

Пристальный взгляд на смещение в предварительных наборах данных
10 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
2 концепции в предварительных данных и количественная частота
3 Сравнение производительности предварительного подготовки и «нулевого выстрела» и 3.1 Экспериментальная установка
3.2
4 Тестирование стресса Концепция тенденции масштабирования частоты и 4.1.
4.2 Тестирование обобщения на чисто синтетическую концепцию и распределения данных
5 Дополнительные идеи от частот концепции предварительного подготовки
6 Проверка хвоста: пусть он виляет!
7 Связанная работа
8 Выводы и открытые проблемы, подтверждения и ссылки
Часть я
Приложение
A. Частота концепции является прогнозирующей производительности в разных стратегиях
B. Частота концепции является прогнозирующей производительности в результате получения метриков извлечения
C. Частота концепции является прогнозирующей производительности для моделей T2I
D. Концепция частота является прогнозирующей производительности в разных концепциях только из изображений и текстовых областей
E. Экспериментальные детали
F. Почему и как мы используем Ram ++?
G. Подробная информация о результатах степени смещения
H. T2I Модели: оценка
I. Результаты классификации: пусть это виляет!
F Почему и как мы используем Ram ++?
Мы подробно описываем, почему мы используем модель RAM ++ [59] вместо Clipscore [56] или моделей обнаружения с открытым вокабуляцией [80]. Кроме того, мы подробно рассказываем о том, как мы выбрали пороговый гиперпараметр, используемый для выявления концепций на изображениях.
F.1 Почему RAM ++, а не клипа или детекторы с открытым вокабуляцией?
Мы приводим несколько качественных примеров, чтобы проиллюстрировать, почему мы выбрали RAM ++. Наши входные изображения не часто связаны с сложными сценами, подходящими для детекторов объектов, но многие мелкозернистые классы, на которых наряду с клипом, даже мощные детекторы открытого мира, такие как OWL-V2 [80], имеют плохую производительность.

F.2 Как: оптимальный порог Ram ++ для расчета частот концепции
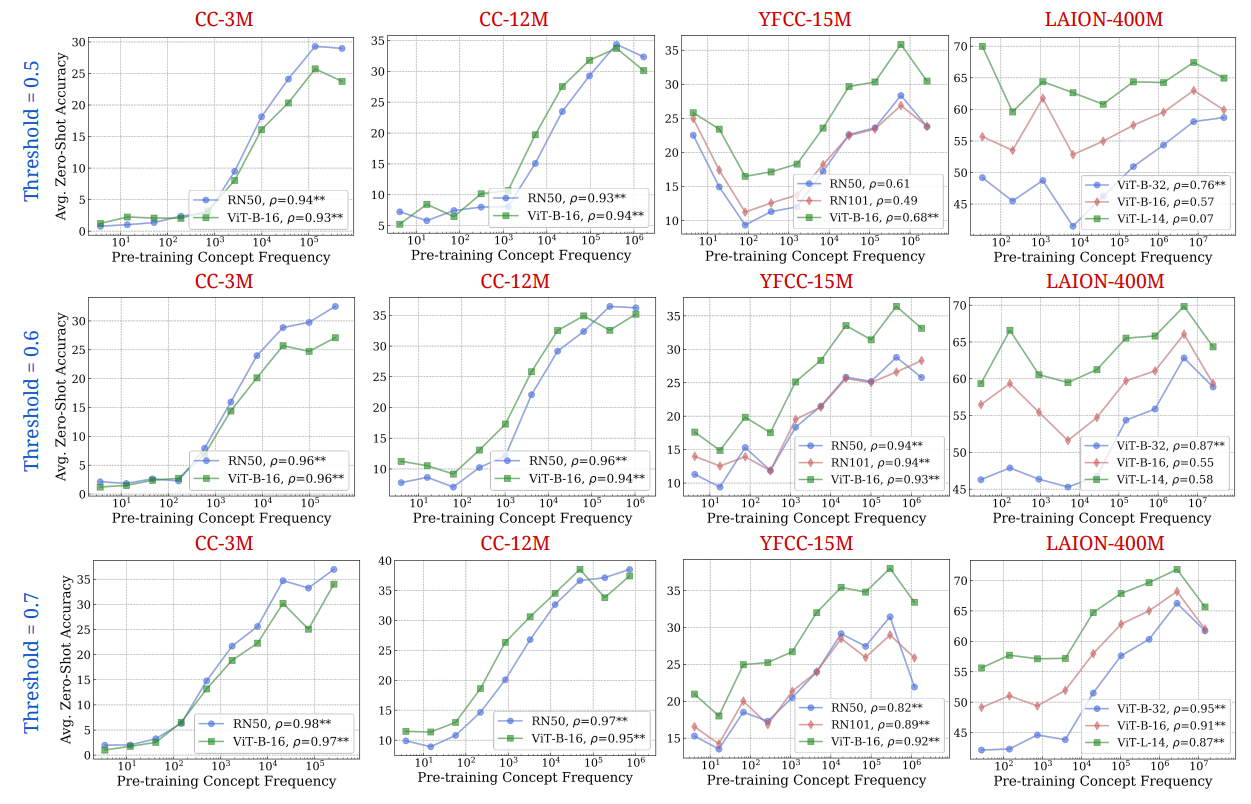
Мы поднимаем выбор порога, который мы используем для назначения концепций изображениям, используя модель RAM ++. Для данного набора концепций RAM ++ предоставляет значение вероятности (путем приема сигмоида над необработанными логитами) для существования каждой концепции на конкретном изображении. Чтобы пометить изображение как содержащую определенную концепцию, мы должны установить порог, определяющий это назначение. Мы проверяем более трех пороговых значений: {0,5, 0,6, 0,7}, демонстрируя количественные и качественные результаты для всех порогов на рис. 20 и 21.
Мы наблюдаем наилучшие результаты оценки частоты с использованием самой высокой частоты 0,7. Это связано с высокой точностью, предоставленной этим порогом, что приводит к тому, что мы считаем только «наиболее выровненными изображениями» на концепцию как хиты. При более низких пороговых значениях (0,5, 0,6) мы отмечаем, что более шумные изображения, которые плохо соответствуют концепции, могут считаться хитами, что приводит к ухудшению точности и тем самым более низкой оценке частоты. Следовательно, мы используем 0,7 в качестве порога для всех наших основных результатов.

G Подробности о результатах степени смещения
В табле. 3 В основной статье мы количественно определили степень смещения и продемонстрировали, что большое количество пар изображений текстовых текстов во всех наборах данных предварительного подготовки искажено. В Alg. 1, мы опишем метод, используемый для количественной оценкиСтепень смещенияДля каждого предварительного набора данных. Мы также демонстрируем несколько качественных примеров нескольких пар изображений текста из набора данных CC-3M, которые идентифицируются как смещенные с использованием нашего анализа.


Авторы:
(1) Вишаал Удандарао, Центр ИИ Тубингена, Университет Табингингена, Кембриджский университет и равный вклад;
(2) Ameya Prabhu, Центр AI Tubingen, Университет Табингинга, Оксфордский университет и равный вклад;
(3) Адхирадж Гош, Центр ИИ Тубинген, Университет Тубингена;
(4) Яш Шарма, Центр ИИ Тубинген, Университет Тубингена;
(5) Филипп Х.С. Торр, Оксфордский университет;
(6) Адель Биби, Оксфордский университет;
(7) Сэмюэль Албани, Кембриджский университет и равные консультирование, приказ, определенный с помощью монеты;
(8) Матиас Бетге, Центр ИИ Тубинген, Университет Тубингена и равные консультирование, Орден определяется с помощью переворачивания монеты.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)