Ваша облачная инфраструктура может масштабироваться в режиме реального времени вместе с вашим приложением без внесения изменений в конфигурацию или написания строки кода. Автомасштабирование — это процесс увеличения или уменьшения емкости рабочих нагрузок приложений без вмешательства человека. При правильной настройке автомасштабирование может снизить затраты и трудозатраты инженеров на обслуживание приложений.
Общий процесс включения автомасштабирования прост. Он начинается с определения набора метрик, которые могут предоставить индикатор того, когда Kubernetes следует масштабировать емкость приложения. Затем набор правил определяет, следует ли увеличивать или уменьшать масштаб приложения. Наконец, с помощью API-интерфейсов Kubernetes ресурсы, доступные приложению, расширяются или сокращаются для выполнения работы, которую должно выполнять приложение.
Автомасштабирование — это процесс увеличения или уменьшения емкости рабочих нагрузок приложений без вмешательства человека. При правильной настройке автомасштабирование может снизить затраты и трудозатраты инженеров на обслуживание приложений. Общий процесс автомасштабирования прост. Он начинается с определения набора метрик, которые могут предоставить индикатор того, когда Kubernetes следует масштабировать емкость приложения. Затем набор правил определяет, следует ли увеличивать или уменьшать масштаб приложения. Наконец, с помощью API-интерфейсов Kubernetes ресурсы, доступные приложению, расширяются или сокращаются для выполнения работы, которую должно выполнять приложение.
Автомасштабирование — сложный процесс, и для некоторых категорий приложений он подходит лучше, чем для других. Например, если требования к пропускной способности приложения меняются нечасто, вам будет лучше выделить ресурсы для самого большого трафика, который будет обрабатывать приложение. Точно так же, если вы можете надежно предсказать нагрузку приложения, вы можете вручную настроить емкость в это время, а не инвестировать в решение для автоматического масштабирования.
Помимо переменной нагрузки на приложение, другие основные мотивы автоматического масштабирования включают управление затратами и емкостью. Например, автоматическое масштабирование кластера позволяет сэкономить деньги на общедоступных облаках, регулируя количество узлов в вашем кластере. Кроме того, если у вас есть статическая инфраструктура, автоматическое масштабирование позволит вам динамически управлять выделением емкости для ваших рабочих нагрузок, чтобы вы могли оптимально использовать свою инфраструктуру.
На высоком уровне автомасштабирование можно разделить на две категории:
- Автомасштабирование рабочей нагрузки: динамическое управление выделением ресурсов для отдельных рабочих нагрузок.
- Автомасштабирование кластера: динамическое управление емкостью кластера.
Давайте сначала углубимся в детали масштабирования рабочих нагрузок в Kubernetes. Некоторыми из стандартных инструментов, используемых для автоматического масштабирования рабочих нагрузок в Kubernetes, являются Horizontal Pod Autoscaler (HPA), Vertical Pod Autoscaler (VPA) и Cluster Proportional Autoscaler (CPA). Для работы с автоскейлерами нам понадобится кластер и простое тестовое приложение, которое мы настроим дальше.
Создание кластера Linode Kubernetes Engine
[Linode] (https://www.linode.com/?utm_source=rahul_rai&utm_medium=affiliate&utm_campaign=&utm_content=&utm_term=) предлагает управляемое предложение Kubernetes, известное как Linode Kubernetes Engine (LKE). Начать работу легко: зарегистрируйте бесплатную учетную запись Linode и следуйте руководству по адаптации LKE. -engine-a-tutorial?utm_source=rahul_rai&utm_medium=affiliate&utm_campaign=&utm_content=&utm_term=), чтобы создать свой кластер.
Для этого руководства я создал кластер, состоящий из двух узлов (называемых Linodes), каждый из которых имеет 2 ядра ЦП и 4 ГБ памяти следующим образом:
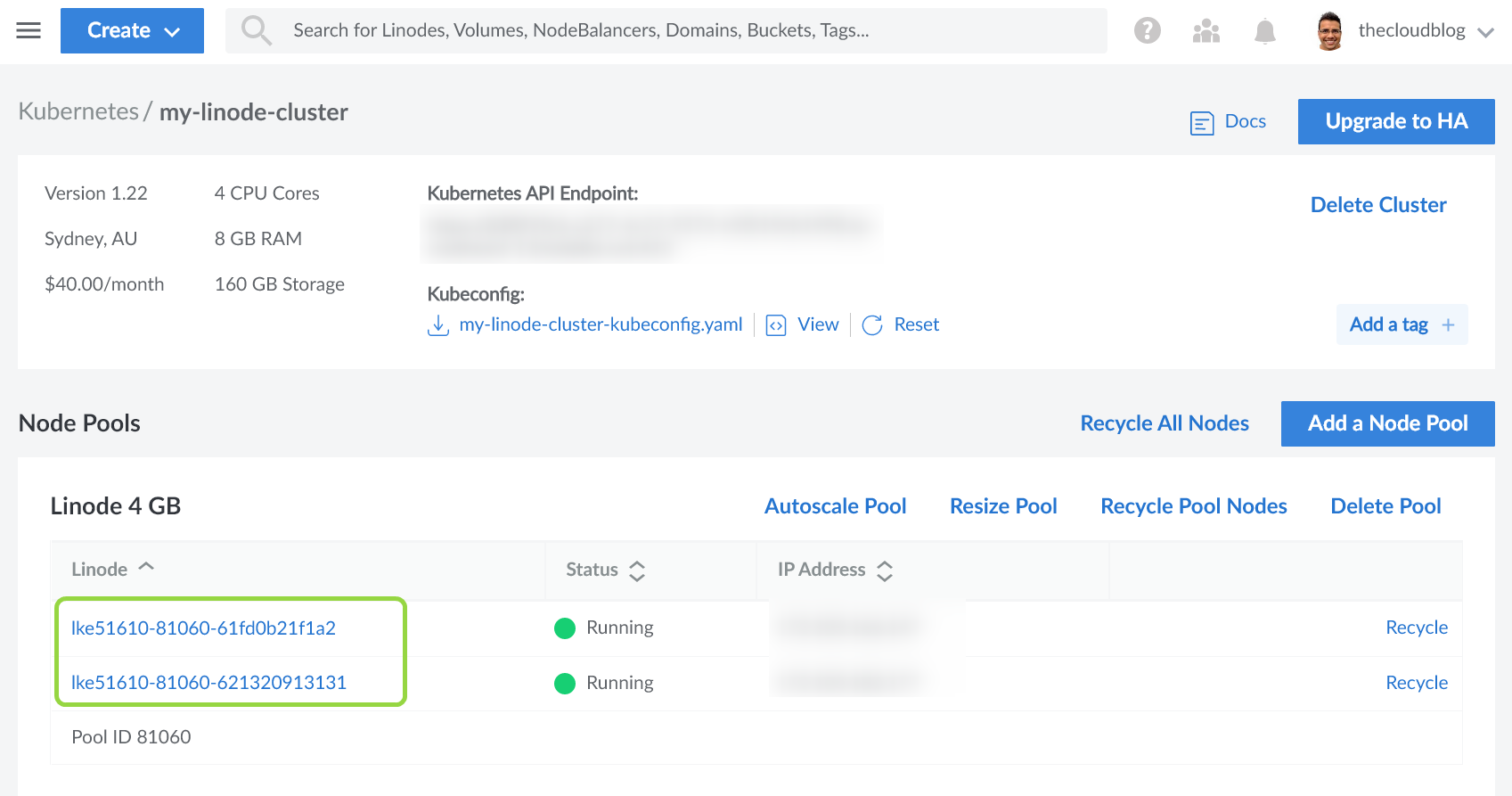
Для работы с кластером вам понадобится файл kubeconfig кластера, который вы можете скачать в разделе обзора кластера. Существует несколько стратегий, которые вы можете использовать для объединения файлов kubeconfig. Однако я предпочитаю обновлять переменную среды KUBECONFIG, указав путь к файлу kubeconfig.
Давайте теперь создадим простое приложение, которое мы будем использовать для тестирования различных автомасштабаторов.
API давления
API давления — это простой .NET REST API, который позволяет применять нагрузку на ЦП и память к поду, в котором работает приложение, через две его конечные точки:
- /memory/{numMegaBytes}/duration/{durationSec}: эта конечная точка добавит указанное количество мегабайт в память и будет поддерживать давление в течение указанного времени.
- /cpu/{threads}/duration/{durationSec}: Эта конечная точка будет запускать указанное количество потоков на ЦП и поддерживать нагрузку в течение указанного времени.
Ниже приведен полный исходный код приложения:
```csharp
с помощью System.Xml;
var builder = WebApplication.CreateBuilder(аргументы);
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
var app = builder.Build();
если (приложение.Окружающая среда.IsDevelopment())
приложение.UseSwagger();
приложение.UseSwaggerUI();
app.MapPost("/memory/{numMegaBytes}/duration/{durationSec}", (long numMegaBytes, int durationSec) =>
// ReSharper отключается один раз CollectionNeverQueried.Local
List
пытаться
в то время как (GC.GetTotalMemory(false) <= numMegaBytes * 1000 * 1000)
Документ XmlDocument = новый();
для (var i = 0; i < 1000000; i++)
memList.Add(doc.CreateNode(XmlNodeType.Element, "узел", string.Empty));
// Не сбой, если память недоступна
поймать (OutOfMemoryException ex)
Console.WriteLine(ex);
Thread.Sleep(TimeSpan.FromSeconds(durationSec));
мемСписок.Очистить();
GC.Собрать();
GC.WaitForPendingFinalizers();
вернуть Результаты.Ок();
.WithName("ЗагрузитьПамять");
app.MapPost("/cpu/{threads}/duration/{durationSec}", (int threads, int durationSec) =>
CancellationTokenSource cts = new();
for (var counter = 0; counter < threads; counter++)
ThreadPool.QueueUserWorkItem(tokenIn =>
pragma warning disable CS8605 // Распаковка возможного нулевого значения.
var token = (CancellationToken)tokenIn;
pragma warning restore CS8605 // Распаковка возможного нулевого значения.
в то время как (! token.IsCancellationRequested)
}, cts.Token);
Thread.Sleep(TimeSpan.FromSeconds(durationSec));
cts.Отмена();
Thread.Sleep(TimeSpan.FromSeconds(2));
cts.Dispose();
вернуть Результаты.Ок();
.WithName("Загрузить ЦП");
приложение.Выполнить();
Вам не нужно беспокоиться о деталях приложения. Я опубликовал образ контейнера приложения на GitHub Packages, который вы можете использовать в своих спецификациях K8s, которые мы создадим в следующих разделах.
Вы можете загрузить исходный код приложения и другие артефакты этого руководства из репозитория GitHub.
Спецификации Kubernetes, используемые в этом руководстве, доступны в папке spec репозитория кода. Используйте следующую спецификацию для развертывания приложения в кластере LKE:
``ямл
apiVersion: приложения/v1
вид: развертывание
метаданные:
имя: API-развертывание давления
спецификация:
селектор:
метки соответствия:
приложение: давление API
реплики: 1
шаблон:
метаданные:
этикетки:
приложение: давление API
спецификация:
контейнеры:
- имя: давление-апи
изображение: ghcr.io/rahulrai-in/dotnet-pressure-api:latest
порты:
- контейнерПорт: 80
Ресурсы:
пределы:
процессор: 500 м
память: 500Ми
апиВерсия: v1
вид: сервис
метаданные:
имя: API-служба давления
этикетки:
запустить: php-apache
спецификация:
порты:
- порт: 80
селектор:
приложение: давление API
Теперь ваше приложение готово принимать запросы, но доступ к нему возможен только внутри кластера. Позже мы будем использовать эфемерный модуль для отправки запросов в наш API. Теперь давайте обсудим наиболее распространенный инструмент автомасштабирования из семейства автомасштабаторов: Horizontal Pod Autoscaler (HPA).
Горизонтальное автомасштабирование Pod (HPA)
Horizontal Pod Autoscaler позволяет динамически регулировать количество модулей в кластере в зависимости от текущей нагрузки. Kubernetes изначально поддерживает его с помощью ресурса HorizontalPodAutoscaler и контроллера, встроенного в kube-controller-manager. HPA полагается на сервер метрик Kubernetes для предоставления PodMetrics. Сервер метрик собирает использование ЦП и памяти модулями из кублетов, работающих на каждом узле в кластере, и делает их доступными для HPA через API метрик.
Следующая диаграмма иллюстрирует компоненты, участвующие в процессе:
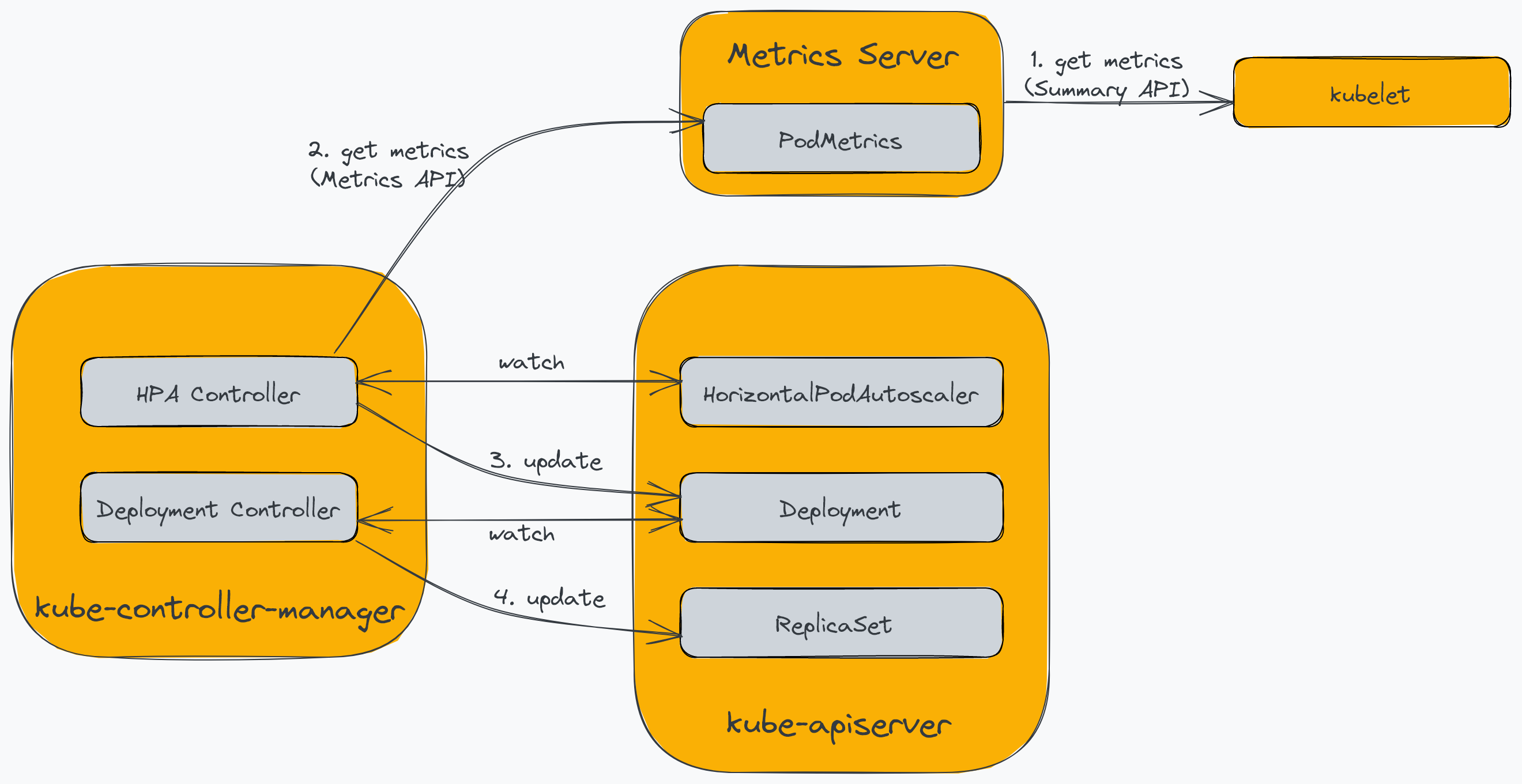
Сервер метрик опрашивает конечную точку Summary API kubelet для сбора показателей использования ресурсов контейнеров, работающих в стручки. Контроллер HPA опрашивает конечную точку API метрик сервера API Kubernetes каждые 15 секунд (по умолчанию), которую он проксирует на сервер метрик. Кроме того, контроллер HPA постоянно отслеживает ресурс HorizontalPodAutoscaler, который поддерживает конфигурации автомасштабирования. Затем контроллер HPA обновляет количество модулей в развертывании (или другом настроенном ресурсе) в соответствии с требованиями на основе конфигураций. Наконец, контроллер развертывания реагирует на изменение, обновляя ReplicaSet, что приводит к изменению количества модулей.
Мы знаем, что сервер метрик является необходимым условием для HPA и VPA. Следуйте инструкциям, указанным в официальном руководстве по серверу метрик, чтобы установить его в своем кластере. Если у вас возникли проблемы с TLS при установке, используйте спецификацию metrics-server.yaml, доступную в папке spec [репозитория кода] (https://github.com/rahulrai-in/dotnet-pressure-api). ) следующим образом:
``` ударить
kubectl применить -f spec/metrics-server.yaml
Давайте теперь настроим объект HorizontalPodAutoscaler, чтобы масштабировать наше развертывание до пяти реплик и уменьшить его до одной реплики на основе среднего использования ресурса памяти следующим образом:
``ямл
apiVersion: автомасштабирование/v2beta2
вид: HorizontalPodAutoscaler
метаданные:
имя: давление-апи-hpa
спецификация:
Масштабная целевая ссылка:
apiVersion: приложения/v1
вид: развертывание
имя: API-развертывание давления
минРеплики: 1
максимальное количество реплик: 5
показатели:
- тип: Ресурс
ресурс:
Название: память
цель:
Тип: Использование
среднийИспользование: 40
Если среднее использование памяти остается на уровне более 40 %, HPA увеличивает количество реплик и наоборот. Вы можете расширить правило, включив в него загрузку ЦП. В этом случае контроллер HPA определит максимальное количество реплик на основе комбинации правил и использует наибольшее значение.
Прежде чем мы начнем, давайте посмотрим на HPA и развертывание в двух разных окнах терминала, чтобы увидеть изменения в количестве реплик в режиме реального времени.
``` ударить
kubectl получить HPA Pressure-API-HPA --watch
kubectl получить развертывание Pressure-API-Deployment --watch
Чтобы активировать HPA, мы запустим эфемерный модуль и дадим ему указание отправлять запросы в конечную точку /memory/{numBytes}/duration/{durationSec}`. Следующая команда запустит HPA для масштабирования модулей, чтобы уменьшить нехватку памяти.
``` ударить
kubectl run -i --tty mem-load-gen --rm --image=busybox --restart=Никогда -- /bin/sh -c "во время сна 0.01; do wget -q -O- --post-data = http://pressure-api-service/memory/1000/duration/180; готово"
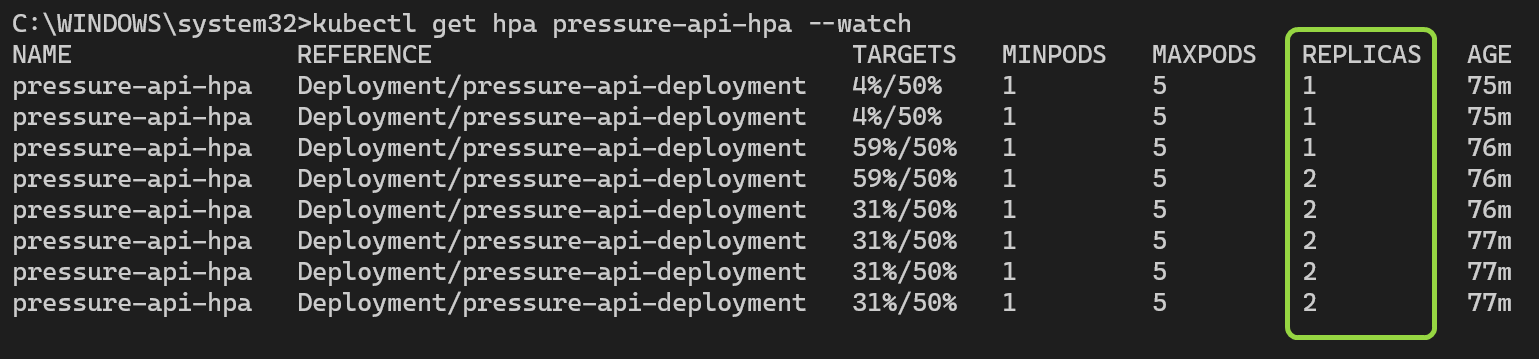
Вы можете наблюдать, как HPA обновляет количество реплик развертывания в окне терминала. Обратите внимание на рост активного использования по сравнению с целевым значением следующим образом:
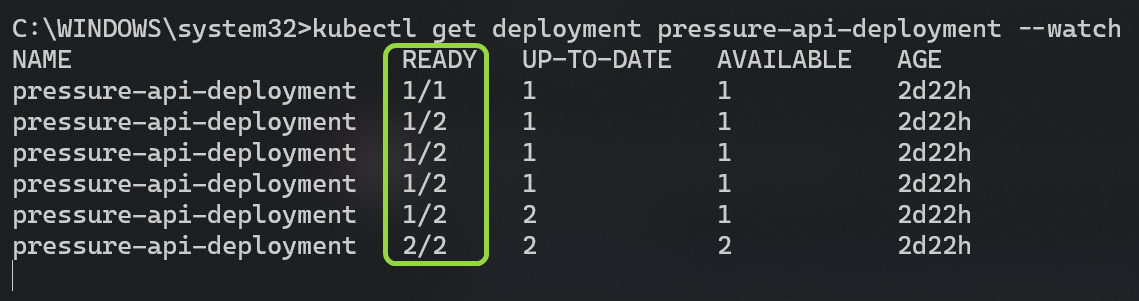
Одновременно вы можете видеть, как реплики обновляются следующим образом:
Есть несколько соображений, которые следует учитывать при использовании HPA:
- Ваше приложение должно быть способно распределять нагрузку между отдельными экземплярами.
- Ваш кластер должен иметь достаточную емкость для увеличения количества модулей. Эту проблему можно решить, заблаговременно предоставив требуемую емкость и используя оповещения, чтобы предложить операторам вашей платформы увеличить емкость кластера. Вы также можете использовать автомасштабирование кластера для автоматического масштабирования кластера. Мы обсудим эту функцию позже в этом уроке.
- ЦП и память могут быть неподходящими показателями для вашего приложения, чтобы принимать решения о масштабировании. В таких случаях вы можете использовать HPA (или VPA) с пользовательскими метриками в качестве альтернативы. Чтобы использовать пользовательские метрики для автоматического масштабирования, вы можете использовать адаптер пользовательских метрик вместо сервера метрик Kubernetes. Популярными адаптерами пользовательских метрик являются [адаптер Prometheus] (https://github.com/kubernetes-sigs/prometheus-adapter) и [Kubernetes Event-Driven Autoscaler (KEDA)] (https://keda.sh/).
Прежде чем мы продолжим, удалите только что созданный HPA и сбросьте счетчик реплик развертывания следующим образом:
``` ударить
kubectl удалить HPA/давление API-HPA
kubectl scale --replicas=2 развертывание/давление-API-развертывание
Давайте обсудим еще один тип автомасштабирования, доступный в Kubernetes: автомасштабирование вертикальных модулей (VPA).
Автомасштабирование вертикальных модулей (VPA)
Vertical Pod Autoscaler позволяет динамически регулировать емкость ресурсов одного экземпляра. В контексте модулей это включает изменение количества ресурсов ЦП и памяти, доступных для модуля. В отличие от HPA, который входит в ядро Kubernetes, VPA требует установки трех компонентов контроллера в дополнение к серверу метрик. На следующей диаграмме показаны компоненты Kubernetes и их взаимодействие с VPA:
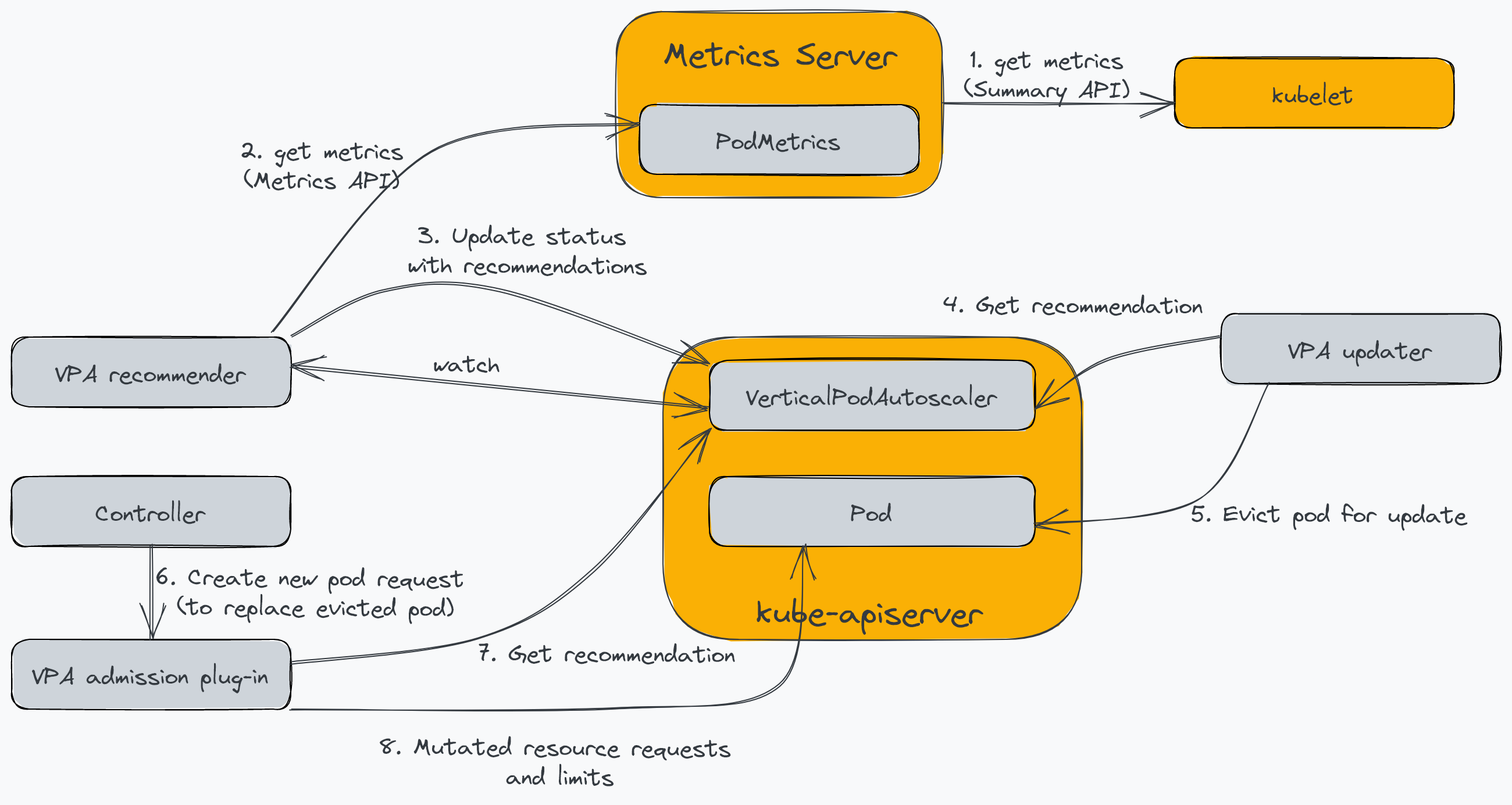
- Рекомендуемый: определяет оптимальные значения ЦП и памяти на основе использования ресурсов модуля.
- Подключаемый модуль: изменяет запросы ресурсов модуля и ограничивает время создания модуля на основе рекомендации рекомендателя.
- Updater: отключает модули, чтобы подключаемый модуль допуска перехватывал запрос на воссоздание.
Следуйте инструкциям по установке в руководстве ReadMe VPA , чтобы подготовить кластер. После завершения установки вы можете проверить работоспособность компонентов VPA, выполнив следующую команду:
``` ударить
kubectl get pods -l "приложение в (vpa-recommender,vpa-admission-controller,vpa-updater)" -n kube-system

Давайте разберемся, как работает операция масштабирования VPA. Объявления запросы ресурсов в спецификации модуля гарантируют, что Kubernetes резервирует для модуля минимально необходимые ресурсы. Когда VPA обнаруживает, что поды приближаются к пределам потребления ресурсов, он автоматически вычисляет новый, более подходящий набор значений. Если вы определяете как запросы ресурсов , так и ограничения ресурсов в спецификации модуля, VPA будет поддерживать соотношение запросов и ограничений при обновлении значений. Таким образом, всякий раз, когда VPA обновляет запросы ресурсов, он также меняет лимиты ресурсов».
Мы определим политику VPA для автоматической настройки запросов ЦП и памяти без добавления дополнительных модулей для обработки рабочей нагрузки следующим образом:
``ямл
apiVersion: "autoscaling.k8s.io/v1"
тип: Вертикальный под автомасштабирование
метаданные:
имя: давление-апи-впа
спецификация:
цельСсылка:
apiVersion: "приложения/v1"
вид: развертывание
имя: API-развертывание давления
политика обновления:
updateMode: Воссоздать
политика ресурса:
Политики контейнера:
- имя контейнера: "*"
минРазрешено:
процессор: 0 м
память: 0Ми
максимально разрешено:
процессор: 1
память: 2000Ми
контролируемые ресурсы: ["процессор", "память"]
контролируемые значения: реквестсандлимитс
Спецификация будет применяться ко всем контейнерам развертывания. Минимальное и максимальное пороговые значения обеспечат работу VPA в разумных пределах.
В поле controllerresources указываются ресурсы, которые будут автоматически масштабироваться VPA.
VPA поддерживает четыре режима обновления. Только режимы «Повторное создание» и «Авто» активируют автомасштабирование. Однако для них существуют ограниченные варианты использования. В режиме «Начальный» контроль доступа будет применяться к заданным значениям ресурсов при их создании, но он не позволит программе обновлений вытеснить какие-либо модули. Наиболее полезным режимом является режим «Выкл.». В этом режиме VPA не будет масштабировать ресурсы. Однако он будет рекомендовать значения ресурсов. Вы можете использовать этот режим, чтобы вычислить оптимальные значения ресурсов для вашего приложения во время их всестороннего нагрузочного тестирования и профилирования, прежде чем они будут запущены в производство. Рекомендуемые значения могут быть применены к спецификации производственного развертывания, экономя инженерный труд.
Примените предыдущую спецификацию и выполните следующую команду, чтобы просмотреть автомасштабирование:
``` ударить
kubectl получить vpa/pressure-api-vpa --watch
Теперь мы применим нагрузку на ЦП, используя следующую команду для активации VPA:
``` ударить
kubectl run -i --tty mem-load-gen --rm --image=busybox --restart=Никогда -- /bin/sh -c "во время сна 0.01; do wget -q -O- --post-data = http://pressure-api-service/cpu/10/duration/180; готово"
Через некоторое время выполните следующую команду, чтобы просмотреть рекомендации, созданные VPA.
``` ударить
kubectl описывает vpa/pressure-api-vpa
Ниже приведен фрагмент вывода предыдущей команды, в котором представлены рекомендации VPA:
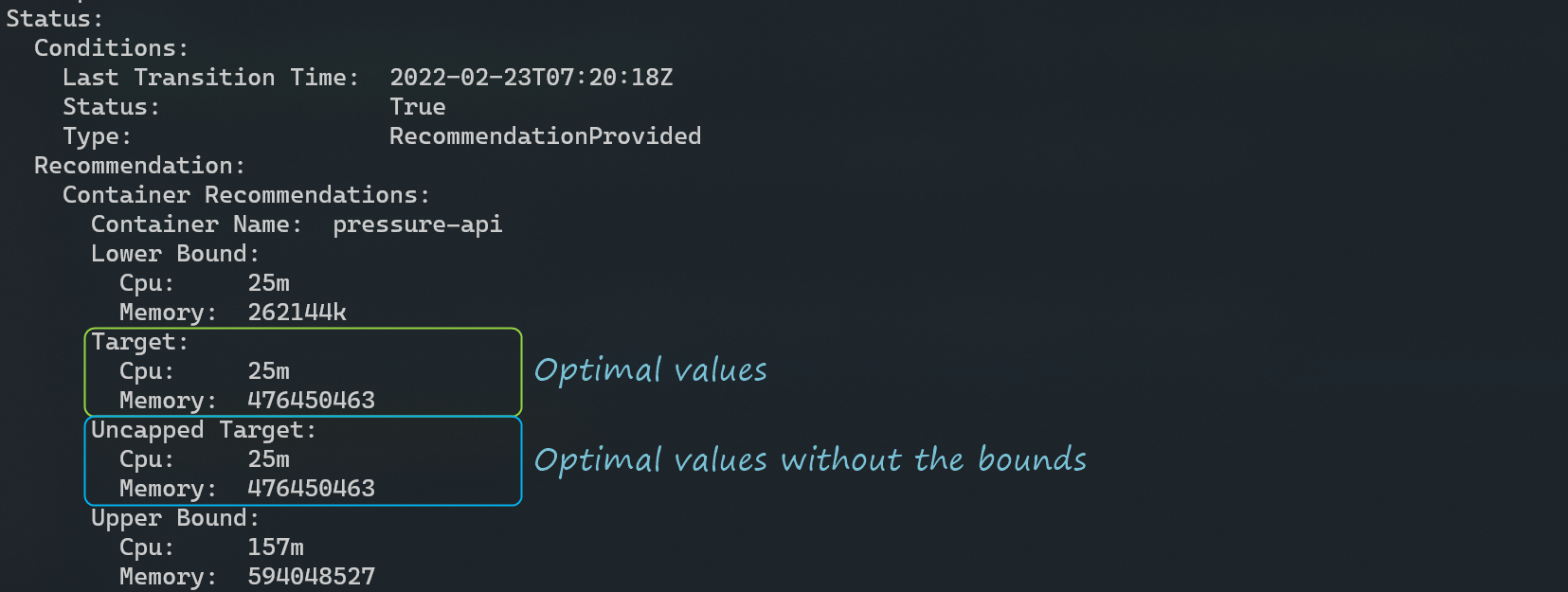
Используйте целевое значение в качестве базовой рекомендации для запросов ЦП и памяти. Если верхняя и нижняя границы, определенные в спецификации VPA, не оптимальны, используйте Uncapped Target в качестве базовой линии, представляющей целевую оценку, полученную без ограничений minAllowed и maxAllowed.
Поскольку мы включили вертикальное автомасштабирование, вновь созданные модули будут иметь аннотации VPA, применяемые контроллером доступа. Следующая команда отобразит аннотации модуля:
``` ударить
kubectl get pod <имя модуля> -o jsonpath='{.metadata.annotations}'
Вот вывод предыдущей команды (из консоли K9s:

Давайте удалим средство автомасштабирования и сбросим наше развертывание, прежде чем переходить к следующему средству масштабирования в списке.
``` ударить
kubectl удалить vpa/давление-api-vpa
kubectl scale --replicas=1 развертывание/давление-API-развертывание
Пропорциональное автомасштабирование кластера (CPA)
Cluster Proportional Autoscaler (CPA) – это горизонтальное средство автоматического масштабирования pod, которое масштабирует реплики в зависимости от количества узлов в кластере. В отличие от других средств автомасштабирования, он не использует API метрик и не требует сервера метрик. Кроме того, в отличие от других средств автомасштабирования, которые мы видели, CPA не масштабируется с помощью ресурса Kubernetes, а вместо этого использует флаги для определения целевых рабочих нагрузок и ConfigMap для конфигурации масштабирования. Следующая диаграмма иллюстрирует компоненты CPA:
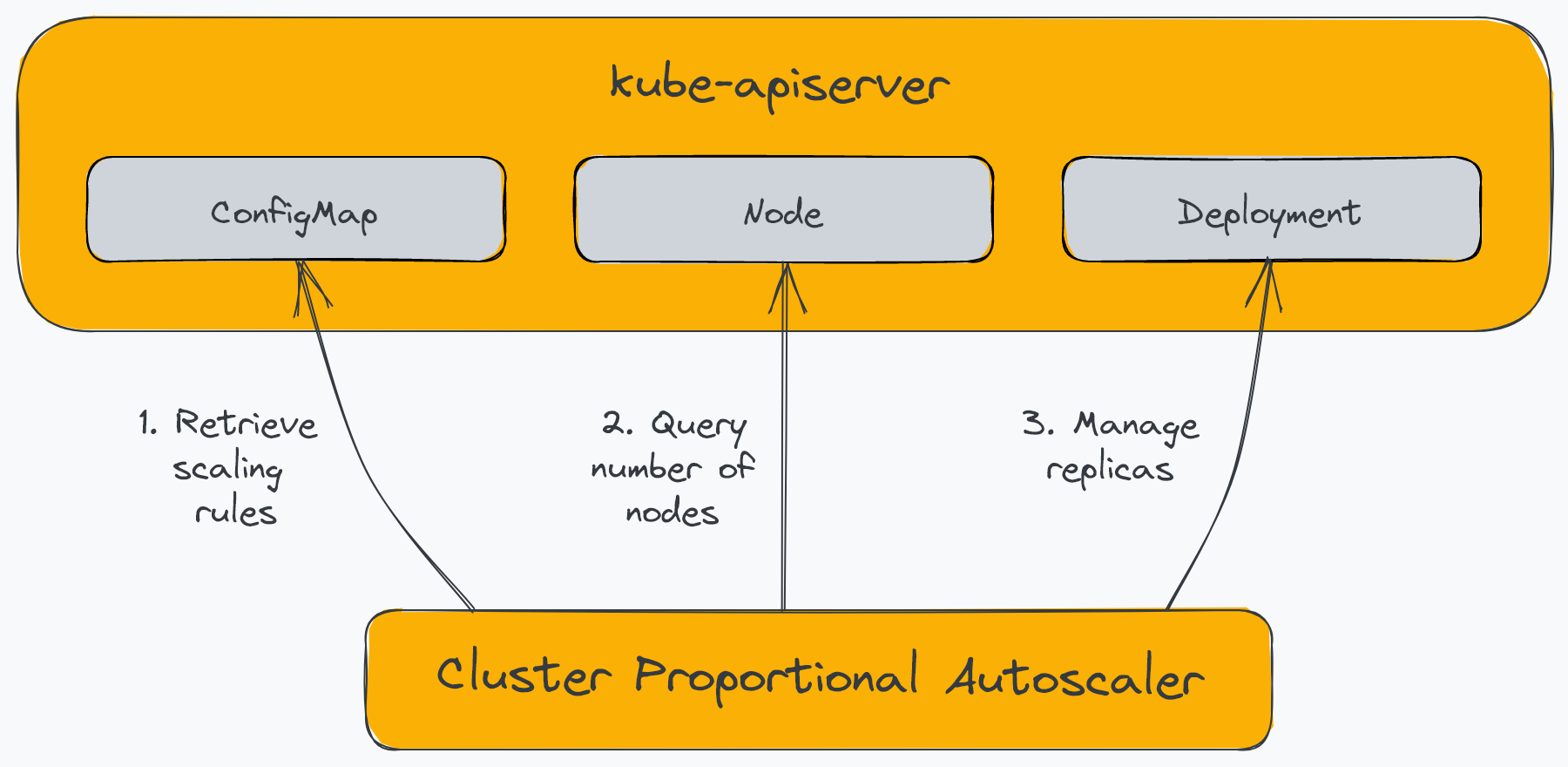
CPA имеет относительно ограниченные варианты использования. Например, CPA обычно используется для масштабирования сервисов платформы, таких как DNS кластера, которые необходимо масштабировать в соответствии с рабочей нагрузкой, развернутой в кластере. Другой вариант использования CPA — наличие простого механизма масштабирования рабочих нагрузок, поскольку он не требует использования сервера метрик или адаптера Prometheus.
Вы можете установить CPA на свой кластер, используя его диаграмму Helm. Используйте следующую команду, чтобы добавить репозиторий Helm cluster-proportional-autoscaler следующим образом:
``` ударить
репозиторий helm добавить cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
обновление репозитория шлема
Вы можете определить правила автомасштабирования в файле значений диаграммы, который создает ConfigMap с указанными конфигурациями. Позже вы можете отредактировать ConfigMap, чтобы изменить поведение автомасштабирования без переустановки диаграммы.
Создайте файл с именем cpa-values.yaml и добавьте следующее содержимое:
``ямл
конфигурация:
лестница:
узлыторепликас:
- [1, 3]
- [2, 5]
опции:
пространство имен: по умолчанию
цель: "развертывание/давление-API-развертывание"
Вы можете указать один из двух методов масштабирования, используемых CPA:
- Линейный: приложение масштабируется прямо пропорционально количеству узлов или ядер в кластере.
- Ladder: использует ступенчатую функцию для определения соотношения узлов:реплики и/или ядра:реплики.
В приведенном выше примере CPA масштабирует развертывание до трех реплик, если у нас есть один узел в кластере и пять реплик для двух узлов. Давайте теперь установим чарт и предоставим ему конфигурацию.
``` ударить
helm upgrade --install cluster-proportional-autoscaler \
кластер-пропорционально-автомасштабирование/кластер-пропорционально-автомасштабирование --values cpa-values.yaml
Как только вы установите CPA, вы обнаружите, что он масштабирует развертывание press-api-deployment до 5 реплик, поскольку в нашем кластере два узла.
Давайте удалим CPA перед переходом к следующему автомасштабатору в списке следующим образом:
``` ударить
helm удалить кластер-пропорционально-автомасштабирование
Мы рассмотрели несколько подходов к автоматическому масштабированию рабочих нагрузок с использованием основных компонентов Kubernetes и дополнительных компонентов, созданных сообществом. Далее мы обсудим, как можно масштабировать сам кластер Kubernetes.
Средство автомасштабирования кластера (CA)
Добавление и удаление емкости из кластера Kubernetes вручную может значительно увеличить затраты на управление кластером и трудозатраты инженеров. Cluster Autoscaler автоматизирует добавление и удаление рабочих узлов в кластере для достижения желаемой емкости. CA прекрасно работает в сочетании с HPA. Как только HPA начинает приближаться к пределу вычислительных ресурсов, CA может рассчитать количество узлов, чтобы удовлетворить нехватку, и добавить новые узлы в кластер. Кроме того, когда CA определяет, что узлы недостаточно загружены в течение длительного периода, он может перепланировать модули pod на другие узлы и удалить недостаточно загруженные узлы из кластера.
Реализация Cluster Autoscaler зависит от поставщиков облачных услуг. Некоторые облачные провайдеры, такие как Azure и AWS, поддерживают Cluster API. Cluster API использует своего оператора Kubernetes для управления инфраструктурой кластера. Средство автомасштабирования кластера переносит операцию обновления количества узлов на контроллер API кластера. Автомасштабирование кластера может быть полезным, если перед его реализацией вы учтете следующее:
- Убедитесь, что вы понимаете, как ваше приложение будет вести себя под нагрузкой, и устраните узкие места, которые мешают горизонтальному масштабированию приложения.
- Знайте верхний предел масштабирования, который может установить облачный провайдер.
- Понимание скорости, с которой кластер может масштабироваться, когда возникает необходимость.
Включить Автомасштабирование кластера в LKE очень просто. Сначала перейдите на страницу обзора кластера и нажмите кнопку Автомасштабирование пула .
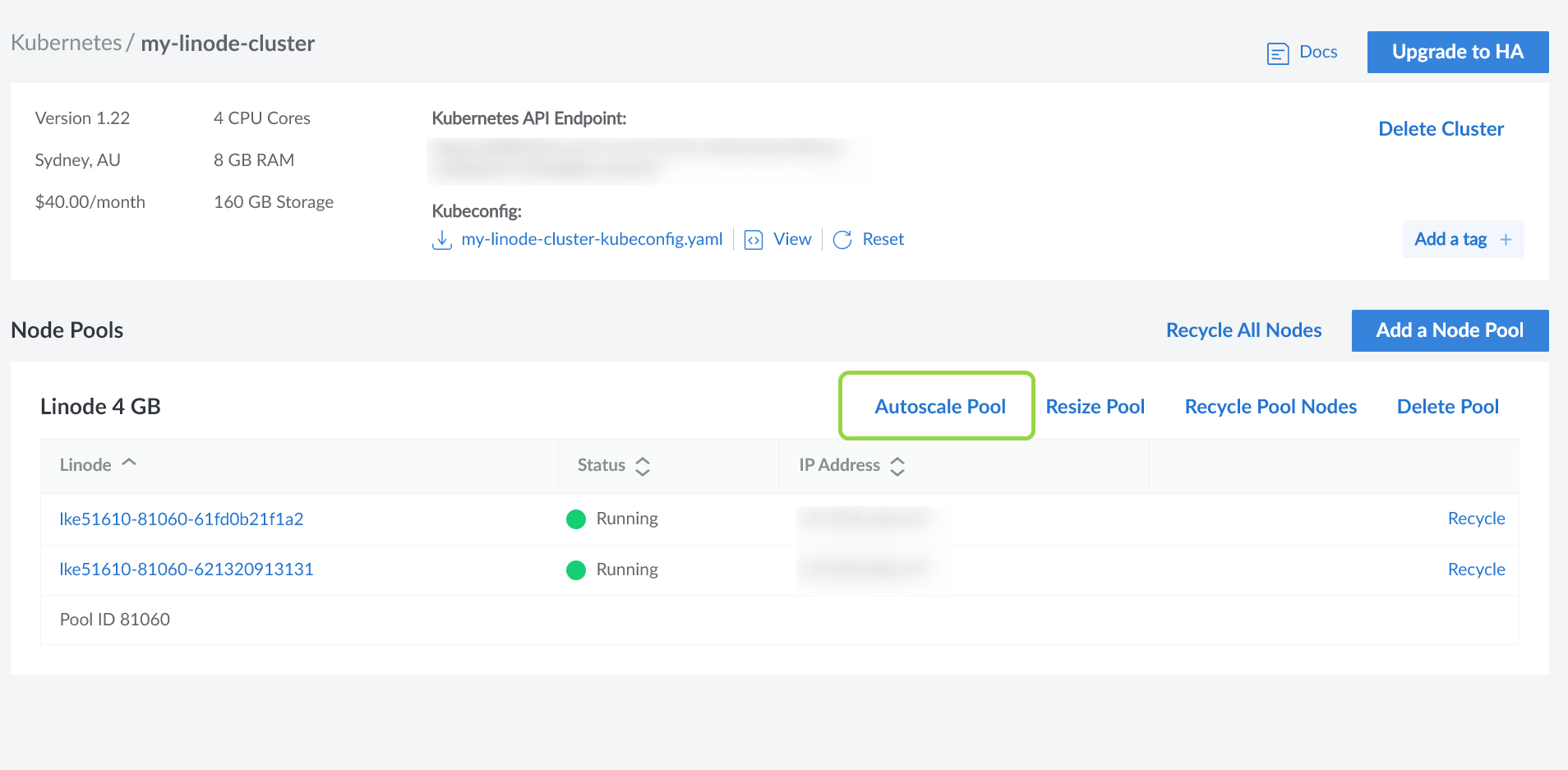
Затем в следующем диалоговом окне введите минимальное и максимальное количество узлов, которые LKE должен поддерживать, следующим образом:
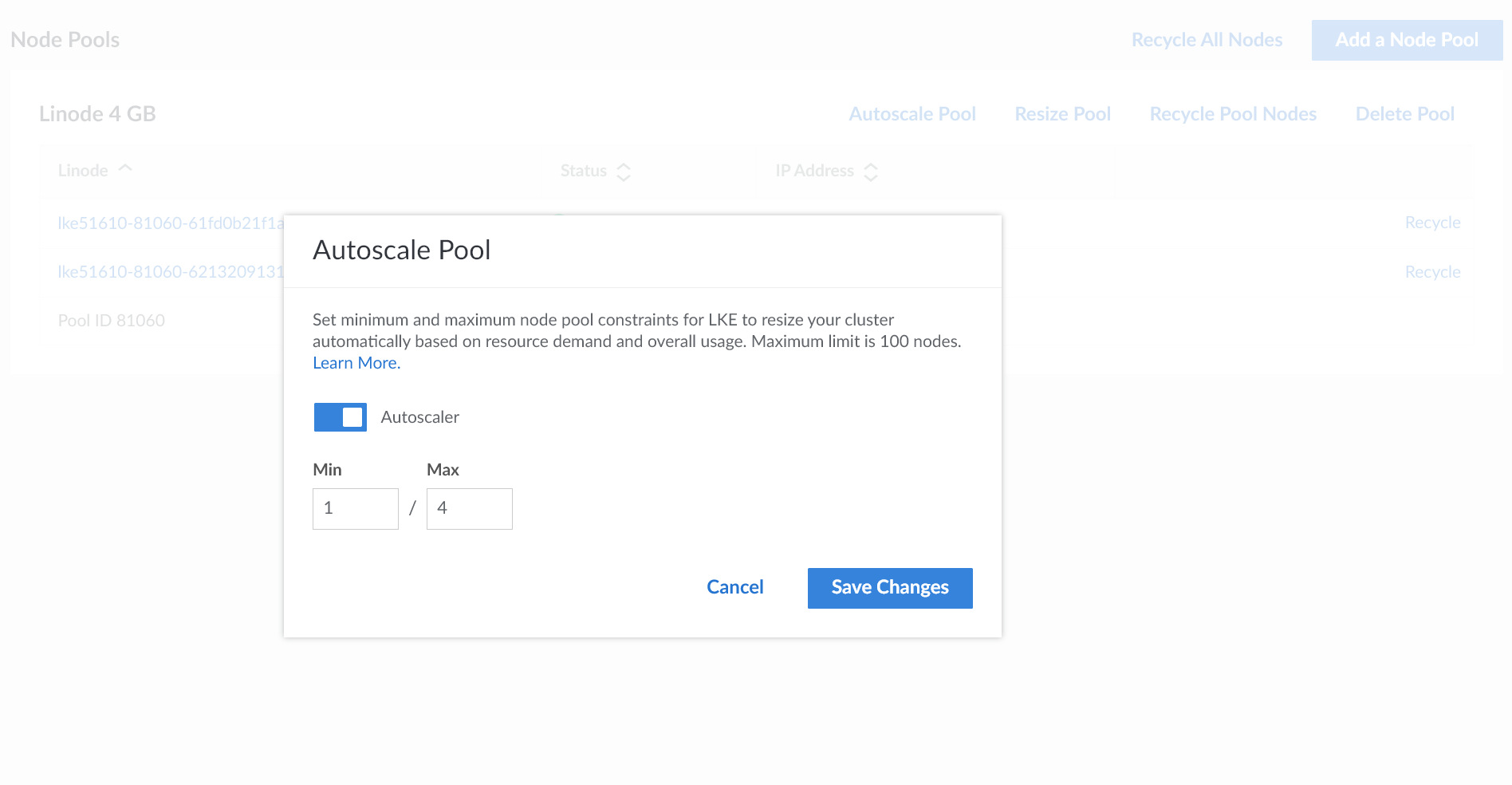
Средство автомасштабирования кластера LKE реагирует на ожидающие поды, которые не удалось запланировать из-за нехватки вычислительных ресурсов. Средство автомасштабирования отслеживает недоиспользуемые узлы и удаляет их из кластера, чтобы уменьшить масштаб кластера.
Мы начали с кластера из двух узлов, каждый с двумя ядрами ЦП и 4 ГБ памяти. Чтобы запустить автомасштабирование кластера, мы можем добавить в наше приложение дополнительные реплики следующим образом:
``` ударить
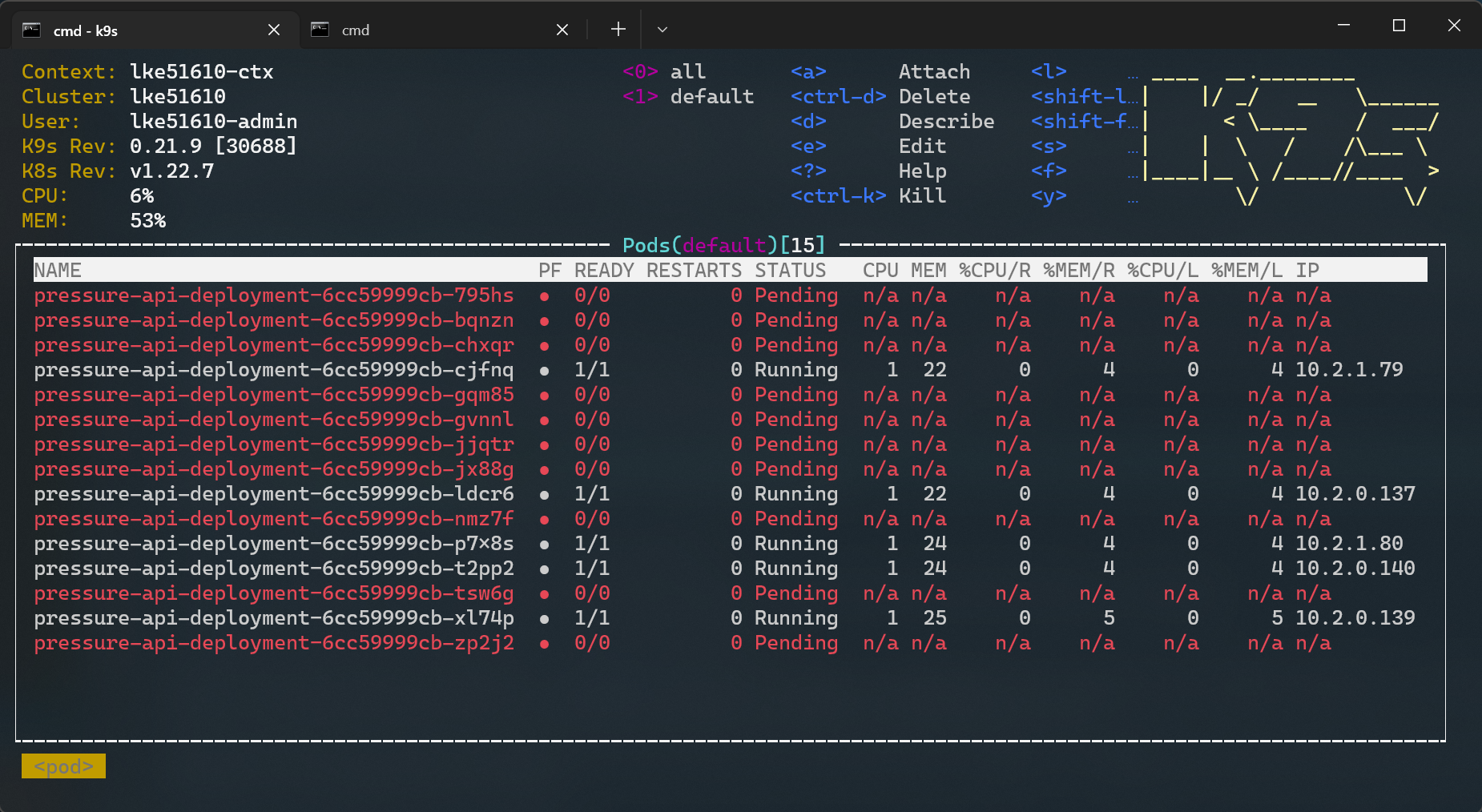
масштаб kubectl --replicas=15 развертывание/давление-API-развертывание
После выполнения команды вы обнаружите, что несколько модулей развертывания переходят в состояние ожидания следующим образом:
Вскоре после этого LKE добавляет в кластер дополнительные узлы и распределяет некоторые из них на новых узлах следующим образом:
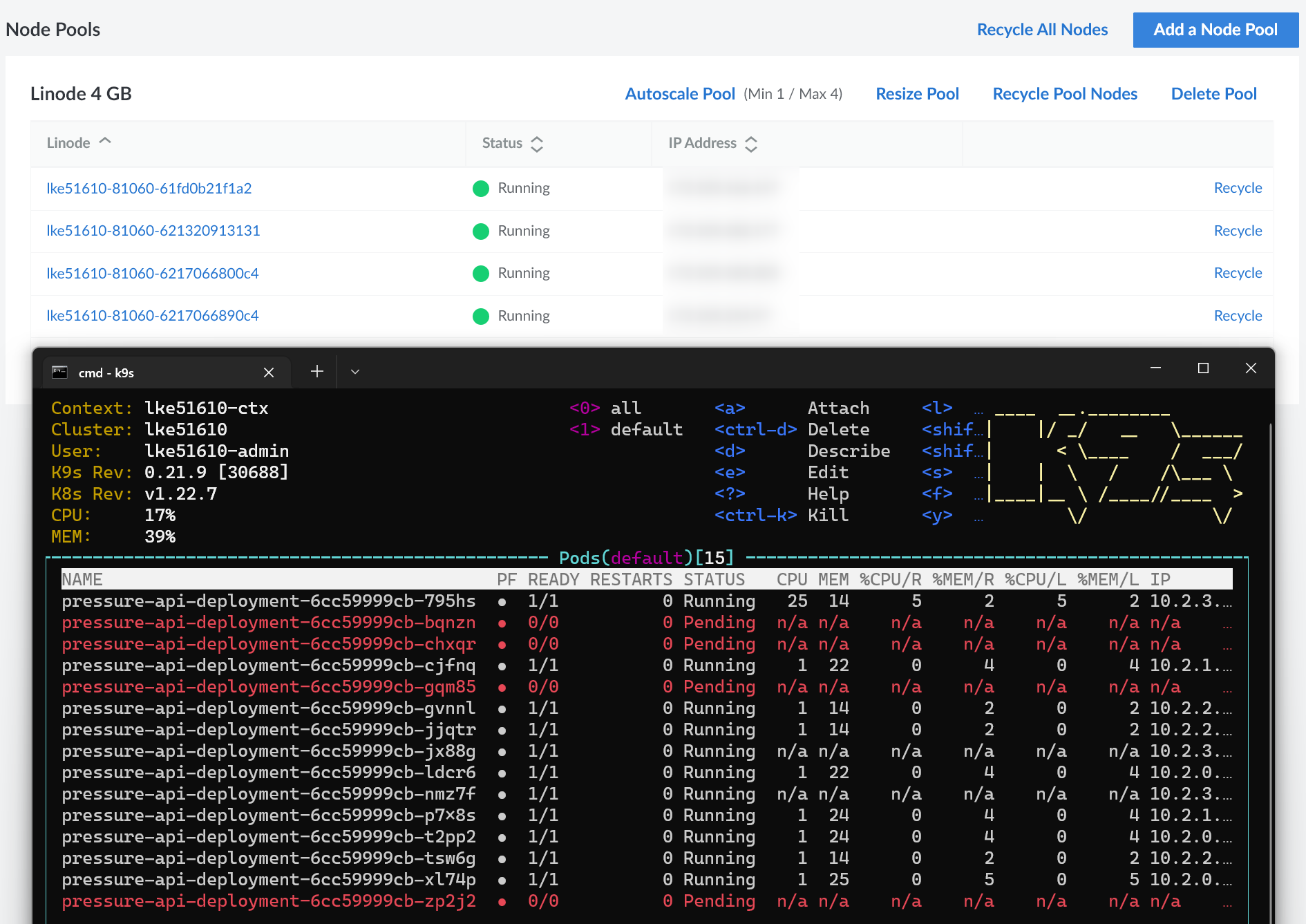
Вы обнаружите, что некоторые модули все еще находятся в состоянии ожидания, потому что мы указали LKE увеличить масштаб до четырех узлов. Наконец, чтобы очистить среду, выполните следующую команду:
``` ударить
kubectl удалить развертывание/давление-API-развертывание
Резюме
Мы обсудили концепции автоматического масштабирования по горизонтали, автомасштабирования по вертикали и автомасштабирования кластера, а также варианты их использования и соображения. Если ваши приложения часто подвергаются изменениям в требованиях к емкости, вы можете использовать HPA для их горизонтального масштабирования. VPA может помочь вам определить оптимальные значения ресурсов для ваших приложений. CPA может помочь вам удовлетворить требования к масштабированию приложений, которые необходимо масштабировать с рабочей нагрузкой в кластере. Если ваши рабочие нагрузки могут масштабироваться за пределы емкости кластера, используйте ЦС для автоматического масштабирования самого кластера. Если вы рассматриваете управляемый сервис Kubernetes, такой как LKE, ищите решение со встроенными инструментами автомасштабирования, чтобы сократить ваши усилия.