
16 приемов SQL, которые должен знать каждый новичок
11 февраля 2023 г.
По шкале от 1 до 10, насколько хороши ваши навыки работы с хранилищами данных?
Хотите подняться выше 7/10? Тогда эта статья для вас.
Насколько хорош ваш SQL? Хотите как можно скорее подготовиться к собеседованию?
В этом сообщении блога подробно описаны самые сложные методы SQL хранилища данных. Я воспользуюсь стандартным диалектом SQL BigQuery, чтобы набросать несколько мыслей по этой теме.
1. Добавочные таблицы и MERGE
Обновление таблицы важно. Это действительно важно. Идеальная ситуация, когда у вас есть транзакции, которые являются ПЕРВИЧНЫМ ключом, уникальными целыми числами и автоинкрементом. Обновление таблицы в этом случае простое:
https://gist.github.com/mshakhomirov/18775cbbe8288af864ad79247c0de63d?embedable =true#файл-1-1-sql
Это не всегда так при работе с денормализованными наборами данных звездообразной схемы в современных хранилищах данных. вам может быть предложено создать сеансы с помощью SQL и/или поэтапно обновить наборы данных, используя только часть данных. transaction_id может не существовать, но вместо этого вам придется иметь дело с моделью данных, где уникальный ключ зависит от последнего известного transaction_id (или метки времени). Например, user_id в наборе данных last_online зависит от последней известной метки времени подключения. В этом случае вам нужно обновить существующих пользователей и вставить новых.
ОБЪЕДИНЕНИЕ и добавочные обновления
Вы можете использовать MERGE или разделить операцию на два действия. Один для обновления существующих записей новыми и один для вставки совершенно новых, которые не завершаются (ситуация LEFT JOIN).
MERGE – это оператор, который обычно используется в реляционных базах данных. Команда Google BigQuery MERGE — это одна из инструкций языка манипулирования данными (DML). Он часто используется для атомарного выполнения трех основных функций в одном операторе. Это функции ОБНОВЛЕНИЕ, ВСТАВКА и УДАЛЕНИЕ.
* Условие UPDATE или DELETE можно использовать, когда совпадают два или более данных. * Предложение INSERT можно использовать, когда два или более данных различны и не совпадают. * Предложение UPDATE или DELETE также можно использовать, когда предоставленные данные не соответствуют источнику.
Это означает, что команда Google BigQuery MERGE позволяет объединять данные Google BigQuery, обновляя, вставляя и удаляя данные из таблиц Google BigQuery.
Рассмотрите этот SQL:
https://gist.github.com/mshakhomirov/5ad1a7518c54bc030d1c78b56fe3cf82?embedable =true#файл-1-2-sql
2. Подсчет слов
Выполнение UNNEST() и проверка наличия нужного слова в списке, который вам нужен, может быть полезен во многих ситуациях, например при анализе настроений хранилища данных:
https://gist.github.com/mshakhomirov/694e040539b0d1b556f8e053d315a3bf?embedable=true #file-2-sql
3. Использование оператора IF() вне оператора SELECT
Это дает нам возможность сэкономить несколько строк кода и сделать код более красноречивым. Обычно вы хотели бы поместить это в подзапрос и добавить фильтр в предложении where, но вместо этого вы можете сделать это:
https://gist.github.com/mshakhomirov/933e6a358e49dcccd4e547a5509c8fda?embedable=true #file-3-sql
Еще один пример того, как НЕ использовать его с разделенными таблицами. Не делайте этого. Это плохой пример, поскольку, поскольку суффиксы совпадающих таблиц, вероятно, определяются динамически (на основе чего-то в вашей таблице), вы будете платить за полное сканирование таблицы.
https://gist.github.com/mshakhomirov/1c62d79cd9690140c569cd047b9d491f?embedable =true#file-3-2-sql
Вы также можете использовать его в предложении HAVING и функциях AGGREGATE.
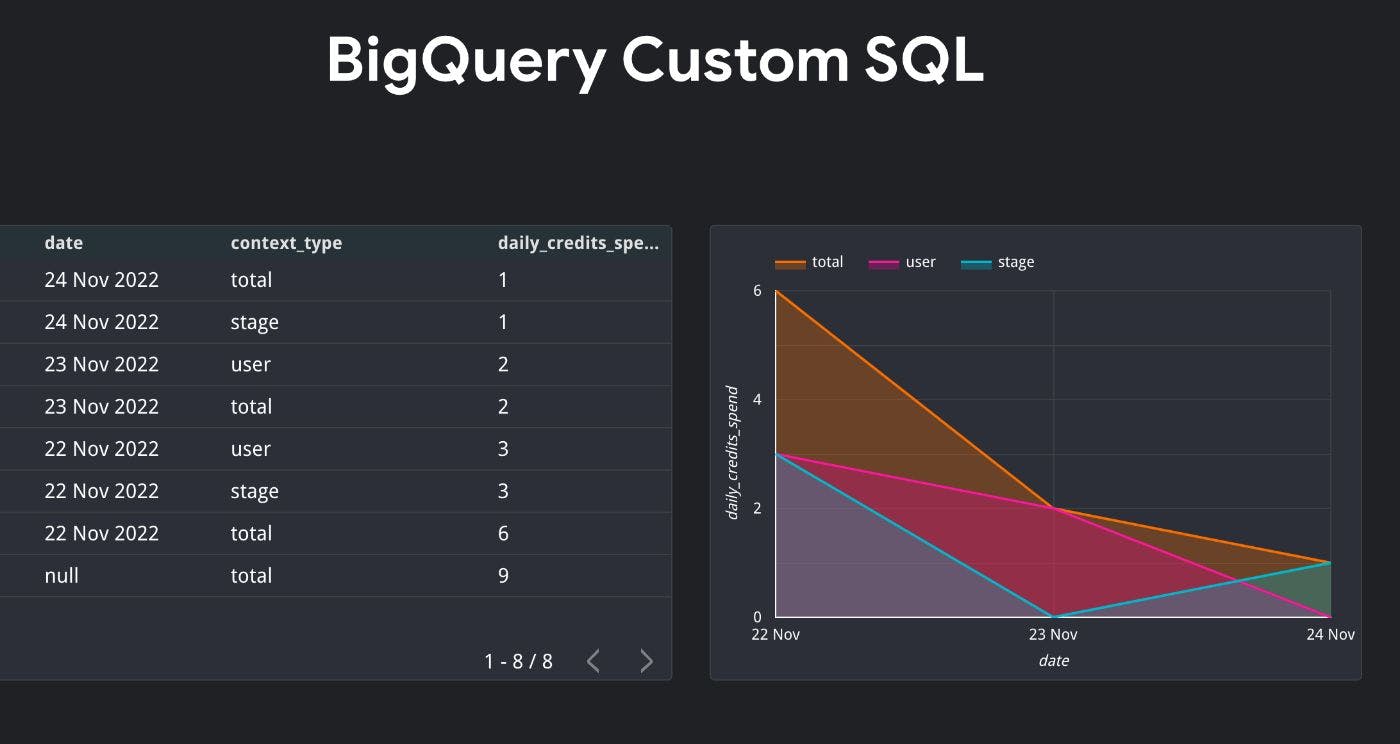
4. Использование GROUP BY ROLLUP
Функция ROLLUP используется для агрегирования на нескольких уровнях. Это полезно, когда вам нужно работать с диаграммами измерений.
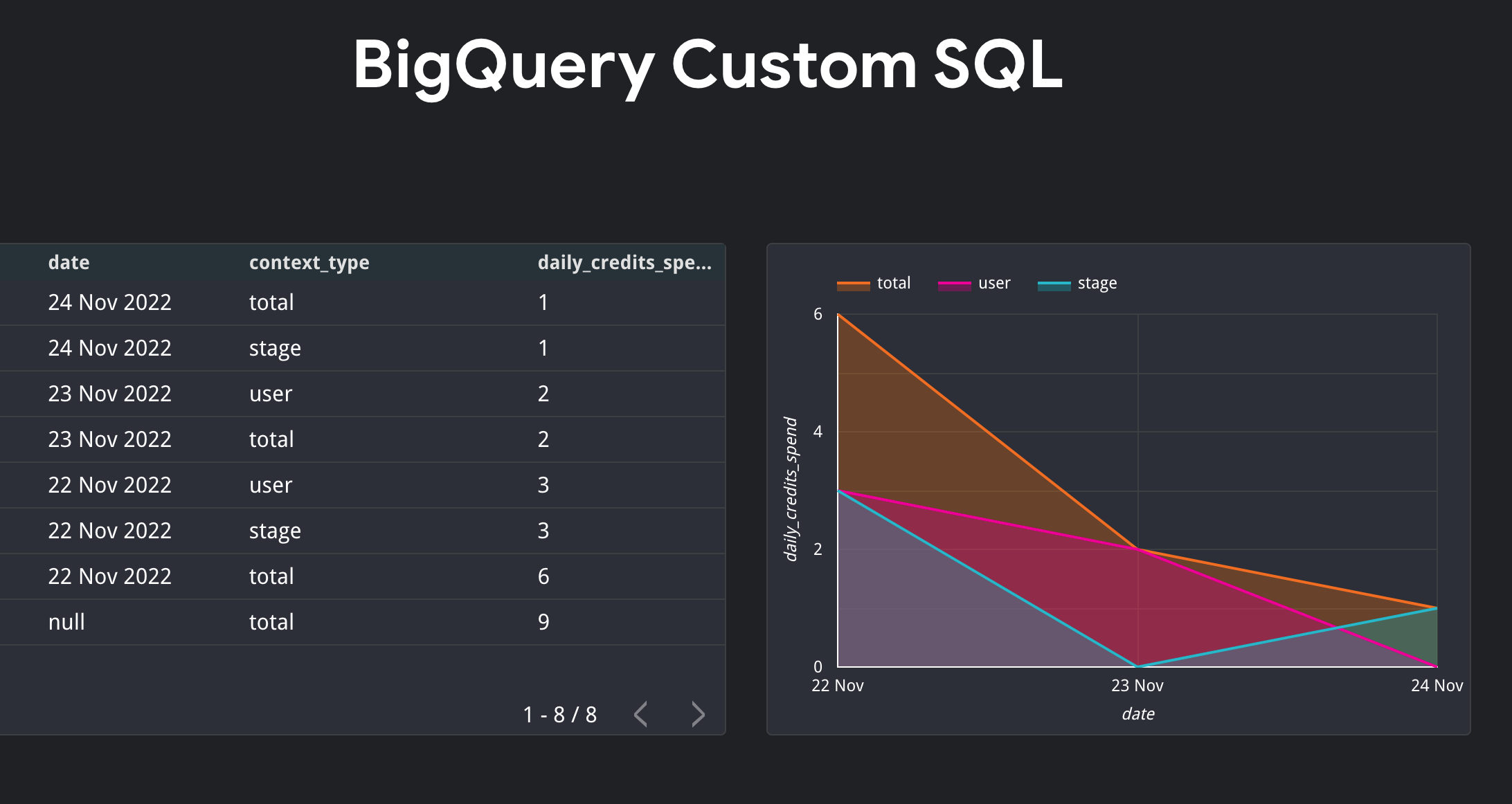
Следующий запрос возвращает общий расход кредита за день по типу транзакции (is_gift), указанному в предложении where, а также показывает общий расход за каждый день и общий расход по всем доступные даты.
https://gist.github.com/mshakhomirov/4cf738aaad967fe92c4fb7192874fadf?embedable=true #file-4-sql
5. Преобразовать таблицу в JSON
Представьте, что вам нужно преобразовать таблицу в объект JSON, где каждая запись является элементом вложенного массива. Вот где функция to_json_string() становится полезной:
https://gist.github.com/mshakhomirov/aac1f93312ae305ba80c915fe4a2a386?embedable=true #file-5-sql
Тогда вы можете использовать его где угодно: даты, маркетинговые воронки, индексы, гистограммы и т. д.
6. Использование РАЗДЕЛА ПО
Учитывая столбцы user_id, date и total_cost. Для КАЖДОЙ даты, как вы показываете общее значение дохода для КАЖДОГО клиента, сохраняя при этом все строки? Вы можете добиться этого следующим образом:
https://gist.github.com/mshakhomirov/e4f11721eb5a3182150df08f25b70d64?embedable=true #file-6-sql
7. Скользящее среднее
Очень часто перед разработчиками бизнес-аналитики стоит задача добавить скользящее среднее значение в свои отчеты и фантастические информационные панели. Это может быть 7-, 14-, 30-дневный/месячный или даже годовой линейный график MA. Итак, как мы это делаем?
https://gist.github.com/mshakhomirov/ebf5488d0036bc9b84ae05889346d986?embedable=true #file-7-sql
8. Массивы дат
Очень удобно, когда вы работаете с удержанием пользователей или хотите проверить набор данных на предмет отсутствующих значений, например дат. В BigQuery есть функция GENERATE_DATE_ARRAY:
https://gist.github.com/mshakhomirov/2ba5a67053f85794462dab98e56ad74d?embedable=true #file-8-sql
9. Номер_строки()
Это полезно для получения последних данных из ваших данных, например последней обновленной записи и т. д., или даже для удаления дубликатов:
https://gist.github.com/mshakhomirov/05d0c04c5975207d98552ffd436add8b?embedable=true #file-9-sql
10. NTILE()
Еще одна функция нумерации. Действительно полезно отслеживать такие вещи, как длительность входа в систему в секундах, если у вас есть мобильное приложение. Например, мое приложение подключено к Firebase, и когда пользователи логин, я могу видеть, сколько времени им потребовалось.
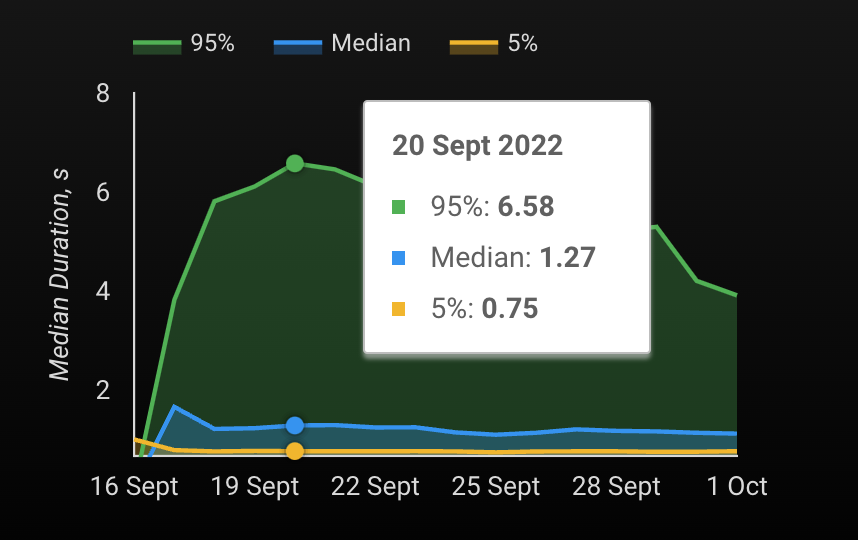
Эта функция делит строки на сегменты constant_integer_expression в зависимости от порядка строк и возвращает номер сегмента с отсчетом от 1, назначенный каждой строке. Количество строк в корзинах может отличаться не более чем на 1. Остаточные значения (остаток от числа строк, разделенных на корзины) распределяются по одному для каждой корзины, начиная с корзины 1. Если constant_integer_expression оценивает равно NULL, 0 или отрицательному, возникает ошибка.
https://gist.github.com/mshakhomirov/16fe941aa8c4ed79e4aad8b7049b307a?embedable=true #file-10-sql
11. Ранг/плотный_ранг
Их также называют функциями нумерации. Я предпочитаю использовать DENSE_RANK в качестве функции ранжирования по умолчанию, так как она не пропускает следующий доступный рейтинг, в отличие от RANK. Он возвращает последовательные значения ранга. Вы можете использовать его с разделом, который делит результаты на отдельные сегменты. Строки в каждом разделе получают одинаковые ранги, если они имеют одинаковые значения. Пример:
https://gist.github.com/mshakhomirov/459b68c5f3d1e8284c01e516db1d8dcb?embedable =true#file-11-1-sql
Еще один пример с ценами на товары:
https://gist.github.com/mshakhomirov/4c90a6fc8516d8264e172676a83a1048?embedable =true#file-11-2-sql
12. Свернуть/развернуть
Pivot заменяет строки столбцами. Это все, что он делает. Unpivot делает противоположное.
https://gist.github.com/mshakhomirov/f90b035ba259e672d4d51a669e0cd1fc?embedable=true #file-12-sql
13. Первое_значение/последнее_значение
Это еще одна полезная функция, которая помогает получить дельту для каждой строки относительно первого/последнего значения в этом конкретном разделе.
https://gist.github.com/mshakhomirov/ea4de9144b97bf8c196cab07609c309e?embedable=true #file-13-sql
14. Преобразование таблицы в массив структур и передача их в UDF
Это полезно, когда вам нужно применить определяемую пользователем функцию (UDF) с некоторой сложной логикой к каждой строке или таблице. Вы всегда можете рассматривать свою таблицу как массив объектов TYPE STRUCT, а затем передавать каждый из них в UDF. Это зависит от вашей логики. Например, я использую его для расчета времени истечения срока действия покупки:
https://gist.github.com/mshakhomirov/35d956fa9db86b12b44ab62c00f42a40?embedable=true #file-14-sql
Похожим образом вы можете создавать таблицы без использования UNION ALL. Например, я использую его для имитации некоторых тестовых данных для модульных тестов. Таким образом, вы можете сделать это очень быстро, просто используя Alt+Shift+Down в вашем редакторе.
https://gist.github.com/mshakhomirov/6ea226c1b5b789d4a31691ce065c20d7?embedable =true#file-14-2-sql
15. Создание воронок событий с использованием FOLLOWING AND UNBOUNDED FOLLOWING
Хорошим примером могут служить маркетинговые воронки. Ваш набор данных может содержать постоянно повторяющиеся события одного и того же типа, но в идеале вы хотели бы связать каждое событие со следующим событием другого типа. Это может быть полезно, когда вам нужно получить список чего-то, например, событий, покупок и т. д., чтобы создать набор данных воронки. Работа с PARTITION BY дает вам возможность сгруппировать все следующие события, независимо от того, сколько их существует в каждом разделе.
https://gist.github.com/mshakhomirov/05fd7d79d8acf3b173181a5d950ab6e7?embedable=true #file-15-sql
16. Регулярное выражение
Вы можете использовать его, если вам нужно извлечь что-то из неструктурированных данных, например валютные курсы, пользовательские группы и т. д.
Работа с курсами обмена валют с использованием регулярного выражения
Рассмотрите этот пример с данными об обменных курсах:
https://gist.github.com/mshakhomirov/9ca6e153da19c491034bd57995875308?embedable =true#file-16-1-sql
Работа с версиями приложений с использованием регулярных выражений
Иногда вам может понадобиться использовать regexp, чтобы получить основную, выпускную или модифицированную версию вашего приложения и создать собственный отчет:
https://gist.github.com/mshakhomirov/b1f442a296ffef52c7baa1245e1dc316?embedable =true#file-16-2-sql
Заключение
SQL — это мощный инструмент, помогающий манипулировать данными. Надеюсь, эти примеры использования SQL из цифрового маркетинга будут вам полезны. Это действительно полезный навык, который может помочь вам во многих проектах. Эти фрагменты SQL сделали мою жизнь намного проще, и я использую их на работе почти каждый день. Более того, SQL и современные хранилища данных являются важнейшими инструментами для науки о данных. Его надежные диалектные функции позволяют легко моделировать и визуализировать данные. Поскольку SQL — это язык, который используют специалисты по хранилищам данных и бизнес-аналитике, это отличный выбор, если вы хотите поделиться с ними данными. Это наиболее распространенный способ связи практически со всеми решениями для хранилищ данных и озер, представленными на рынке.
Первоначально опубликовано на mydataschool.com автором датамайк
Майк — страстный и сосредоточенный на цифровых технологиях человек с огромным драйвом и энтузиазмом, ему нравятся проблемы, которые бросает полный набор цифрового маркетинга. Живет в Великобритании, в 2015 году получил степень магистра делового администрирования в Университете Ньюкасла.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)