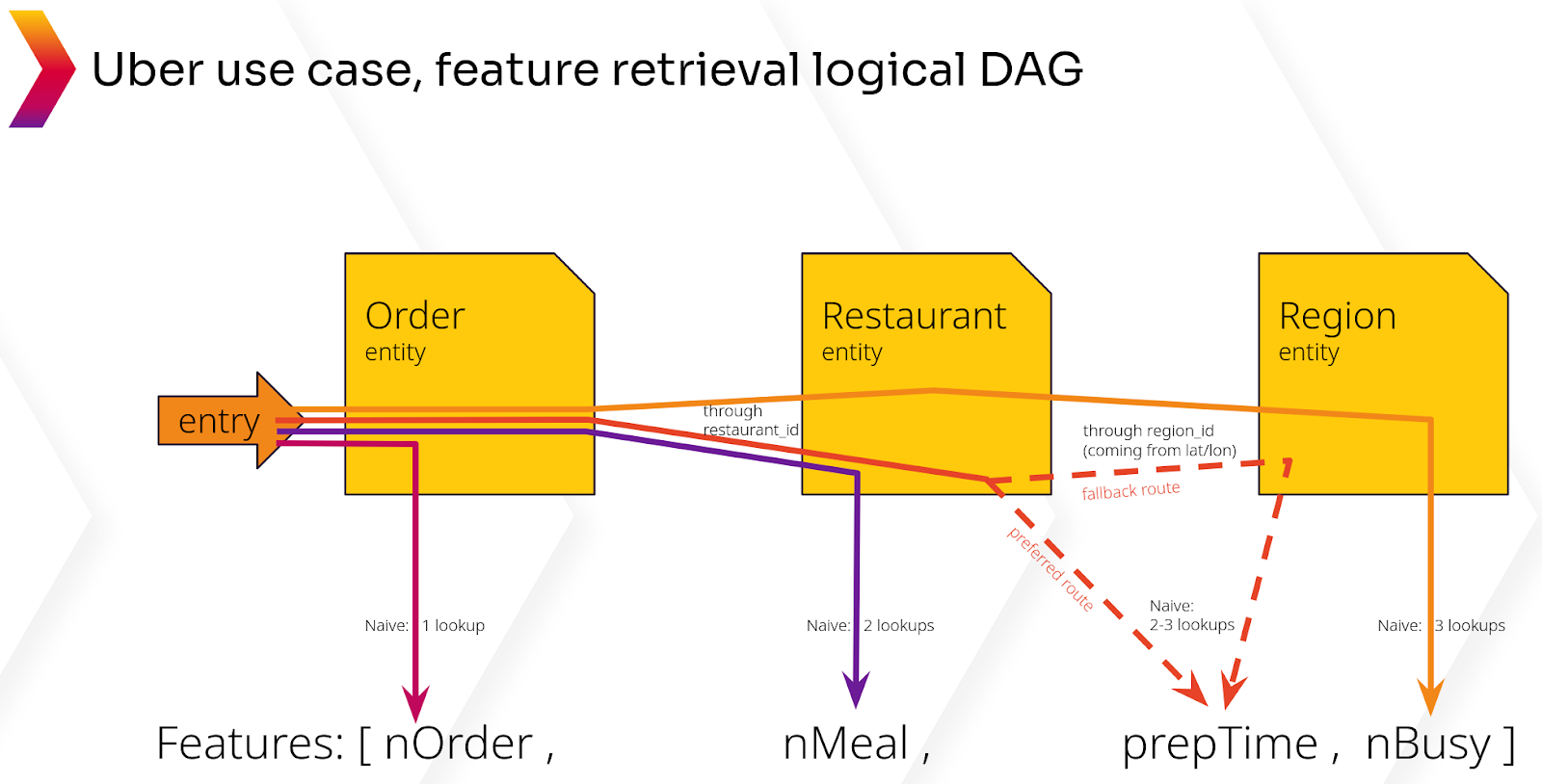 п
п
Чтобы получить внутреннее соединение в Cassandra, можно либо денормализовать данные при вставке, либо сделать два последовательных запроса к Cassandra + выполнить соединение на стороне клиента. Хотя можно выполнять все внутренние соединения при вставке данных в базу данных посредством денормализации, иметь соотношение 1:1 между моделью и таблицей нецелесообразно, поскольку это означает поддержку чрезмерного количества денормализованных таблиц. Передовой опыт предполагает, что хранилище функций должно разрешать 1–2 последовательных запроса для внутренних соединений в сочетании с денормализацией.
Вот сводка показателей производительности, которые можно использовать для оценки требований к конвейерам машинного обучения в реальном времени:
Условия тестирования:
- функций = 200
- количество таблиц (сущностей) = 3
- количество внутренних соединений = 2
- Запрос TPS: 5000 запросов в секунду
- Запись TPS: 500 записей в секунду.
- Размер кластера: 3 узла на AstraDB*
Сводная информация о задержке (неопределенности здесь являются стандартными отклонениями):
- tp95 = 13,2(+/-0,6) мс
- tp99 = 23,0(+/-3,5) мс
- tp99,9 = 63(+/- 5) мс
Эффект уплотнения:
- tp95 = незначительный
- tp99, tp999 = пренебрежимо мало, учитывается сигмами, указанными выше
Эффект от сбора измененных данных (CDC):
- tp50, tp95 ~ 3-5 мс
- tp99 ~ 3 мс
- tp999 ~ пренебрежимо мало
*Следующие тесты были проведены на бесплатном уровне Astra DB от DataStax, который представляет собой бессерверную среду для Кассандра. Пользователи должны ожидать аналогичных показателей задержки при развертывании на трех нотах с использованием следующих рекомендованных настроек. .
Наиболее значительное влияние на задержку оказывает количество внутренних соединений. Если запрашивается только одна таблица вместо трех, tp99 падает на 58%; для двух столов на 29% меньше. tp95 падает на 56% и 21% соответственно. Поскольку Cassandra масштабируется по горизонтали, запрос дополнительных функций также не приводит к значительному увеличению средней задержки.
Наконец, если требования к задержке не могут быть выполнены из коробки, у Cassandra есть две дополнительные функции: возможность поддерживать денормализованные данные (и, таким образом, уменьшать количество внутренних соединений) благодаря высокой пропускной способности записи и возможность выборочной репликации данных для ввода. кэши памяти (например, Redis) с помощью системы отслеживания измененных данных. Дополнительные советы по уменьшению задержки можно найти здесь.
Реализовать отказоустойчивую запись с малой задержкой для преобразования функций
Ключевым компонентом искусственного интеллекта в реальном времени является возможность использовать самые последние данные для вывода модели, поэтому важно, чтобы новые данные были доступны для вывода как можно скорее. В то же время для корпоративных сценариев важно, чтобы запись была надежной, поскольку потеря данных может привести к серьезным производственным проблемам.
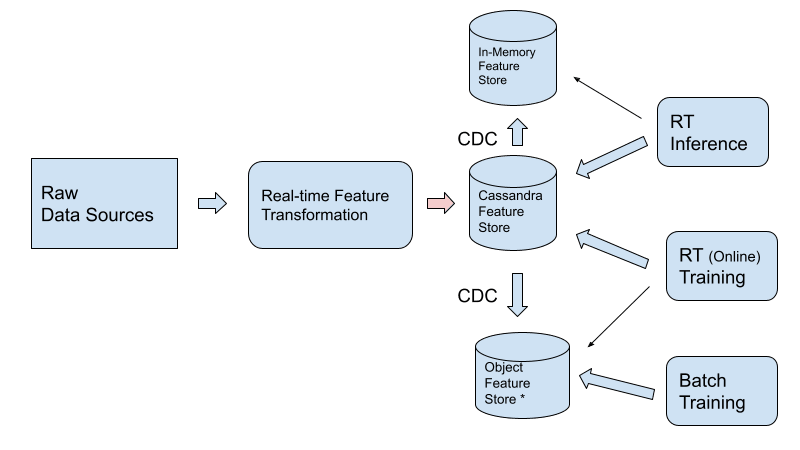
*Хранилища объектов (например, S3 или HIVE) можно заменить другими типами пакетно-ориентированных систем, например хранилищами данных.
Существует компромисс между надежной записью с малой задержкой и обслуживанием функций с малой задержкой. Например, данные можно хранить только в ненадежном месте (например, Redis), но сбои в работе могут затруднить восстановление самых современных функций, поскольку для этого потребуется большой пересчет необработанных событий. .
Общая архитектура предполагает запись функций в офлайн-магазин (например, Hive/S3) и репликацию функций в интернет-магазин (например, кэш в памяти). Несмотря на то, что это обеспечивает устойчивость и низкую задержку для обслуживания функций, это достигается за счет введения задержки для записи функций, что неизменно приводит к снижению производительности прогнозирования.
Cassandra обеспечивает хороший компромисс между обслуживанием функций с малой задержкой и «долговременной» записью функций с малой задержкой. Данные, записанные в Cassandra, обычно реплицируются не менее трех раз, и поддерживается репликация в нескольких регионах. Задержка от записи до доступности для чтения обычно составляет доли миллисекунды. В результате, сохраняя функции непосредственно в онлайн-магазине (Cassandra) и минуя офлайн-магазин, приложение получает более быстрый доступ к последним данным, чтобы делать более точные прогнозы. В то же время CDC, как в интернет-магазине, так и в офлайн-магазине, позволяет проводить пакетное обучение или исследование данных с помощью существующих инструментов.
Реализовать низкую задержку и записи для кэширования прогнозов и мониторинга производительности
Помимо хранения преобразований функций, также необходимо хранить прогнозы и другие данные отслеживания для мониторинга производительности.
Есть несколько вариантов использования для хранения прогнозов:
- Хранилище прогнозов. В этом сценарии база данных используется для кэширования прогнозов, сделанных либо система пакетной обработки или система потоковой передачи. Потоковая архитектура особенно полезна, когда время, необходимое для логического вывода, превышает допустимое в системе "запрос-ответ".
- Мониторинг производительности прогнозирования Часто необходимо отслеживать выходные данные прогнозирования в режиме реального времени и сравнивать их с окончательными результатами. Это означает наличие базы данных для регистрации результатов прогноза и конечного результата.
Cassandra подходит для обоих вариантов использования благодаря высокой пропускной способности операций записи.
Планирование эластичных рабочих нагрузок чтения и записи
Уровень транзакций запроса и записи в секунду обычно зависит от количества пользователей, одновременно использующих систему. В результате рабочие нагрузки могут меняться в зависимости от времени суток или времени года. Важно иметь возможность быстро увеличивать и уменьшать масштаб кластера для поддержки возросших рабочих нагрузок. В Cassandra и Astra DB есть функции, обеспечивающие динамическое масштабирование кластера.
Второй аспект, который может повлиять на рабочие нагрузки записи, — это изменения в логике преобразования функций. При большом всплеске рабочих нагрузок записи Cassandra автоматически отдает приоритет поддержке запросов с малой задержкой и записи TPS, а не согласованности данных, что обычно приемлемо для выполнения логических выводов в реальном времени.
Реализовать поддержку нескольких регионов с малой задержкой
Поскольку ИИ в реальном времени становится повсеместным во всех приложениях, важно убедиться, что данные функций доступны как можно ближе к тому месту, где происходит вывод. Это означает, что хранилище объектов находится в том же регионе, что и приложение, выполняющее вывод. Репликация данных в хранилище функций по регионам помогает обеспечить эту функцию. Кроме того, репликация только функций, а не необработанных данных, используемых для создания функций, значительно снижает плату за выход из облака.
Astra DB по умолчанию поддерживает репликацию в нескольких регионах с задержкой репликации в миллисекундах. Мы рекомендуем передавать все необработанные данные о событиях в один регион, выполнять генерацию функций, а также хранить и реплицировать функции во все другие регионы.
Хотя теоретически можно добиться некоторого преимущества в отношении задержки путем создания признаков в каждом регионе, данные о событиях часто необходимо объединять с необработанными данными о событиях из других регионов. с точки зрения корректности и эффективности проще отправить все события в один регион для обработки для большинства вариантов использования. С другой стороны, если использование модели наиболее целесообразно в региональном контексте, и большинство событий связаны с объектами, специфичными для региона, то имеет смысл рассматривать объекты как специфичные для региона. Любые события, которые необходимо реплицировать между регионами, можно поместить в пространства ключей с глобальными стратегиями репликации, но в идеале это должно быть небольшое подмножество событий. В определенный момент глобальная репликация таблиц событий будет менее эффективной, чем простая отправка всех событий в один регион для вычисления признаков.
Запланируйте экономичную поддержку нескольких облаков с малой задержкой
Поддержка нескольких облаков повышает отказоустойчивость приложений и позволяет клиентам договариваться о более низких ценах. Однооблачные интернет-магазины, такие как DynamoDB, приводят как к увеличению задержки при получении функций, так и к значительным затратам на исходящие данные, но также создают привязку к одному поставщику облака.
Базы данных с открытым исходным кодом, поддерживающие репликацию между облаками, обеспечивают наилучшее соотношение цены и производительности. Чтобы свести к минимуму стоимость исходящего трафика, события и создание функций следует консолидировать в одном облаке, а данные функций следует реплицировать в базы данных с открытым исходным кодом в других облаках. Это сводит к минимуму затраты на исходящий трафик.
Планирование пакетного обучения и обучения производственных моделей в режиме реального времени
Инфраструктура пакетной обработки для построения моделей используется в двух случаях: построение и тестирование новых моделей и построение моделей для производства. Поэтому обычно было достаточно, чтобы данные признаков хранились в более медленных хранилищах объектов для целей обучения. Однако более новые парадигмы обучения моделей включают обновление моделей в режиме реального времени или почти в реальном времени (обучение в реальном времени); это известно как «онлайн-обучение» (например, Монолит TikTok). Шаблон доступа для обучения в реальном времени находится где-то между логическим выводом и традиционным пакетным обучением. Требования к пропускной способности данных выше, чем для логического вывода (поскольку обычно не требуется доступ к поиску по одной строке), но не настолько высоки, как для пакетной обработки, которая требует полного сканирования таблицы.
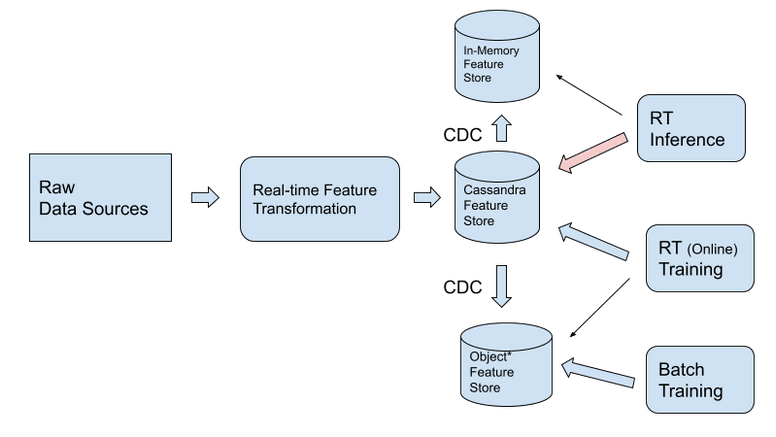
Cassandra может поддерживать рейтинг TPS в сотни тысяч в секунду (с соответствующей моделью данных), что может обеспечить достаточную пропускную способность для большинства случаев использования обучения в реальном времени. Однако в случае, если пользователь хочет продолжить обучение в режиме реального времени из хранилища объектов, Cassandra достигает этого через CDC в хранилище объектов. Для пакетного обучения CDC должен реплицировать данные в объектное хранилище. Стоит отметить, что платформы машинного обучения, такие как Tensorflow и PyTorch, особенно оптимизированы для параллельного обучения моделей машинного обучения из объектного хранилища
Более подробное объяснение «онлайн-обучения» см. в объяснении Чипа Хуюена на сайте технический документ от Gomes et. др.
Поддержка архитектуры Kappa
 Использование архитектуры Kappa для создания функций вызывает некоторые новые соображения:
Использование архитектуры Kappa для создания функций вызывает некоторые новые соображения:
- Функции обновления обновляются массово, что может привести к значительному количеству операций записи в базу данных. Важно следить за тем, чтобы во время этих крупных обновлений не страдала задержка запросов.
- Уровень обслуживания по-прежнему должен поддерживать различные типы запросов, в том числе запросы с малой задержкой для логического вывода и запросы с высоким TPS для пакетного обучения моделей.
Cassandra поддерживает архитектуру Kappa следующими способами:
- Cassandra предназначена для записи; увеличение притока записей не приводит к значительному снижению задержки запросов. Cassandra выбирает обработку записей с окончательной согласованностью вместо строгой согласованности, которая обычно приемлема для прогнозирования.
- С помощью CDC данные можно реплицировать в хранилище объектов для обучения и в хранилище в памяти для логических выводов. CDC мало влияет на задержку запросов к Cassandra.
Поддержка архитектуры Lambda
В большинстве компаний используется архитектура Lambda с конвейером пакетного уровня, который отделен от конвейера реального времени. В этом сценарии есть несколько категорий функций:
- Функции, которые вычисляются только в режиме реального времени и реплицируются в хранилище пакетных функций для обучения.
- Функции, которые вычисляются только в пакетном режиме и реплицируются в хранилище функций в реальном времени.
- Функции сначала вычисляются в режиме реального времени, а затем пересчитываются в пакетном режиме. Затем расхождения обновляются как в режиме реального времени, так и в хранилище объектов.
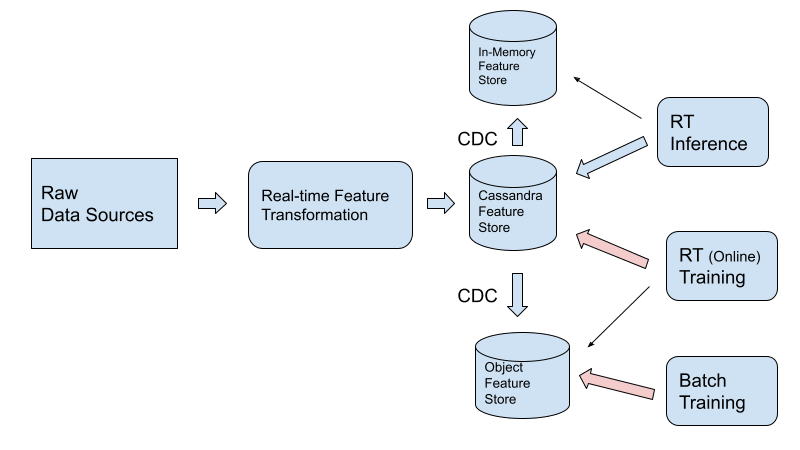
Однако в этом сценарии DataStax рекомендует архитектуру, как показано на этом рисунке:
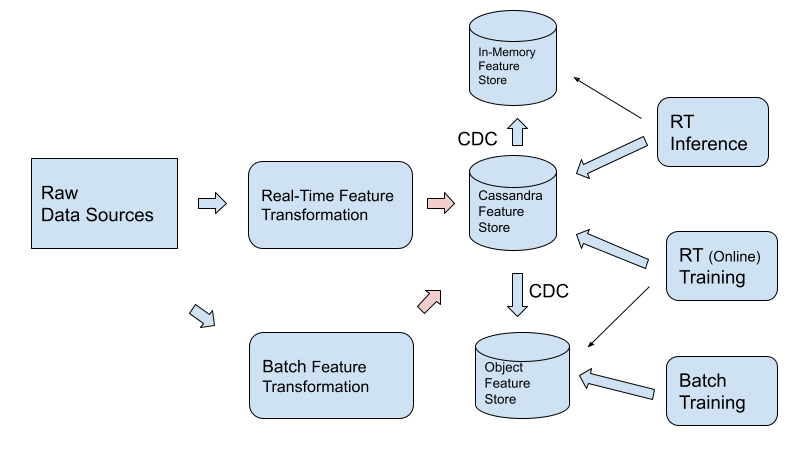 Причины следующие:
Причины следующие:
- Cassandra предназначена для пакетной загрузки данных с минимальным влиянием на задержку чтения.
- Благодаря единой системе записи управление данными становится значительно проще, чем если бы данные были разделены между хранилищем функций и хранилищем объектов. Это особенно важно для функций, которые сначала вычисляются в реальном времени, а затем повторно вычисляются в пакетном режиме.
- При экспорте данных из Cassandra через CDC в хранилище объектов экспорт данных можно оптимизировать для пакетного обучения (распространенный шаблон, используемый в таких компаниях, как Facebook), который значительно сокращает расходы на инфраструктуру обучения.
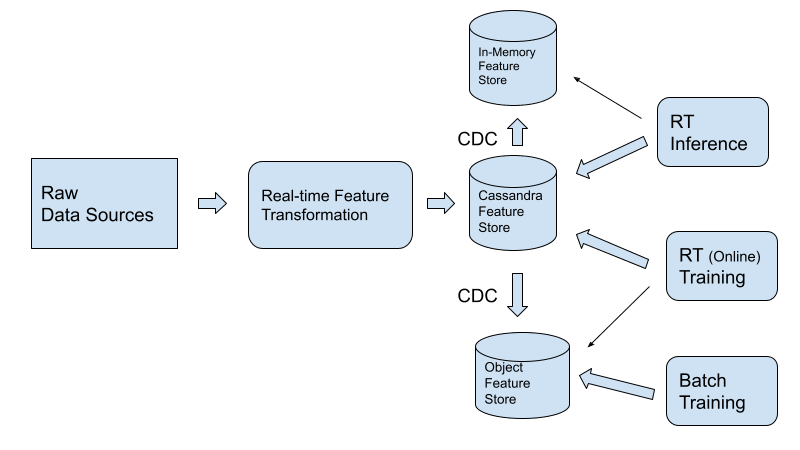
Если невозможно обновить существующие пайплайны или есть определенные причины, по которым функции должны быть сначала в хранилище объектов, мы рекомендуем использовать двусторонний путь CDC между хранилищем функций Cassandra и хранилищем объектов, как показано ниже.
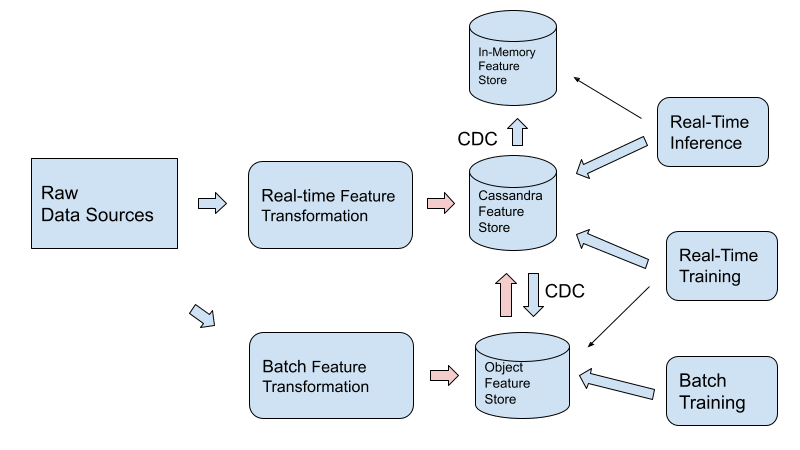 Обеспечить совместимость с существующей экосистемой программного обеспечения машинного обучения
Обеспечить совместимость с существующей экосистемой программного обеспечения машинного обучения
Чтобы использовать Cassandra в качестве хранилища функций, ее необходимо интегрировать с двумя частями экосистемы: библиотеками машинного обучения, которые выполняют вывод и обучение, и библиотеками обработки данных, которые выполняют преобразование функций.
Двумя наиболее популярными фреймворками для машинного обучения являются TensorFlow и PyTorch. Cassandra имеет драйверы Python, которые позволяют легко извлекать функции из базы данных Cassandra; другими словами, несколько функций могут быть получены параллельно (см. этот пример кода). Двумя наиболее популярными платформами для преобразования функций являются Flink и Spark Structured Streaming. Коннекторы для Flink и Spark доступны для Cassandra. Практики могут использовать учебные пособия по Flink и Spark Structured Streaming, и Кассандра.
Магазины функций с открытым исходным кодом, такие как FEAST, также имеют соединитель и tutorial и для Cassandra.
Понимание шаблонов запросов и пропускной способности для определения затрат
Количество запросов на чтение для Cassandra как хранилища функций зависит от количества входящих запросов на вывод. Предполагая, что данные объектов разделены на несколько таблиц или если данные могут быть загружены параллельно, это должно дать оценку разветвления между выводами в реальном времени, которые можно сделать. Например, 200 функций в 10 объектах в 10 отдельных таблицах дают соотношение примерно 1:10 между выводом в реальном времени и запросами к Cassandra.
Вычисление количества выполняемых выводов будет зависеть от шаблона трафика вывода. Например, в случае "потокового вывода" вывод будет выполняется всякий раз, когда изменяется релевантная функция, поэтому общее количество выводов зависит от того, как часто меняются данные функции. Когда вывод выполняется в режиме «запрос-ответ», он выполняется только тогда, когда его запрашивает пользователь.
Понимание шаблонов пакетной записи и записи в реальном времени для определения затрат
На производительность записи в основном влияет частота изменения функций. Если происходит денормализация, это также может повлиять на количество написанных функций. Другие соображения относительно пропускной способности записи включают в себя кэширование логических выводов для сценариев пакетного или потокового вывода.
Заключение
При разработке конвейера машинного обучения в реальном времени особое внимание необходимо уделить производительности и масштабируемости хранилища функций. Требованиям особенно хорошо удовлетворяют базы данных NoSQL, такие как Cassandra. Создайте собственное хранилище функций с помощью Cassandra или AstraDB и попробуйте Feast.dev с коннектором Cassandra .
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27740)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)