Python и R — два самых популярных языка программирования, используемых для статистического анализа, анализа данных и машинного обучения. Оба языка предлагают богатую коллекцию инструментов и библиотек для работы с данными и широко используются в научных кругах, исследованиях и промышленности. R больше ориентирован на статистический анализ и имеет более простой синтаксис, а Python отличается универсальностью, что позволяет использовать более широкий спектр приложений и библиотек.
В этой статье мы сосредоточимся на наилучших предустановленных наборах данных R, обычно используемых для статистического анализа, включая классификацию, регрессионный анализ, кластеризацию и анализ временных рядов.
Предустановленные наборы данных — это наборы данных, поставляемые с программным обеспечением или платформой. В R эти наборы данных предоставляют пользователям удобный способ начать работу со статистическим анализом и машинным обучением, не тратя время на поиск или создание наборов данных.
Полный список предустановленных наборов данных R
1. Mtcars< /a>
Этот набор данных содержит информацию о различных моделях автомобилей и их характеристиках. Набор данных mtcars также взят из американского журнала Motor Trend за 1974 год и включает 32 наблюдения по 11 переменным.
Переменные включают:
* Mpg - Переменная mpg представляет мили на галлон (mpg) для модели автомобиля. * Cyl — переменная cyl представляет количество цилиндров в двигателе модели автомобиля. * Disp - Переменная disp представляет рабочий объем модели автомобиля, то есть объем воздушно-топливной смеси, которую двигатель может сжать и сжечь за один цикл, в кубических дюймах. * Hp - Переменная hp представляет полную мощность модели автомобиля в лошадиных силах. * Drat — переменная drat представляет передаточное число задней оси модели автомобиля. * Wt — переменная wt представляет собой вес модели автомобиля в тысячах фунтов. * Qsec — переменная qsec представляет время, необходимое для преодоления дистанции в четверть мили с места. * Vs - Переменная vs представляет тип двигателя (0 = V-образный, 1 = прямой). * Am — переменная am представляет тип трансмиссии (0 = автоматическая, 1 = ручная). * Шестерня - Шестерня представляет количество передних передач в модели автомобиля. * Carb — переменная carb представляет количество карбюраторов в двигателе модели автомобиля.
Набор данных Mtcars можно загрузить в R, введя data(mtcars ), или его можно загрузить, нажав здесь.
2. Вес цыпленка< /h2>
Набор данных ChickWeight, или chickwts, включает информацию о весе цыплят с течением времени. Набор данных также содержит 578 наблюдений по 4 переменным.
Переменные включают:
* Вес — переменная веса представляет собой вес цыпленка в граммах. * Время — переменная времени представляет время в днях, когда был измерен вес. * Chick — переменная chick представляет собой идентификатор цыпленка. * Диета. Переменная диеты представляет тип рациона, которым кормили курицу во время эксперимента.
Набор данных ChickWeight можно загрузить в R, введя data(ChickWeight ), или его можно загрузить, нажав здесь.
3. CO2< /a>
Набор данных CO2 включает измерения концентрации углекислого газа в атмосфере (CO2) в обсерватории Мауна-Лоа на Гавайях, проведенные с марта 1958 года по декабрь 2001 года. Набор данных также содержит 468 наблюдений по двум переменным.
Переменные включают:
* CO2 — эта переменная представляет собой концентрацию CO2 в атмосфере в частях на миллион, измеренную в обсерватории Мауна-Лоа на Гавайях. * Растение — эта переменная представляет собой тип растения, на котором измерялась концентрация CO2. Существует два типа растений: «Квебек» и «Миссисипи».
Набор данных CO2 можно загрузить в R, введя data(CO2 ), или его можно загрузить, нажав здесь.
4. Ирис
Этот набор данных включает измерения длины чашелистиков, ширины чашелистиков, длины и ширины лепестков 150 цветков ириса, принадлежащих к 3 разным видам: setosa, versicolor и virginica. Набор данных ириса состоит из 150 строк и 5 столбцов, которые хранятся в виде фрейма данных, включая столбец для видов каждого цветка.
Переменные включают:
* Sepal.Length — sepal.length представляет длину чашелистика в сантиметрах. * Sepal.Width — ширина чашелистика представляет ширину чашелистика в сантиметрах. * Petal.Length — длина лепестка представляет собой длину лепестка в сантиметрах. * Виды. Переменная вида представляет вид цветка ириса с тремя возможными значениями: setosa, versicolor и virginica.
Набор Iris можно загрузить в R, введя data(iris), или его можно загрузить с помощью нажав здесь.

5. жилье в Бостоне
Набор данных Boston Housing включает цены на жилье и связанные с ними факторы в районе Бостона. Набор данных был получен из информации, собранной Службой переписи населения США о жилье в районе Бостона, штат Массачусетс. Набор данных также включает 506 наблюдений по 14 переменным.
Переменные включают:
* Преступность — переменная преступности представляет уровень преступности на душу населения по городам. * Zn - Переменная zn представляет долю земель под жилую застройку, зонированных под участки площадью более 25 000 кв. футов. * Indus — переменная indus представляет долю акров неторговых предприятий на город. * Chas — переменная chas показывает, расположено ли свойство вдоль реки Чарльз или нет. * Nox - Переменная nox представляет собой концентрацию оксидов азота (частей на 10 миллионов) в воздухе. * Rm - переменная rm представляет собой среднее количество комнат в жилом доме. * возраст: эта переменная представляет собой долю жилых единиц, построенных до 1940 года. * Dis - Переменная dis представляет собой взвешенное расстояние до пяти центров занятости Бостона. * Rad - переменная rad представляет собой индекс доступности радиальных магистралей. * Налог — переменная налога представляет собой полную ставку налога на имущество на 10 000 долларов США. * Ptratio - переменная ptratio представляет соотношение учеников и учителей по городам. * Черный — переменная «черный» представляет долю чернокожих по городам. * Lstat - Переменная lstat представляет процент населения с более низким статусом. * Medv – переменная medv представляет медианную стоимость домов, занимаемых владельцами, в тысячах долларов США.
Набор Boston Housing можно загрузить в R, введя data( Boston), или его можно загрузить, нажав здесь.
6. Качество воздуха
Этот набор данных включает ежедневные измерения качества воздуха в Нью-Йорке с мая по сентябрь 1973 года. Он также состоит из 153 наблюдений по 6 переменным.
Переменные включают:
* Озон. Переменная озона представляет собой максимальную суточную концентрацию озона в частях на миллиард (частей на миллиард), измеренную на станции мониторинга в Нью-Йорке. * Солнечная - R: переменная solar.R представляет собой ежедневное солнечное излучение в Лэнгли (мера солнечной энергии), измеренное на той же станции мониторинга. * Ветер — переменная ветра представляет собой среднюю суточную скорость ветра в милях в час (миль/ч). * Temp — переменная temp представляет собой среднюю дневную температуру в градусах по Фаренгейту. * Месяц — переменная месяца представляет месяц, в котором было сделано наблюдение (значение от 5 до 9). * День. Переменная дня представляет день месяца, в который было сделано наблюдение (значение от 1 до 31).
Набор качества воздуха можно загрузить в R, введя данные (качество воздуха), или его можно скачать нажав здесь.
7. Титаник
Набор данных "Титаника" включает информацию о пассажирах на борту "Титаника", в том числе о том, выжили они или нет. Набор данных также содержит 891 строку и 12 переменных и также основан на списке пассажиров злополучного первого рейса Титаника, затонувшего в северной части Атлантического океана 15 апреля 1912 года после столкновения с айсбергом.
Переменные включают:
* PassengerId — Эта переменная представляет собой уникальный идентификатор каждого пассажира Титаника. * Выжил — эта переменная показывает, выжил ли пассажир или нет. Значение 0 указывает на то, что пассажир не выжил, а значение 1 указывает на то, что пассажир выжил. * Pclass — эта переменная представляет класс путешествия пассажира. На «Титанике» было три класса: первый, второй и третий. * Имя — эта переменная представляет имя пассажира. * Пол — эта переменная представляет пол пассажира. * Возраст — эта переменная представляет возраст пассажира. * SibSp — эта переменная представляет количество братьев и сестер/супругов, которые были у пассажира на борту «Титаника». * Parch — эта переменная представляет количество родителей/детей, которые были у пассажира на борту «Титаника». * Билет — эта переменная представляет номер билета пассажира. * Fare — эта переменная представляет тариф, который пассажир заплатил за свой билет. * Cabin — эта переменная представляет номер кабины пассажира. * Embarked — эта переменная представляет порт посадки пассажира. На «Титанике» было три порта посадки: Шербур, Квинстаун и Саутгемптон.
Набор данных Titanic можно загрузить в R, введя data(titanic), или его можно загрузить с помощью нажав здесь.
8. Верный
Этот набор данных включает измерения времени извержения и времени ожидания между извержениями гейзера Old Faithful в Йеллоустонском национальном парке. Набор данных Faithful также содержит 272 наблюдения по 2 переменным.
Переменные включают:
* Время извержения — переменная времени извержения представляет продолжительность текущего извержения в минутах. * Время ожидания. Переменная времени ожидания представляет собой промежуток времени между текущим и предыдущим извержением в минутах.
Набор данных Faithful можно загрузить в R, введя data(faithful) или можно загрузить, нажав здесь.
9. Оранжевый
Набор данных Orange включает измерения роста апельсиновых деревьев. Набор данных также содержит 35 наблюдений по 3 переменным.
Переменные включают:
* Дерево — числовой вектор, представляющий номер дерева (1-5). * Возраст — числовой вектор, представляющий возраст дерева (в годах). * Окружность — числовой вектор, представляющий окружность ствола дерева (в мм).
Набор данных Orange можно загрузить в R, введя data(Orange), или его можно загрузить с помощью нажав здесь.
10. растение растений
Этот набор данных включает результаты эксперимента по влиянию удобрений на рост растений. Набор данных также содержит 30 наблюдений по 2 переменным.
Переменные включают:
* Вес — числовой вектор, представляющий вес растений (в граммах). * Группа – факторная переменная, представляющая группу обработки удобрениями (либо "ctrl" для контрольной группы, либо "trt" для обработанной группы).
Набор данных PlantGrowth можно загрузить в R, введя data(PlantGrowth), или его можно загрузить с помощью нажав здесь.
11. Швейцария
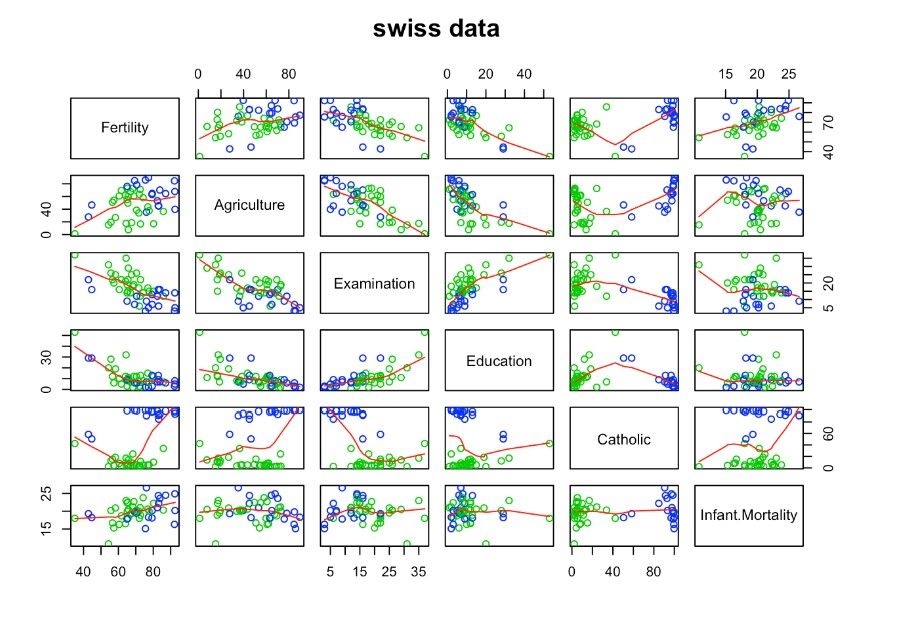
Набор данных Swiss включает социально-экономические данные по 47 франкоязычным провинциям Швейцарии в начале 1880-х годов. Он также состоит из 47 наблюдений по 6 переменным.
Переменные включают:
* Рождаемость. Эта переменная представляет коэффициент рождаемости (количество живорождений на 1000 женщин) в каждом кантоне. * Сельское хозяйство. Эта переменная представляет процентную долю мужчин в кантоне, отнесенных к категории фермеров. * Экзамен - Эта переменная представляет собой процент мужчин в кантоне, сдавших военный экзамен. * Образование. Эта переменная представляет собой процент людей в кантоне, имеющих образование, позволяющее посещать университет. * Католик — эта переменная представляет процент населения кантона, исповедующего католицизм. * Infant.Mortality — эта переменная представляет уровень младенческой смертности (количество смертей детей в возрасте до 1 года на 1000 живорождений) в каждом кантоне.
Набор данных Swiss можно загрузить в R, введя data(swiss), или его можно загрузить с помощью нажав здесь.
12. Женщины
Этот набор данных включает рост матерей и их дочерей для американских женщин в возрасте 30–39 лет. Набор данных также состоит из 15 наблюдений по 2 переменным.
Переменные включают:
* Мать — числовой вектор, представляющий рост матери (в дюймах). * Дочь — числовой вектор, представляющий рост дочери (в дюймах).
Набор данных женщины можно загрузить в R, введя данные (женщины), или его можно загрузить, нажав здесь.
Распространенные варианты использования предустановленных наборов данных R
Mtcars — набор данных Mtcars используется для регрессионного анализа и исследовательского анализа данных для изучения взаимосвязи между техническими характеристиками автомобиля и эффективностью использования топлива.
Вес цыпленка – Набор данных ChickWeight используется для анализа продольных данных о росте, таких как влияние рациона на рост цыплят.
CO2 – Набор данных CO2 используется для анализа взаимосвязи между концентрацией CO2 в атмосфере и ростом растений.
Iris – набор данных Iris используется для поисковых данных. анализ и классификационный анализ для изучения взаимосвязи между видами цветков ириса и их физическими характеристиками.
жилье в Бостоне – Набор данных Boston Housing используется для регрессионного анализа для изучения взаимосвязи между ценами на жилье и различными факторами, такими как уровень преступности и доступность общественного транспорта.
Качество воздуха — набор данных качества воздуха используется для поисковых данных. анализ и регрессионный анализ для изучения взаимосвязи между загрязнением воздуха и различными погодными факторами.
Titanic — набор данных Titanic используется для классификационного анализа. и анализ выживания для изучения факторов, повлиявших на выживание пассажиров Титаника.
Faithful – набор данных Faithful используется для исследовательского анализа данных и моделирования для изучения закономерностей времени извержения и времени ожидания гейзера Old Faithful в Йеллоустонском национальном парке.
Orange — набор данных Orange используется для регрессионного анализа. и моделирование роста для изучения роста апельсиновых деревьев.
PlantGrowth — набор данных PlantGrowth используется для проверки гипотез. и анализ ANOVA для изучения влияния различных типов удобрений на рост растений.
Swiss – набор данных Swiss используется для поисковых данных. анализ и проверка гипотез для изучения взаимосвязи между рождаемостью и социально-экономическими показателями в провинциях Швейцарии.
Женщины — используется набор данных "Женщины". для исследовательского анализа данных и проверки гипотез для изучения взаимосвязи между ростом и весом женщин.
Заключительные мысли
К этим наборам данных также можно получить доступ через пакеты R, такие как "tidyverse", "ggplot2" и "data.table"
Они также доступны в общедоступных репозиториях, таких как Kaggle, GitHub и репозиторий машинного обучения UCI.
Главное изображение этой статьи было создано с помощью модели стабильной диффузии искусственного интеллекта HackerNoon с использованием подсказки «Программирование R».
Дополнительные списки наборов данных: