

10-минутный глубокий обзор базовой архитектуры Apache SeaTunnel и DataX
3 сентября 2024 г.Введение
В этой статье в первую очередь обобщается архитектура и поток кода DataX и SeaTunnel, что поможет читателям легче понять исходный код.
DataX
Давайте сначала получим общее представление о DataX:
GitHub:https://github.com/alibaba/DataX
Архитектура DataX
Основная архитектура DataX спроектирована следующим образом:
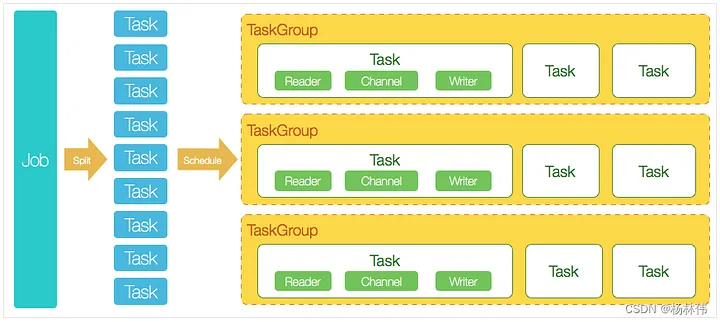
Чтобы понять приведенную выше схему, рассмотрим простой пример: пользователь отправляет задание DataX и настраивает 20 параллельных задач для синхронизации данных из 100 таблиц, разбитых на сегменты MySQL, в ODPS.
Процесс принятия решения о планировании DataX выглядит следующим образом:
- Шаг 1: DataXJob разделяет 100 задач на основе сегментированных таблиц;
- Шаг 2: На основе 20 одновременных задач DataX вычисляет, что необходимо выделить 4 TaskGroups;
- Шаг 3: 4 группы задач равномерно распределяют 100 задач, каждая группа задач обрабатывает 25 задач в 5 параллельных потоках.
В процессе выполнения кода DataX есть несколько ключевых классов, и их обязанности следующие (нажмите на класс, чтобы просмотреть исходный код):
ClassResponsibilityJobContainerTask containerReaderReader plugin interfaceWriterWriter plugin interfaceJobAssignUtilTask assignment utility classAbstractSchedulerTask scheduler abstract classTaskGroupContainerTask group container
Проблемы с DataX
Сначала давайте обобщим преимущества DataX, к которым относятся следующие:
- Надежный мониторинг качества данных: например, мониторинг трафика, объема данных во время выполнения и обнаружение «грязных» данных;
- Широкие возможности преобразования данных: позволяют легко анонимизировать, дополнять, фильтровать данные и т. д. во время передачи;
- Точный контроль скорости: возможность управления скоростью выполнения заданий для достижения наилучшей скорости синхронизации в пределах емкости базы данных;
Однако версия DataX с открытым исходным кодом имеет ряд серьезных недостатков, таких как:
- Он не поддерживает кластеризацию и поддерживает только многопоточный режим на одной машине для выполнения задач синхронизации.
- Он не поддерживает обработку в реальном времени, например, источники данных в реальном времени, такие как Kafka, и компоненты в экосистеме больших данных, такие как Flink.
На данный момент появление Apache SeaTunnel, похоже, заполняет пробелы, оставленные DataX.
Apache SeaTunnel
Давайте получим общее представление о SeaTunnel в его репозитории GitHub:https://github.com/apache/seaтуннель
Apache SeaTunnel позиционирует себя как высокопроизводительную, распределенную, масштабную интеграционную среду следующего поколения.
Хорошо, давайте продолжим рассматривать его соответствующие функциональные особенности.
Архитектура морского туннеля
Это краткая схема архитектуры дизайна продукта с официального сайта Apache SeaTunnel:
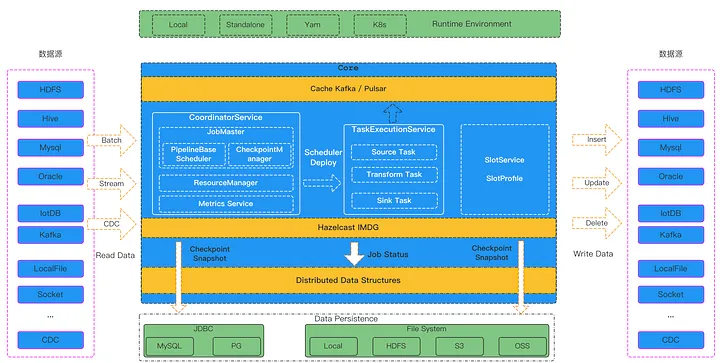
Я считаю, что разработанный мной самостоятельно движок SeaTunnel является ядром всего SeaTunnel, состоящего из трех основных служб (кликните по имени класса, чтобы просмотреть соответствующий исходный код):
ClassResponsibilityCoordinatorServiceMaster служба, отвечающая за генерацию DAG, управление процессом контрольных точек, управление ресурсами, статистику и агрегацию метрик заданий. TaskExecutionServiceWorker служба, фактическая среда выполнения для каждой задачи в jobSlotService Запускается на каждом узле кластера, в основном отвечает за разделение, распределение и восстановление ресурсов на узле.
Поток выполнения кода SeaTunnel
Что касается архитектуры или потока выполнения кода SeaTunnel, то на официальном сайте, похоже, не представлена соответствующая схема проектирования потока.
Чтобы лучше понять процесс, я нарисую схему, показывающую поток выполнения кода SeaTunnel:
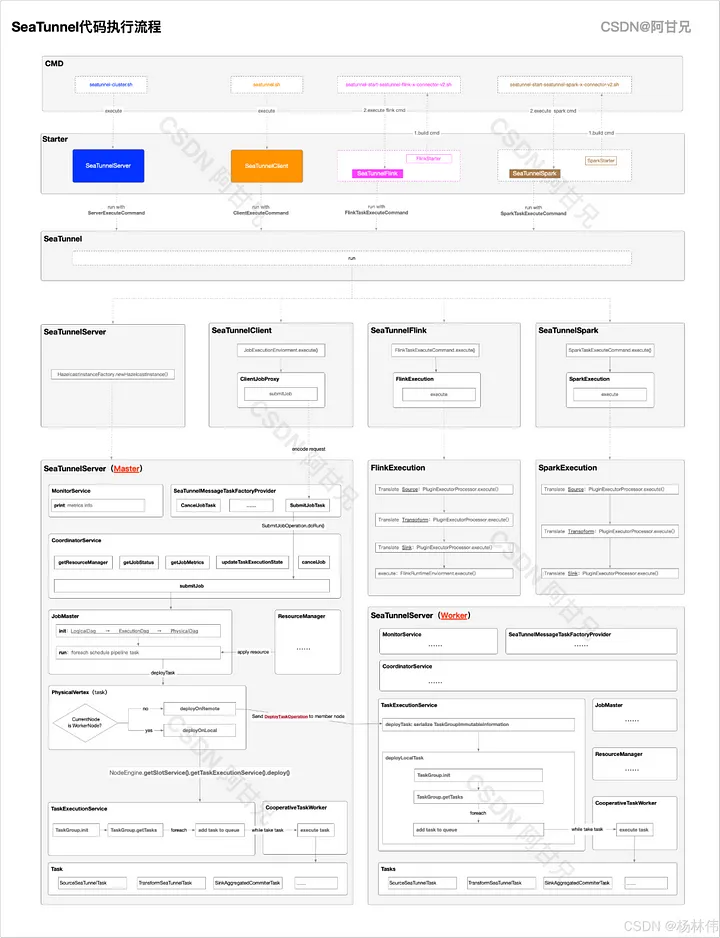
На уровне команд CMD (точка входа) следующие команды в основном делятся на:
- seatunnel-cluster.sh: в основном используется для запуска кластера SeaTunnel;
- seatunnel.sh: клиент SeaTunnel, в основном используемый для отправки заданий в кластер SeaTunnel или остановки выполнения заданий в кластере;
- seatunnel-start-seatunnel-flink-x-connector-v2.sh: в основном используется для отправки заданий в кластер Flink (обратите внимание, что сценарий выполнения использует
evalкоманда для выполнения команды скрипта flink, выведенной из консоли FlinkStarter); - seatunnel-start-seatunnel-spark-x-connector-v2.sh: в основном используется для отправки заданий в кластер Spark (обратите внимание, что сценарий выполнения использует
evalкоманда для выполнения команды скрипта Spark, выведенной из консоли SparkStarter).
Механизм исполнения, поддерживаемый SeaTunnel, включает:
EngineCore ClassDescriptionSeaTunnel (Zeta) РекомендуетсяSeaTunnelServerРазделенный на Master и Worker, Master в основном отвечает за генерацию DAG заданий, управление ресурсами, метрики и т. д.
Worker в основном выполняет определенные узлы задач, и каждый Worker определяет, выполнять ли его, на основе того, является ли IP-адрес SlotProfile локальным адресом (в частности, вorg.apache.seatunnel.engine.server.dag.physical.PhysicalVertex#deploy)FlinkSeaTunnelFlinkThePluginExecutorProcessorтипы делятся на Source, Sink и Transform, в основном используются для перевода конфигурации SeaTunnel в конфигурацию, распознаваемую Flink, и, наконец, используют FlinkTableEnvironmentдля выполнения задач ETLSparkSeaTunnelSparkПодобно логике выполнения движка Flink,PluginExecutorProcessorтипы делятся на Источник, Приемник, Преобразование и, наконец, переведенные и выполненные задачи ETL
Заключение
До сих пор в этой статье было представлено обзорное сравнение архитектуры и потока кода DataX и SeaTunnel.
Эта статья показывает только мое понимание этих двух продуктов после прочтения их исходного кода. Могут быть ограничения или недостатки, и читатели могут оставлять комментарии, чтобы указать на них. Надеюсь, эта статья будет вам полезна.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27116)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)