
80 % проблем не выявляются только путем тестирования: создайте стек надежности данных, чтобы сократить время простоя
9 апреля 2022 г.26 июля 2004 г. 5-летний стартап под названием Google столкнулся с серьезной проблемой: их приложение было недоступно.
В течение нескольких часов пользователи в США, Франции и Великобритании не могли получить доступ к популярной поисковой системе. Компания, в которой тогда работало 800 человек, и миллионы ее пользователей остались в неведении, поскольку инженеры изо всех сил пытались решить проблему и обнаружить ее основную причину.
К полудню утомительный и интенсивный процесс, проведенный несколькими запаниковавшими инженерами, определил, что вирус MyDoom был виноват.
В 2021 году сбой такой продолжительности и масштаба считается довольно аномальным, но 15 лет назад такие сбои программного обеспечения не были чем-то из ряда вон выходящим. Бенджамин Трейнор Слосс, в то время руководивший командами через несколько таких опытов, решил, что должен быть лучший способ управлять и предотвращать эти головокружительные пожарные учения не только в Google, но и во всей отрасли.
Вдохновленный своей ранней карьерой в области создания данных и ИТ-инфраструктуры, Слосс систематизировал свои знания в виде совершенно новой дисциплины — проектирование надежности сайта (SRE) — посвященной оптимизации обслуживания и операции программных систем (таких как поисковая система Google) с учетом надежности.
Согласно Слоссу и другим прокладывающим путь вперед для дисциплины, SRE была посвящена автоматизации, избавляющей от необходимости беспокоиться о пограничных случаях и неизвестных неизвестных (таких как ошибочный код, сбои сервера и вирусы). В конечном счете, Слосс и его команда хотели, чтобы инженеры могли автоматизировать ручной труд по поддержанию быстро растущей кодовой базы компании, гарантируя при этом, что их базы будут защищены, когда системы сломаются.
«SRE — это образ мышления и подход к производству. Большинство инженеров, разрабатывающих систему, также могут быть SRE для этой системы», [он сказал] (https://www.youtube.com/watch?v=1NF6N2RwVoc). «Вопрос в том, могут ли они взять сложную, может быть, нечетко сформулированную проблему и найти масштабируемое, технически обоснованное решение?»
Если бы у Google были правильные процессы и системы для прогнозирования и предотвращения последующих проблем, сбои можно было бы не только легко устранять с минимальным воздействием на пользователей, но и вообще предотвращать.
Данные — это программное обеспечение, а программное обеспечение — это данные
Почти 20 лет спустя команды по обработке данных постигла та же участь. Как и программное обеспечение, системы данных становятся все более сложными, с многочисленными зависимостями вверх и вниз по течению. Десять или даже пять лет назад было нормальным и общепринятым управлять своими данными в хранилищах, но теперь команды и даже целые компании работают с данными, что способствует более совместному и отказоустойчивому подходу к управлению данными.
За последние несколько лет мы стали свидетелями широкого внедрения лучших практик разработки программного обеспечения в сфере обработки данных. и команды аналитиков для устранения этого пробела, от внедрения инструментов с открытым исходным кодом, таких как [dbt] (https://www.getdbt.com) и [Apache Airflow] (https://airflow.apache.org), для упрощения преобразования данных и оркестровки. в облачные хранилища данных и озера, такие как Snowflake и Databricks.
По сути, этот сдвиг в сторону [гибких принципов] (https://hackernoon.com/what-are-the- Different-stages-of-the-agile-software-development-lifecycle) связан с тем, как мы концептуализируем, проектируем, строим, и поддерживать системы данных. Давно прошли времена разрозненных информационных панелей и отчетов, которые создаются один раз, редко используются и никогда не обновляются; теперь, чтобы быть полезными в масштабе, данные также должны быть обработаны, поддерживаться и управляться для использования конечными пользователями в компании.
И для того, чтобы с данными можно было обращаться как с программным продуктом, они также должны быть такими же надежными.
Повышение надежности данных

Короче говоря, [надежность данных] (https://www.montecarlodata.com/what-is-data-reliability/) — это способность организации обеспечивать высокую доступность и работоспособность данных на протяжении всего их жизненного цикла, от приема до конечных продуктов. : информационные панели, модели ML и производственные наборы данных.
В прошлом внимание уделялось изолированному решению различных частей головоломки, от тестирования фреймворков до наблюдаемости данных, но этого подхода уже недостаточно. Однако, как скажет вам любой инженер по данным, надежность данных (и способность действительно обращаться с данными как с продуктом) не достигается в бункере.
Изменение схемы в одном активе данных может повлиять на несколько таблиц и даже полей ниже по течению в ваших информационных панелях Tableau. Отсутствующее значение может привести вашу финансовую команду в истерику, когда они запрашивают новую информацию в [Looker] (https://www.looker.com).
А когда 500 строк вдруг превращаются в 5000, обычно это признак того, что что-то не так — вы просто не знаете, где и как сломалась таблица.
Даже при наличии множества отличных инструментов и ресурсов для обработки данных данные могут быть повреждены по миллионам различных причин, от операционных проблем и изменений кода до проблем с самими данными.
![Пообщавшись с сотнями команд по обработке данных и на собственном опыте, я обнаружил, что около 80 процентов проблем с данными не решаются одним лишь тестированием. Изображение предоставлено Лиором Гавишем.]
Исходя из моего собственного опыта и после общения с сотнями команд, большинство дата-инженеров в настоящее время обнаруживают проблемы с качеством данных двумя способами: тестирование (идеальный результат) и гневные сообщения от нижестоящих заинтересованных сторон (вероятный результат).
Точно так же, как SRE управляют временем простоя приложений, современные инженеры данных должны сосредоточиться на сокращении времени простоя данных — периодов времени, когда данные неточны, отсутствуют или иным образом ошибочны — за счет автоматизации, непрерывной интеграции и непрерывного развертывания моделей данных, а также других гибких методов. принципы.
В прошлом мы обсуждали, как создать быструю и грязную платформу данных; теперь мы развиваем этот дизайн, чтобы отразить следующий шаг на пути к хорошим данным: стек надежности данных.
Вот как и зачем его строить.
Представляем: стек надежности данных
В настоящее время перед группами обработки данных стоит задача создания масштабируемых, высокопроизводительных платформ данных, которые могут удовлетворить потребности межфункциональных аналитических групп, сохраняя, обрабатывая и направляя данные для получения точных и своевременных аналитических данных.
Но чтобы достичь этого, нам также нужен правильный подход к обеспечению того, чтобы необработанные данные были пригодны для использования и в первую очередь заслуживали доверия. С этой целью некоторые из лучших команд создают стеки надежности данных как часть своих современных платформ данных.
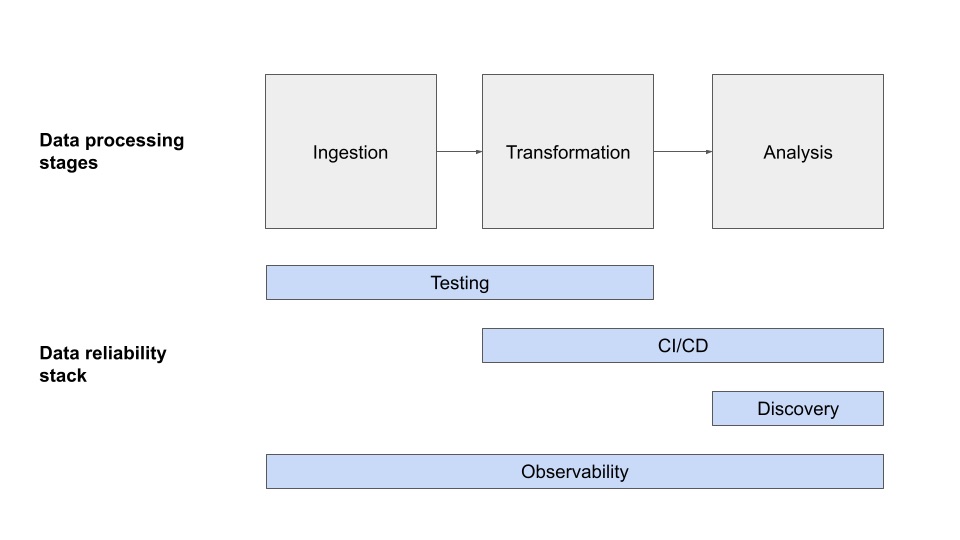
На мой взгляд, современный стек надежности данных состоит из четырех отдельных уровней: тестирование, CI/CD, наблюдаемость данных и обнаружение данных, каждый из которых представляет отдельный этап на пути к обеспечению качества данных вашей компании.
![Стек надежности данных состоит из пяти уровней, включая тестирование, CI/CD, наблюдаемость данных и обнаружение данных. Изображение предоставлено Лиором Гавишем.]
Тестирование
Тестирование ваших данных играет решающую роль в обнаружении проблем с качеством данных еще до того, как они попадут в производственный конвейер данных. При тестировании инженеры предвидят, что что-то может сломаться, и пишут логику для упреждающего обнаружения проблемы.
Тестирование данных — это процесс проверки предположений вашей организации о данных до или во время производства. Написание базовых тестов, проверяющих такие вещи, как уникальность и not_null, — это способ, с помощью которого организации могут проверить основные предположения, которые они делают об исходных данных.
Организации также часто следят за тем, чтобы данные были в правильном формате для работы их команды, и чтобы данные соответствовали их бизнес-потребностям.
Некоторые из наиболее распространенных тестов качества данных включают в себя:
- Нулевые значения — неизвестны ли какие-либо значения (NULL)?
- Объем — я вообще получил какие-либо данные? Я получил слишком много или слишком мало?
- Распределение — находятся ли мои данные в допустимом диапазоне? Находятся ли мои значения в пределах заданного столбца?
- Уникальность — дублируются ли какие-либо значения?
- Известные инварианты — всегда ли прибыль равна разнице между выручкой и себестоимостью или какие-то другие общеизвестные факты о моих данных?
По моему собственному опыту, два лучших инструмента для проверки ваших данных — это [dbt-тесты] (https://docs.getdbt.com/docs/building-a-dbt-project/tests) и Большие ожидания (как инструмент более общего назначения). Оба инструмента имеют открытый исходный код и позволяют обнаруживать проблемы с качеством данных до того, как они попадут в руки заинтересованных лиц.
Хотя dbt не является решением для тестирования как таковое, его готовые тесты хорошо работают, если вы уже используете фреймворк для моделирования и преобразования данных.
Непрерывная интеграция (CI)/непрерывная доставка (CD)
CI/CD — это ключевой компонент жизненного цикла разработки программного обеспечения, обеспечивающий стабильность и надежность развертывания нового кода по мере обновления. сделано с течением времени, с помощью автоматизации.
В контексте проектирования данных CI/CD относится не только к процессу непрерывной интеграции нового кода, но и к процессу интеграции новых данных в систему. Выявляя проблемы на ранней стадии, в идеале, на этапе фиксации кода или объединения новых данных, команды, работающие с данными, могут ускорить и повысить надежность рабочего процесса разработки.
Начнем с кодовой части уравнения. Как и традиционные инженеры-программисты, инженеры данных получают выгоду от использования системы управления версиями, например, Github, для управления своим кодом и преобразованиями, чтобы новый код можно было должным образом проверять и контролировать версии.
Система CI/CD, например CircleCI или Jenkins (с открытым исходным кодом), с полностью автоматизированным тестированием и развертыванием. setup может повысить предсказуемость и согласованность развертывания кода.
Все это должно звучать очень знакомо. Там, где группы данных сталкиваются с дополнительным уровнем сложности, возникает проблема понимания того, как изменения кода могут повлиять на набор данных, который он выводит.
Вот где появляются новые инструменты, которые позволяют командам сравнивать выходные данные нового фрагмента кода с предыдущим запуском того же кода. Выявление непредвиденных расхождений данных на ранних этапах процесса, до того, как код будет развернут, достигается более высокая надежность. Хотя для этого процесса требуются репрезентативные промежуточные или производственные данные, он может быть очень эффективным.
Существует также еще одно семейство инструментов, призванных помочь командам более надежно отправлять новые данные, а не новый код. С помощью LakeFS или Project Nessie команды могут размещать свои данные перед их публикацией для дальнейшего использования с семантикой, подобной git.
Представьте, что вы создаете ветку с вновь обработанными данными и передаете ее в основную ветку только в том случае, если она считается хорошей! В сочетании с тестированием ветвление данных может быть очень эффективным способом предотвращения передачи недостоверных данных нижестоящим потребителям.
Наблюдаемость данных
Предварительное тестирование и проверка версий данных — отличный первый шаг на пути к обеспечению надежности данных, но что происходит, когда данные перестают работать — и дальше?
В дополнение к элементам стека надежности данных, которые обеспечивают качество данных перед преобразованием и моделированием, группам инженеров данных необходимо инвестировать в комплексные автоматизированные решения для наблюдения за данными, которые могут обнаруживать возникновение проблем с данными почти в реальном времени.
Аналогично DevOps Решения по наблюдению (например, Datadog и Новый Relic), data observability использует автоматический мониторинг, оповещение и сортировку для выявления и оценивать проблемы качества данных.
Наблюдаемость данных измеряется по пяти ключевым компонентам работоспособности и надежности данных: свежесть, распространение, объем, схема и происхождение:
- Свежесть: Данные свежие? Когда он был сгенерирован в последний раз? Какие восходящие данные включены и/или опущены?
- Распределение: Находятся ли данные в допустимых пределах? Это правильный формат? Он завершен?
- Том: Все ли данные получены? Были ли данные дублированы случайно? Сколько данных было удалено из таблицы?
- Схема: Что это за схема и как она изменилась? Кто внес изменения в схему и по каким причинам?
- Происхождение: Для данного актива данных, на какие исходные и нижестоящие источники он влияет? Кто генерирует эти данные и кто полагается на данные для принятия решений?
Наблюдаемость данных составляет остальные 80 процентов времени простоя данных, которые ваша команда не может предсказать (неизвестные неизвестные), не только обнаруживая и предупреждая о проблемах с качеством данных, но также обеспечивая анализ основных причин, анализ воздействия, происхождение на уровне поля и операционную информацию. на вашей платформе данных.
Благодаря этим инструментам ваша команда будет хорошо оснащена, чтобы не только устранять, но и предотвращать возникновение подобных проблем в будущем благодаря историческому и статистическому анализу надежности ваших данных.
Обнаружение данных
Хотя традиционно это не считается частью стека надежности, мы считаем, что обнаружение данных имеет решающее значение. Один из наиболее распространенных способов создания недостоверных данных — это игнорирование уже существующих активов и создание новых наборов данных, которые значительно перекрывают или даже противоречат существующим.
Это создает путаницу среди потребителей в организации относительно того, какие данные наиболее важны для конкретного бизнес-вопроса, и снижает доверие и воспринимаемую надежность. Это также создает огромную задолженность по данным для команд инженеров данных.
Без хорошего обнаружения командам приходится поддерживать десятки различных наборов данных, описывающих одни и те же измерения или факты. Одна только сложность делает дальнейшую разработку сложной задачей, а высокая надежность — чрезвычайно трудной задачей.
В то время как обнаружение данных является чрезвычайно сложной проблемой, каталоги данных проложили путь к большей демократизации и доступности. Например, мы были свидетелями того, как такие решения, как Atlan, data.world и Stemma может решить эти две проблемы.
В то же время решения для наблюдения за данными могут помочь устранить многие общепринятые проблемы с надежностью и проблемы с задолженностью по данным, необходимые для обнаружения данных. Соединяя воедино метаданные, родословную, индикаторы качества, шаблоны использования, а также созданную человеком документацию, наблюдаемость данных может ответить на такие вопросы, как:
- Какие данные доступны мне для описания наших клиентов?
- Какому набору данных я должен доверять больше всего?
- Как я могу использовать этот набор данных?
- Кто эксперты, которые могут помочь ответить на вопросы об этом?
Короче говоря, эти инструменты позволяют потребителям и производителям данных находить нужные наборы данных или отчеты и избегать дублирования усилий.
Демократизация этой информации и предоставление ее любому лицу, которое использует или создает данные, является важной частью головоломки надежности.
Будущее надежности данных
По мере того как данные становятся все более и более неотъемлемой частью повседневных операций современного бизнеса и лежат в основе цифровых продуктов, потребность в надежных данных будет только возрастать, равно как и технические требования, обеспечивающие это доверие.
Тем не менее, хотя ваш стек поможет вам в этом, надежность данных не решается только с помощью технологий. Самые сильные подходы также включают культурные и организационные сдвиги, чтобы расставить приоритеты в управлении, конфиденциальности и безопасности — все три области современного стека данных созрели для ускорения в течение следующих нескольких лет.
Еще одним мощным инструментом в вашем арсенале надежности данных является определение приоритетов соглашений об уровне обслуживания (SLA) и других мер для отслеживания частоты проблем относительно согласованных ожиданий, установленных с вашими заинтересованными сторонами, — еще один проверенный и надежный передовой опыт, почерпнутый из разработки программного обеспечения.
Такие метрики будут иметь решающее значение, поскольку ваша организация движется к тому, чтобы рассматривать данные как продукт, а группы обработки данных не так, как финансовые аналитики, а как группы разработчиков и инженеров.
А пока мы желаем вам не простоя данных — и много времени безотказной работы!
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27740)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)