

53 истории о парсинге данных, которые стоит узнать
9 января 2024 г.Давайте узнаем о скрапинге данных из этих 53 бесплатных историй. Они упорядочены по времени чтения, созданного на HackerNoon. Посетите /Learn Repo, чтобы найти самые читаемые истории о любой технологии.
1. Как я успешно провел реверс-инжиниринг ChatGPT и создал неофициальную оболочку API
 Очистка ChatGPT с помощью Python
Очистка ChatGPT с помощью Python
2. Как POST-запросы с помощью Python упрощают парсинг веб-страниц
 Чтобы очистить веб-сайт, обычно отправляют запросы GET, но полезно знать, как отправлять данные. В этой статье мы увидим, как начать работу с POST-запросами.
Чтобы очистить веб-сайт, обычно отправляют запросы GET, но полезно знать, как отправлять данные. В этой статье мы увидим, как начать работу с POST-запросами.
3. Введение в AutoScraper: быстрый и легкий автоматический веб-скребок для Python
 В последние несколько лет парсинг веб-страниц стал одной из моих повседневных и часто необходимых задач. Мне было интересно, смогу ли я сделать это умным и автоматическим, чтобы сэкономить много времени. Итак, я сделал AutoScraper!
В последние несколько лет парсинг веб-страниц стал одной из моих повседневных и часто необходимых задач. Мне было интересно, смогу ли я сделать это умным и автоматическим, чтобы сэкономить много времени. Итак, я сделал AutoScraper!
4. Как парсить Google с помощью Python

5. Мой путь создания парсера с помощью Ruby

6. Как извлечь наборы данных НЛП с YouTube
 Лень самому парсить данные nlp? В этом посте я покажу вам быстрый способ парсинга наборов данных НЛП с помощью Youtube и Python.
Лень самому парсить данные nlp? В этом посте я покажу вам быстрый способ парсинга наборов данных НЛП с помощью Youtube и Python.
7. Как извлечь данные с любого веб-сайта с помощью JavaScript
 Узнайте, как очищать Интернет с помощью сценариев, написанных на node.js, чтобы автоматизировать сбор данных с веб-сайта и использовать их для любых целей.
Узнайте, как очищать Интернет с помощью сценариев, написанных на node.js, чтобы автоматизировать сбор данных с веб-сайта и использовать их для любых целей.
8. Драматург против Селена: сравнение двух
 Краткое сравнение Selenium и Playwright с точки зрения парсинга веб-страниц. Какой из них удобнее всего использовать?
Краткое сравнение Selenium и Playwright с точки зрения парсинга веб-страниц. Какой из них удобнее всего использовать?
9. Как парсинг веб-страниц помогает компаниям превзойти конкурентов

10. Парсинг веб-страниц с использованием Node.js
 Хотя существует несколько различных библиотек для парсинга Интернета с помощью Node.js, в этом уроке я буду использовать библиотеку puppeteer.
Хотя существует несколько различных библиотек для парсинга Интернета с помощью Node.js, в этом уроке я буду использовать библиотеку puppeteer.
11. Парсинг веб-страниц с использованием Python: советы и рекомендации

12. Тайный гигант пейджеров Америки
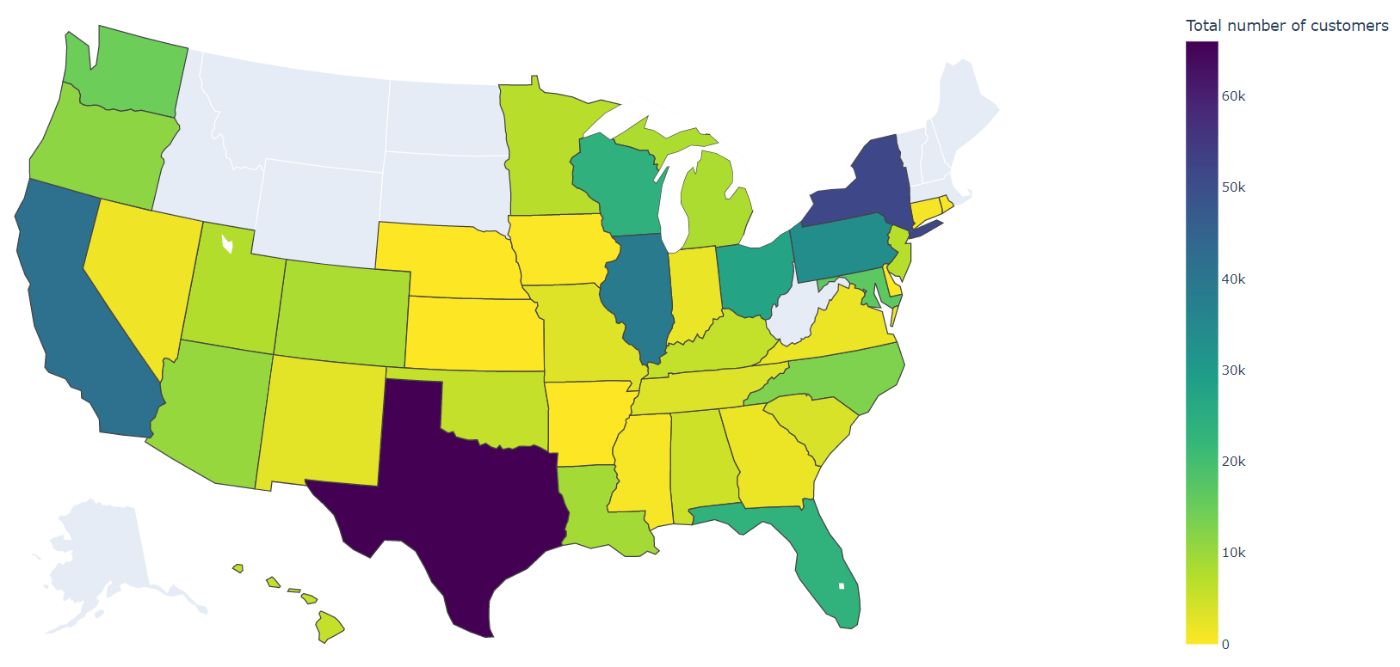 В начале января 2022 года я спонтанно купил пейджер. Я заглянул на рынок пейджеров в США и, к своему удивлению...
В начале января 2022 года я спонтанно купил пейджер. Я заглянул на рынок пейджеров в США и, к своему удивлению...
13. 8 браузерных расширений для профессионального сканирования Карт Google
 Эти расширения для очистки карт Google можно использовать для различных целей в различных ситуациях, например, для сбора данных или исследования рынка.
Эти расширения для очистки карт Google можно использовать для различных целей в различных ситуациях, например, для сбора данных или исследования рынка.
14. Как мне бесплатно создать парсер LinkedIn?
 Ознакомьтесь с этим пошаговым руководством о том, как бесплатно создать собственный парсер LinkedIn!
Ознакомьтесь с этим пошаговым руководством о том, как бесплатно создать собственный парсер LinkedIn!
15. Что такое сбор веб-данных?
 Все, что вам нужно знать, чтобы автоматизировать, оптимизировать и оптимизировать процесс сбора данных в вашей организации!
Все, что вам нужно знать, чтобы автоматизировать, оптимизировать и оптимизировать процесс сбора данных в вашей организации!
16. Как очистить профили Amazon, Yelp и GitHub за 30 секунд
 Самых талантливых разработчиков мира можно найти на GitHub. Что, если бы существовал простой, быстрый и бесплатный способ найти, ранжировать и завербовать их? Менее чем за минуту я покажу вам, как это сделать, используя бесплатные инструменты и разработанный мной процесс проверки лучших технических специалистов в BizPayO.
Самых талантливых разработчиков мира можно найти на GitHub. Что, если бы существовал простой, быстрый и бесплатный способ найти, ранжировать и завербовать их? Менее чем за минуту я покажу вам, как это сделать, используя бесплатные инструменты и разработанный мной процесс проверки лучших технических специалистов в BizPayO.
17. Парсинг веб-страниц с использованием Python: советы и рекомендации
 Необходимость в дополнительных данных о сайтах в Интернете увеличивается. Когда мы реализуем проекты, связанные с данными, в качестве монитора цен, анализа сделок или агрегатора уведомлений, мы всегда стремимся регистрировать данные о сайтах в Интернете. Без эмбарго копируйте и храните данные в Интернете, которые были деактуализированы. В этой статье мы можем преобразовать «эксперта» в извлечение данных из веб-сайтов, которые состоят из парсинга веб-страниц с помощью Python.
Необходимость в дополнительных данных о сайтах в Интернете увеличивается. Когда мы реализуем проекты, связанные с данными, в качестве монитора цен, анализа сделок или агрегатора уведомлений, мы всегда стремимся регистрировать данные о сайтах в Интернете. Без эмбарго копируйте и храните данные в Интернете, которые были деактуализированы. В этой статье мы можем преобразовать «эксперта» в извлечение данных из веб-сайтов, которые состоят из парсинга веб-страниц с помощью Python.
18. Веб-сканирование и парсинг: в чем разница между сканерами и парсерами?
 Изучите фундаментальные различия между сканированием и парсингом веб-страниц и определите, какой из них подходит именно вам.
Изучите фундаментальные различия между сканированием и парсингом веб-страниц и определите, какой из них подходит именно вам.
19. Где я могу найти нужные данные по маркетингу в социальных сетях?
 Как маркетолог, вы, вероятно, знаете, что маркетинг в социальных сетях — это частично искусство, частично наука.
Как маркетолог, вы, вероятно, знаете, что маркетинг в социальных сетях — это частично искусство, частично наука.
20. Очистка обратных ссылок Google Search Console
 Узнайте, как эмулировать обычный запрос пользователя и очищать данные консоли поиска Google с помощью Python и Beautiful Soup.
Узнайте, как эмулировать обычный запрос пользователя и очищать данные консоли поиска Google с помощью Python и Beautiful Soup.
21. Как использовать парсинг веб-страниц для принятия маркетинговых решений
 Узнайте, как использовать парсинг веб-страниц в маркетинге. В этой статье мы рассмотрим варианты использования и советы по началу работы.
Узнайте, как использовать парсинг веб-страниц в маркетинге. В этой статье мы рассмотрим варианты использования и советы по началу работы.
22. Очистка данных о заданиях Glassdoor
 Glassdoor — один из крупнейших рынков труда в мире, но его трудно охватить. В этой статье мы легально извлечем данные о заданиях с помощью Python & Красивый суп
Glassdoor — один из крупнейших рынков труда в мире, но его трудно охватить. В этой статье мы легально извлечем данные о заданиях с помощью Python & Красивый суп
23. Сбор ответов на твиты с помощью Python и Tweepy Twitter API [Пошаговое руководство]
 Быстрый способ бесплатного извлечения твитов и ответов
Быстрый способ бесплатного извлечения твитов и ответов
24. Более 15 частых вопросов о парсинге веб-страниц
 Ранее опубликовано по адресу https://www.octoparse.es/blog/15-preguntas-frecuentes-sobre-web-scraping
Ранее опубликовано по адресу https://www.octoparse.es/blog/15-preguntas-frecuentes-sobre-web-scraping
25. Пошаговое руководство по созданию парсера футбольных данных
 Сбор футбольных данных (футбол в США) — отличный способ создать комплексные наборы данных, которые помогут создать информационные панели со статистикой. Воспользуйтесь нашим парсером футбольных данных!
Сбор футбольных данных (футбол в США) — отличный способ создать комплексные наборы данных, которые помогут создать информационные панели со статистикой. Воспользуйтесь нашим парсером футбольных данных!
26. Введение в парсинг веб-страниц без кода
 Парсинг веб-страниц сломал барьеры программирования, и теперь его можно выполнять гораздо проще и легче, не используя ни единой строки кода.
Парсинг веб-страниц сломал барьеры программирования, и теперь его можно выполнять гораздо проще и легче, не используя ни единой строки кода.
27. Как веб-сканирование используется в науке о данных
 Инструменты без кода для сбора данных для вашего проекта Data Science
Инструменты без кода для сбора данных для вашего проекта Data Science
28. Как создать веб-сканер с нуля
 Как часто вы хотели получить информацию и обращались к Google за быстрым ответом? Любую информацию, необходимую нам в повседневной жизни, можно получить из Интернета. Вы можете извлекать данные из Интернета и использовать их для принятия наиболее эффективных бизнес-решений. Это делает парсинг и сканирование веб-страниц мощным инструментом. Если вы хотите программно собирать определенную информацию с веб-сайта для дальнейшей обработки, вам необходимо либо создать, либо использовать веб-скребок или веб-сканер. Мы стремимся помочь вам создать веб-сканер для индивидуального использования.
Как часто вы хотели получить информацию и обращались к Google за быстрым ответом? Любую информацию, необходимую нам в повседневной жизни, можно получить из Интернета. Вы можете извлекать данные из Интернета и использовать их для принятия наиболее эффективных бизнес-решений. Это делает парсинг и сканирование веб-страниц мощным инструментом. Если вы хотите программно собирать определенную информацию с веб-сайта для дальнейшей обработки, вам необходимо либо создать, либо использовать веб-скребок или веб-сканер. Мы стремимся помочь вам создать веб-сканер для индивидуального использования.
29. Как разработать инструмент сравнения цен на Python
 Интернет-покупки различных товаров уже не роскошь, а скорее необходимость. Получение желаемого продукта прямо у вашего порога облегчило потребителям возможность совершать покупки без особых усилий. В результате каждый год появляется несколько нишевых сайтов электронной коммерции или универсальных торговых сайтов. Эта тенденция не ограничивается каким-то конкретным регионом, а является глобальным явлением, поскольку все больше и больше людей предпочитают онлайн-покупки посещению торговых точек из-за пробок на дорогах и простоты совершения покупок. Именно поэтому прогнозируется, что к 2021 году 15,5 % продаж будет осуществляться через онлайн-сайты.
Интернет-покупки различных товаров уже не роскошь, а скорее необходимость. Получение желаемого продукта прямо у вашего порога облегчило потребителям возможность совершать покупки без особых усилий. В результате каждый год появляется несколько нишевых сайтов электронной коммерции или универсальных торговых сайтов. Эта тенденция не ограничивается каким-то конкретным регионом, а является глобальным явлением, поскольку все больше и больше людей предпочитают онлайн-покупки посещению торговых точек из-за пробок на дорогах и простоты совершения покупок. Именно поэтому прогнозируется, что к 2021 году 15,5 % продаж будет осуществляться через онлайн-сайты.
30. Парсинг веб-страниц PHP с использованием Goutte
 Когда вы говорите о парсинге веб-страниц, большинство людей думают в последнюю очередь о PHP.
Когда вы говорите о парсинге веб-страниц, большинство людей думают в последнюю очередь о PHP.
31. Как отслеживать ключевые слова на форуме с помощью Python и AWS Lambda
 Создавая ScrapingBee, я всегда каждый день просматриваю различные форумы, чтобы помочь людям ответить на вопросы, связанные с парсингом веб-страниц, и пообщаться с сообществом.
Создавая ScrapingBee, я всегда каждый день просматриваю различные форумы, чтобы помочь людям ответить на вопросы, связанные с парсингом веб-страниц, и пообщаться с сообществом.
32. Эволюция больших данных и парсинга данных
 Как генеральный директор прокси-сервиса и поставщика решений для очистки данных, я полностью понимаю, почему глобальные утечки данных, которые время от времени появляются в заголовках новостей, создали ужасную репутацию веб-скрейпинга и почему в наши дни так много людей относятся к большим данным с цинизмом.
Как генеральный директор прокси-сервиса и поставщика решений для очистки данных, я полностью понимаю, почему глобальные утечки данных, которые время от времени появляются в заголовках новостей, создали ужасную репутацию веб-скрейпинга и почему в наши дни так много людей относятся к большим данным с цинизмом.
33. Как создать красивый виджет iOS на JavaScript
 С помощью приложения Scriptable можно создать собственный виджет iOS даже при наличии базовых знаний JavaScript.
С помощью приложения Scriptable можно создать собственный виджет iOS даже при наличии базовых знаний JavaScript.
34. Парсинг Amazon с помощью Puppeteer и без браузера
 Простое руководство, демонстрирующее возможности Puppeteer и работы без браузера. Очистите Amazon.com, чтобы автоматически собирать цены на определенные товары!
Простое руководство, демонстрирующее возможности Puppeteer и работы без браузера. Очистите Amazon.com, чтобы автоматически собирать цены на определенные товары!
35. 3 Mejores Formas de Crawl Datas desde Website
 Необходимость сканирования веб-данных увеличилась в последние годы. Полученные данные можно использовать для оценки или прогнозирования в различных лагерях. Здесь я использую 3 метода, которые можно использовать для сбора данных из Интернета.
Необходимость сканирования веб-данных увеличилась в последние годы. Полученные данные можно использовать для оценки или прогнозирования в различных лагерях. Здесь я использую 3 метода, которые можно использовать для сбора данных из Интернета.
36. Введение в парсинг веб-страниц: что это такое и с чего начать
 Краткое введение в парсинг веб-страниц: что это такое, как оно работает, некоторые плюсы и минусы, а также несколько инструментов, которые можно использовать для этого.
Краткое введение в парсинг веб-страниц: что это такое, как оно работает, некоторые плюсы и минусы, а также несколько инструментов, которые можно использовать для этого.
37. Парсинг данных в Node.js 101
 Как собирать данные без этих надоедливых баз данных.
Как собирать данные без этих надоедливых баз данных.
38. Как парсить товары Bestbuy с помощью Scrapezone SDK
 Добро пожаловать в новый способ парсинга Интернета. В следующем руководстве мы будем парсить страницы продуктов BestBuy без написания каких-либо парсеров, используя одну простую библиотеку: Scrapezone SDK.
Добро пожаловать в новый способ парсинга Интернета. В следующем руководстве мы будем парсить страницы продуктов BestBuy без написания каких-либо парсеров, используя одну простую библиотеку: Scrapezone SDK.
39. Краткое руководство по парсингу данных
 Предположим, вы хотите как можно быстрее получить большие объемы информации с веб-сайта. Как это можно сделать?
Предположим, вы хотите как можно быстрее получить большие объемы информации с веб-сайта. Как это можно сделать?
40. Руководство по парсингу веб-страниц с помощью JavaScript и Node.js
 С массовым увеличением объема данных в Интернете этот метод становится все более полезным для получения информации с веб-сайтов и ее применения для различных случаев использования. Обычно извлечение веб-данных включает в себя запрос к данной веб-странице, доступ к ее HTML-коду и анализ этого кода для сбора некоторой информации. Поскольку JavaScript превосходно манипулирует DOM (объектной моделью документа) внутри веб-браузера, создание сценариев извлечения данных в Node.js может быть чрезвычайно универсальным. Следовательно, это руководство посвящено парсингу веб-страниц с помощью JavaScript.
С массовым увеличением объема данных в Интернете этот метод становится все более полезным для получения информации с веб-сайтов и ее применения для различных случаев использования. Обычно извлечение веб-данных включает в себя запрос к данной веб-странице, доступ к ее HTML-коду и анализ этого кода для сбора некоторой информации. Поскольку JavaScript превосходно манипулирует DOM (объектной моделью документа) внутри веб-браузера, создание сценариев извлечения данных в Node.js может быть чрезвычайно универсальным. Следовательно, это руководство посвящено парсингу веб-страниц с помощью JavaScript.
41. Как извлекать знания из Википедии в стиле Data Science
 Люди, работающие с данными, склонны думать, что они разрабатывают и экспериментируют со сложными и сложными алгоритмами и получают самые современные результаты. Во многом это правда. Это то, чем больше всего гордится специалист по данным, и это самая инновационная и полезная часть. Но чего люди обычно не замечают, так это того, сколько труда они тратят, собирая, обрабатывая и обрабатывая данные, что приводит к великолепным результатам. Вот почему вы можете видеть, что SQL встречается в большинстве требований к должностям специалиста по данным.
Люди, работающие с данными, склонны думать, что они разрабатывают и экспериментируют со сложными и сложными алгоритмами и получают самые современные результаты. Во многом это правда. Это то, чем больше всего гордится специалист по данным, и это самая инновационная и полезная часть. Но чего люди обычно не замечают, так это того, сколько труда они тратят, собирая, обрабатывая и обрабатывая данные, что приводит к великолепным результатам. Вот почему вы можете видеть, что SQL встречается в большинстве требований к должностям специалиста по данным.
42. Как очистить среднюю публикацию: руководство по Python для начинающих
 Некоторое время назад я пытался провести анализ публикации на Medium для личного проекта. Но получить данные оказалось проблемой: очистка только главной страницы издания не гарантирует, что вы получите все нужные данные.
Некоторое время назад я пытался провести анализ публикации на Medium для личного проекта. Но получить данные оказалось проблемой: очистка только главной страницы издания не гарантирует, что вы получите все нужные данные.
43. Парсинг данных с помощью Selenium: Upwork, серия №2
 Привет, разработчики!
Привет, разработчики!
44. Как выполнить парсинг Amazon с помощью библиотеки Python Scrapy [Учебное пособие]
 Scrapy — это платформа приложений для сканирования веб-сайтов и извлечения структурированных/неструктурированных данных, которую можно использовать для широкого спектра приложений, таких как интеллектуальный анализ данных, обработка информации или архивирование исторических данных. Как мы все знаем, сейчас эпоха «данных». Данные повсюду, и каждая организация хочет работать с данными и вывести свой бизнес на более высокий уровень. В этом сценарии Scrapy играет жизненно важную роль в предоставлении данных этим организациям, чтобы они могли использовать их в широком спектре приложений. Scrapy может удалять данные не только с веб-сайтов, но и с веб-сервисов.
Scrapy — это платформа приложений для сканирования веб-сайтов и извлечения структурированных/неструктурированных данных, которую можно использовать для широкого спектра приложений, таких как интеллектуальный анализ данных, обработка информации или архивирование исторических данных. Как мы все знаем, сейчас эпоха «данных». Данные повсюду, и каждая организация хочет работать с данными и вывести свой бизнес на более высокий уровень. В этом сценарии Scrapy играет жизненно важную роль в предоставлении данных этим организациям, чтобы они могли использовать их в широком спектре приложений. Scrapy может удалять данные не только с веб-сайтов, но и с веб-сервисов.
45. Сбор отзывов с Amazon с помощью Scrapy в Python [Учебное пособие]
 Вы ищете метод очистки обзоров Amazon и не знаете, с чего начать? В этом случае этот блог может оказаться очень полезным для сбора обзоров Amazon. В этом блоге мы обсудим сбор обзоров Amazon с использованием Scrapy в Python. Веб-скрапинг — это простой способ сбора данных с разных веб-сайтов, а Scrapy — это платформа веб-сканирования на Python.
Вы ищете метод очистки обзоров Amazon и не знаете, с чего начать? В этом случае этот блог может оказаться очень полезным для сбора обзоров Amazon. В этом блоге мы обсудим сбор обзоров Amazon с использованием Scrapy в Python. Веб-скрапинг — это простой способ сбора данных с разных веб-сайтов, а Scrapy — это платформа веб-сканирования на Python.
46. 5 способов защиты от царапин, которые можно использовать
 С помощью больших данных люди могут получить данные из Интернета для анализа данных с помощью веб-сайтов. Есть различные формы, которые можно использовать для собственного растредора: расширения и навигаторы, кодификация Python с помощью Beautiful Soup или Scrapy, а также дополнительные возможности извлечения данных в виде Octoparse.
С помощью больших данных люди могут получить данные из Интернета для анализа данных с помощью веб-сайтов. Есть различные формы, которые можно использовать для собственного растредора: расширения и навигаторы, кодификация Python с помощью Beautiful Soup или Scrapy, а также дополнительные возможности извлечения данных в виде Octoparse.
47. Какую выгоду туристическая индустрия может получить от сбора данных
 В наши дни туристическая индустрия является основным сектором услуг в большинстве стран. Это также крупный источник занятости и доходов. Это требует большого количества постоянных инноваций и обслуживания. Туристическая индустрия — динамичная отрасль, в которой потребности и предпочтения клиента меняются каждое мгновение. Игрокам рынка в этой области необходимо идти в ногу с тенденциями в отрасли, выбором клиентов и даже с деталями своей собственной исторической деятельности, чтобы с течением времени работать лучше. Таким образом, как и следовало ожидать, компаниям, работающим в туристическом секторе, необходимо много данных из разных источников и конвейер для оценки и использования этих данных для получения аналитических сведений и рекомендаций.
В наши дни туристическая индустрия является основным сектором услуг в большинстве стран. Это также крупный источник занятости и доходов. Это требует большого количества постоянных инноваций и обслуживания. Туристическая индустрия — динамичная отрасль, в которой потребности и предпочтения клиента меняются каждое мгновение. Игрокам рынка в этой области необходимо идти в ногу с тенденциями в отрасли, выбором клиентов и даже с деталями своей собственной исторической деятельности, чтобы с течением времени работать лучше. Таким образом, как и следовало ожидать, компаниям, работающим в туристическом секторе, необходимо много данных из разных источников и конвейер для оценки и использования этих данных для получения аналитических сведений и рекомендаций.
48. Парсинг веб-страниц от А до Я в 2020 году [Практическое руководство]

49. Как парсить веб-страницы с помощью Python, Snscrape & HarperDB
 Узнайте, как выполнять очистку веб-страниц в Твиттере с помощью библиотеки Python snsscrape и автоматически сохранять собранные данные в базе данных с помощью HarperDB.
Узнайте, как выполнять очистку веб-страниц в Твиттере с помощью библиотеки Python snsscrape и автоматически сохранять собранные данные в базе данных с помощью HarperDB.
50. Большие данные: 70 невероятных бесплатных данных, которые можно получить в 2020 году
 Пожалуйста, нажмите на оригинальную статью: http://www.octoparse.es/blog/70-fuentes-de-datos-gratuitas-en-2020
Пожалуйста, нажмите на оригинальную статью: http://www.octoparse.es/blog/70-fuentes-de-datos-gratuitas-en-2020
51. Парсинг с помощью Selenium 101: большая дыра в наборе инструментов для специалистов по данным [Часть 1]
 Веб-скрапинг, который обычно забывают во всех курсах и курсах по науке о данных, по моему честному мнению, является базовым инструментом в наборе инструментов Data Scientist, равно как и инструментом для получения и, следовательно, использования внешних данных из вашей организации, когда общедоступные базы данных недоступны.
Веб-скрапинг, который обычно забывают во всех курсах и курсах по науке о данных, по моему честному мнению, является базовым инструментом в наборе инструментов Data Scientist, равно как и инструментом для получения и, следовательно, использования внешних данных из вашей организации, когда общедоступные базы данных недоступны.
52 . Python для науки о данных: как очистить данные веб-сайта с помощью 300 лучших API в Интернете

53. Как составить список наблюдения за опционами Call OTM First Strike на основе Cashtags wHAOR
 Сегодня мы собираемся создать скрипт, который очищает Twitter для сбора биржевых символов. Мы будем использовать эти символы, чтобы очистить Yahoo Finance для получения данных об опционах на акции. Чтобы гарантировать возможность загрузки всех данных параметров, мы будем выполнять каждый веб-запрос с помощью луковой маршрутизации высокой доступности. В конце мы применим волшебство Pandas, чтобы перенести первый из контракта денежного колла для каждого символа в окончательный список наблюдения.
Сегодня мы собираемся создать скрипт, который очищает Twitter для сбора биржевых символов. Мы будем использовать эти символы, чтобы очистить Yahoo Finance для получения данных об опционах на акции. Чтобы гарантировать возможность загрузки всех данных параметров, мы будем выполнять каждый веб-запрос с помощью луковой маршрутизации высокой доступности. В конце мы применим волшебство Pandas, чтобы перенести первый из контракта денежного колла для каждого символа в окончательный список наблюдения.
Спасибо, что ознакомились с 53 самыми читаемыми историями о парсинге данных на HackerNoon.
Посетите репозиторий /Learn, чтобы найти самые читаемые статьи о любой технологии.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
15 наборов данных Excel для начинающих аналитиков данных
20 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27156)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)