Давайте узнаем о инженерии данных из этих 96 бесплатных историй. Они упорядочены по времени чтения, созданного на HackerNoon. Посетите /Learn Repo, чтобы найти самые читаемые истории о любой технологии.
1. Как повысить скорость запросов, чтобы максимально эффективно использовать ваши данные
 В этой статье я расскажу о том, как мне удалось повысить общую эффективность обработки данных за счет оптимизации выбора и использования хранилищ данных.
В этой статье я расскажу о том, как мне удалось повысить общую эффективность обработки данных за счет оптимизации выбора и использования хранилищ данных.
2. Введение в карьеру специалиста по обработке данных
 Ценным преимуществом для всех, кто хочет освоить область инженерии данных, является понимание различных типов данных и конвейера данных.
Ценным преимуществом для всех, кто хочет освоить область инженерии данных, является понимание различных типов данных и конвейера данных.
3. Знакомьтесь: предприниматель: Алон Лев, генеральный директор Qwak
 Знакомьтесь: предприниматель: Алон Лев, генеральный директор Qwak
Знакомьтесь: предприниматель: Алон Лев, генеральный директор Qwak
4. Облачные сервисы захватят мир, говорит Вероника, кандидат от Noonies и преподаватель Python
 Генеральное интервью номинанта Noonies 2021 с Вероникой. Узнайте больше об облачных сервисах, разработке данных и Python.
Генеральное интервью номинанта Noonies 2021 с Вероникой. Узнайте больше об облачных сервисах, разработке данных и Python.
5. Введение в «Большие надежды», инструмент для анализа данных с открытым исходным кодом
 Это первый завершенный вебинар из серии «Большие надежды 101». Цель этого вебинара – показать вам, что нужно для успешного развертывания и запуска Great Expectations.
Это первый завершенный вебинар из серии «Большие надежды 101». Цель этого вебинара – показать вам, что нужно для успешного развертывания и запуска Great Expectations.
6. Инструменты обработки данных для геопространственных данных
 Информация о местоположении делает область геопространственной аналитики такой популярной сегодня. Для сбора полезных данных требуются уникальные инструменты, о которых рассказывается в этом блоге.
Информация о местоположении делает область геопространственной аналитики такой популярной сегодня. Для сбора полезных данных требуются уникальные инструменты, о которых рассказывается в этом блоге.
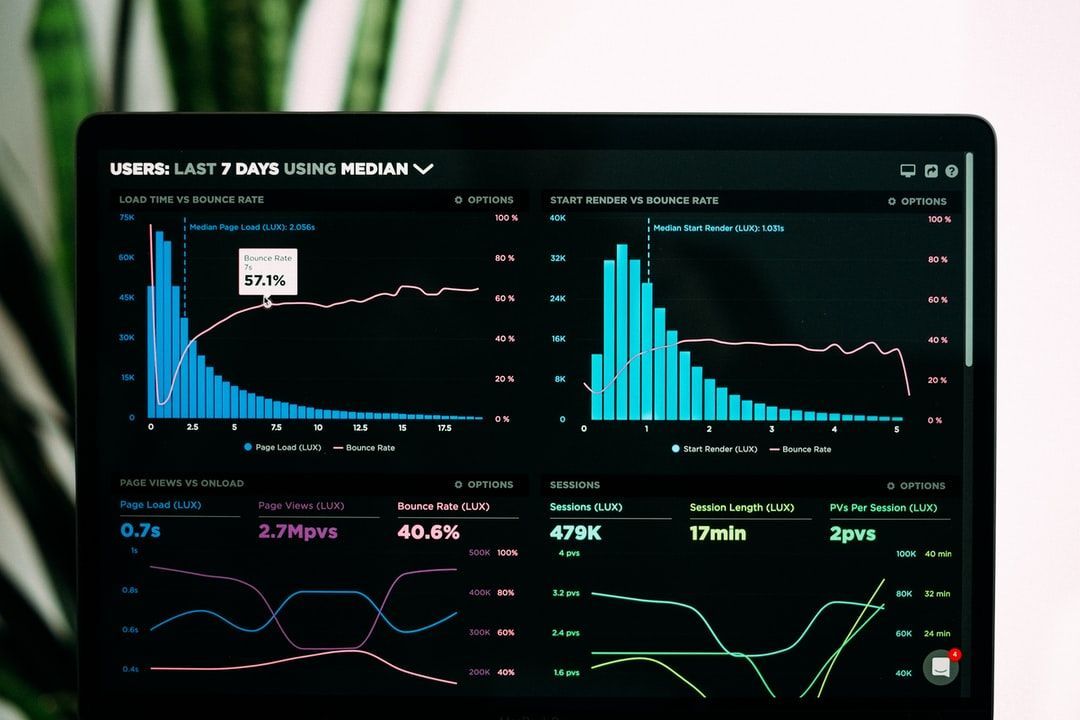
7. Лучшие виды визуализации данных
 Изучение лучших инструментов визуализации данных может стать первым шагом на пути использования анализа данных в ваших интересах и на благо вашей компании.
Изучение лучших инструментов визуализации данных может стать первым шагом на пути использования анализа данных в ваших интересах и на благо вашей компании.
8. Экономичное хранение данных: дельта-представление и секционированная необработанная таблица
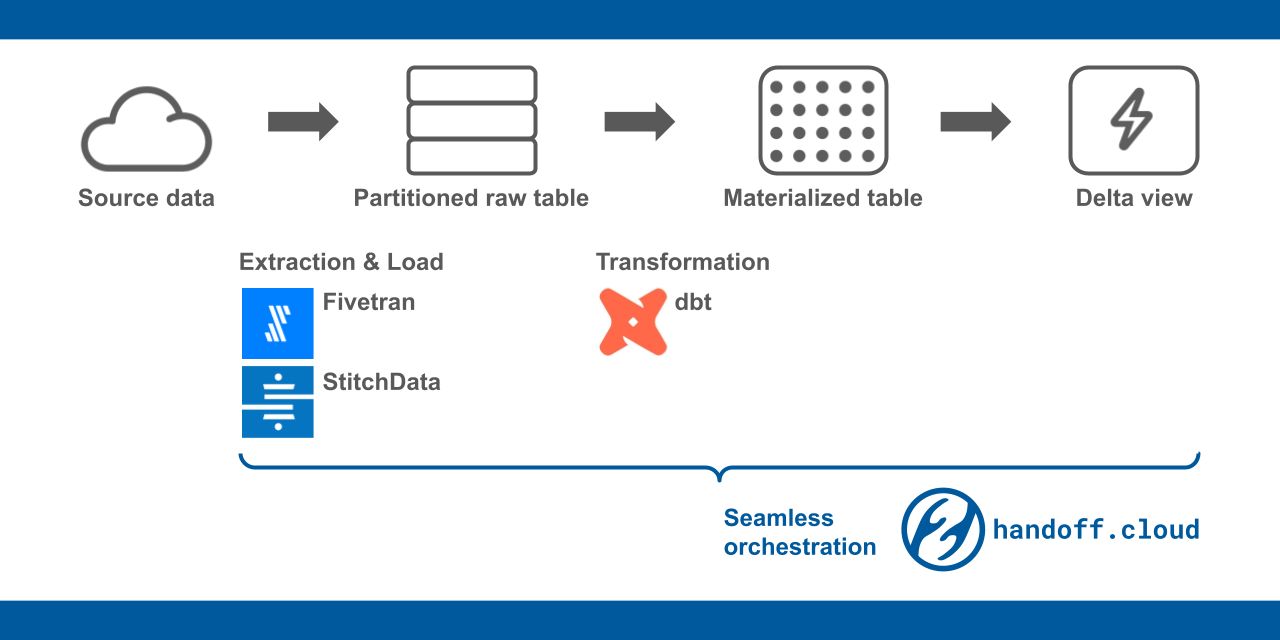 Худший кошмар менеджеров по аналитике — это случайное завышение стоимости хранилища данных. Как избежать получения неожиданно дорогих счетов?
Худший кошмар менеджеров по аналитике — это случайное завышение стоимости хранилища данных. Как избежать получения неожиданно дорогих счетов?
9. Конкурс писателей по маркетингу роста от mParticle и HackerNoon
 mParticle & HackerNoon с радостью проводит конкурс сочинений по маркетингу роста. У вас есть шанс выиграть деньги из колоссального призового фонда в 12 000 долларов!
mParticle & HackerNoon с радостью проводит конкурс сочинений по маркетингу роста. У вас есть шанс выиграть деньги из колоссального призового фонда в 12 000 долларов!
10. Каково будущее инженера данных? – 6 драйверов отрасли
 Является ли дата-инженер по-прежнему «худшим местом за столом»? Выступает Максим Бошемен, создатель Apache Airflow и Apache Superset.
Является ли дата-инженер по-прежнему «худшим местом за столом»? Выступает Максим Бошемен, создатель Apache Airflow и Apache Superset.
11. Почему бизнесу необходимо управление данными
 Управление – это гордиев узел всех проблем вашего бизнеса.
Управление – это гордиев узел всех проблем вашего бизнеса.
12. Руководство по реализации плана передачи данных mParticle в приложении электронной коммерции
 Просматривайте события и атрибуты данных mParticle, отображаемые в пользовательском интерфейсе электронной коммерции, и экспериментируйте с реализацией плана данных mParticle самостоятельно.
Просматривайте события и атрибуты данных mParticle, отображаемые в пользовательском интерфейсе электронной коммерции, и экспериментируйте с реализацией плана данных mParticle самостоятельно.
13. Шесть привычек, которые помогут получать высокоэффективные данные
 Поставьте свою организацию на путь стабильного качества данных, внедрив эти шесть принципов высокоэффективной работы с данными.
Поставьте свою организацию на путь стабильного качества данных, внедрив эти шесть принципов высокоэффективной работы с данными.
14. 5 способов стать лидером, которые понравятся инженерам данных
 Как стать лучшим лидером в области обработки данных, который понравится инженерам данных?
Как стать лучшим лидером в области обработки данных, который понравится инженерам данных?
15. На пути к открытым цепочкам опционов. Часть III. Начало работы с Airflow
 В статье «На пути к открытым цепочкам опционов» Крис Чоу представляет свое решение для сбора данных об опционах: конвейер данных с Airflow, PostgreSQL и Docker.
В статье «На пути к открытым цепочкам опционов» Крис Чоу представляет свое решение для сбора данных об опционах: конвейер данных с Airflow, PostgreSQL и Docker.
16. Обработка больших наборов данных стала быстрой и простой: библиотека Polars
 Обработка больших данных, например. Очистка, агрегирование или фильтрация выполняются невероятно быстро с помощью библиотеки фреймов данных Polars на Python благодаря ее дизайну.
Обработка больших данных, например. Очистка, агрегирование или фильтрация выполняются невероятно быстро с помощью библиотеки фреймов данных Polars на Python благодаря ее дизайну.
17. Сертифицируйте свои ресурсы данных, чтобы не относиться к инженерам данных как к каталогам
 Доверие к данным начинается и заканчивается общением. Вот как лучшие в своем классе команды по работе с данными сертифицируют таблицы, одобренные для использования в их организации.
Доверие к данным начинается и заканчивается общением. Вот как лучшие в своем классе команды по работе с данными сертифицируют таблицы, одобренные для использования в их организации.
18. Наблюдение за данными, подходящее для структуры любой группы обработки данных
 Команды обработки данных бывают самых разных форм и размеров. Как вы встраиваете возможность наблюдения за данными в свой конвейер таким образом, чтобы это соответствовало структуре вашей команды? Читайте дальше.
Команды обработки данных бывают самых разных форм и размеров. Как вы встраиваете возможность наблюдения за данными в свой конвейер таким образом, чтобы это соответствовало структуре вашей команды? Читайте дальше.
19. Обслуживание структурированных данных в Alluxio: пример

20. Решение вопросов на собеседовании с аналитиком данных Noom
 Нум помогает вам похудеть. Мы поможем вам получить работу в Noom. В сегодняшней статье мы покажем вам один из сложных вопросов Noom на собеседовании по SQL.
Нум помогает вам похудеть. Мы поможем вам получить работу в Noom. В сегодняшней статье мы покажем вам один из сложных вопросов Noom на собеседовании по SQL.
21. Что такое инженер по надежности данных?
 С каждым днем предприятия все больше полагаются на данные для принятия решений.
С каждым днем предприятия все больше полагаются на данные для принятия решений.
22. Как создать проект обработки данных Python с помощью шаблона конвейера
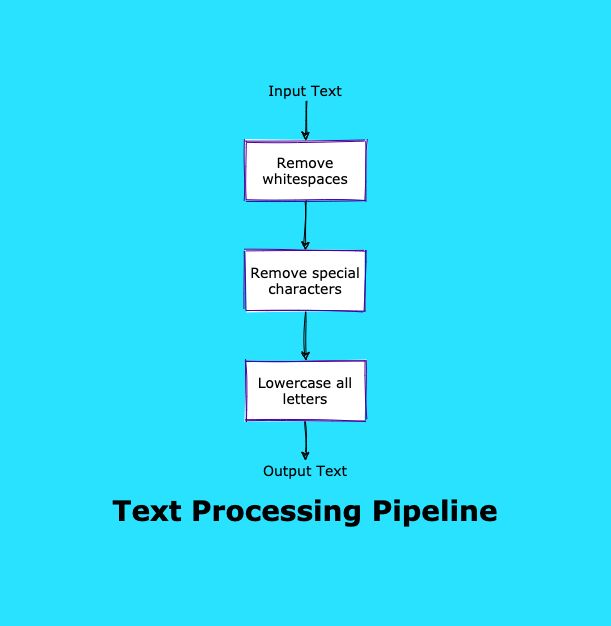 В этой статье мы расскажем, как использовать шаблоны конвейеров в проектах разработки данных Python. Создайте функциональный конвейер, установите fastcore и выполните другие действия.
В этой статье мы расскажем, как использовать шаблоны конвейеров в проектах разработки данных Python. Создайте функциональный конвейер, установите fastcore и выполните другие действия.
23. Обслуживание структурированных данных в Alluxio: пример

24. Как создать действительно работающие алгоритмы машинного обучения
 Масштабное применение моделей машинного обучения в производстве может оказаться затруднительным. Вот четыре самые большие проблемы, с которыми сталкиваются команды по работе с данными, и способы их решения.
Масштабное применение моделей машинного обучения в производстве может оказаться затруднительным. Вот четыре самые большие проблемы, с которыми сталкиваются команды по работе с данными, и способы их решения.
25. Могут ли данные вашей организации когда-либо быть самообслуживаемыми?
 Системы самообслуживания являются большим приоритетом для лидеров данных, но что именно это означает? И неужели от этого больше хлопот, чем пользы?
Системы самообслуживания являются большим приоритетом для лидеров данных, но что именно это означает? И неужели от этого больше хлопот, чем пользы?
26. Как мы используем dbt (клиент) в нашей команде по работе с данными
 На самом деле это не статья, а несколько заметок о том, как мы используем dbt в нашей команде.
На самом деле это не статья, а несколько заметок о том, как мы используем dbt в нашей команде.
27. Сокращение стандартного времени расчета аудитории на 80 %.
 Стандартные аудитории: продукт, расширяющий функциональность обычных аудиторий, один из самых гибких, мощных и эффективных инструментов mParticle.
Стандартные аудитории: продукт, расширяющий функциональность обычных аудиторий, один из самых гибких, мощных и эффективных инструментов mParticle.
28. Smartype Hubs: синхронизация разработчиков с вашим тарифным планом
 Внедрение кода отслеживания на основе устаревшей версии тарифного плана вашей организации может привести к трудоемкой отладке, загрязнению конвейеров данных и
Внедрение кода отслеживания на основе устаревшей версии тарифного плана вашей организации может привести к трудоемкой отладке, загрязнению конвейеров данных и
29 . 80 % проблем не удается выявить только с помощью тестирования: повысьте надежность данных, чтобы сократить время простоя
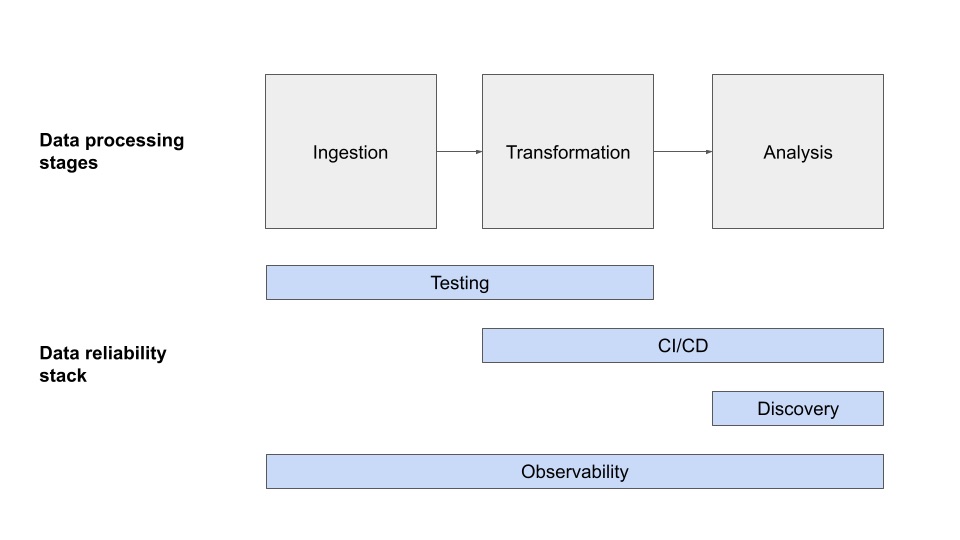 Поговорив с сотнями команд, я обнаружил, что около 80% проблем с данными не решаются одним лишь тестированием. Вот четыре уровня построения стека надежности данных.
Поговорив с сотнями команд, я обнаружил, что около 80% проблем с данными не решаются одним лишь тестированием. Вот четыре уровня построения стека надежности данных.
30. Как извлечь наборы данных НЛП с YouTube
 Лень самому парсить данные nlp? В этом посте я покажу вам быстрый способ парсинга наборов данных НЛП с помощью Youtube и Python.
Лень самому парсить данные nlp? В этом посте я покажу вам быстрый способ парсинга наборов данных НЛП с помощью Youtube и Python.
31. Знакомство с Amazon SageMaker
 Стек Amazon AI/ML
Стек Amazon AI/ML
32. Краткое введение в 5 прогнозных моделей в науке о данных
 Прогнозное моделирование в науке о данных больше похоже на ответ на вопрос «Что произойдет в будущем на основе известного поведения в прошлом?»
Прогнозное моделирование в науке о данных больше похоже на ответ на вопрос «Что произойдет в будущем на основе известного поведения в прошлом?»
33. Совет по инженерии данных: использование CDP для упрощения сбора данных
 Платформы данных клиентов (CDP) имеют огромную ценность для инженеров: от упрощения сбора данных до возможности разработки функций на основе данных.
Платформы данных клиентов (CDP) имеют огромную ценность для инженеров: от упрощения сбора данных до возможности разработки функций на основе данных.
34. Написание Pandas для масштабирования кода Python
 Создавайте эффективные и гибкие конвейеры данных на Python, которые адаптируются к меняющимся требованиям.
Создавайте эффективные и гибкие конвейеры данных на Python, которые адаптируются к меняющимся требованиям.
35. На пути к открытым цепочкам опционов. Часть V: Контейнеризация конвейера
 В статье «На пути к открытым цепочкам опционов» Крис Чоу представляет свое решение для сбора данных об опционах: конвейер данных с Airflow, PostgreSQL и Docker.
В статье «На пути к открытым цепочкам опционов» Крис Чоу представляет свое решение для сбора данных об опционах: конвейер данных с Airflow, PostgreSQL и Docker.
36. Apache Airflow: хороший ли это инструмент для проверки качества данных?
 Узнайте, как поток воздуха влияет на проверку качества данных и почему вам следует искать альтернативный инструмент решения
Узнайте, как поток воздуха влияет на проверку качества данных и почему вам следует искать альтернативный инструмент решения
37. 5 самых важных советов, которые должен знать каждый аналитик данных
 5 вещей, которые должен знать каждый аналитик данных, и почему это не Python и не SQL
5 вещей, которые должен знать каждый аналитик данных, и почему это не Python и не SQL
38. Нейронная пространственно-временная обработка сигналов машинного обучения с помощью PyTorch Geometric Temporal
 PyTorch Geometric Temporal — это библиотека глубокого обучения для нейронной обработки пространственно-временных сигналов.
PyTorch Geometric Temporal — это библиотека глубокого обучения для нейронной обработки пространственно-временных сигналов.
39. Как Datadog выявила скрытые проблемы с производительностью AWS
 Миграция с Convox на Nomad и некоторые проблемы с производительностью AWS, с которыми мы столкнулись на этом пути благодаря Datadog
Миграция с Convox на Nomad и некоторые проблемы с производительностью AWS, с которыми мы столкнулись на этом пути благодаря Datadog
40. Создание крупномасштабной интерактивной системы SQL-запросов с помощью программного обеспечения с открытым исходным кодом
 Это результат сотрудничества команды Баолуна Мао из JD.com и моей команды из Alluxio. Оригинал статьи был опубликован в блоге Аллюксио. В этой статье описывается, как компания JD создала интерактивную платформу OLAP, объединив две технологии с открытым исходным кодом: Presto и Alluxio.
Это результат сотрудничества команды Баолуна Мао из JD.com и моей команды из Alluxio. Оригинал статьи был опубликован в блоге Аллюксио. В этой статье описывается, как компания JD создала интерактивную платформу OLAP, объединив две технологии с открытым исходным кодом: Presto и Alluxio.
41. Как построить направленный ациклический граф (DAG) – на пути к открытым цепочкам опционов, часть IV
 В статье «На пути к открытым цепочкам опционов» Крис Чоу представляет свое решение для сбора данных об опционах: конвейер данных с Airflow, PostgreSQL и Docker.
В статье «На пути к открытым цепочкам опционов» Крис Чоу представляет свое решение для сбора данных об опционах: конвейер данных с Airflow, PostgreSQL и Docker.
42. Понимание различий между наукой о данных и инженерией данных
 Краткое описание разницы между наукой о данных и инженерией данных.
Краткое описание разницы между наукой о данных и инженерией данных.
43. Командам по обработке данных нужны лучшие ключевые показатели эффективности. Вот как.
 Вот шесть важных шагов для постановки целей группам обработки данных.
Вот шесть важных шагов для постановки целей группам обработки данных.
44. Как настроить команду обработки данных вашей организации для достижения успеха
 Лучшие практики по созданию команды по работе с данными в быстрорастущем стартапе: от найма первого инженера по обработке данных до IPO.
Лучшие практики по созданию команды по работе с данными в быстрорастущем стартапе: от найма первого инженера по обработке данных до IPO.
45. Как растут DAG: когда люди доверяют источнику данных, они будут спрашивать больше
 Этот пост в блоге представляет собой обновленную версию выступления, которое мы с Джеймсом провели на Strata еще в 2017 году. Зачем повторять выступление на конференции трехлетней давности? Что ж, основные идеи уже давно устарели, мы никогда раньше не воплощали их в письменной форме, и за это время мы узнали кое-что новое. Наслаждайтесь!
Этот пост в блоге представляет собой обновленную версию выступления, которое мы с Джеймсом провели на Strata еще в 2017 году. Зачем повторять выступление на конференции трехлетней давности? Что ж, основные идеи уже давно устарели, мы никогда раньше не воплощали их в письменной форме, и за это время мы узнали кое-что новое. Наслаждайтесь!
46. Хотите создать автоматические выключатели данных с помощью Airflow? Вот как!
 Узнайте, как использовать Airflow ShortCircuitOperator для создания автоматических выключателей данных, чтобы предотвратить попадание неверных данных в ваши конвейеры данных.
Узнайте, как использовать Airflow ShortCircuitOperator для создания автоматических выключателей данных, чтобы предотвратить попадание неверных данных в ваши конвейеры данных.
47. На пути к открытым цепочкам опционов. Часть II: Основополагающий код ETL
 В статье «На пути к открытым цепочкам опционов» Крис Чоу представляет свое решение для сбора данных об опционах: конвейер данных с Airflow, PostgreSQL и Docker.
В статье «На пути к открытым цепочкам опционов» Крис Чоу представляет свое решение для сбора данных об опционах: конвейер данных с Airflow, PostgreSQL и Docker.
48. Запуск Presto Engine в гибридной облачной архитектуре
 Миграция рабочих нагрузок Presto из полностью локальной среды в облачную инфраструктуру имеет множество преимуществ, включая уменьшение конфликтов за ресурсы и сокращение затрат за счет оплаты вычислительных ресурсов по требованию. В случае Presto, работающего с данными, хранящимися в HDFS, разделение вычислений в облаке и локальном хранилище очевидно, поскольку архитектура Presto позволяет компонентам хранения и вычислений работать независимо. Критической проблемой в этой гибридной среде Presto в облаке, получающей данные HDFS из локальной среды, является задержка в сети между двумя кластерами.
Миграция рабочих нагрузок Presto из полностью локальной среды в облачную инфраструктуру имеет множество преимуществ, включая уменьшение конфликтов за ресурсы и сокращение затрат за счет оплаты вычислительных ресурсов по требованию. В случае Presto, работающего с данными, хранящимися в HDFS, разделение вычислений в облаке и локальном хранилище очевидно, поскольку архитектура Presto позволяет компонентам хранения и вычислений работать независимо. Критической проблемой в этой гибридной среде Presto в облаке, получающей данные HDFS из локальной среды, является задержка в сети между двумя кластерами.
49. Получение информации из наиболее детального набора демографических данных
 Узнайте, как настроить и работать локально с самым подробным набором демографических данных из существующих.
Узнайте, как настроить и работать локально с самым подробным набором демографических данных из существующих.
50. Почему микросервисы плохо справляются с машинным обучением... и что с этим можно сделать

51. Использование агрегирования данных для определения стоимости проданных товаров
 В этом тематическом исследовании описывается, как мы создали специальную библиотеку, которая объединяет данные из разных источников для получения необходимой нам информации.
В этом тематическом исследовании описывается, как мы создали специальную библиотеку, которая объединяет данные из разных источников для получения необходимой нам информации.
52. Подходят ли базы данных NoSQL для инженерии данных?
 В этой статье мы рассмотрим случаи использования, в которых инженерам данных может потребоваться взаимодействие с базой данных NoSQL, а также рассмотрим плюсы и минусы.
В этой статье мы рассмотрим случаи использования, в которых инженерам данных может потребоваться взаимодействие с базой данных NoSQL, а также рассмотрим плюсы и минусы.
53. Преимущества архитектуры гибридного развертывания
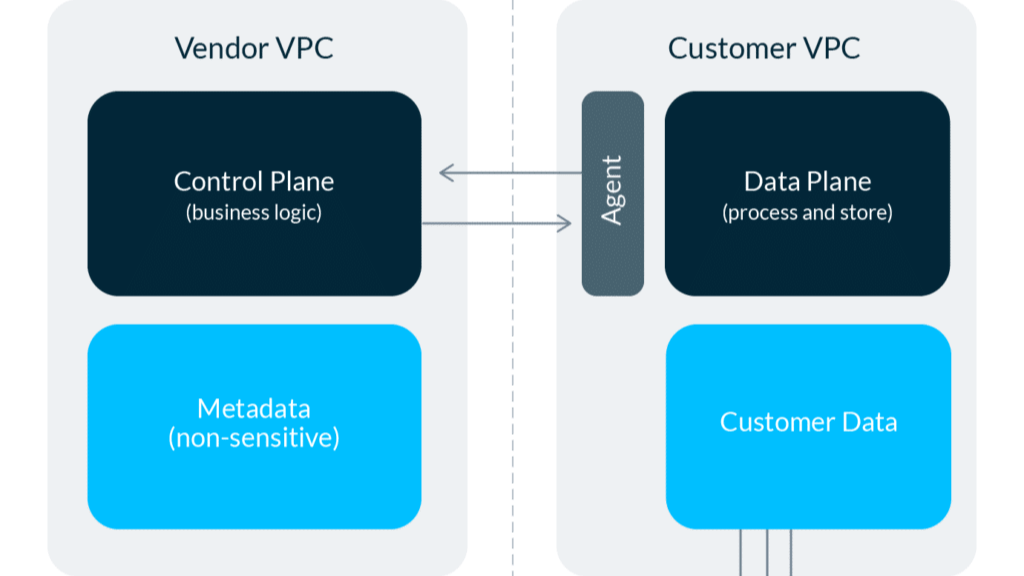 Посмотрите, как гибридная архитектура сочетает в себе лучшее из мира SaaS и локального мира для современного программного обеспечения для стека данных.
Посмотрите, как гибридная архитектура сочетает в себе лучшее из мира SaaS и локального мира для современного программного обеспечения для стека данных.
54. Как мы улучшили задания Spark в HDFS до 30 раз
 Являясь третьим по величине сайтом электронной коммерции в Китае, Vipshop обрабатывает большие объемы данных, собираемых ежедневно, для создания целевой рекламы для своих потребителей. В этой статье приглашенный автор Ганг Денг из Vipshop описывает, как соблюдать соглашения об уровне обслуживания, улучшая сложные задачи Spark на HDFS до 30 раз, и оптимизируя доступ к горячим данным с помощью Alluxio, чтобы создать надежный и стабильный конвейер вычислений для таргетированной рекламы в электронной коммерции.
Являясь третьим по величине сайтом электронной коммерции в Китае, Vipshop обрабатывает большие объемы данных, собираемых ежедневно, для создания целевой рекламы для своих потребителей. В этой статье приглашенный автор Ганг Денг из Vipshop описывает, как соблюдать соглашения об уровне обслуживания, улучшая сложные задачи Spark на HDFS до 30 раз, и оптимизируя доступ к горячим данным с помощью Alluxio, чтобы создать надежный и стабильный конвейер вычислений для таргетированной рекламы в электронной коммерции.
55. Почему мы учим Pandas вместо SQL?
 Как я научился перестать использовать панды и полюбил SQL.
Как я научился перестать использовать панды и полюбил SQL.
56. Как развернуть метабазу на Google Cloud Platform (GCP)?
 Метабаза — это инструмент бизнес-аналитики для вашей организации, который подключает различные источники данных, чтобы вы могли исследовать данные и создавать информационные панели. Я постараюсь написать серию статей о том, как обеспечить и внедрить это для вашей организации. Эта статья о том, как быстро приступить к работе.
Метабаза — это инструмент бизнес-аналитики для вашей организации, который подключает различные источники данных, чтобы вы могли исследовать данные и создавать информационные панели. Я постараюсь написать серию статей о том, как обеспечить и внедрить это для вашей организации. Эта статья о том, как быстро приступить к работе.
57. Советы по работе с базами данных: 7 причин, почему озера данных могут решить ваши проблемы
 Озера данных являются важным компонентом в создании любой перспективной платформы данных. В этой статье мы рассмотрим 7 причин, по которым вам нужно озеро данных.
Озера данных являются важным компонентом в создании любой перспективной платформы данных. В этой статье мы рассмотрим 7 причин, по которым вам нужно озеро данных.
58. Сбор данных об изменениях, управляемых событиями: введение, варианты использования и инструменты
 Как обнаруживать, фиксировать и распространять изменения в исходных базах данных на целевые системы в режиме реального времени на основе событий с помощью системы отслеживания измененных данных (CDC).
Как обнаруживать, фиксировать и распространять изменения в исходных базах данных на целевые системы в режиме реального времени на основе событий с помощью системы отслеживания измененных данных (CDC).
59. 7 ошибок(!), на которые нужно обратить внимание инженерам по работе с данными в проекте машинного обучения
 В этой статье рассматриваются семь ошибок при разработке данных в проекте машинного обучения. Список отсортирован по убыванию в зависимости от того, сколько раз я встречал каждый из них.
В этой статье рассматриваются семь ошибок при разработке данных в проекте машинного обучения. Список отсортирован по убыванию в зависимости от того, сколько раз я встречал каждый из них.
60. HarperDB — это больше, чем просто база данных: вот почему
 HarperDB — это больше, чем просто база данных, а для некоторых пользователей или проектов HarperDB вообще не служит базой данных. Как это возможно?
HarperDB — это больше, чем просто база данных, а для некоторых пользователей или проектов HarperDB вообще не служит базой данных. Как это возможно?
61. Введение в Delight: пользовательский интерфейс Spark и сервер истории Spark
 Delight — это кроссплатформенная панель мониторинга с открытым исходным кодом для Apache Spark с памятью и памятью. Показатели ЦП, дополняющие пользовательский интерфейс Spark и сервер истории Spark.
Delight — это кроссплатформенная панель мониторинга с открытым исходным кодом для Apache Spark с памятью и памятью. Показатели ЦП, дополняющие пользовательский интерфейс Spark и сервер истории Spark.
62. Масштабируйте конвейеры данных с помощью Airflow и Kubernetes
 Неважно, выполняете ли вы фоновые задачи, задания предварительной обработки или конвейеры машинного обучения. Написание задач – это легкая часть. Самое сложное — это оркестровка. Управление зависимостями между задачами, планирование рабочих процессов и мониторинг их выполнения утомительны.
Неважно, выполняете ли вы фоновые задачи, задания предварительной обработки или конвейеры машинного обучения. Написание задач – это легкая часть. Самое сложное — это оркестровка. Управление зависимостями между задачами, планирование рабочих процессов и мониторинг их выполнения утомительны.
63. Современное хранилище данных мертво?
 Нужен ли нам радикально новый подход к технологии хранилищ данных? Неизменяемое хранилище данных начинается с соглашений об уровне обслуживания потребителей данных и передачи данных в предварительно смоделированном виде.
Нужен ли нам радикально новый подход к технологии хранилищ данных? Неизменяемое хранилище данных начинается с соглашений об уровне обслуживания потребителей данных и передачи данных в предварительно смоделированном виде.
64. Эффективное обучение моделей в облаке с помощью Kubernetes, TensorFlow и Alluxio с открытым исходным кодом

65. Осведомленность о местоположении данных: преимущества реализации многоуровневой локализации
 Многоуровневая локальность — это функция, которую возглавляет мой коллега Эндрю Одиберт из Alluxio. В этой статье подробно рассматривается, как многоуровневая локализация помогает обеспечить оптимальную производительность и снизить затраты. Оригинал статьи был опубликован в инженерном блоге Alluxio
Многоуровневая локальность — это функция, которую возглавляет мой коллега Эндрю Одиберт из Alluxio. В этой статье подробно рассматривается, как многоуровневая локализация помогает обеспечить оптимальную производительность и снизить затраты. Оригинал статьи был опубликован в инженерном блоге Alluxio
66. Рабочий процесс разработки Docker для Apache Spark
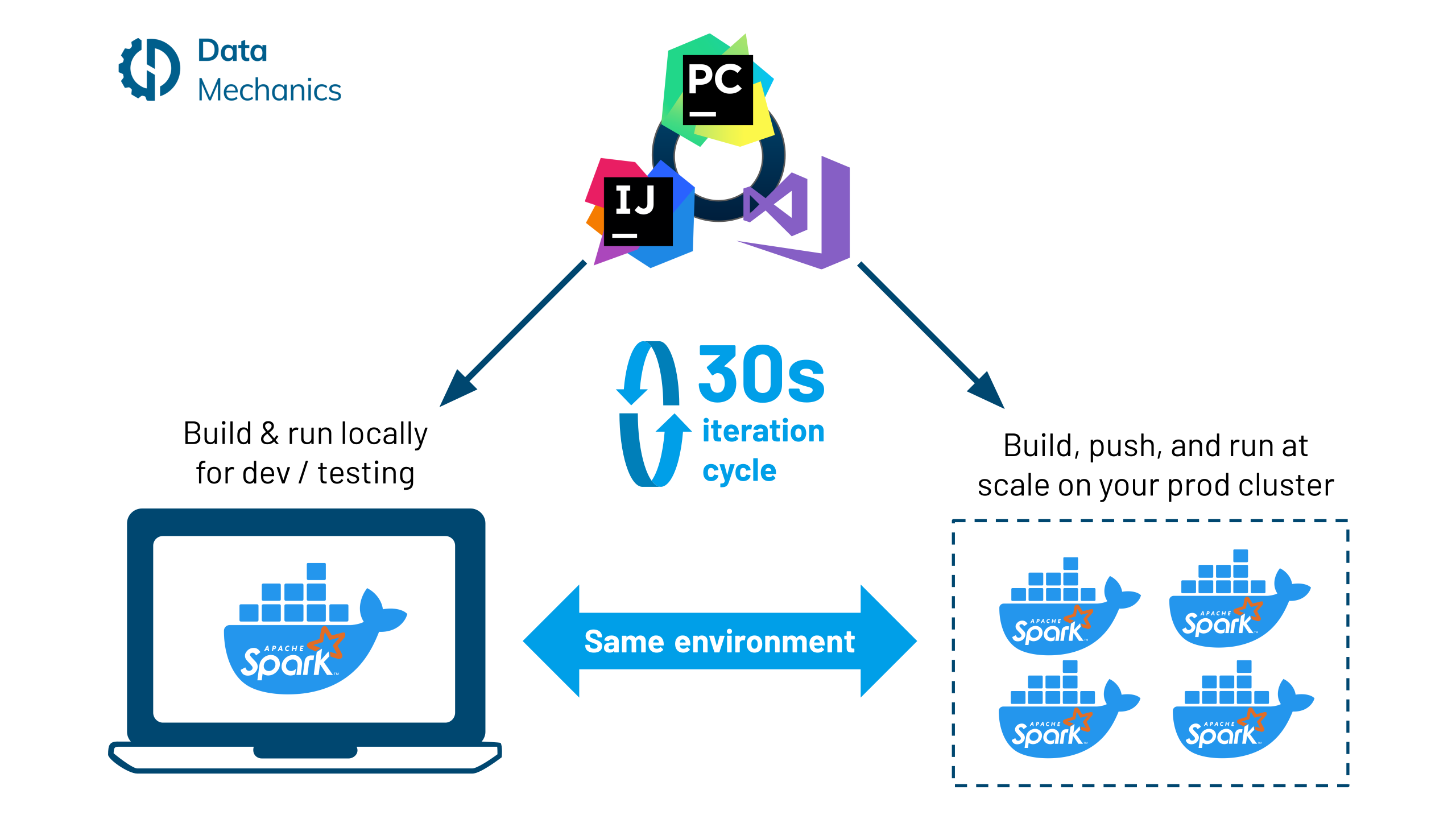 Преимущества использования контейнеров Docker хорошо известны: они предоставляют согласованные и изолированные среды, поэтому приложения можно развертывать где угодно — локально, в средах разработки/тестирования/производства, среди всех облачных провайдеров и локально — повторяемым способом. .
Преимущества использования контейнеров Docker хорошо известны: они предоставляют согласованные и изолированные среды, поэтому приложения можно развертывать где угодно — локально, в средах разработки/тестирования/производства, среди всех облачных провайдеров и локально — повторяемым способом. .
67. Что такое сетка данных — и подходит ли она мне?
 Спросите любого в индустрии данных, что сейчас актуально, и, скорее всего, «сетка данных» поднимется на первое место в списке. Но что такое сетка данных и подходит ли она вам?
Спросите любого в индустрии данных, что сейчас актуально, и, скорее всего, «сетка данных» поднимется на первое место в списке. Но что такое сетка данных и подходит ли она вам?
68. 10 ключевых навыков, которые нужны каждому инженеру данных
 В результате разрыва между разработчиками приложений и специалистами по данным спрос на инженеров по данным вырос до 50 % в 2020 году, особенно благодаря увеличению инвестиций в SaaS-продукты на основе искусственного интеллекта.
В результате разрыва между разработчиками приложений и специалистами по данным спрос на инженеров по данным вырос до 50 % в 2020 году, особенно благодаря увеличению инвестиций в SaaS-продукты на основе искусственного интеллекта.
69. Создайте трекер цен криптовалют с помощью Node.js и Cassandra
 Поскольку полтора десятилетия назад произошел большой взрыв в сфере технологий обработки данных, который привел к появлению таких технологий, как Hadoop, которые удовлетворяют требованиям четырех букв «V». — объем, разнообразие, скорость и достоверность. Наблюдается рост использования баз данных со специализированными возможностями для обслуживания различных типов данных и моделей использования. Теперь вы можете увидеть компании, использующие графовые базы данных, базы данных временных рядов, базы данных документов и другие для различных клиентских и внутренних рабочих нагрузок.
Поскольку полтора десятилетия назад произошел большой взрыв в сфере технологий обработки данных, который привел к появлению таких технологий, как Hadoop, которые удовлетворяют требованиям четырех букв «V». — объем, разнообразие, скорость и достоверность. Наблюдается рост использования баз данных со специализированными возможностями для обслуживания различных типов данных и моделей использования. Теперь вы можете увидеть компании, использующие графовые базы данных, базы данных временных рядов, базы данных документов и другие для различных клиентских и внутренних рабочих нагрузок.
70. Обслуживание структурированных данных в Alluxio
 В этой статье рассказывается об управлении структурированными данными (предварительная версия для разработчиков), доступном в последней версии Alluxio 2.1.0, новой попытке предоставить дополнительные преимущества SQL и рабочим нагрузкам со структурированными данными с использованием Alluxio. Оригинальная концепция обсуждалась в инженерном блоге Alluxio. Эта статья является первой из двух статей о функции управления структурированными данными, над которой работала моя команда.
В этой статье рассказывается об управлении структурированными данными (предварительная версия для разработчиков), доступном в последней версии Alluxio 2.1.0, новой попытке предоставить дополнительные преимущества SQL и рабочим нагрузкам со структурированными данными с использованием Alluxio. Оригинальная концепция обсуждалась в инженерном блоге Alluxio. Эта статья является первой из двух статей о функции управления структурированными данными, над которой работала моя команда.
[71. На пути к открытым цепочкам опционов:
Решение конвейера данных — часть I](https://hackernoon.com/towards-open-options-chains-a-data-pipeline-solution-for-options-data-part-i)
 В статье «На пути к открытым цепочкам опционов» Крис Чоу представляет свое решение для сбора данных о опционах: конвейер данных с Airflow, PostgreSQL и Docker.
В статье «На пути к открытым цепочкам опционов» Крис Чоу представляет свое решение для сбора данных о опционах: конвейер данных с Airflow, PostgreSQL и Docker.
72. Почему Data Science – это командный вид спорта?
 Сегодня я расскажу, почему я считаю науку о данных командным видом спорта?
Сегодня я расскажу, почему я считаю науку о данных командным видом спорта?
73. Почему качество данных является ключом к успеху операций по машинному обучению
 В этой первой статье нашей серии, состоящей из двух частей, мы рассмотрим ML Ops и подчеркнем, как и почему качество данных является ключевым моментом в рабочих процессах ML Ops.
В этой первой статье нашей серии, состоящей из двух частей, мы рассмотрим ML Ops и подчеркнем, как и почему качество данных является ключевым моментом в рабочих процессах ML Ops.
74. 9 лучших курсов по инженерии данных, которые стоит пройти в 2023 году
 В этом списке вы найдете одни из лучших курсов по разработке данных и карьерные пути, которые помогут вам начать свой путь в области разработки данных!
В этом списке вы найдете одни из лучших курсов по разработке данных и карьерные пути, которые помогут вам начать свой путь в области разработки данных!
75. 4 важных шага для создания большого каталога разъемов
 Искусство создания большого каталога разъемов основано на луковичных слоях.
Искусство создания большого каталога разъемов основано на луковичных слоях.
76. Все, что вам нужно знать о глубоком наблюдении за данными
 Что такое Deep Data Observability и чем она отличается от Shallow.
Что такое Deep Data Observability и чем она отличается от Shallow.
77. Питон & Инженерия данных: под капотом операторов соединения
 В этом посте я обсуждаю алгоритмы вложенного цикла, хэш-соединения и соединения слиянием в Python.
В этом посте я обсуждаю алгоритмы вложенного цикла, хэш-соединения и соединения слиянием в Python.
78. Как мы создали межрегиональный гибридный облачный шлюз хранения данных для машинного обучения и машинного обучения; ИИ в WeRide
 В этом блоге приглашенный писатель Дерек Тан, исполнительный директор Infra & Моделирование в WeRide описывает, как инженеры используют Alluxio в качестве шлюза данных гибридного облака для локальных приложений для доступа к общедоступному облачному хранилищу, такому как AWS S3.
В этом блоге приглашенный писатель Дерек Тан, исполнительный директор Infra & Моделирование в WeRide описывает, как инженеры используют Alluxio в качестве шлюза данных гибридного облака для локальных приложений для доступа к общедоступному облачному хранилищу, такому как AWS S3.
79. Как реализовать машинное обучение путем разработки конвейеров с самого начала
 Написание кода машинного обучения в виде конвейеров с самого начала сокращает технический долг и увеличивает скорость внедрения машинного обучения в производство.
Написание кода машинного обучения в виде конвейеров с самого начала сокращает технический долг и увеличивает скорость внедрения машинного обучения в производство.
80. Goldman Sachs, Data Lineage и заклинания Гарри Поттера
 Goldman будет доминировать в потребительском банкинге
Goldman будет доминировать в потребительском банкинге
81. Тест производительности: Apache Spark на DataProc против. Google BigQuery

Когда дело доходит до инфраструктуры больших данных на Google Cloud Platform, наиболее популярным выбором, который сегодня должны учитывать архитекторы данных, являются Google BigQuery – бессерверное, масштабируемое и экономичное облачное хранилище данных, Cloud Dataflow и Dataproc на основе Apache Beam — полностью управляемый облачный сервис для более простого и экономичного запуска кластеров Apache Spark и Apache Hadoop.
82. Сборка или покупка: чему мы научились, внедрив каталог данных
 Почему мы решили наконец купить единое рабочее пространство для обработки данных (Atlan), потратив 1,5 года на создание собственного внутреннего решения с использованием Amundsen и Atlas
Почему мы решили наконец купить единое рабочее пространство для обработки данных (Atlan), потратив 1,5 года на создание собственного внутреннего решения с использованием Amundsen и Atlas
83. Сохраняйте и ищите в истории своего канала Slack на бесплатном плане Slack
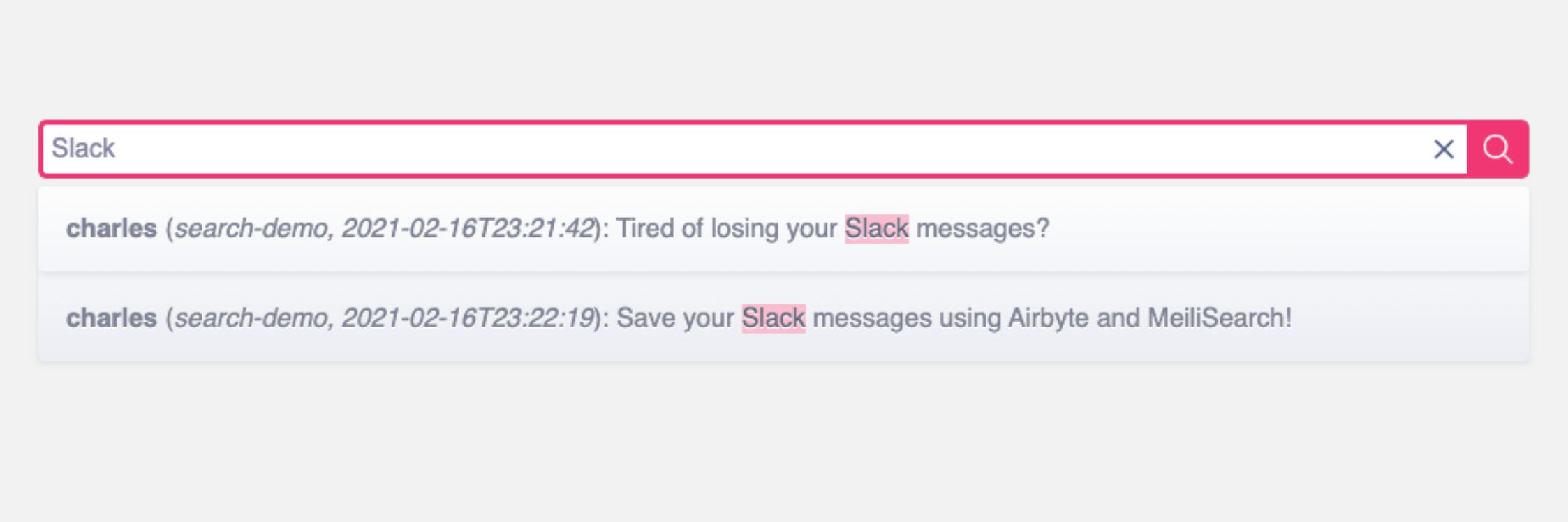 Иногда мы не можем позволить себе платную подписку на Slack. Вот руководство о том, как бесплатно сохранять и искать в истории Slack.
Иногда мы не можем позволить себе платную подписку на Slack. Вот руководство о том, как бесплатно сохранять и искать в истории Slack.
84. The DeltaLog: Основы Delta Lake [Часть 2]
 Серия из нескольких частей, которая проведет вас от новичка до эксперта по озеру Дельта
Серия из нескольких частей, которая проведет вас от новичка до эксперта по озеру Дельта
85. Глубокое обучение в облаке Alibaba с помощью Alluxio: как запустить PyTorch на HDFS
 В этом руководстве показано, как команда Alibaba Cloud Container запускает PyTorch на HDFS с использованием Alluxio в среде Kubernetes. Оригинал статьи на китайском языке был опубликован в инженерном блоге Alibaba Cloud, затем переведен и опубликован в инженерном блоге Alluxio
В этом руководстве показано, как команда Alibaba Cloud Container запускает PyTorch на HDFS с использованием Alluxio в среде Kubernetes. Оригинал статьи на китайском языке был опубликован в инженерном блоге Alibaba Cloud, затем переведен и опубликован в инженерном блоге Alluxio
86. Представляем Handoff: платформу оркестрации бессерверных конвейеров данных

87. Как машинное обучение используется в астрономии
 Является ли астрономия наукой о данных?
Является ли астрономия наукой о данных?
88. Вакцины против гриппа: за ними стоит наука о данных
89. Тестирование данных: речь идет как об обнаружении проблем, так и о качестве реагирования
 Поздравляем, вы успешно внедрили тестирование данных в свой конвейер!
Поздравляем, вы успешно внедрили тестирование данных в свой конвейер!
90. 6 лучших практик CI/CD для сквозных конвейеров разработки
 Чтобы добиться максимальной эффективности, нужно знать, как головоломки науки о данных сочетаются друг с другом, и затем решать их.
Чтобы добиться максимальной эффективности, нужно знать, как головоломки науки о данных сочетаются друг с другом, и затем решать их.
91. Улучшение: революция машинного обучения и обработки данных для оптимизации маркетинговых усилий
 В этом блоге рассматриваются реальные примеры использования компаниями, использующими машинное обучение и революцию в области обработки данных, для оптимизации своих маркетинговых усилий.
В этом блоге рассматриваются реальные примеры использования компаниями, использующими машинное обучение и революцию в области обработки данных, для оптимизации своих маркетинговых усилий.
92. Введение в соединители данных: ваш первый шаг к аналитике данных
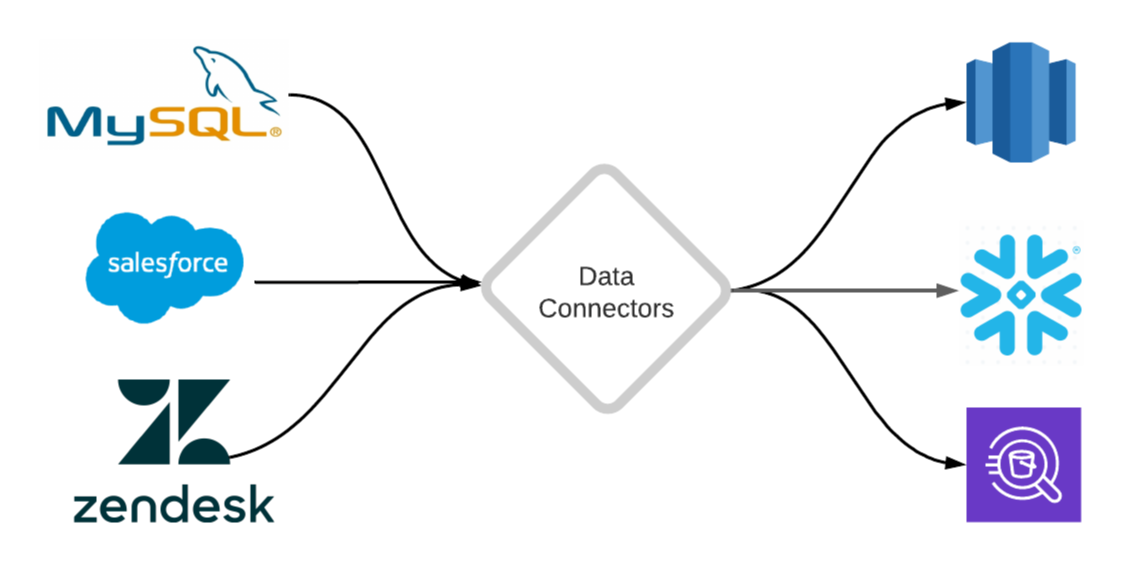 В этом посте объясняется, что такое соединитель данных, и представлена основа для создания соединителей, которые реплицируют данные из разных источников в ваше хранилище данных.
В этом посте объясняется, что такое соединитель данных, и представлена основа для создания соединителей, которые реплицируют данные из разных источников в ваше хранилище данных.
93. Как создать рабочий процесс n8n для управления различными базами данных и планирования рабочих процессов
 Узнайте, как построить рабочий процесс n8n, который обрабатывает текст, сохраняет данные в двух базах данных и отправляет сообщения в Slack.
Узнайте, как построить рабочий процесс n8n, который обрабатывает текст, сохраняет данные в двух базах данных и отправляет сообщения в Slack.
94. Как создать стек данных с нуля
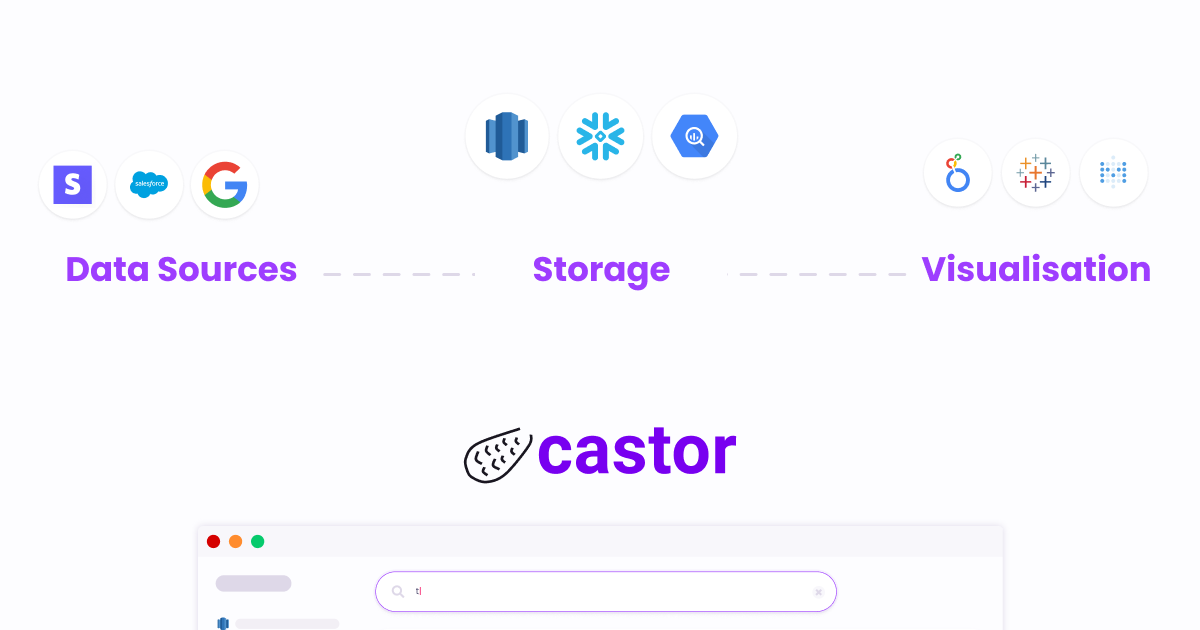 Обзор современного стека данных после интервью с 200+ лидерами данных. Матрица решений для сравнительного анализа (DW, ETL, управление, визуализация, документация и т. д.)
Обзор современного стека данных после интервью с 200+ лидерами данных. Матрица решений для сравнительного анализа (DW, ETL, управление, визуализация, документация и т. д.)
95. Как начать работу с контролем версий данных (DVC)
 Контроль версий данных (DVC) — это версия Git, ориентированная на данные. Фактически, он почти такой же, как Git, с точки зрения связанных с ним функций и рабочих процессов.
Контроль версий данных (DVC) — это версия Git, ориентированная на данные. Фактически, он почти такой же, как Git, с точки зрения связанных с ним функций и рабочих процессов.
96. Как выполнить увеличение данных с помощью библиотеки Augly
 Увеличение данных – это метод, используемый практиками для увеличения объема данных путем создания модифицированных данных из существующих данных.
Увеличение данных – это метод, используемый практиками для увеличения объема данных путем создания модифицированных данных из существующих данных.
Спасибо, что ознакомились с 96 самыми читаемыми историями об инженерии данных на HackerNoon.
Посетите репозиторий /Learn, чтобы найти самые читаемые статьи о любой технологии.