

10 лучших наборов данных обнимающихся лиц для построения моделей НЛП
21 февраля 2023 г.Hugging Face предлагает решения и инструменты для разработчиков и исследователей. Благодаря библиотеке с открытым исходным кодом под названием Transformers они предоставляют доступ к современным предварительно обученным моделям.
Благодаря высокому качеству и легкодоступности наборов данных, охватывающих различные темы и языки, Hugging Face внесла свой вклад в развитие технологии НЛП.
В этой статье рассматриваются Лучшие наборы данных обнимающихся лиц для построения моделей НЛП, доступные разработчикам и исследователям по всему миру.
Полный список наборов данных обнимающихся лиц
1. IMDB
Набор данных IMDB обычно используется для задач обработки естественного языка, в частности для анализа настроений. Он состоит из коллекции из 50 000 обзоров фильмов с веб-сайта Internet Movie Database, поровну разделенных на положительные и отрицательные отзывы. Набор данных используется для бинарной классификации, что означает, что основная цель — классифицировать каждый отзыв как положительный или отрицательный в зависимости от настроения, выраженного в тексте.
Каждый отзыв в этом наборе данных представляет собой текстовый документ, а набор данных был предварительно обработан и очищен, поэтому он готов к использованию для обучения и оценки моделей анализа тональности. Набор данных IMDB доступен на платформе Hugging Face, что упрощает доступ и использование с популярными библиотеками НЛП, такими как библиотека Hugging Face Transformers.
Примечание. Из-за того, что этот набор данных включает только обзоры фильмов на английском языке и может не представлять другие типы текста, он ограничен.
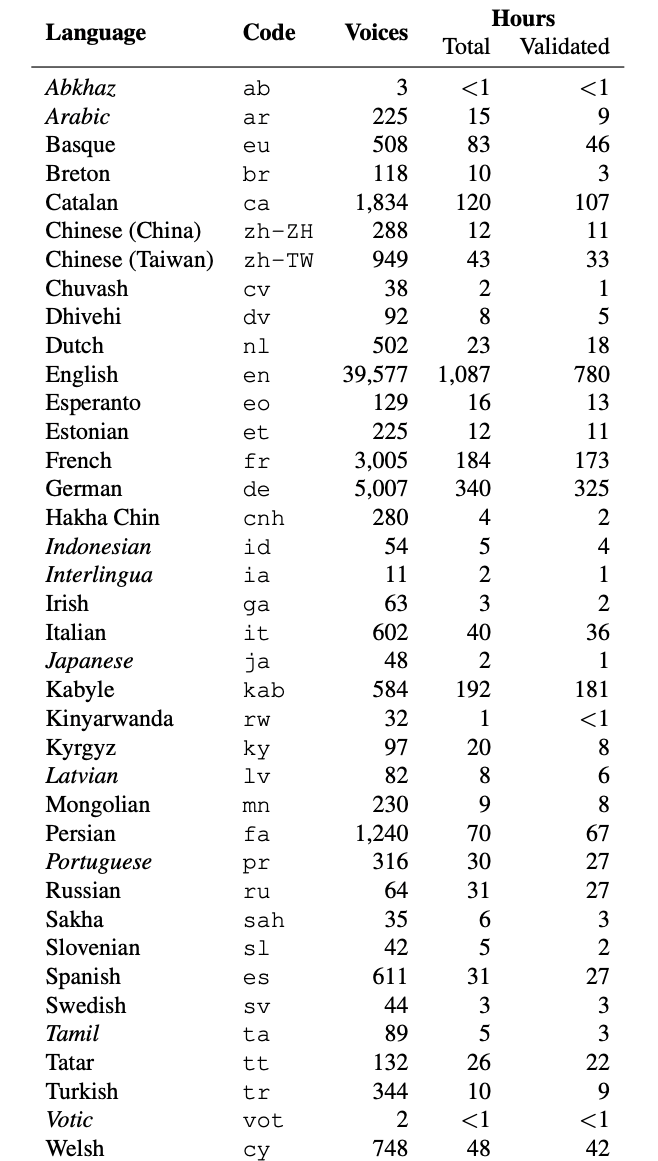
2. Общий голос
Это большой набор данных с открытым исходным кодом записей человеческого голоса, созданный Mozilla для использования при разработке и обучении моделей распознавания речи. Он уникален тем, что он многоязычный, с записями на более чем 60 разных языках. Common Voice Dataset — один из крупнейших общедоступных наборов данных для распознавания речи, поскольку он содержит более 9 000 часов голосовых данных от более чем 60 000 участников со всего мира.
Каждая запись в наборе данных соответствует метаданным, включая пол, возраст говорящего, акцент и текст произнесенного предложения. Он доступен в различных форматах, таких как FLAC, MP3 и WAV.
Каждая запись в наборе данных связана с метаданными, в том числе с возрастом, полом и акцентом говорящего, а также с текстом произнесенного предложения. Набор данных доступен на Hugging Face как часть общего голосового пакета в различных форматах, включая FLAC, MP3 и WAV, что упрощает работу с ним в различных программных средах.
3. Полярность Amazon
Набор данных Amazon Polarity — это набор текстовых обзоров и связанных с ними звездных оценок продуктов, продаваемых на Amazon. Набор данных состоит из более чем 3 миллионов обзоров на нескольких языках, включая английский, немецкий, японский и французский, и охватывает широкий спектр категорий товаров, включая книги, электронику и одежду. Цель набора данных — предложить крупномасштабный ориентир для анализа тональности, где задача состоит в том, чтобы спрогнозировать тональность данного отзыва как положительную или отрицательную на основе соответствующего звездного рейтинга.
Этот набор данных предварительно обработан, помечен и доступен на Hugging Face как часть пакета amazon_polarity, который предоставляет удобный интерфейс для загрузки и работы с набором данных в Python.
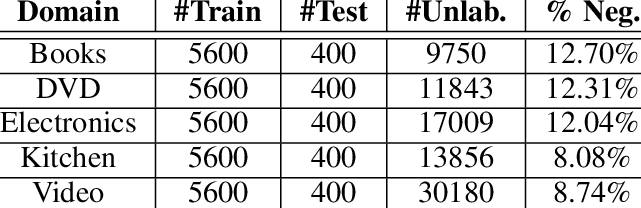
4. Силикон
Этот набор данных содержит классификации предложений по типам: директивные, комиссивные, информативные или вопросительные. Эти предложения собраны из различных областей, таких как телевизионные диалоги, телефонные разговоры и т. д.
В наборе данных Silicone все точки данных на английском языке. Благодаря пониманию того, как можно спроектировать системы разговорного языка для обработки различных типов предложений в различных предметных областях, это также ценный ресурс для обучения и оценки моделей естественного языка.
5. Темы Yahoo Answers
Набор данных Yahoo Answers Topics содержит более 1 миллиона вопросов и соответствующих им тем, просканированных из Yahoo Answers. Набор данных включает широкий спектр предметов, включая спорт, бизнес и т. д. финансы, общество & культура, наука & математика, семья & отношения, компьютеры & Интернет и многое другое.
Каждый вопрос в наборе данных помечен одной или несколькими тематическими категориями, что делает его полезным для разработки моделей, которые могут точно классифицировать текстовые данные по нескольким категориям. Набор данных предварительно обрабатывается и токенизируется, что упрощает обучение модели для классификации определенных вопросов и ответов по одной из этих категорий.
6. Эмоции
Набор данных Emotions представляет собой набор текстов, помеченных категориями эмоций. Набор данных включает тексты, выражающие шесть основных эмоций: гнев, страх, радость, любовь, печаль и удивление.
Тексты в этом наборе данных получены из различных общедоступных наборов данных и онлайн-ресурсов, таких как Reddit, Twitter и новостные статьи. Каждый текст помечен одной из шести основных категорий эмоций, что позволяет использовать набор данных для обучения и оценки моделей обработки естественного языка, которые могут классифицировать текстовые данные по этим категориям эмоций.
Одной из особенностей набора данных Emotions является то, что он ориентирован на широкий спектр эмоций, что позволяет обучать модели, которые могут распознавать и различать различные эмоциональные состояния. Это полезно для создания моделей для таких приложений, как анализ настроений или чат-боты.
7. Разжигание ненависти18
Этот набор данных представляет собой набор больших текстовых данных с более чем 24 000 помеченных экземпляров, которые могут быть полезны для обучения моделей глубокого обучения. Он помечен как разжигание ненависти или не разжигание ненависти и включает в себя различные типы текста, такие как твиты, публикации в Facebook и комментарии на YouTube.
Набор данных о разжигании ненависти разбит на три категории:
- язык ненависти
- оскорбительные выражения
- ни
К категории "язык вражды" относятся тексты, выражающие ненависть или предубеждение по отношению к определенной группе на основании их расы, пола, религии или других характеристик. В категорию "оскорбительные выражения" входят тексты, которые могут не выражать прямой ненависти, но тем не менее считаются крайне оскорбительными или неуместными.
Одной из особенностей набора данных о разжигании ненависти является его специализация на разжигании ненависти и оскорбительных выражениях, что необходимо для создания моделей, способных распознавать домогательства и дискриминацию в Интернете и бороться с ними.
8. СМС-спам
Набор данных SMS-спама содержит более 5000 SMS-сообщений, классифицированных как спам или ветчина (не спам). Он собирается с мобильных телефонов реальных пользователей и обычно используется в исследованиях машинного обучения и обработки естественного языка для моделей обучения, которые могут отличать спам от законных сообщений. Это может быть полезно для разработки спам-фильтров или выявления потенциально мошеннических сообщений.
9. Банковское дело 77
Это всеобъемлющая и сложная коллекция финансовых текстовых данных, включающая более 77 000 документов. Среди этих документов более 13 000 сообщений клиентов, отправленных в банки, с подробным описанием различных жалоб и проблем. Эти сообщения клиентов классифицируются по семидесяти семи различным направлениям, включая запросы о поступлении карты, неисправностях карты, дополнительных расходах по карте и проблемах с отклоненным переводом.
Используя набор данных Banking 77, банки могут сократить время отклика и лучше справляться с проблемами клиентов. Кроме того, другие предприятия, которые получают большие объемы запросов клиентов, могут использовать набор данных Banking 77 в качестве модели для создания аналогичных инструментов для классификации и анализа сообщений клиентов. Однако важно отметить, что подготовка набора данных для машинного обучения требует тщательной фильтрации и обработки для обеспечения точности и качества.

10. Сканировать
Набор данных Scan содержит более 7000 вопросов, которые охватывают широкий спектр тем, таких как спорт, наука и развлечения, и представляет собой масштабный эталон для оценки моделей понимания естественного языка (NLU). Он предназначен для проверки способности модели выполнять различные типы рассуждений, включая временное рассуждение, пространственное рассуждение и логическое рассуждение. К каждому вопросу прилагается набор возможных ответов, и цель модели — выбрать правильный ответ из предоставленных вариантов.
Распространенные варианты использования наборов данных лиц, обнимающих
IMDB – набор данных IMDB можно использовать для анализа настроений. и задачи классификации текста, такие как определение того, является ли обзор фильма положительным или отрицательным.
Common Voice. Набор данных Common Voice полезен для задач распознавания речи, например, создание моделей преобразования речи в текст для разных языков.
Amazon Polarity. Набор данных Amazon Polarity можно использовать для анализа настроений и задачи классификации текста, например определение положительного или отрицательного отзыва о продукте на Amazon.
Silicone – набор данных Silicone предназначен для задач классификации текста, в частности для определения тип предложения как комиссивное, директивное, информативное или вопросительное.
Темы Yahoo Answers — набор данных Yahoo Answers Topics можно использовать для темы задачи классификации, такие как определение темы или предмета данного текста.
Emotion. Набор данных Emotion можно использовать для задач классификации эмоций, таких как как определение эмоций или настроений, выраженных в тексте.
Разжигание ненависти18. Набор данных о разжигании ненависти можно использовать для обнаружения и анализ разжигания ненависти, который полезен для выявления и борьбы с ненормативной лексикой в Интернете.
SMS Spam – набор данных SMS Spam можно использовать для обнаружения спама. сообщений, что полезно для фильтрации нежелательных сообщений в почтовых ящиках SMS.
Банковское дело 77 — набор данных Банковское дело 77 можно использовать для задач классификации намерений. , например классифицировать сообщения клиентов банкам по разным категориям намерений, например запросы о получении карты, проблемы с неработающей картой или дополнительные расходы на карту.
Сканирование. Набор данных сканирования можно использовать для задач классификации текста, таких как как идентифицирующий тип текста как новостной или академический, и может использоваться для обучения моделей таким задачам, как обобщение текста и создание текста.
Заключительные мысли
Hugging Face предлагает широкий спектр доступных наборов данных, предназначенных для различных задач обработки естественного языка, от классификации текста до языкового моделирования. Благодаря растущей коллекции наборов данных Hugging Face и постоянным обновлениям он стал популярным и надежным источником данных НЛП.
Эти наборы данных доступны для свободного скачивания и использования любым пользователем.
Дополнительные списки наборов данных:
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27720)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)