

Руководство инженера -инженера по Пейисебергу
21 июня 2025 г.Написано: Diptiman Raichaudhuri, адвокат разработчика сотрудников в Confluent
В этой статье показывает инженеры по данным, как использовать Pyiceberg, легкую и мощную библиотеку Python. Pyiceberg облегчает выполнение общих задач данных, таких как создание, чтение, модификация или удаление данных в Apache Aceberg, без необходимости большого кластера.
При обучении сложным бизнес -требованиям и необходимостью анализа больших объемов информации платформы данных значительно изменились за последние несколько лет, чтобы помочь предприятиям извлечь больше информации и ценность из их разнообразных источников данных.
Для предприятий Analytics варианты использования, платформа Open Data Lakehouse была в авангарде этой эволюции этой платформы. Открытые данные Lakehouse позволяют командам данных создавать «композируемые» архитектуры в их экосистеме. С помощью этой модели команды данных могут разрабатывать платформы данных с уровнями хранения, вычислений и управления данными по своему выбору, чтобы удовлетворить постоянно развивающиеся потребности предприятий. Форматы открытых столов (OTF), такие как Apache Araceberg, являются двигателями, управляющими внедрением современных открытых озеро.
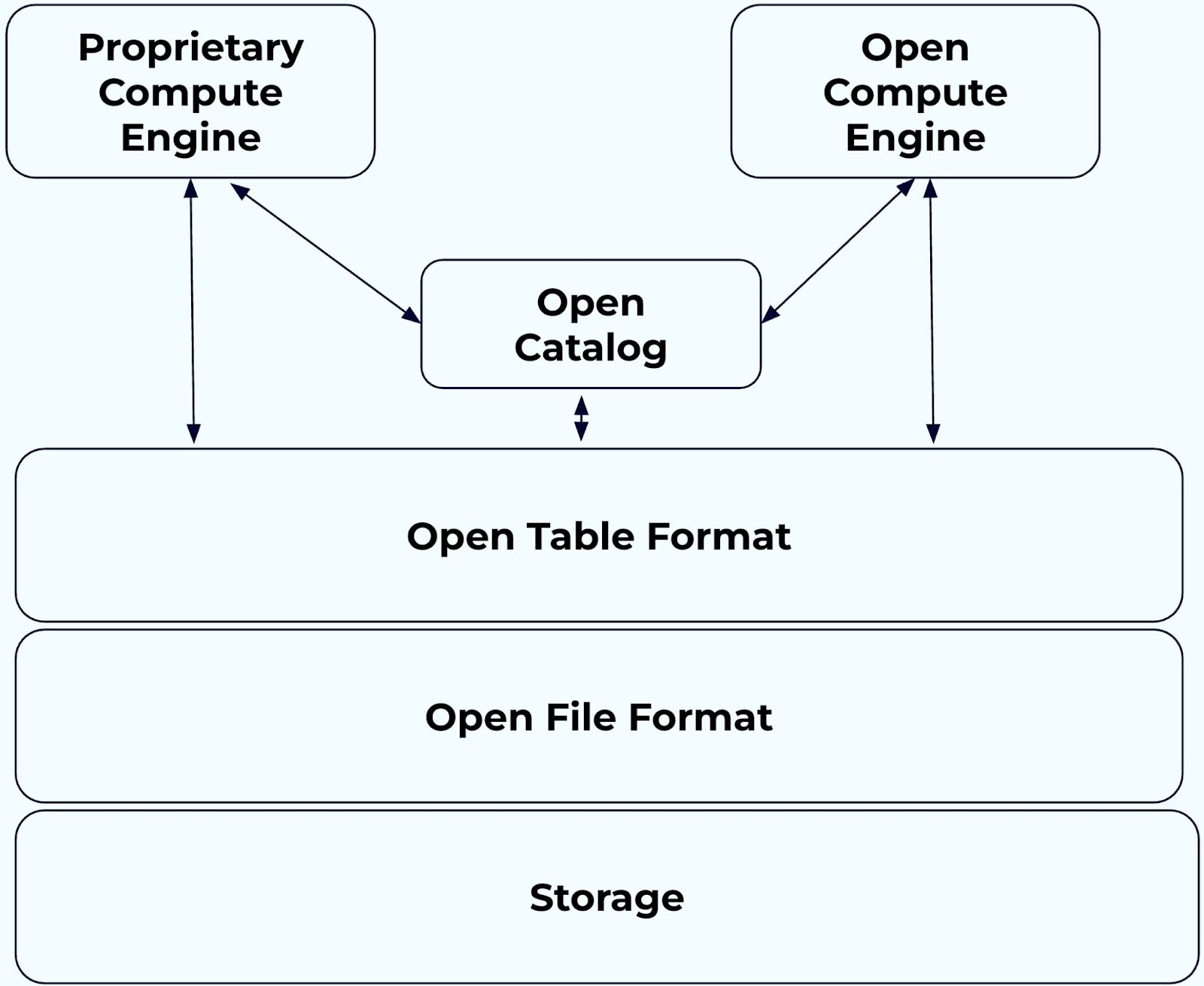
Архитектура композиционной платформы данных
Платформы данных, построенные с айсбергом Apache, обычно имеют три уровня:
- Уровень данных: Физические файлы данных (обычно паркет, AVRO или ORC) хранятся в этом слое.
- Слой метаданных: Вместо сортировки таблиц в отдельные каталоги айсберг сохраняет список файлов. Слой метаданных управляет снимками, схемами и статистикой файлов.
- Каталог айсберга: Каталог - это центральный репозиторий, который облегчает обнаружение таблицы, создание и модификацию таблиц и обеспечивает транзакционную консистенцию управления таблицами айсберга.
Эта популярная диаграмма из документации Apache Araceberg иллюстрирует эти слои:
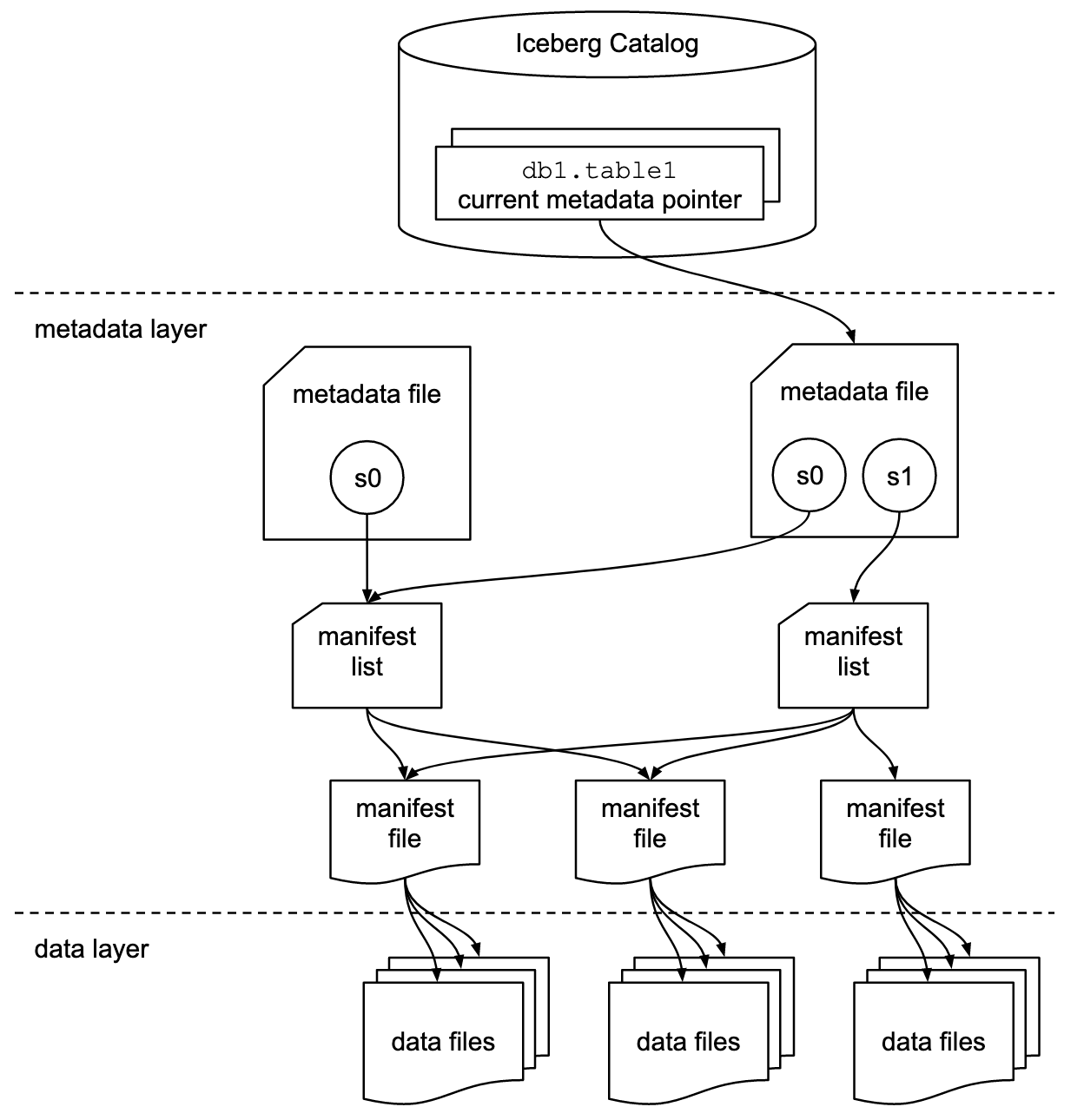
Apache Aceberg Slieles (Источник)
Что такое Пийцберг?
Pyiceberg расширяет возможности аналитики и инженеров данных для создания сложных открытых платформ Lakehouse на широком спектре облаков (AWS, Azure и Google Cloud) и локальное хранилище. Pyiceberg - это реализация Python для доступа к таблицам айсберга. Разработчики, использующие Pyiceberg, могут использовать Pythonic Data Transformations без необходимости запуска высокопрофессиональных двигателей запросов в кластерах Java Virtual Machine (JVM). Pyiceberg использует каталоги для загрузки таблиц айсберга и выполнения операций чтения-Write-Upsert. Он обрабатывает аспекты метаданных и форматов таблицы айсберга, позволяя инженерам -инженерам использовать небольшие, быстрые и высокоэффективные двигатели для передачи данных, такие как Pyarrow (реализация питона стрелки Apache), DAFT или DuckDB в качестве вычислительного уровня для реальной обработки данных.
Pyiceberg может работать в качестве автономной программы или в кластерах Kubernetes для устойчивости к неисправности. Его родная интеграция с протоколами каталога айсберга, такими как Rest, SQLCatalog или AWS -клей, делает его популярным и легким выбором для запроса таблиц айсберга без необходимости кластеров JVM/PY4J.
Развертывания производства Pyiceberg часто интегрируют рабочие нагрузки потоковой передачи данных, такие какНастольный поток, где потоковые данные создаются как темы Apache Kafka и материализуются как таблицы айсберга. Это мощный инструмент для преодоления разрыва между системами эксплуатационных данных и аналитическими системами данных.
Почему Пеййцеберг?
Pyiceberg предоставляет удобный для питона способ запуска языка манипулирования данными (DML) на таблицах айсберга. Для платформ данных малых и средних данных, которые работают со 100-х годов гигабайт данных, таких как те, которые обрабатывают аналитику департамента, внутренняя отчетность или специализированное инструменты,-простота использования часто важнее для предприятий, чем для сложных функций. Если объем данных (как исторический, так и инкрементный) не является огромным, развертывание полноценного кластера для запуска запросов на айсберге может показаться ошеломляющим и излишним. Это связано с тем, что эти двигатели запросов (например, Spark и Flink) полагаются на языки программирования Scala или Java, работающие на виртуальной машине Java (JVM), чтобы навязывать и оптимизировать многопоточную и многоядерную обработку. Для программистов Python это означало использование Py4j, что позволяет программам Python, работающим в интерпретаторе Python для динамического доступа к объектам Java в JVM.
В следующем разделе давайте создадим демонстрацию с Pyiceberg, чтобы понять, как работают шаблоны айсберга чтения и записи.
Как построить данные Lakehouse с Pyiceberg, Pyarrow и DuckDB
Давайте практиковать и построить демонстрацию датчика датчика IoT Lakehouse с Pyiceberg. Для этого примера мы будем использовать Pyiceberg и Pyarrow для внедрения/Upsert и Delete Data Areberg и создать код Visual Studio (VS -код).
Во -первых, создана новая виртуальная среда Python под названием «pyiceberg_playground», выполнив следующую команду:
$>python -m venv iceberg_playground
Затем этот каталог - «Aceberg_playground» - ’открывается в коде VS, где будет размещен проект Pyiceberg. На следующем изображении показан код VS «Чистый сланец».
Паяйсберг и другие библиотеки затем устанавливаются в виртуальной среде, выполняя следующие две команды:
$>source bin/activate
(iceberg_playground)$>pip install pyiceberg daft duckdb sqlalchemy pandas
Для этого примера Pyiceberg будет использовать SQLCatalog, в котором хранится информация о таблице айсберга в локальной базе данных SQLite. Айсберг также поддерживает каталоги, включая Rest, Hive и AWS -клей.
Файл конфигурации .pyiceberg.yaml подготовлен со следующим контентом, на корне проекта:
catalog:
pyarrowtest:
uri: sqlite:///pyiceberg_catalog/pyarrow_catalog.db
warehouse: file:////Users/diptimanraichaudhuri/testing_space/iceberg_playground/dw1
Обратите внимание, как каталог айсберга хранится в каталоге Pyiceberg_catalog в качестве файла SQLite и в хранилище данных, в котором хранятся все данные и метаданные в каталоге DW1.
Оба эти каталога теперь созданы на уровне корневого проекта. Этот каталог назван Pyarrowtest.
Далее, настройка Pyiceberg проверяется с помощью следующего сценария:
import os
from pyiceberg.catalog import load_catalog
os.environ["PYICEBERG_HOME"] = os.getcwd()
catalog = load_catalog(name='pyarrowtest')
print(catalog.properties)
Обратите внимание, как Pyiceberg читает имя каталога из файла YAML и создает локальную базу данных SQLite в каталоге Pyiceberg_Catalog. Поскольку SQLite распространяется с помощью установщиков Python, его не нужно устанавливать отдельно.
Если сценарий запускается должным образом, в терминале должны отображаться свойства «pyarrow_catalog».
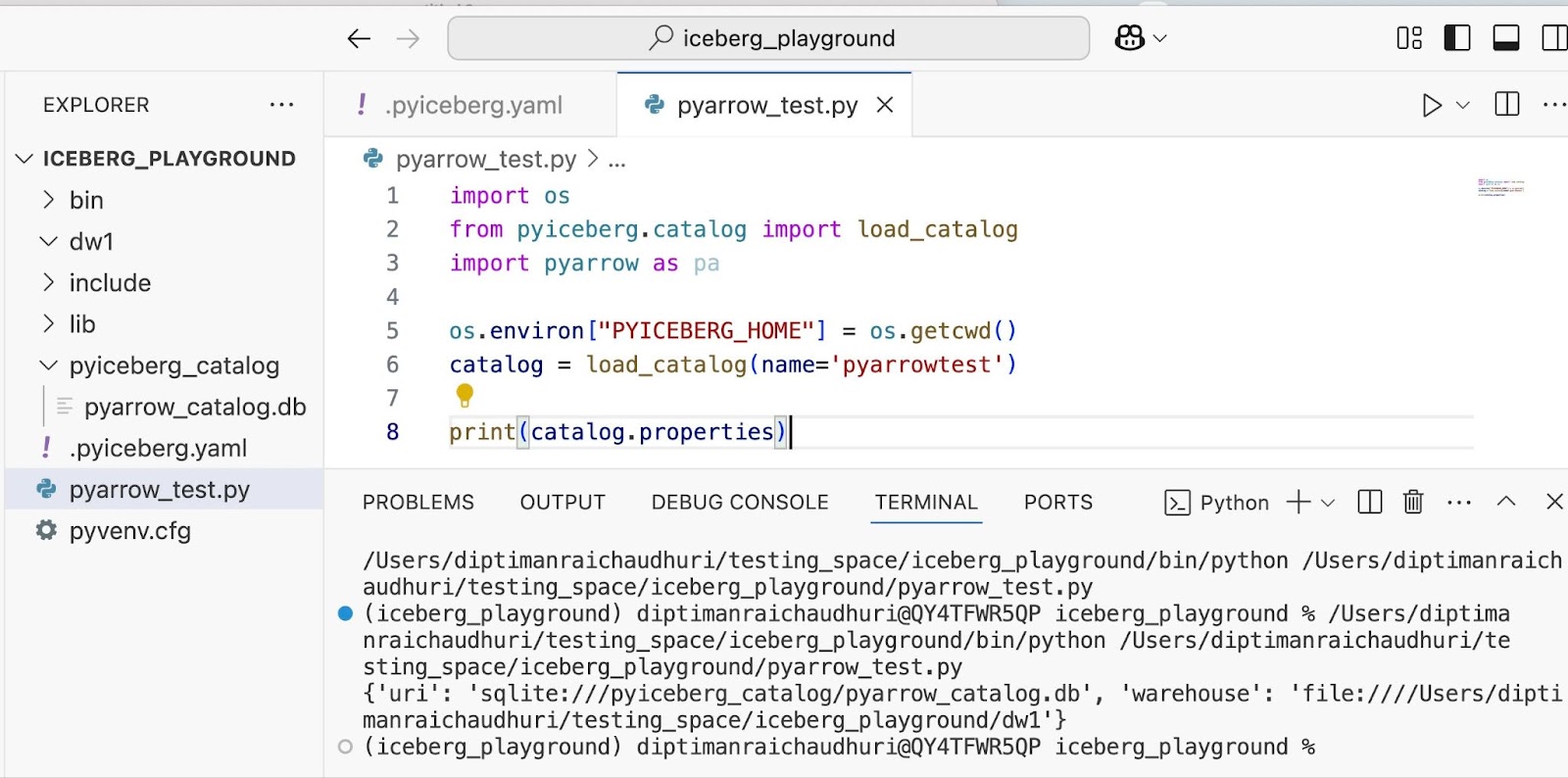
Скрипт загрузил каталог из файла. YAML, поскольку переменная среды Pyicebeg_home ’была указана как корень проекта.
Затем схема добавляется с использованием класса схемы Pyiceberg. Поскольку в этом примере хранится данные из набора датчиков IoT, схема построена с тремя столбцами и их необходимыми типами данных. Field Device_ID было установлено как основной ключ, так и в качестве ключа раздела.
Затем создается пространство имен вместе со столом айсберга со схемой. Пространство имен - это логическая группировка таблиц на складе (помните, как склад уже создается при определении файла YAML).
Начальная нагрузка данных выполняется с использованием списка Pyarrow In-Memory, и Sensor_Table считывается с помощью метода Pyiceberg Scan () для преобразования данных в DataFrame Pandas.
import os
from pyiceberg.catalog import load_catalog
from pyiceberg.schema import Schema
from pyiceberg.types import (NestedField,
StringType, FloatType)
from pyiceberg.partitioning import PartitionSpec, PartitionField
from pyiceberg.transforms import IdentityTransform
import pyarrow as pa
os.environ["PYICEBERG_HOME"] = os.getcwd()
catalog = load_catalog(name='pyarrowtest')
print(catalog.properties)
# Define the schema
schema = Schema(
NestedField(1, "device_id", StringType(), required=True),
NestedField(2, "ampere_hour", FloatType(), required=True),
NestedField(3, "device_make", StringType(), required=True),
identifier_field_ids=[1] # 'device_id' is the primary key
)
# Define the partition spec - device_id as partition key
partition_spec = PartitionSpec(
PartitionField(source_id=1, field_id=1000, transform=IdentityTransform(), name="device_id")
)
# Create a namespace and an iceberg table
catalog.create_namespace_if_not_exists('sensor_ns')
sensor_table = catalog.create_table_if_not_exists(
identifier='sensor_ns.sensor_data',
schema=schema,
partition_spec=partition_spec
)
# Insert initial data
initial_data = pa.table([
pa.array(['b8:27:eb:bf:9d:51', '00:0f:00:70:91:0a', '1c:bf:ce:15:ec:4d']),
pa.array([21.43, 17.86, 31.65]),
pa.array(['ABB', 'Honeywell', 'Siemens'])
], schema=schema.as_arrow())
# Write initial data
sensor_table.overwrite(initial_data)
# Print a Pandas dataframe representation of the table data
print("\nInsert operation completed")
print(sensor_table.scan().to_pandas())
Если вышеупомянутый скрипт выполняется успешно, этот результат отображается в терминале:
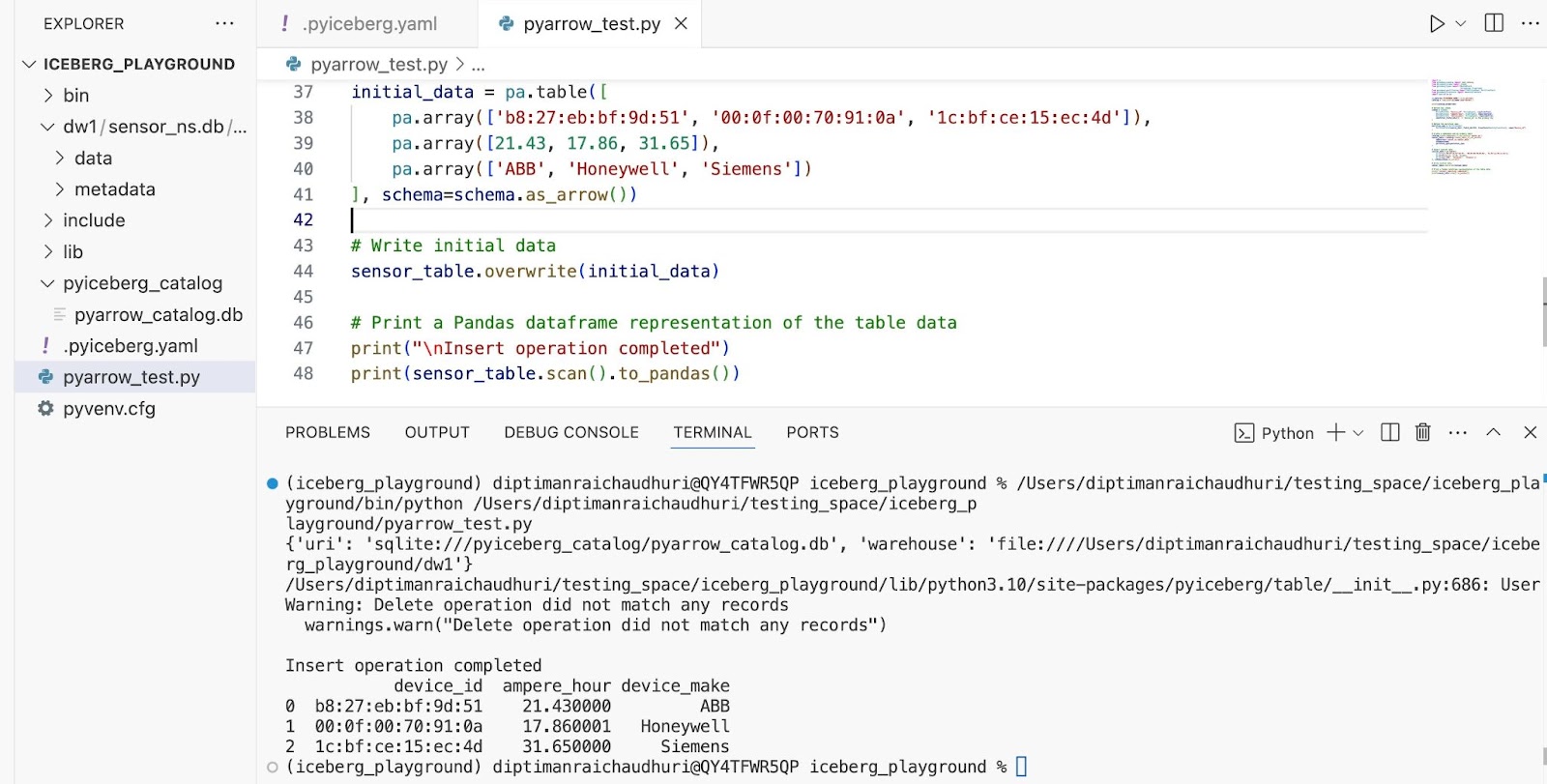
При успешной завершении вставки можно подтвердить три слоя айсберга:
- Каталог: Это файл sqlite pyarrow_catalog.db, который будет проверен чуть позже в этой статье.
- Метаданные: В каталоге «метаданные» создаются файлы метаданных, которые имеют решающее значение для включения операций создания, чтения, обновления, удаления (CRUD). Создаются два файла метаданных JSON, один во время создания таблицы, а другой после первой вставки данных. Файл «Snap-*. Avro» является списком манифестов, а файл Manifest-это другой файл .avro.
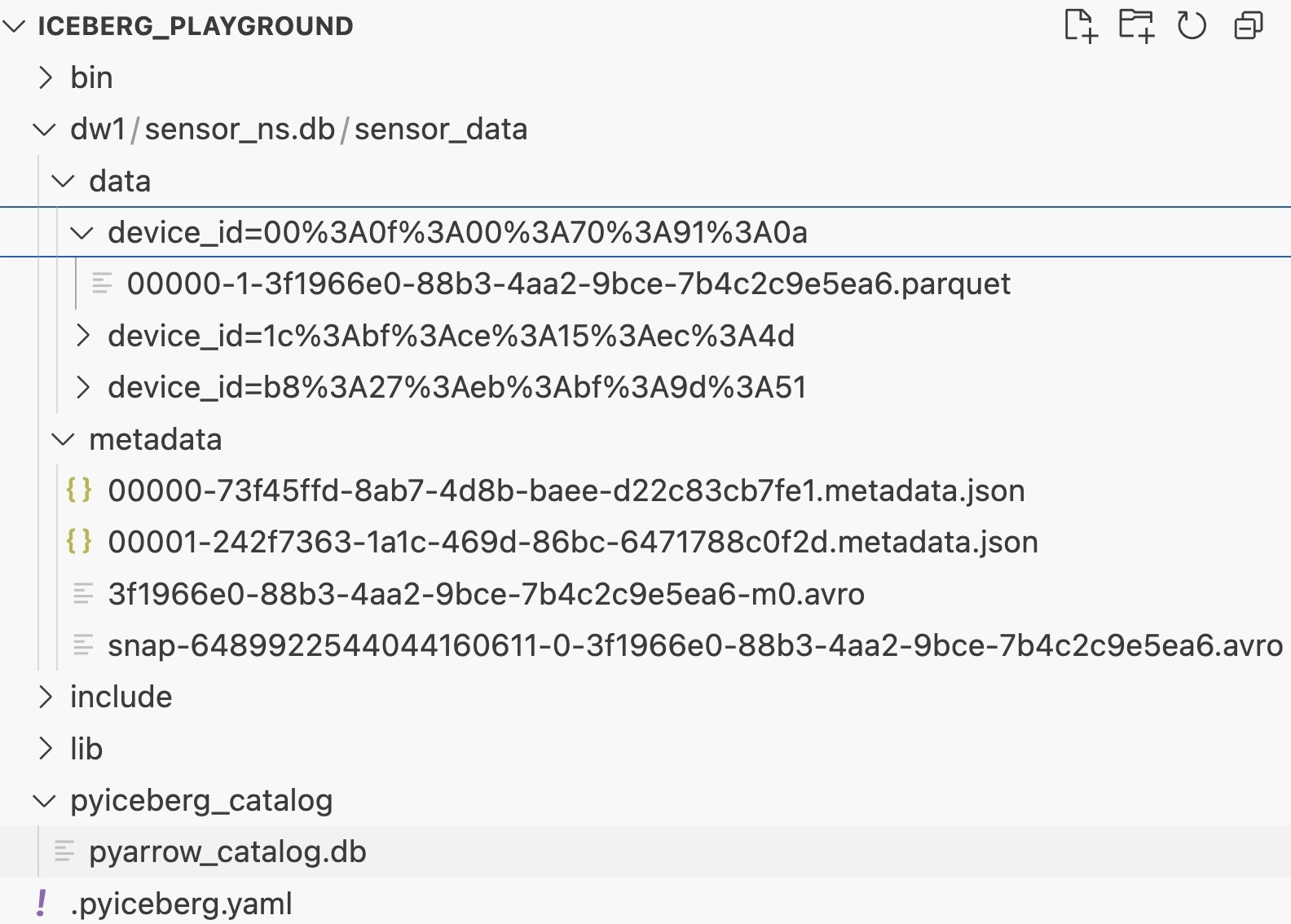
- Данные: Файлы данных записаны в формате .parquet, с Device_id в качестве ключа раздела. Поскольку существует три отдельных устройства, создаются три каталога. Таблица айсберга «Sensor_Data» создается с пространством имен «Sensor_NS.DB» на складе «DW1». Эти поля данных создаются в каталоге «Данные» таблицы «Sensor_Data».
Выражения Pyiceberg могут быть использованы для фильтрации записей. Некоторые из общих выражений, используемых для фильтрации: startswith, evalto, больше, или, или и т. Д.
from pyiceberg.expressions import StartsWith, EqualTo
# Filter columns
print("\nFilter records with device_make == ABB ")
print(sensor_table.scan(row_filter=EqualTo('device_make', 'ABB')).to_pandas())
Pyiceberg также поддерживает операции Upsert. В следующем коде пример обновления существующего device_make для одного из датчиков от «Siemens» до «Kepware».
# Create an UPSERT batch of Arrow records where one fot he device_make is changed
upsert_data = pa.table([
pa.array(['b8:27:eb:bf:9d:51', '00:0f:00:70:91:0a', '1c:bf:ce:15:ec:4d']),
pa.array([21.43, 17.86, 31.65]),
pa.array(['ABB', 'Honeywell', 'Kepware'])
], schema=schema.as_arrow())
# UPSERT changed data
try:
join_columns = ["device_id"]
upsert_result = sensor_table.upsert(upsert_data.select(["device_id", "ampere_hour", "device_make"]))
except Exception as e:
print(e)
print("\nUpsert operation completed")
print(sensor_table.scan().to_pandas())
Аналогичным образом, также поддерживается операция удаления:
# Delete row
sensor_table.delete(delete_filter=EqualTo('device_id', '1c:bf:ce:15:ec:4d'))
print("\n After Delete")
print(sensor_table.scan().to_pandas())
Стоит отметить, что удаление на любом складе является нюансированной операцией, и айсберг не является исключением. Операции на уровне строк в айсберге определяются двумя стратегиями: Copy-on Write (Cow) и Merge-on-read (MOR). Удалить операции также создают файлы удаления для стратегии MOR.
Pyiceberg в настоящее время поддерживает MOR удаляет, но с некоторыми нюансами. В то время как Pyiceberg предлагает возможность удалять строки, он в первую очередь реализует это, используя удаление коров по умолчанию, что означает, что файлы данных переписываются вместо создания удаленных файлов. Тем не менее, ведутся работа по улучшению MOR Pyiceberg для поддержки удаления равенства и сделать ее более эффективным для частых, небольших обновлений.
В качестве последнего шага, давайте использовать DuckDB, чтобы запросить каталог SQLite Aceberg, хранящийся в файле pyarrow_catalog.db. Следующая команда запускается на терминале VS -кода:
duckdb -ui pyiceberg_catalog/pyarrow_catalog.db
Это откроет окно браузера в порту 4213 (по умолчанию), где SQL -запрос можно запускать в каталоге айсберга, как показано:
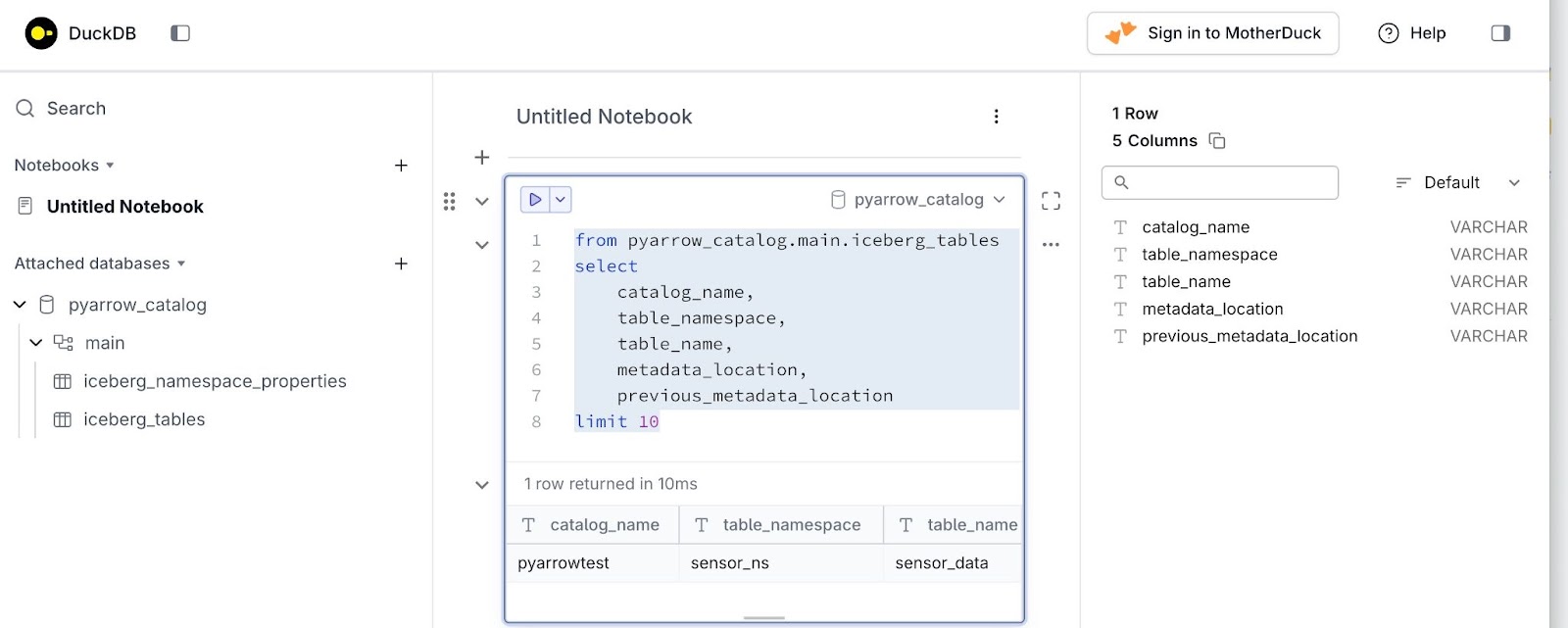
Это обеспечивает простой и простой способ извлечения информации из каталога SQL
Разблокировка данных с Pyiceberg
Для компаний с объемами данных, которые меньше, чем терабайты, Pyiceberg и Pyarrow являются быстрыми вариантами для запуска интерактивных запросов в Python. Использование этой комбинации может значительно сократить время для получения информации о озерных домах малого и среднего.
Инженеры данных могут начать работу сДокументация Pyiceberg, который поддерживается и поддерживается в курсе. ТакжеAPIУ страницы есть отличные примеры всех API Pyiceberg.
Счастливого кодирования!
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)