

13 лучших наборов данных для практики Power BI
8 февраля 2023 г.В 2022 году компания Gartner назвала Microsoft Power BI лидером среди платформ бизнес-аналитики и аналитики.
С помощью инструментов бизнес-аналитики, таких как Microsoft Power BI, неструктурированные данные могут подвергаться процессам извлечения, очистки и анализа для получения сведений, которые помогают организациям принимать решения на основе данных.
В этой статье мы рассмотрим 13 лучших наборов данных для практики Power BI, которые необходимы специалистам по работе с данными для повышения квалификации в Power BI.
Список лучших наборов данных для практики Power BI
1. Пример продаж в супермаркетах
Набор данных Sample Superstore Sales содержит данные о продажах вымышленной розничной компании, включая информацию о продуктах, заказах и клиентах.
Этот набор данных включает следующие переменные:
* Идентификатор заказа — уникальный идентификатор для каждого заказа. * Идентификатор клиента — уникальный идентификатор для каждого клиента. * Дата заказа - Дата размещения заказа. * Дата отправки — дата отправки заказа. * Режим доставки — режим доставки заказа (например, стандартный, в тот же день). * Сегмент — сегмент клиента (например, потребительский, корпоративный, домашний офис). * Регион — регион, в котором находится клиент (например, Западный, Центральный, Восточный). * Категория — категория приобретенного товара (например, «Мебель», «Технологии», «Офисные товары»). * Подкатегория — подкатегория приобретенного продукта (например, стулья, рабочие столы, бумага). * Название продукта - название приобретенного продукта. * Продажи — доход от продаж приобретенного продукта. * Количество - Количество единиц купленного товара. * Скидка - Скидка на приобретенный товар. * Прибыль — прибыль, полученная от приобретенного продукта.
2. Хранилище данных Adventure Works
Хранилище данных Adventure Works — это образец базы данных для служб Microsoft SQL Server Analysis Services (SSAS). Он предлагает многомерную модель данных для вымышленного производителя велосипедов Adventure Works Cycles. Он также содержит информацию о каталогах продуктов, продажах, демографических данных клиентов и временных данных для анализа и анализа. отчетность.
Этот набор данных включает следующие переменные:
* Клиент. Сюда входят демографические данные клиентов, такие как возраст, пол, образование и доход. * Продажи — включает информацию о продажах, такую как территория продаж, продавец и дата заказа. * Продукт. Сюда входят категории продуктов, подкатегории и названия продуктов. * Дата — включает дату и связанные атрибуты, такие как квартал, месяц, день и день недели. *География — сюда входят штат, город, почтовый индекс и заказы клиентов.
To download this dataset, you can click здесь.
3. Задержки и отмены рейсов
Этот реальный набор данных содержит данные о номерах рейсов, вылетах, авиакомпаниях, времени прибытия и причинах любых задержек или отмен. С помощью этого набора данных пользователи Power BI выполняют анализ данных и создают интерактивные информационные панели для выявления наиболее распространенных причин сбоев рейсов путем изучения частоты отмен авиалиний и задержек рейсов.
Он включает следующие переменные:
* Продолжительность полета - продолжительность времени от вылета до прибытия на рейс. * Причина задержки — причина любой задержки рейса. Примеры могут включать погоду, механические проблемы или управление воздушным движением. * Время задержки — количество времени, на которое рейс был задержан. * Cancellation Reason - Причина отмены рейса. Примеры могут включать погодные условия, механические проблемы или недостаточный пассажиропоток. * Дата полета - Дата, когда состоялся полет. * Номер рейса — уникальный идентификатор, присваиваемый авиакомпанией каждому рейсу. * Название авиакомпании — название авиакомпании, выполняющей рейс. * Аэропорт вылета — аэропорт, из которого планируется вылет рейса. * Аэропорт прибытия — аэропорт, в который должен прибыть рейс. * Запланированное время вылета — время вылета рейса согласно первоначальному плану авиакомпании. * Фактическое время вылета — фактическое время вылета рейса, если оно отличается от запланированного времени вылета. * Запланированное время прибытия — время прибытия рейса согласно первоначальному плану авиакомпании. * Фактическое время прибытия — фактическое время прибытия рейса, если оно отличается от запланированного времени прибытия.
4. Данные такси Нью-Йорка
NYC Taxi Data – это обширный и сложный набор данных, который содержит информацию о поездках на такси в Нью-Йорке, включая продолжительность поездки, стоимость проезда, а также места посадки и высадки пассажиров. Он охватывает миллионы поездок и охватывает несколько лет, предоставляя обширный источник информации о городской мобильности и транспортных схемах в городе.
Анализируя эти данные, вы можете получить представление о различных областях индустрии такси в Нью-Йорке. Например, вы можете визуализировать распределение поездок по времени и пространству, а также определить горячие точки активности такси в городе.
Набор данных включает следующие переменные:
* Продолжительность поездки — продолжительность поездки в секундах. * Trip Distance — расстояние, пройденное на такси, в милях. * Количество пассажиров - Общее количество пассажиров в такси. * Сумма тарифа — стоимость проезда, взимаемая с пассажира, в долларах. * Способ оплаты — способ оплаты, используемый пассажирами (например, кредитная карта, наличные и т. д.). * Место посадки и высадки — GPS-координаты мест посадки и высадки. * Тип поездки - указывает, является ли поездка выездной поездкой (зеленое такси или заказное такси) или уличным градом (желтое такси). * Время получения и возврата — время и дата получения и возврата.
Чтобы загрузить этот набор данных, нажмите здесь.
5. Всемирный супермаркет
Набор данных Global Superstore представляет собой симуляцию розничных продаж в магазинах в разных странах. Он включает информацию о клиентах, заказах и продуктах, что особенно полезно для изучения данных о розничных продажах, поскольку предлагает большой и разнообразный набор данных, которые можно использовать для анализа поведения клиентов, эффективности продуктов и моделей продаж.
Он включает следующие переменные:
* Идентификатор заказа — уникальный идентификатор для каждого заказа. * Дата заказа — дата и время размещения заказа. * Дата отправки — дата и время отправки заказа. * Режим доставки — способ доставки заказа (например, стандартный, экспресс). * Идентификатор клиента — уникальный идентификатор для каждого клиента. * Имя клиента - полное имя клиента. * Сегмент — сегмент клиента, такой как Домашний офис или Корпоративный. * Страна — страна, в которой проживает клиент. * Город - Город, в котором проживает клиент. * Штат — штат, в котором проживает клиент. * Почтовый индекс - Почтовый индекс места жительства клиента. * Регион — географический регион, в котором проживает клиент.
- Идентификатор продукта – уникальный идентификатор для каждого продукта.
- Категория — широкая категория товаров, например "Мебель", "Товары для офиса" или "Технологии".
- Подкатегория – определенная подкатегория товаров, например "Стулья", "Бумага" или "Телефоны".
- Название продукта – название продукта.
- Продажи – общий доход от продаж продукта.
- Количество – количество проданных единиц товара.
- Скидка — скидка, применяемая к товару.
- Прибыль — общая прибыль, полученная от продукта.
Чтобы загрузить этот набор данных, нажмите здесь.
6. Данные о погоде в Сиэтле
Этот набор данных представляет собой всеобъемлющий набор данных, содержащий историческую информацию о погоде в Сиэтле, штат Вашингтон. Его можно использовать для изучения климата и погодных условий, а также влияния погоды на различные отрасли и виды деятельности, такие как туризм, сельское хозяйство и транспорт.
Некоторые из важнейших переменных данных о погоде в Сиэтле включают:
* Дата - Дата наблюдения. * Prcp - Количество осадков, в дюймах. * Tmax — максимальная температура за этот день в градусах по Фаренгейту. * Tmin — минимальная температура в этот день в градусах по Фаренгейту. * Дождь — показывает TRUE, если в этот день наблюдался дождь, и FALSE, если дождя не было.
7. Показатели развития Всемирного банка
Этот набор данных содержит информацию о ВВП, ожидаемой продолжительности жизни и уровне грамотности в различных странах мира. Он также включает в себя множество экономических и социальных переменных.
Вот некоторые из переменных, включенных в этот набор данных:
* Валовой внутренний продукт (ВВП) * Инфляция * Уровень безработицы * Государственный долг * Торговый баланс * Ожидаемая продолжительность жизни * Коэффициент младенческой смертности * Доступ к электричеству * Уровень грамотности * Подписки на мобильную связь
Примечание. Переменные, включенные в набор данных, зависят от анализируемого года и страны.
Вы можете загрузить набор данных непосредственно с веб-сайта или загрузить его с Kaggle.
8. Данные здравоохранения США
Набор данных о состоянии здоровья США предоставляет исчерпывающую информацию о поведении и состоянии здоровья, включая данные об использовании медицинских услуг, физической активности и хронических заболеваниях. Его можно использовать для изучения тенденций в области общественного здравоохранения и изучения влияния образа жизни и поведения в отношении здоровья на результаты в отношении здоровья.
Данные о состоянии здоровья в США получены от Центров по контролю и профилактике заболеваний (CDC), Национального центра статистики здравоохранения (NCHS) и Агентства исследований и качества в области здравоохранения (AHRQ).
Общие переменные в этом наборе данных включают:
* Демографическая информация - возраст, пол, раса и этническая принадлежность * Показатели состояния здоровья - самооценка здоровья, хронических заболеваний и инвалидности * Меры по использованию медицинских услуг - госпитализация, посещение отделения неотложной помощи и посещение первичной медико-санитарной помощи. * Поведение в отношении здоровья - курение, физические упражнения и диета * Показатели здоровья - ожидаемая продолжительность жизни, уровень смертности и заболеваемость конкретными заболеваниями. * Расходы на здравоохранение — общие медицинские расходы, наличные расходы и страховое покрытие. * Доступ к медицинскому обслуживанию, включая страховое покрытие, наличие поставщиков медицинских услуг и близость к медицинским учреждениям.
Примечание. Переменные, включенные в набор данных о здоровье США, могут различаться в зависимости от источника данных.
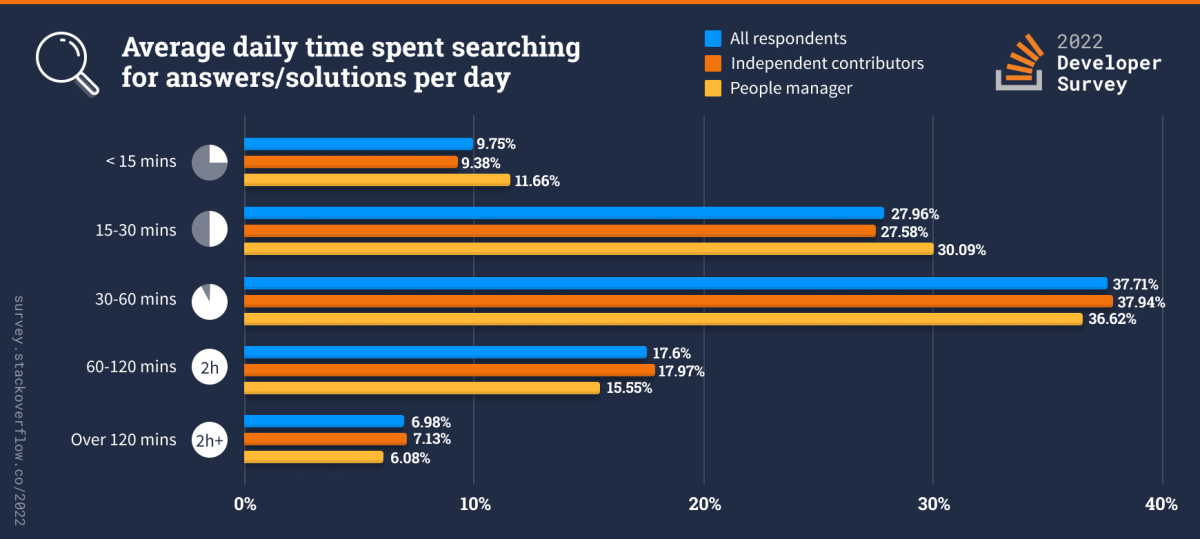
9. Результаты опроса Stack Overflow
Результаты опроса Stack Overflow содержат результаты ежегодного опроса разработчиков Stack Overflow. Он включает в себя различные аспекты опыта разработчиков, такие как заработная плата и компенсация, предпочтительные технологии, удовлетворенность работой и т. д. Его можно использовать для изучения и получения информации о состоянии сообщества разработчиков.
Этот набор данных содержит большое количество переменных, включая, помимо прочего, следующие:
* Личная информация - возраст, пол, страна и уровень образования. * Занятость - Занятость занятости, размер компании и название должности. * Опыт разработки - Многолетний опыт, основной язык программирования и среда разработки. * Заработная плата и компенсация - Заработная плата, валюта и льготы. * Удовлетворенность работой - удовлетворенность работой, карьерой и поиском работы. * Использование технологии — предпочитаемая операционная система, язык программирования, среда разработки и инструменты. * Участие в сообществе — участие в проектах с открытым исходным кодом, репутация Stack Overflow и участие в сообществах разработчиков.
Набор данных можно загрузить непосредственно с веб-сайта.
10. Титаник: машинное обучение после катастрофы
В этом популярном наборе данных с открытым исходным кодом содержится информация о пассажирах на борту корабля "Титаник", когда он затонул 15 апреля 1912 года.
Некоторые из переменных, включенных в набор данных:
* PassengerId — уникальный идентификатор для каждого пассажира. * Выжил: показывает, выжил ли пассажир или нет (0 = нет, 1 = да). * Pclass: класс пассажира (1 = 1-й, 2 = 2-й, 3 = 3-й). * Имя - Имя пассажира. * Пол - пол пассажира. * Возраст - Возраст пассажира. * SibSp - Количество братьев и сестер/супругов на борту. * Parch - количество родителей/детей на борту. * Билет - номер билета. * Fare - Стоимость проезда, оплаченная за билет. * Кабина - Номер кабины. * Embarked — порт посадки (C = Шербур, Q = Квинстаун, S = Саутгемптон).
Вы можете скачать набор данных на Kaggle.
11. Качество вина
Набор данных Wine Quality содержит информацию о образцах красного и белого вина. Цель этого набора данных Power BI — классифицировать качество вина на основе таких химических свойств, как pH, плотность, содержание алкоголя и лимонной кислоты.
Общие переменные, включенные в этот набор данных:
* Фиксированная кислотность - количество фиксированных кислот в вине, выраженное в г/дм^3. * Летучая кислотность - количество летучих кислот в вине, выраженное в г/дм^3. * Лимонная кислота - количество лимонной кислоты в вине, выраженное в г/дм^3. * Остаточный сахар: количество остаточного сахара в вине, выраженное в г/дм^3. * Хлориды - Количество хлоридов в вине, выраженное в г/дм^3. * Свободный диоксид серы - количество свободного диоксида серы в вине, выраженное в мг/дм^3. * Общий диоксид серы - количество общего диоксида серы в вине, выраженное в мг/дм^3. * Плотность - плотность вина, выраженная в г/см^3. * pH - уровень pH вина. * Сульфаты - количество сульфатов в вине, выраженное в г/дм^3. * Алкоголь - содержание алкоголя в вине, выраженное в % об. * Качество — оценка качества вина по шкале от 0 до 10.
Вы можете загрузить набор данных из репозитория машинного обучения UCI. нажав здесь.
12. Уровень преступности в США
Набор данных US Crime Rates содержит информацию об уровне преступности в США. Он организован на основе географического региона, периода или других соответствующих факторов и в основном используется для анализа тенденций и моделей преступности, а также для поддержки принятия решений в области уголовного правосудия и обеспечения соблюдения законов. Он также широко используется для исследовательского анализа и визуализации данных и может использоваться для создания интерактивных информационных панелей и отчетов в Power BI.
Некоторые из переменных, включенных в набор данных:
* M - Процент мужчин в возрасте 14–24 лет. * Po1 - Расходы на полицейскую охрану на душу населения в 1960 г. * Po2 - Расходы на полицейскую охрану на душу населения в 1959 г. * M.F - количество самцов на 100 самок.
Вы можете скачать набор данных с сайта Kaggle. р>
13. Объявления Airbnb
Этот набор данных представляет собой набор данных о объявлениях Airbnb, включая цену, удобства, тип недвижимости, количество спален и местоположение в Нью-Йорке. Он обычно используется для исследовательского анализа и визуализации данных с упором на распределение объявлений и цен по разным адресам и районам.
Некоторые из переменных, включенных в набор данных:
* Id — уникальный идентификатор Airbnb для листинга. * Идентификатор хоста — уникальный идентификатор Airbnb для хоста. * Имя хоста — имя листинга. * Neighborhood Group — группа соседей, например, Манхэттен, Бруклин и т. д. * Подтверждение личности хоста. Показывает, подтверждена ли личность хоста или нет.
Доступ к набору данных можно получить на Kaggle, нажав здесь .

Распространенные варианты использования наборов данных Power BI в проектах
Розничная аналитика
Хранилище данных Adventure Works
* Анализ розничных продаж, сегментация клиентов, анализ эффективности продуктов, сегментация рынка и анализ территории продаж.
Транспортная аналитика
* Анализ спроса и предложения такси, анализ поездок, анализ работы водителей, сравнение тарифов, анализ эффективности полетов и сравнение аэропортов.
Аналитика погоды
* Анализ тенденций погоды, анализ изменения климата, прогнозирование погодных условий и их влияние на различные отрасли.
Экономическая аналитика
Показатели развития Всемирного банка
* Анализ глобального развития, сравнение стран, прогнозирование экономических тенденций и анализ экономических показателей.
Аналитика здравоохранения
* Медицинская аналитика, сравнение штатов, анализ расходов на здравоохранение и результатов.
Кадровая аналитика
Результаты опроса Stack Overflow
* Анализ рабочей силы, анализ технологических тенденций, сравнение заработной платы и удовлетворенности работой.
Машинное обучение/прогнозирование выживания
Титаник: машинное обучение после катастрофы
* Прогноз выживания, анализ данных и визуализация катастрофы Титаника.
Анализ качества
* Анализ качества, прогнозирование качества вина на основе его химических свойств, анализ предпочтения вина и рекомендации.
Криминальная аналитика
* Анализ преступности, сравнение уровней преступности по городам, штатам и регионам, а также анализ моделей и тенденций преступности.
Аналитика путешествий
* Анализ поездок, анализ спроса на жилье, анализ цен на аренду и анализ популярных туристических направлений.
Заключительные мысли
Эти наборы данных и распространенные варианты использования помогут вам лучше понять роль Power BI в оказании помощи организациям в принятии более взвешенных решений в режиме реального времени.
Они также доступны для свободного скачивания и использования любым пользователем.
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)