

3 способа бесшовной интеграции данных с Seatunnel для потоковой передачи ETL
12 июня 2025 г.Seatunnel-это простая в использовании высокопроизводительную распределенную платформу интеграции данных, поддерживающая массовую синхронизацию данных в реальном времени. Он обладает стабильными и эффективными возможностями обработки, обеспечивает синхронизацию сотен миллиардов записей в день и широко используется в производственных средах более 3000 предприятий в Китае.
DataBend-это облачная платформа, разделенная на вычислительную подставку, с эластичностью и высокими функциями параллелизма, подходящей для современных требований к обработке данных.
Эта статья будет посвящена анализу плагина MySQL-CDC в Seatunnel и формате данных, выведенном по его раковине, и дальнейшего изучения осуществимости и пути реализации интеграции Seatunnel с данными данных в практических сценариях.
<!-усечение->
Seatunnel в целом является стандартным инструментом синхронизации данных:

Seatunnel и MySQL-CDC
Разъем CDC Seatunnel MySQL позволяет читать данные снимка и инкрементные данные из баз данных MySQL. В зависимости от стороны раковины, мы наблюдаем, можно ли напрямую использоваться данными данных MySQL-CDC напрямую.
Из тестирования компонентом синхронизации MySQL, используемого Seatunnel, по-видимому, является детезий-мискл-соединитель (тот же компонент, который используется Kafka Connect).
Конечно! Вот линейный перевод английского языка текста, который вы предоставили:
Источник: MySQL-CDC раковина: консоль
Задача - синхронизироватьwubx.t01Стол из MySQL с использованием seatunnel. Файл конфигурацииv2.mysql.streaming.conf
# v2.mysql.streaming.conf
env{
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 2000
}
source {
MySQL-CDC {
base-url="jdbc:mysql://192.168.1.100:3306/wubx"
username="wubx"
password="wubxwubx"
table-names=["wubx.t01"]
startup.mode="initial"
}
}
sink {
Console {
}
}
Начать сиденье
./bin/seatunnel.sh --config ./config/v2.mysql.streaming.conf -m local
Наблюдайте за журналами на терминале.
Наблюдается полная синхронизация
SELECT * FROM `wubx`.`t01`
Полученные данные следующие:
2025-05-07 14:28:21,914 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=1: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=INSERT : 1, databend
2025-05-07 14:28:21,914 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=2: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=INSERT : 3, MySQL
2025-05-07 14:28:21,914 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=3: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=INSERT : 4, Setunnel01
Полная синхронизация завершена.
Вставьте на сторону источника
insert into t01 values(5,'SeaTunnel');Seatunnel может непосредственно собирать постепенные данные с соответствующим видом действия = вставка.
2025-05-07 14:35:48,520 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=4: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=INSERT : 5, SeaTunnel
Обновление на стороне источника
update t01 set c1='MySQL-CDC' where id=5;
2025-05-07 14:36:47,455 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=5: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=UPDATE_BEFORE : 5, SeaTunnel
2025-05-07 14:36:47,455 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=6: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=UPDATE_AFTER : 5, MySQL-CDC
Удалить на стороне источника
delete from t01 where id=5;
2025-05-07 14:37:33,082 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=7: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=DELETE : 5, MySQL-CDC
Выход формата журнала консоли относительно ясен, что очень полезно для устранения неполадок и последующего использования.
Источник: MySQL-CDC раковина: MySQL
Основываясь на вышеуказанном тесте вывода MySQL-CDC на терминал, можно подтвердить, что операции вставки, обновления и удаления могут быть правильно захвачены и обработаны. Затем мы тестируем MySQL -CDC -> MySQL. Соответствующий файл конфигурацииv2.mysql.streaming.m.confЭто следующее:
#v2.mysql.streaming.m.conf
env{
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 2000
}
source {
MySQL-CDC {
base-url="jdbc:mysql://192.168.1.100:3306/wubx"
username="wubx"
password="wubxwubx"
table-names=["wubx.t01"]
startup.mode="initial"
}
}
sink {
jdbc {
url = "jdbc:mysql://192.168.1.100:3306/wubx?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
user = "wubx"
password = "wubxwubx"
generate_sink_sql = true
# You need to configure both database and table
database = wubx
table = s_t01
primary_keys = ["id"]
schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST"
data_save_mode="APPEND_DATA"
}
}
Вот линейный английский перевод предоставленного вами контента:
Начать сиденье
./bin/seatunnel.sh --config ./config/v2.mysql.streaming.m.conf -m local
Наблюдайте за журналами на терминале.
Анализ процесса синхронизации
Полные заявления о синхронизации:
2025-05-07 14:56:01,024 INFO [e.IncrementalSourceScanFetcher] [debezium-snapshot-reader-0] - Start snapshot read task for snapshot split: SnapshotSplit(tableId=wubx.t01, splitKeyType=ROW<id INT>, splitStart=null, splitEnd=null, lowWatermark=null, highWatermark=null) exactly-once: false
2025-05-07 14:56:01,026 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - Snapshot step 1 - Determining low watermark {ts_sec=0, file=mysql-bin.000058, pos=7737, gtids=12b437c2-ba62-11ec-a554-b4b5b694bca5:1-2215900, row=0, event=0} for split SnapshotSplit(tableId=wubx.t01, splitKeyType=ROW<id INT>, splitStart=null, splitEnd=null, lowWatermark=null, highWatermark=null)
2025-05-07 14:56:01,028 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - Snapshot step 2 - Snapshotting data
2025-05-07 14:56:01,028 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - Exporting data from split 'wubx.t01:0' of table wubx.t01
2025-05-07 14:56:01,028 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - For split 'wubx.t01:0' of table wubx.t01 using select statement: 'SELECT * FROM `wubx`.`t01`'
2025-05-07 14:56:01,032 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - Finished exporting 3 records for split 'wubx.t01:0', total duration '00:00:00.004'
2025-05-07 14:56:01,033 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - Snapshot step 3 - Determining high watermark {ts_sec=0, file=mysql-bin.000058, pos=7737, gtids=12b437c2-ba62-11ec-a554-b4b5b694bca5:1-2215900, row=0, event=0} for split SnapshotSplit(tableId=wubx.t01, splitKeyType=ROW<id INT>, splitStart=null, splitEnd=null, lowWatermark=null, highWatermark=null)
2025-05-07 14:56:01,519 INFO [o.a.s.c.s.c.s.r.f.SplitFetcher] [Source Data Fetcher for BlockingWorker-TaskGroupLocation{jobId=972391330309210113, pipelineId=1, taskGroupId=2}] - Finished reading from splits [wubx.t01:0]
Стоковая сторона подготовлена заявления SQL для написания данных:
2025-05-07 14:56:01,708 INFO [.e.FieldNamedPreparedStatement] [st-multi-table-sink-writer-1] - PrepareStatement sql is:
INSERT INTO `wubx`.`s_t01` (`id`, `c1`) VALUES (?, ?) ON DUPLICATE KEY UPDATE `id`=VALUES(`id`), `c1`=VALUES(`c1`)
2025-05-07 14:56:01,709 INFO [.e.FieldNamedPreparedStatement] [st-multi-table-sink-writer-1] - PrepareStatement sql is:
DELETE FROM `wubx`.`s_t01` WHERE `id` = ?
Из приведенных выше утверждений видно, что соответствующие события Binlog могут быть обработаны непосредственно следующим образом:
- Вставка и обновление могут быть обработаны непосредственно с помощью заявления:
INSERT INTO wubx.s_t01 (id, c1) VALUES (?, ?) ON DUPLICATE KEY UPDATE id=VALUES(id), c1=VALUES(c1) - Удалить может быть обработана с помощью заявления:
DELETE FROM wubx.s_t01 WHERE id = ?
Краткое содержание
Seatunnel MySQL-CDC относительно стабилен. В лечении данных используется Debezium, который является очень зрелым и надежным инструментом.
Источник: MySQL-CDC Sind: S3 Format JSON
В этом разделе фокусируется на основе синхронизации данных в облачных средах, особенно на том, как завершить синхронизацию данных при самых низких затратах. При синхронизации данных в облаке необходимо учитывать, как выполнить задачу с минимальными затратами. В зарубежных проектах разработчики предпочитают использовать Cafka-Connect, обычно сначала тонущая данные в S3, а затем обрабатывают файлы в S3 в партии, чтобы наконец получить полный набор данных.
Используйте файл конфигурацииv2.mysql.streaming.s3.confнапрямую:
env{
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 2000
}
source {
MySQL-CDC {
base-url="jdbc:mysql://192.168.1.100:3306/wubx"
username="wubx"
password="wubxwubx"
table-names=["wubx.t01"]
startup.mode="initial"
}
}
sink {
S3File {
bucket = "s3a://mystage"
tmp_path = "/tmp/SeaTunnel/${table_name}"
path="/mysql/${table_name}"
fs.s3a.endpoint="http://192.168.1.100:9900"
fs.s3a.aws.credentials.provider="org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider"
access_key = "minioadmin"
secret_key = "minioadmin"
file_format_type="json"
schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST"
data_save_mode="APPEND_DATA"
}
}
Во -первых, тока с использованием формата JSON.
Начать сиденье
./bin/seatunnel.sh --config ./config/v2.mysql.streaming.s3.conf -m local
Наблюдайте за журналами на терминале.
Обнаружил полную синхронизацию
2025-05-07 15:14:41,430 INFO [.c.s.f.h.HadoopFileSystemProxy] [hz.main.generic-operation.thread-42] - rename file :[/tmp/SeaTunnel/t01/SeaTunnel/972396021571125249/c679929b12/T_972396021571125249_c679929b12_0_1/NON_PARTITION/T_972396021571125249_c679929b12_0_1_0.json] to [/mysql/t01/T_972396021571125249_c679929b12_0_1_0.json] finish
Содержание/mysql/t01/T_972396021571125249_c679929b12_0_1_0.json:
{"id":1,"c1":"databend"}
{"id":3,"c1":"MySQL"}
{"id":4,"c1":"Setunnel01"}
{"id":5,"c1":"SeaTunnel"}
Видеть, что это несколько разочаровывает; Кажется, в нем не хватает полями и полям времени.
Вставьте на сторону источника
Следующий,insert into t01 values(6,'SeaTunnel01');
2025-05-07 15:18:59,380 INFO [.c.s.f.h.HadoopFileSystemProxy] [hz.main.generic-operation.thread-16] - rename file :[/tmp/SeaTunnel/t01/SeaTunnel/972396021571125249/c679929b12/T_972396021571125249_c679929b12_0_130/NON_PARTITION/T_972396021571125249_c679929b12_0_130_0.json] to [/mysql/t01/T_972396021571125249_c679929b12_0_130_0.json] finish
СодержаниеT_972396021571125249_c679929b12_0_130_0.json:
{"id":6,"c1":"SeaTunnel01"}
Обновление на стороне источника
Оператор выполнения:
update t01 set c1='MySQL-CDC' where id=5;
Информация о журнале:
2025-05-07 15:20:15,386 INFO [.c.s.f.h.HadoopFileSystemProxy] [hz.main.generic-operation.thread-9] - rename file :[/tmp/SeaTunnel/t01/SeaTunnel/972396021571125249/c679929b12/T_972396021571125249_c679929b12_0_168/NON_PARTITION/T_972396021571125249_c679929b12_0_168_0.json] to [/mysql/t01/T_972396021571125249_c679929b12_0_168_0.json] finish
Соответствующий содержимое файла JSON:
{"id":5,"c1":"SeaTunnel"}
{"id":5,"c1":"MySQL-CDC"}
Одна операция обновления записала две строки данных в файле JSON, но из -за отсутствия типа работы (kind) и поля временной метки, трудно точно восстановить процесс изменения данных. Если было включено поле временной метки, можно было бы соблюдать последнюю запись.
Сторона источника удалить
Оператор выполнения:
delete from t01 where id=5;
Информация о журнале:
2025-05-07 15:22:53,392 INFO [.c.s.f.h.HadoopFileSystemProxy] [hz.main.generic-operation.thread-6] - rename file :[/tmp/SeaTunnel/t01/SeaTunnel/972396021571125249/c679929b12/T_972396021571125249_c679929b12_0_247/NON_PARTITION/T_972396021571125249_c679929b12_0_247_0.json] to [/mysql/t01/T_972396021571125249_c679929b12_0_247_0.json] finish
Соответствующий содержимое файла JSON:
{"id":5,"c1":"MySQL-CDC"}
В операции удаления также не хватает типа операции (kind) и записывает только одну исходную строку данных, что затрудняет последующую обработку и отслеживание данных.
Краткое содержание
Таким образом, использование Seatunnel S3File раковины с форматом JSON для отслеживания данных в настоящее время невозможно. Рекомендуется, чтобы раковина S3File добавила поддержкуmaxwell_jsonиdebezium_jsonформаты.
https://github.com/apache/seatunnel/issues/9278
С нетерпением жду улучшения этой функции, так что Seatunnel может синхронизировать все данные с S3, позволяя S3 играть роль очереди сообщений.
Источник: MySQL-CDC раковина: kafka
Мир с открытым исходным кодом очень интересный; Если функция не достижима, всегда есть альтернатива. Поскольку MySQL-CDC основан на детезиуме внизу, он должен поддерживать формат детезиума.
https://seatunnel.apache.org/docs/2.3.10/connector-v2/formats/debezium-jsonТакже поддерживаетhttps://seatunnel.apache.org/docs/2.3.10/connector-v2/formats/maxwell-json
Это означает, что Seatunnel, чтобы поддерживать совместимость с Дебезиумом и Максвеллом, поддерживает выбор этих двух форматов при погружении в Кафку.
Дебезий-Json
{
"before": {
"id": 111,
"name": "scooter",
"description": "Big 2-wheel scooter ",
"weight": 5.18
},
"after": {
"id": 111,
"name": "scooter",
"description": "Big 2-wheel scooter ",
"weight": 5.17
},
"source": {
"version": "1.1.1.Final",
"connector": "mysql",
"name": "dbserver1",
"ts_ms": 1589362330000,
"snapshot": "false",
"db": "inventory",
"table": "products",
"server_id": 223344,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 2090,
"row": 0,
"thread": 2,
"query": null
},
"op": "u",
"ts_ms": 1589362330904,
"transaction": null
}
Данные вышеупомянутого формата могут быть легко обработаны в DataBend или Snowflake. Вы можете использовать поля
"op": "u",
"ts_ms": 1589362330904,
чтобы объединить данные в целевую таблицу черезmerge into + streamметод
Максвелл-Json
{
"database":"test",
"table":"product",
"type":"insert",
"ts":1596684904,
"xid":7201,
"commit":true,
"data":{
"id":111,
"name":"scooter",
"description":"Big 2-wheel scooter ",
"weight":5.18
},
"primary_key_columns":[
"id"
]
}
Это тело JSON содержитtypeВtsи первичные поля, что делает его очень удобным для использования SQL для обработки ELT позже.
Краткое содержание
Другими словами, если вы хотите вывести такого рода стандартные журналы форматов CDC с использованием Seatunnel, вам необходимо представить кафка-подобную архитектуру:
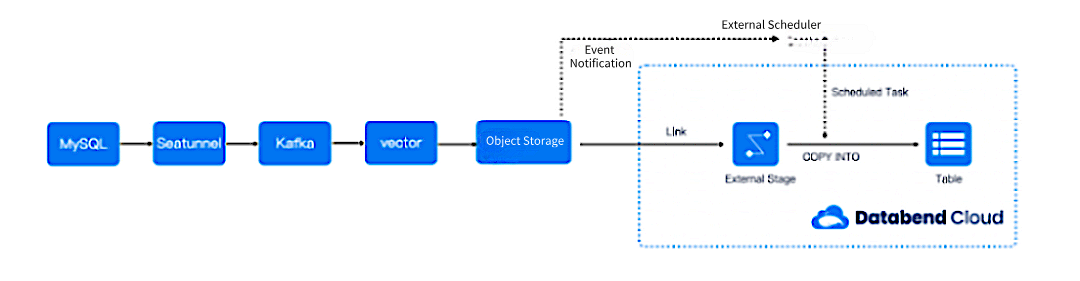
Поговорив с членами сообщества, оказывается, что некоторые люди делают это - сингуляция сообщений от Кафки до Осс.
Пример интеграции тела сообщений Maxwell-JSON с DataBend
- Создайте таблицу обновлений для записи сведения о сообщении Binlog:
create table t01_update(
database varchar,
table varchar,
type varchar,
ts bigint,
xid bigint,
commit boolean,
data variant,
primary_key_columns array(varchar)
);
Источник данных этой таблицы может быть получен из S3 и загружен вблизи в реальном времени вt01_updateс использованиемcopy intoПолем
- Создайте целевую таблицу:
create table t01(
id int,
name varchar,
description varchar,
weight double
);
- Создать поток на
t01_updateТаблица, чтобы запечатлеть их приращения:
create stream stream_t01_update on table t01_update;
- Объедините данные в целевую таблицу в DataBend:
MERGE INTO t01 AS a
USING (
SELECT
data:id AS id,
data:name AS name,
data:description AS description,
data:weight AS weight,
ts,
type
FROM stream_t01_update
QUALIFY ROW_NUMBER() OVER (PARTITION BY id ORDER BY ts DESC) = 1
) AS b
ON a.id = b.id
WHEN MATCHED AND b.type = 'update' THEN
UPDATE SET
a.name = b.name,
a.description = b.description,
a.weight = b.weight
WHEN MATCHED AND b.type = 'delete' THEN
DELETE
WHEN NOT MATCHED THEN
INSERT (id, name, description, weight)
VALUES (b.id, b.name, b.description, b.weight);
Этот SQL использует дедупликацию окна, чтобы объединить необработанные данные Binlog в целевую таблицу.
Подходы интеграции Seatunnel и Databend
Основываясь на анализе форм вывода MySQL-CDC, существует три способа интеграции Seatunnel с DataBend:
- Первый подход: непосредственно разрабатывайте разъем Seatunnel для DataBend, поддерживающего как раковину, так и источник. Это проще в реализации.
- Второй подход: добавьте поддержку
debezium-jsonиmaxwell-jsonФорматы в раковине S3file, что более элегантно. Инкрементные данные могут затем основываться на потоке данных DataBend для удобного доступа к источнику внешнего источника данных. - Третий подход: представьте Kafka в качестве раковины Seatunnel для непосредственного использования
debezium-jsonиmaxwell-jsonСообщения, позволяющие нисходящим системам подписать данные о увеличении с помощью управления данными.
Тестируя многочисленные форматы и поведение Seatunnel, мы предварительно понимаем возможности Seatunnel MySQL-CDC, подготовившись к интеграции с DataBend. В сочетании с Seatunnel в сочетании с Seatunnel уже может выполнять большие задачи CDC. Если у вас есть связанные практики, бесплатно бесплатно поделиться ими в комментариях!
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27360)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)