

Грубный подход к 3D-локализации, управляемой текстами без основной правды
16 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
Связанная работа
Метод
3.1 Обзор нашего метода
3.2 грубое извлечение текстовых клеток
3.3 Оценка прекрасной позиции
3.4 Цели обучения
Эксперименты
4.1 Описание набора данных и 4.2 Подробная информация
4.3 Критерии оценки и 4.4 результаты
Анализ производительности
5.1 Исследование абляции
5.2 Качественный анализ
5.3 Анализ встраивания текста
Заключение и ссылки
Дополнительный материал
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
Анонимные авторы
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
3 Метод
3.1 Обзор нашего метода

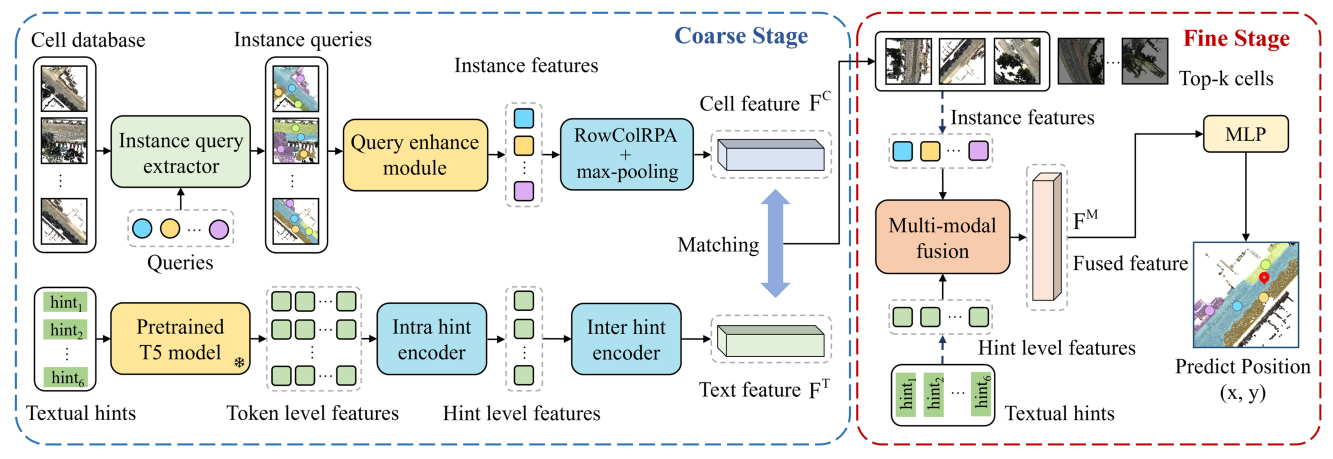
Следуя Text2pos [21], наш метод принимает грубую стратегию, как показано на рис. 2. Во-первых, наши процессы извлечения текстовых клеток точели облака и текстовые сигналы для идентификации соответствующих ячеек, как подробно описано в разделе 3.2. На прекрасной стадии наша модель оценки позиции напрямую предсказывает окончательные координаты целевого местоположения на основе текстовых подсказок и извлеченных ячеек, как описано в разделе 3.3. Примечательно, что этот подход не требует от земли-несущей экземпляры в качестве входных и полностью эксплуатирует пространственные отношения на обоих этапах. Цель обучения описана в разделе 3.4.
3.2 грубое извлечение текстовых клеток
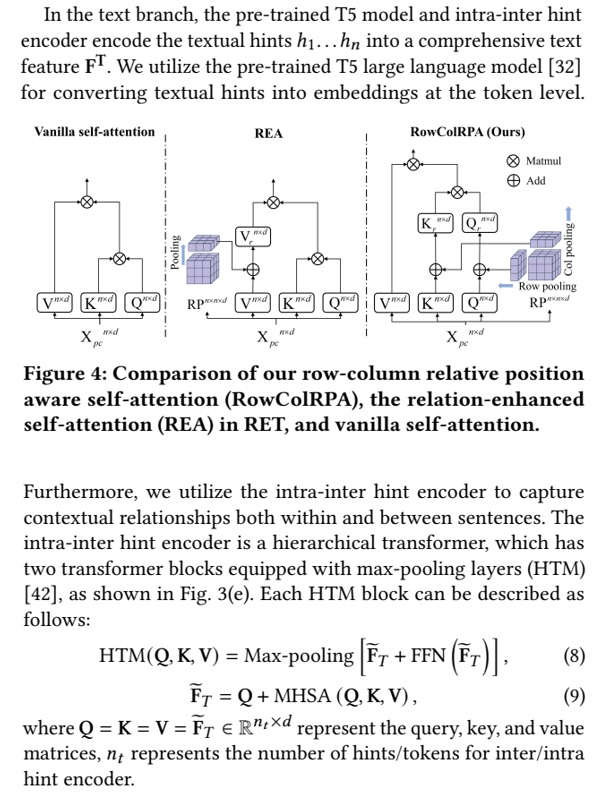
Подобно предыдущим методам [21, 39, 42], мы используем модель двойной ветви для кодирования необработанного облака точек 𝐶 и текстового описания 𝑇 в общее пространство встраивания, как показано в левой части рис. 2. Чтобы непосредственно кодировать облака точечных клеток, наша трехмерная ветвь состоит из трех основных компонентов: экстрактор запроса Query, укрепляющий Query-Some-warulancelpor (Shipraination and undrancement roundrupraintraillpol Модуль с максимальным слоем. Экстракт запроса экземпляра обрабатывает начальные запросы и необработанные облака точек для создания запросов экземпляра и масок экземпляра. Модуль «Усиление запроса» объединяет семантические запросы с соответствующими функциями маски экземпляра для генерации функций экземпляра, как показано на рис. 3 (d). Модуль Rowcolrpa с максимальным слоем, с другой стороны, объединяет эти функции экземпляра, чтобы генерировать функцию ячейки.

В тех случаях, когда FFN (·) является сетью Feed Forward, MHSA (·) является мульти-головным самоуничтожением, MMHCA (·)-это многоголовое перекрестное привлечение в масках. Модуль маски генерирует бинарную маску для каждого запроса, как показано на рис. 3 (б). Этот процесс включает в себя сопоставление запросов экземпляра в то же пространство функций, что и основная функция F0 с использованием многослойного персептрона (MLP). Сходство между этими отображенными запросами экземпляра и F0 вычисляется с помощью точечных продуктов, причем полученные оценки подвергаются сигмоидной функции и последующим пороговым значением при 0,5, чтобы получить бинарные маски экземпляра. Во время запроса после обработки запросы экземпляра фильтруются на основе уверенности в прогнозировании и дополнительно объединяются с характеристиками, полученными из масок экземпляра, что приводит к формированию запросов окончательного экземпляра. Эти запросы экземпляра - это кортежи, которые инкапсулируют исходные запросы, их центральные координаты, номер точки и среднее значение цвета RGB. Общая архитектура и ключевые модули экстрактора запроса экземпляра показаны на рис. 3 (а).



Авторы:
(1) Lichao Wang, FNII, Cuhksz (wanglichao1999@outlook.com);
(2) Zhihao Yuan, FNII и SSE, Cuhksz (zhihaoyuan@link.cuhk.edu.cn);
(3) Jinke Ren, FNII и SSE, Cuhksz (jinkeren@cuhk.edu.cn);
(4) Shuguang Cui, SSE и FNII, Cuhksz (shuguangcui@cuhk.edu.cn);
(5) Чжэнь Ли, автор -соответствующий автор из SSE и FNII, Cuhksz (lizhen@cuhk.edu.cn).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)