

Вы теряете питание графического процессора - фиксируйте свой входной трубопровод TensorFlow сегодня
30 июля 2025 г.Обзор контента
- Обзор
- Ресурсы
- Настраивать
- Набор данных
- Тренировочная петля
- Оптимизировать подход
- Наивный подход
- Предварительное получение
- Параллелизация извлечения данных
- Параллелизация преобразования данных
- Кэширование
- Векторизация картирования
- Уменьшение следа памяти
Обзор
GPU и TPU могут радикально сократить время, необходимое для выполнения одного этапа обучения. Достижение пиковой производительности требует эффективного входного трубопровода, который предоставляет данные для следующего шага до завершения текущего шага. Аtf.dataAPI помогает построить гибкие и эффективные входные трубопроводы. Этот документ демонстрирует, как использоватьtf.dataAPI для создания высокопрофессиональных входных трубопроводов TensorFlow.
Прежде чем продолжить, проверьтеПостроить входные трубопроводы TensorFlowруководство, чтобы узнать, как использоватьtf.dataAPI.
Ресурсы
- Построить входные трубопроводы TensorFlow
tf.data.DatasetAPI- Анализировать
tf.dataпроизводительность с TF Profiler
Настраивать
import tensorflow as tf
import time
2024-08-15 02:29:59.860833: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-08-15 02:29:59.882136: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-08-15 02:29:59.888640: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
На протяжении всего этого руководства вы будете повторять набор данных и измерить производительность. Создание воспроизводимых показателей производительности может быть трудным. Различные факторы, влияющие на воспроизводимость, включают:
- Текущая загрузка процессора
- Сетевой трафик
- Сложные механизмы, такие как кэш
Чтобы получить воспроизводимый эталон, вы построите искусственный пример.
Набор данных
Начните с определения класса, наследуя отtf.data.DatasetназываетсяArtificialDatasetПолем Этот набор данных:
- Генерирует
num_samplesОбразцы (по умолчанию 3) - Спит в течение некоторого времени перед первым элементом, чтобы моделировать открытие файла
- Спит в течение некоторого времени, прежде чем производить каждый элемент для моделирования чтения данных из файла
class ArtificialDataset(tf.data.Dataset):
def _generator(num_samples):
# Opening the file
time.sleep(0.03)
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
time.sleep(0.015)
yield (sample_idx,)
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_signature = tf.TensorSpec(shape = (1,), dtype = tf.int64),
args=(num_samples,)
)
Этот набор данных похож наtf.data.Dataset.rangeВо-первых, добавление фиксированной задержки в начале и между каждым образцом.
Тренировочная петля
Затем напишите фиктивную петлю обучения, которая измеряет, сколько времени требуется для итерации над набором данных. Время обучения моделируется.
def benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
for sample in dataset:
# Performing a training step
time.sleep(0.01)
print("Execution time:", time.perf_counter() - start_time)
Оптимизировать производительность
Чтобы показать, как можно оптимизировать производительность, вы улучшите производительностьArtificialDatasetПолем
Наивный подход
Начните с наивного трубопровода, не используя уловки, итерация над набором данных, как это.
benchmark(ArtificialDataset())
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1723689002.526086 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689002.529717 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689002.533395 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689002.537215 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689002.548874 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689002.552105 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689002.555507 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689002.559016 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689002.562268 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689002.565421 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689002.568842 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689002.572296 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.797478 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.799457 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.801473 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.803565 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.805613 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.807466 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.809382 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.811373 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.813299 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.815122 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.817022 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.819005 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.857728 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.860099 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.862063 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.864094 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.866073 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.867912 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.869940 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.871942 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.873924 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.876256 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.878556 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689003.880974 112933 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
Execution time: 0.28992818999995507
Под капюшоном так было потрачено время вашего исполнения:
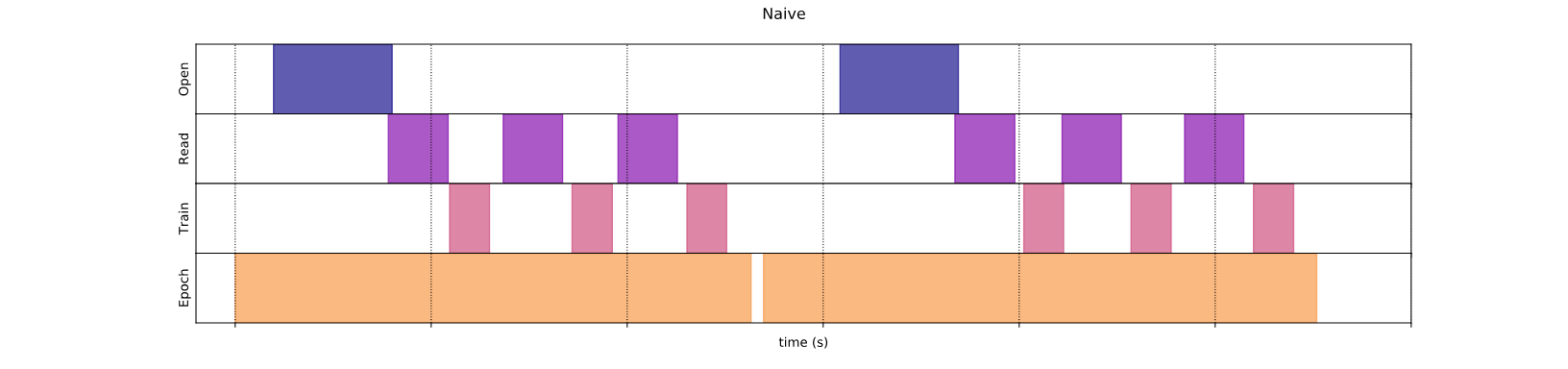
Сюжет показывает, что выполнение этапа обучения включает в себя:
- Открытие файла, если он еще не был открыт
- Получение ввода данных из файла
- Использование данных для обучения
Тем не менее, в наивной синхронной реализации, как здесь, в то время как ваш трубопровод получает данные, ваша модель находится на холостом ходу. И наоборот, в то время как ваша модель тренируется, входной трубопровод находится на холостом ходу. Таким образом, время обучения - это сумма открытия, чтения и обучения.
Следующие разделы основаны на этом входном трубопроводе, иллюстрируя лучшие практики для проектирования входных трубопроводов производительности TensorFlow.
Предварительное получение
Предварительная обработка перекрывает предварительную обработку и выполнение модели шага обучения. Пока модель выполняет этап обученияs, входной трубопровод читает данные для шагаs+1Полем Это уменьшает шаг к максимальному (в отличие от суммы) обучения и времени, необходимого для извлечения данных.
Аtf.dataAPI предоставляетtf.data.Dataset.prefetchтрансформация. Его можно использовать для отделения времени, когда данные создаются с момента использования данных. В частности, преобразование использует фоновый поток и внутренний буфер для предварительного вычинения элементов из набора данных ввода в преддверии времени, когда они запрашиваются. Количество элементов для предварительной выборки должно быть равным (или, возможно, больше, чем) количество партий, потребляемых одним этапом обучения. Вы можете либо вручную настроить это значение, либо установить его наtf.data.AUTOTUNE, что побудитtf.dataВремя выполнения, чтобы настроить значение динамично во время выполнения.
Обратите внимание, что преобразование предварительного переключения дает преимущества в любое время, когда есть возможность перекрывать работу «производителя» с работой «потребителя».
benchmark(
ArtificialDataset()
.prefetch(tf.data.AUTOTUNE)
)
Execution time: 0.282483695999872
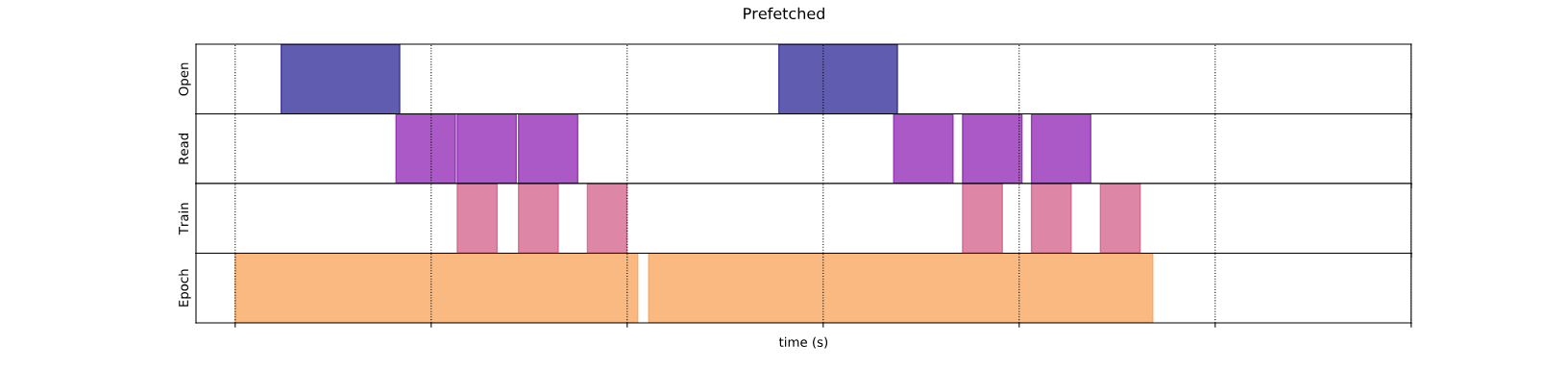
Теперь, как показывает график времени выполнения данных, в то время как этап обучения работает для образца 0, входной трубопровод читает данные для образца 1 и т. Д.
Параллелизация извлечения данных
В реальном мире входные данные могут храниться удаленно (например, в Google Cloud Storage или HDF). Трубопровод наборов данных, который хорошо работает при локальном чтении данных, может стать узким местом на вводе/выводе при удаленном чтении данных из -за следующих различий между локальным и удаленным хранилищем:
- Время до первого байта: Чтение первого байта файла из удаленного хранилища может занять за заказы больше, чем на локальном хранилище.
- Прочитать пропускную способность: В то время как удаленное хранилище обычно предлагает большую пропускную способность заполнить, чтение одного файла может использовать только небольшую часть этой полосы пропускания.
Кроме того, после того, как необработанные байты загружаются в память, также может потребоваться десериализация и/или расшифровку данных (например,Протобуф), который требует дополнительных вычислений. Эта накладная расходы присутствуют независимо от того, хранятся ли данные локально или удаленно, но могут быть хуже в удаленном случае, если данные не предварительно обрабатываются эффективно.
Чтобы смягчить влияние различных накладных расходов извлечения данных,tf.data.Dataset.interleaveПреобразование может использоваться для параллелизации этапа загрузки данных, чередование содержимого других наборов данных (например, считывателей файлов данных). Количество наборов данных для перекрытия может быть указано поcycle_lengthаргумент, в то время как уровень параллелизма может быть указанnum_parallel_callsаргумент Похоже наprefetchтрансформация,interleaveПреобразование поддерживаетtf.data.AUTOTUNE, который делегирует решение о том, какой уровень параллелизма использовать дляtf.dataвремя выполнения.
Последовательное интерпалирование
Аргументы по умолчаниюtf.data.Dataset.interleaveПреобразование делает его последовательно переплетать отдельные образцы из двух наборов данных.
benchmark(
tf.data.Dataset.range(2)
.interleave(lambda _: ArtificialDataset())
)
Execution time: 0.4770545540004605
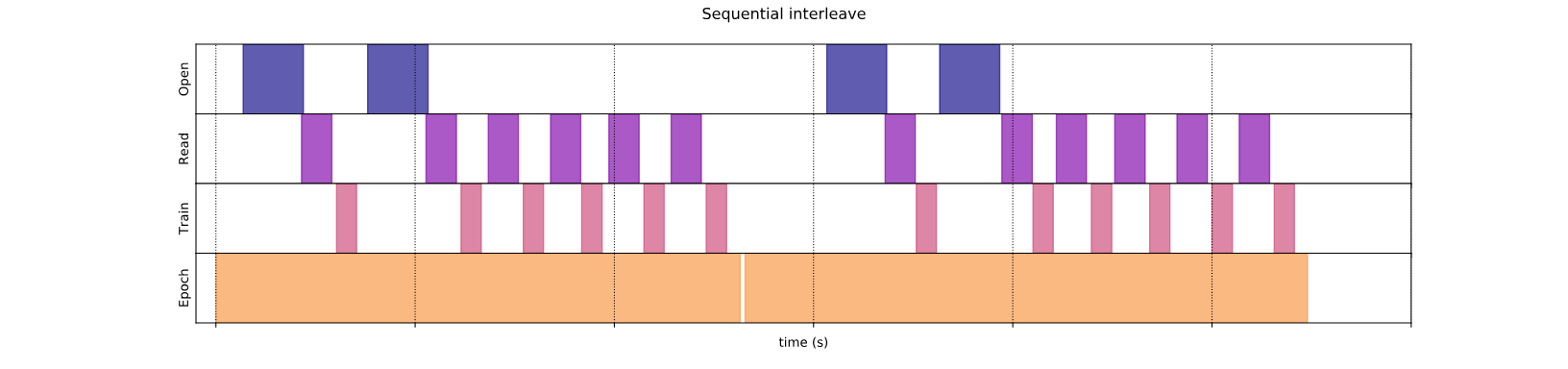
Этот график времени выполнения данных позволяет демонстрировать поведениеinterleaveПреобразование, извлечение образцов альтернативно из двух доступных наборов данных. Тем не менее, здесь не связано с улучшением производительности.
Параллельное переплета
Теперь используйтеnum_parallel_callsаргументinterleaveтрансформация. Это загружает несколько наборов данных параллельно, сокращая время, ожидающее открытия файлов.
benchmark(
tf.data.Dataset.range(2)
.interleave(
lambda _: ArtificialDataset(),
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.37743708600009995
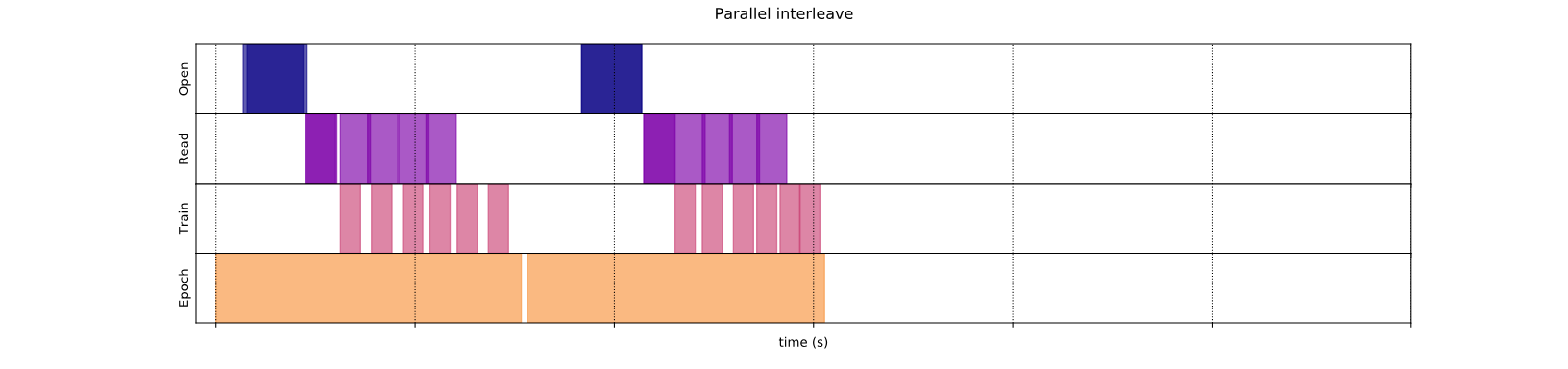
На этот раз, как показывает график времени выполнения данных, чтение двух наборов данных параллелизируется, что сокращает время обработки глобальной обработки данных.
Параллелизация преобразования данных
При подготовке данных входные элементы могут быть предварительно обработаны. С этой целью,tf.dataAPI предлагаетtf.data.Dataset.mapПреобразование, которое применяет пользовательскую функцию к каждому элементу набора данных ввода. Поскольку входные элементы не зависят друг от друга, предварительная обработка может быть параллелизирована по нескольким ядрам ЦП. Чтобы сделать это возможным, аналогичноprefetchиinterleaveпреобразования,mapПреобразование обеспечиваетnum_parallel_callsАргумент, чтобы указать уровень параллелизма.
Выбор наилучшего значения дляnum_parallel_callsАргумент зависит от вашего оборудования, характеристик ваших учебных данных (таких как его размер и форма), стоимость функции вашей карты и то, что другая обработка происходит на процессоре одновременно. Простая эвристика состоит в том, чтобы использовать количество доступных ядер ЦП. Однако, что касаетсяprefetchиinterleaveтрансформация,mapПреобразование поддерживаетtf.data.AUTOTUNEкоторый делегирует решение о том, какой уровень параллелизма использовать дляtf.dataвремя выполнения.
def mapped_function(s):
# Do some hard pre-processing
tf.py_function(lambda: time.sleep(0.03), [], ())
return s
Последовательное отображение
Начните с использованияmapПреобразование без параллелизма в качестве базового примера.
benchmark(
ArtificialDataset()
.map(mapped_function)
)
Execution time: 0.49222556600034295
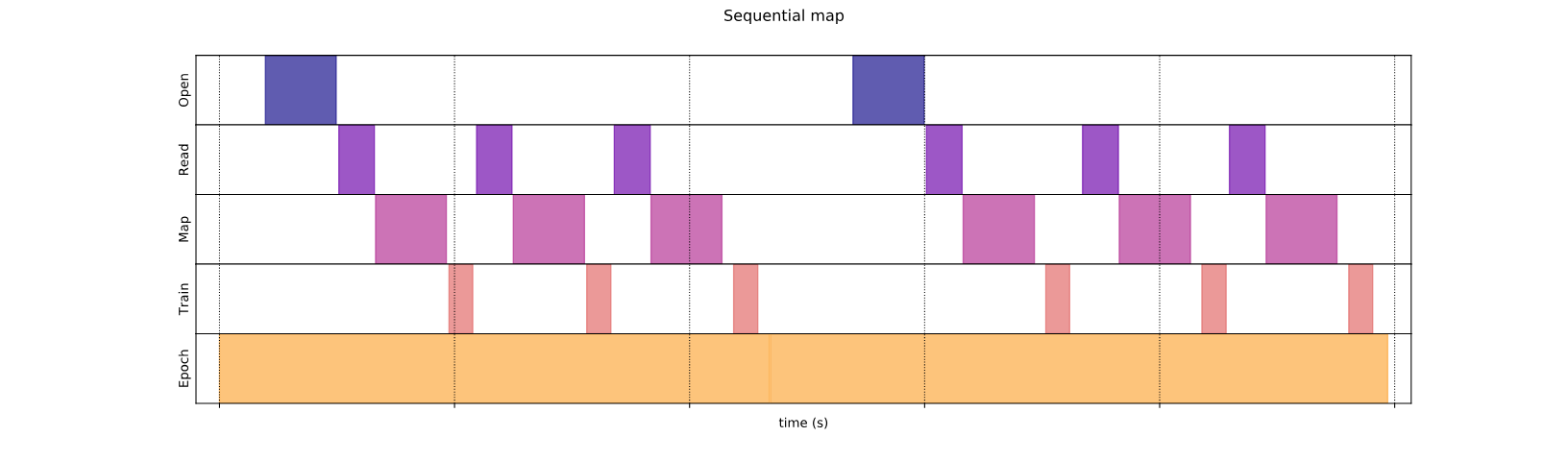
Что касаетсянаивный подходЗдесь, как показывает сюжет, The Times, проведенные на открытие, чтение, предварительное обработку (картирование) и обучающие шаги, суммируются вместе для одной итерации.
Параллельное картирование
Теперь используйте ту же функцию предварительной обработки, но примените ее параллельно на несколько образцов.
benchmark(
ArtificialDataset()
.map(
mapped_function,
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.36392719900049997
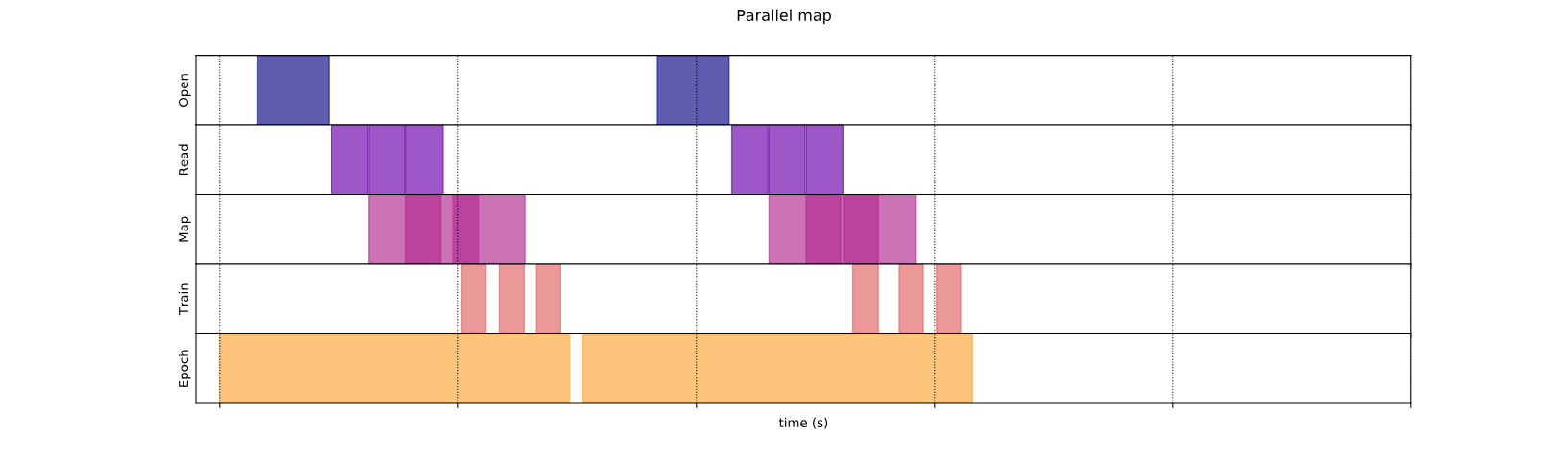
Как показывает график данных, этапы предварительной обработки перекрываются, сокращая общее время для одной итерации.
Кэширование
Аtf.data.Dataset.cacheПреобразование может кэшировать набор данных либо в памяти, либо в локальном хранилище. Это сохранит некоторые операции (например, открытие файлов и чтение данных) от выполнения во время каждой эпохи.
benchmark(
ArtificialDataset()
.map( # Apply time consuming operations before cache
mapped_function
).cache(
),
5
)
Execution time: 0.3864543270001377
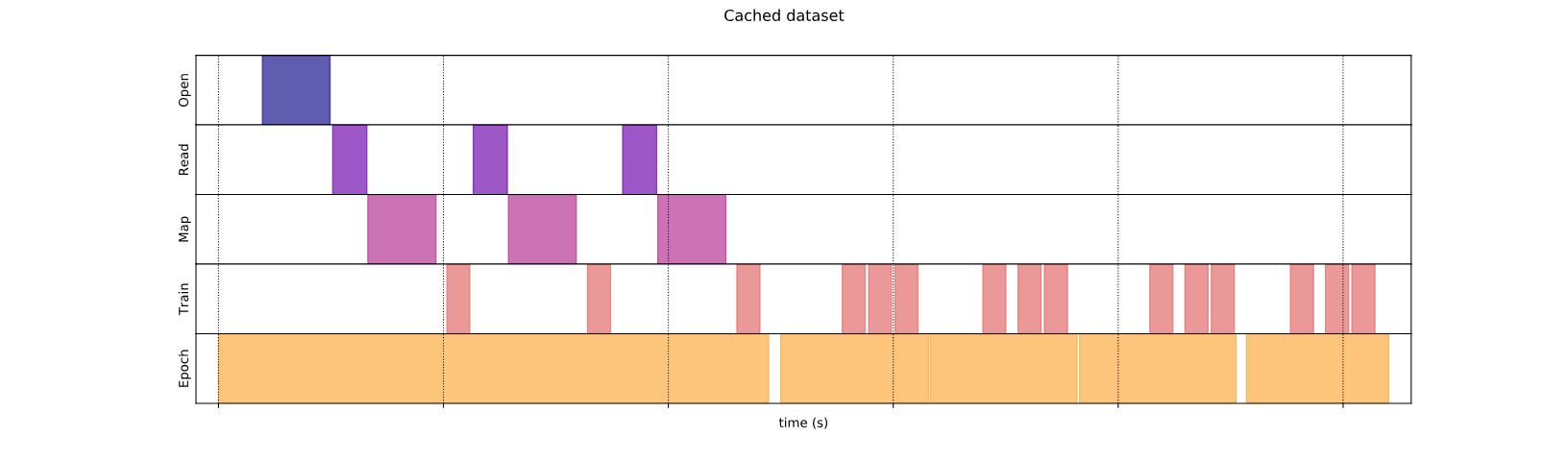
Здесь график времени выполнения данных показывает, что когда вы кэшируете набор данных, преобразования передcacheОдин (например, открытие файла и чтение данных) выполняется только в первую эпоху. Следующие эпохи повторно используют данные, кэшированныеcacheтрансформация.
Если пользовательская функция передана вmapтрансформация дорого, применитьcacheтрансформация послеmapПреобразование до тех пор, пока полученный набор данных все еще может вписаться в память или локальное хранилище. Если пользовательская функция увеличивает пространство, необходимое для хранения набора данных за пределами емкости кэша, либо примените его послеcacheПреобразование или рассмотрите предварительную обработку ваших данных перед учебной задачей, чтобы сократить использование ресурсов.
Векторизация картирования
Вызывая пользовательную функцию, передаваемую вmapПреобразование имеет накладные расходы, связанные с планированием и выполнением пользовательской функции. Векторизировать пользовательская функция (то есть она работает на партии входов одновременно) и применитеbatchтрансформациядоаmapтрансформация.
Чтобы проиллюстрировать эту хорошую практику, ваш искусственный набор данных не подходит. Задержка планирования составляет около 10 микросекунд (10e-6 секунд), что гораздо меньше, чем десятки миллисекунд, используемых вArtificialDataset, и, таким образом, его влияние трудно увидеть.
Для этого примера используйте базуtf.data.Dataset.rangeФункциональна и упростите обучающий цикл до самой простой формы.
fast_dataset = tf.data.Dataset.range(10000)
def fast_benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for _ in tf.data.Dataset.range(num_epochs):
for _ in dataset:
pass
tf.print("Execution time:", time.perf_counter() - start_time)
def increment(x):
return x+1
Скалярное картирование
fast_benchmark(
fast_dataset
# Apply function one item at a time
.map(increment)
# Batch
.batch(256)
)
Execution time: 0.23993100699954084
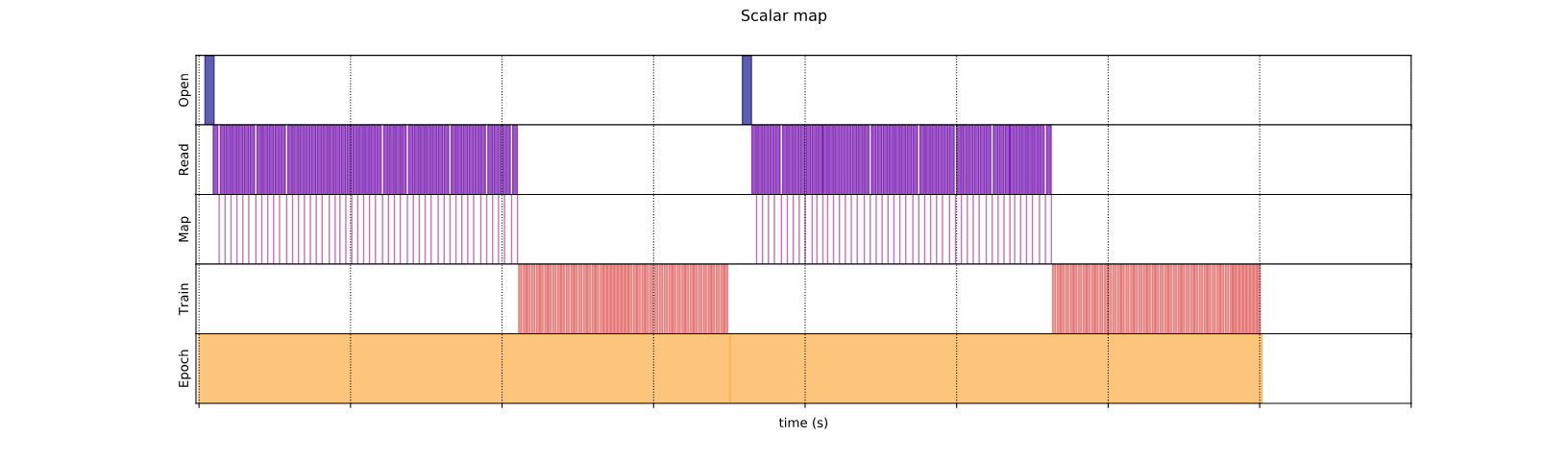
Участок выше иллюстрирует, что происходит (с меньшим количеством образцов), используя метод скалярного отображения. Это показывает, что отображаемая функция применяется для каждого образца. Хотя эта функция очень быстрая, у нее есть некоторые накладные расходы, которые влияют на производительность времени.
Векторизованное картирование
fast_benchmark(
fast_dataset
.batch(256)
# Apply function on a batch of items
# The tf.Tensor.__add__ method already handle batches
.map(increment)
)
Execution time: 0.04984995199993136
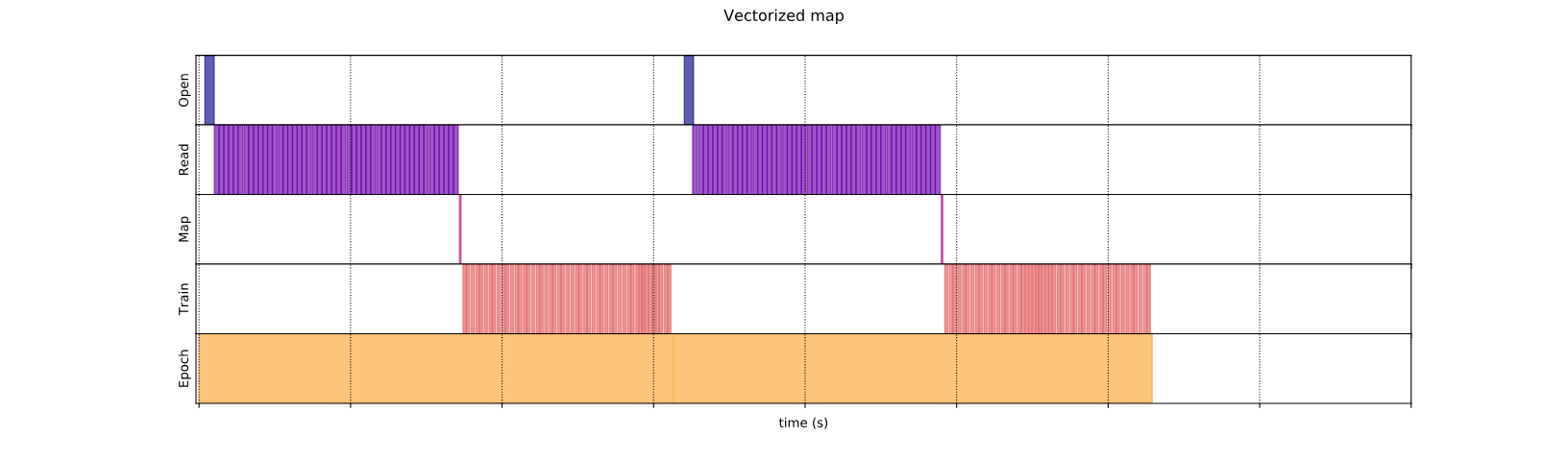
На этот раз функция сопоставления вызывается один раз и применяется к партии образца. Как показывает график времени выполнения данных, в то время как функция может занять больше времени для выполнения, накладные расходы появляются только один раз, улучшая общую производительность времени.
Уменьшение следа памяти
Ряд преобразований, включаяinterleaveВprefetch, иshuffleПоддерживать внутренний буфер элементов. Если пользовательская функция передана вmapПреобразование изменяет размер элементов, затем упорядочение преобразования карты и преобразования, которые буферизируют элементы, влияют на использование памяти. В общем, выберите порядок, который приводит к более низкому трассе памяти, если только другой порядок не желателен для производительности.
Кэширование частичных вычислений
Рекомендуется кэшировать набор данных послеmapПреобразование, за исключением случаев, если это преобразование делает данные слишком большими, чтобы вписаться в память. Компромисс может быть достигнут, если ваша функция сопоставлена может быть разделена на две части: требующая много времени и часть, потребляющая память. В этом случае вы можете цепорить свои преобразования, как ниже:
dataset.map(time_consuming_mapping).cache().map(memory_consuming_mapping)
Таким образом, трудоемкая часть выполняется только в первую эпоху, и вы избегаете использования слишком большого количества кеша.
Первоначально опубликовано на
Оригинал