

5 способов хранения рыночных данных: CSV, SQLite, Postgres, Mongo, Arctic
21 ноября 2022 г.Как лучше хранить рыночные данные?
Ну, это зависит от совокупности факторов. Среди наиболее важных я назову размер набора данных, частоту запросов на чтение и запись и желаемую задержку.
Итак, давайте погрузимся и создадим приложение, которое будет выполнять значительное количество операций CRUD и подключать его к различным базам данных. Мы будем использовать обычные файлы CSV, реляционные базы данных SQLite и Postgres и нереляционные базы данных Mongo и Arctic.
Мы будем измерять время выполнения следующих операций:
- добавить 1 тыс. записей одну за другой,
– массовое сохранение 1 млн записей,
- прочитать всю базу данных с 1 миллионом записей,
- сделать один запрос к базе данных с 1 млн записей
Мы также сравним размер базы данных для наборов данных размером 1 млн записей.
Чтобы создать этот миллион записей, мы будем использовать генератор синтетических данных, описанный здесь. р>

Сделаем обзор возможных вариантов хранения данных. Файлы CSV — это быстрый и удобный способ работы с данными электронных таблиц, но он не подходит для постоянного хранения данных. SQLite не требует настройки, работает быстро и стабильно — вероятно, лучший вариант для небольших проектов. Postgres — это готовая к производству база данных с открытым исходным кодом и множеством вариантов использования. Mongo — это альтернатива NoSQL, которая иногда может быть намного быстрее, чем базы данных SQL. Arctic создан на основе Mongo, чтобы сделать его еще более полезным для тех, кто работает с рыночными данными, поскольку Arctic по умолчанию поддерживает фреймы данных pandas и массивы NumPy.
Теперь поговорим о нашем приложении.
Мы создадим пять коннекторов к пяти различным хранилищам данных. Они будут состоять из четырех классов: Connector, ReaderApp, WriterApp и ServiceApp. На этот раз мы создадим некоторые коннекторы с нуля, а не будем использовать SQLAlchemy в образовательных целях.
Класс соединителя будет содержать служебные данные, такие как имена файлов и методы для создания таблиц.
ReaderApp будет содержать методы для чтения данных из базы данных и выполнения запроса.
class ReaderApp:
__metaclass__ = ABCMeta
@abstractmethod
def read_all_data(self):
'''reads all data from file/database'''
raise NotImplementedError("Should implement read_all_data()")
@abstractmethod
def read_query(self):
'''makes a specific query to file/database '''
raise NotImplementedError("Should implement read_query()")
WriterApp сохранит данные в базе данных.
class WriterApp:
__metaclass__ = ABCMeta
@abstractmethod
def append_data(self):
'''saves data line by line, like in real app '''
raise NotImplementedError("Should implement save_data()")
@abstractmethod
def bulk_save_data(self):
'''save all data at one time '''
raise NotImplementedError("Should implement bulk_save_data()")
А ServiceApp будет отвечать за очистку баз данных и статистики, включая размер базы данных.
class ServiceApp:
__metaclass__ = ABCMeta
@abstractmethod
def clear_database(self):
raise NotImplementedError("Should implement clear_database()")
@abstractmethod
def size_of_database(self):
raise NotImplementedError("Should implement size_of_database()")
После создания всех этих классов мы можем использовать их в нашем основном приложении MultiDatabaseApp. Он будет генерировать синтетические данные, выполнять операции CRUD, измерять время выполнения и строить диаграммы для визуализации результатов.
Самый питонический способ измерить время выполнения — использовать функцию декоратора. Он просто делает что-то до и после запуска «оформленной» части.
def execution_time(func):
#measures a database operation execution time
def measure_time(*args, **kwargs) -> dict:
start_time = time.time()
response = func(*args, **kwargs)
execution_time = time.time() - start_time
response['execution_time'] = execution_time
return response
return measure_time
Код доступен здесь.
Теперь все приготовления готовы, и мы можем начинать!

Первое действие — массовое сохранение 1 миллиона синтетических тиков. И Postgres, и Mongo работают медленно. Все настройки сервера базы данных установлены по умолчанию, что может быть причиной. Арктика здесь лидер!
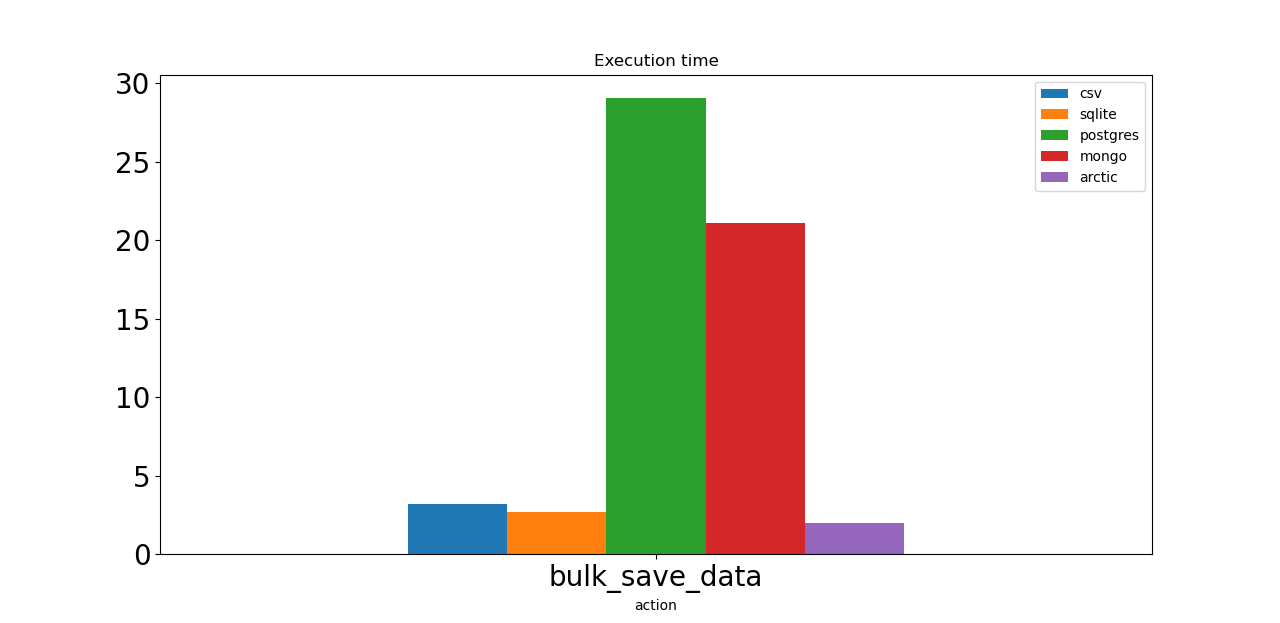 И CSV, и SQLite работают почти так же быстро, как Arctic.
И CSV, и SQLite работают почти так же быстро, как Arctic.

Следующий тест добавляет 1000 тиков один за другим. И опять же, Postgres — худший вариант. Монго здесь лидер; мы можем выбрать его, если нам нужно часто сохранять данные. Арктика, построенная на Монго, должна иметь такую же скорость. Тем не менее, я использовал VersionStore с 1 миллионом уже добавленных точек данных, поэтому Arctic каждый раз считывает эти данные, добавляет одну и сохраняет.
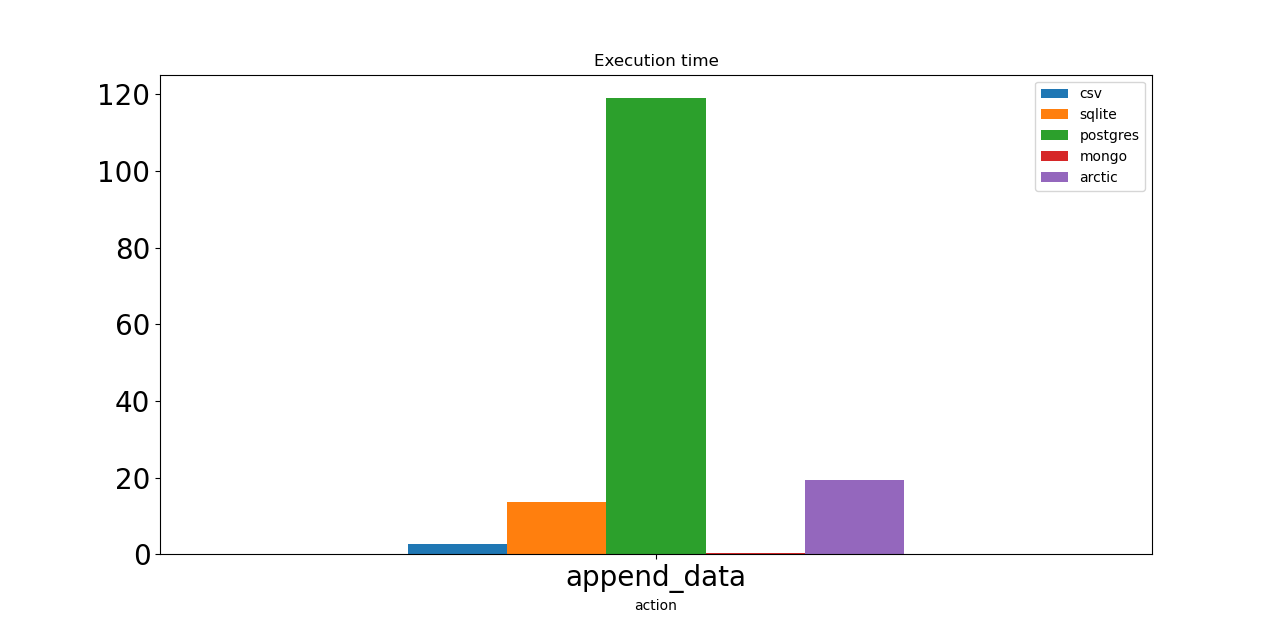
И CSV, и SQLite показывают достойные результаты.

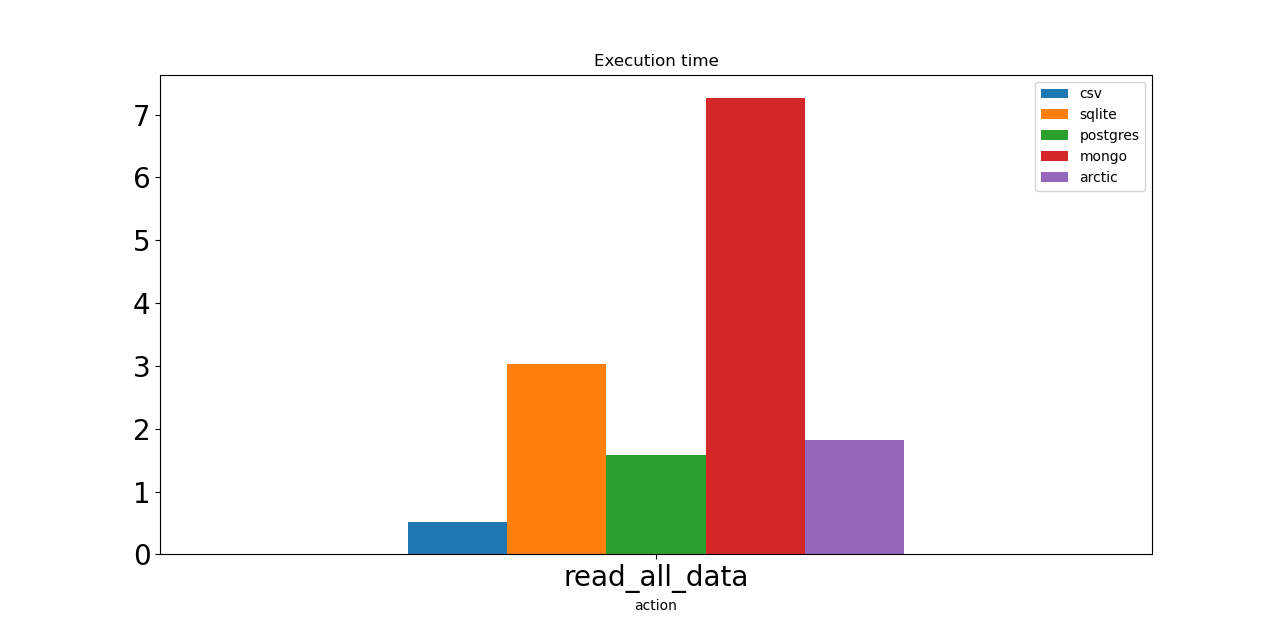
Теперь давайте проверим скорость операций чтения. Первый — это просто запрос на чтение всего набора данных. CSV показывает лучший результат. Операция выполняется менее чем за 1 секунду! Postgres и Arctic нужно почти 2 секунды, SQLite — 3 секунды. Монго — самая медленная лошадь, у нее 7 секунд.

Следующая операция для тестирования — это запрос на выбор только тех строк, в которых цена биткойна меньше 20 155. Базы данных SQL достаточно быстры, как и файлы CSV. Mongo и Arctic требуется больше времени для получения данных из базы данных.
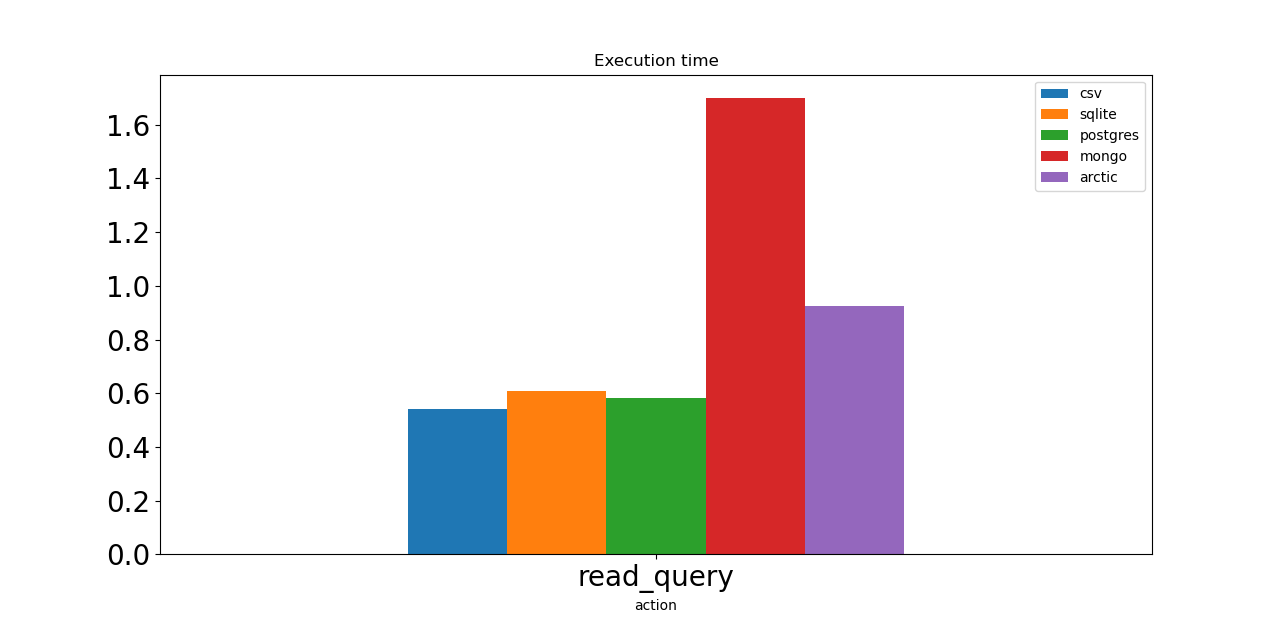

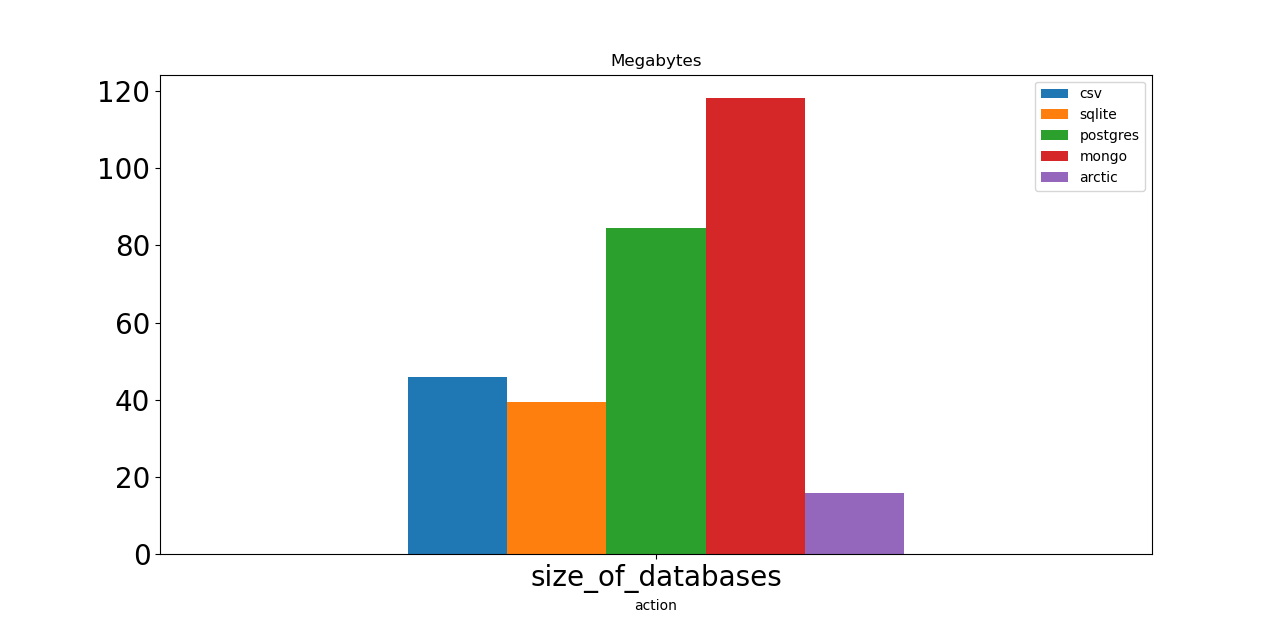
Теперь давайте проверим размеры нашей базы данных. Арктика как минимум в два раза лучше любого конкурента. Какой отличный результат! Базы данных CSV и SQLite имеют средний размер, около 40 МБ каждая. Postgres и Mongo требуется около 100 МБ для хранения одного и того же объема данных, а это означает, что если мы ограничены дисковым пространством или пропускной способностью, мы должны рассмотреть другие варианты.

Теперь давайте еще раз взглянем на создание времени выполнения операций.
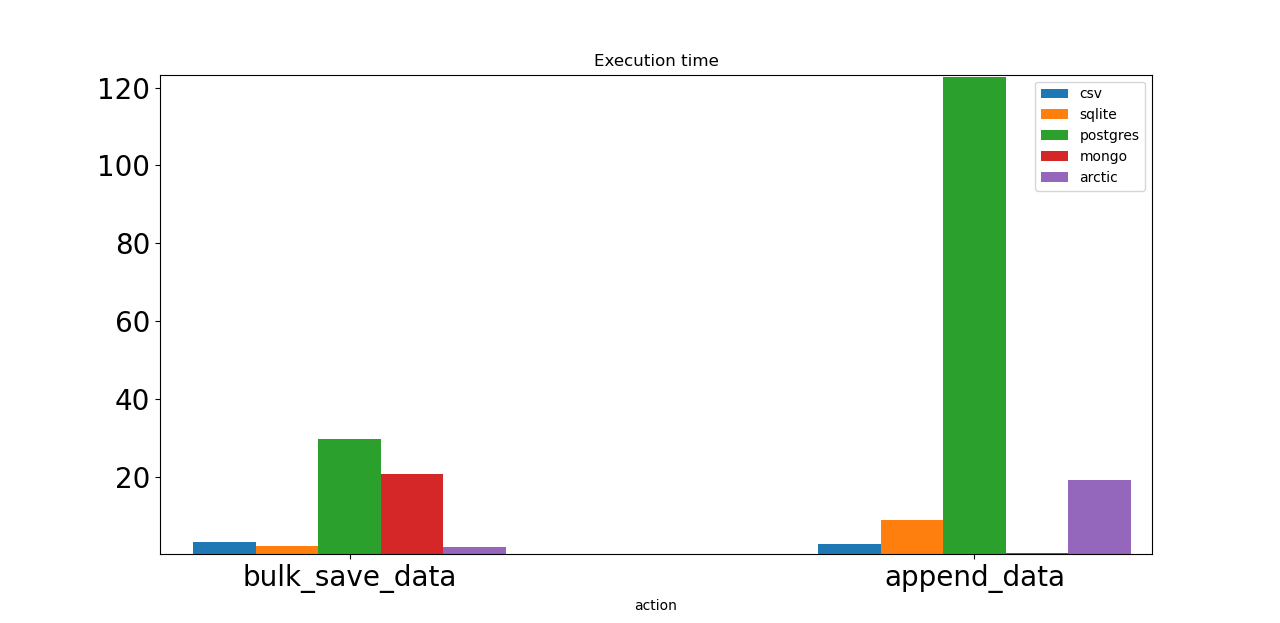
Мы можем выбрать Mongo и Arctic, если нам нужно выполнить много операций записи в нашей базе данных. Но на самом деле CSV и SQLite тоже могут быть нашим выбором. Postgres — самый медленный вариант, но есть способы решить эту проблему, например отправка асинхронных запросов на выделенный сервер базы данных.
Объединение операций чтения.
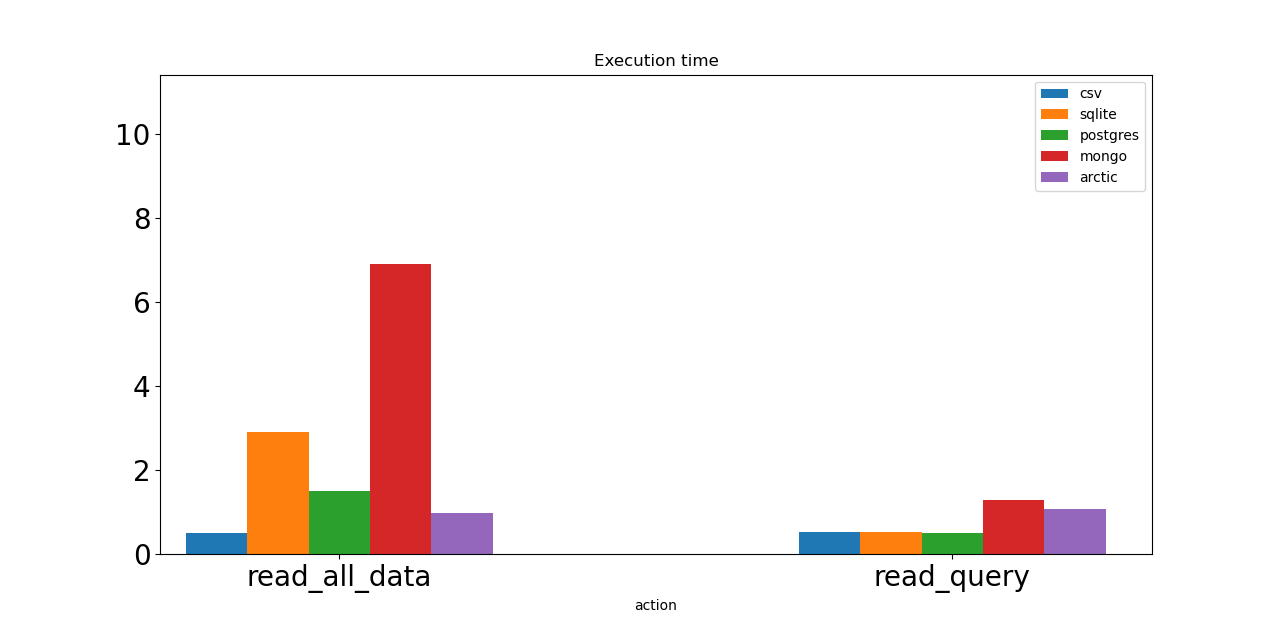
Постгрес выглядит здесь хорошим выбором. Конечно, CSV-файлы еще быстрее, но CSV — это не настоящая база данных. Арктика выглядит как отличный вариант для рассмотрения. Mongo — самый медленный.
Некоторые заключительные мысли. CSV и SQLite во многих случаях не являются готовым выбором для производства, но они могут быть простыми для множества небольших/средних проектов. У Postgres медленное время записи, поэтому он не выглядит как вариант для хранения рыночных данных. Mongo и Arctic могут быть хорошими вариантами, если мы говорим об огромном наборе данных, который невозможно сохранить в обычном файле CSV.
репозиторий Github с кодом.

Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27562)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)