

Почему ваша работа CDC Seatunnel висит на этапе снимка (и как это исправить)
10 июля 2025 г.Проблема встречалась
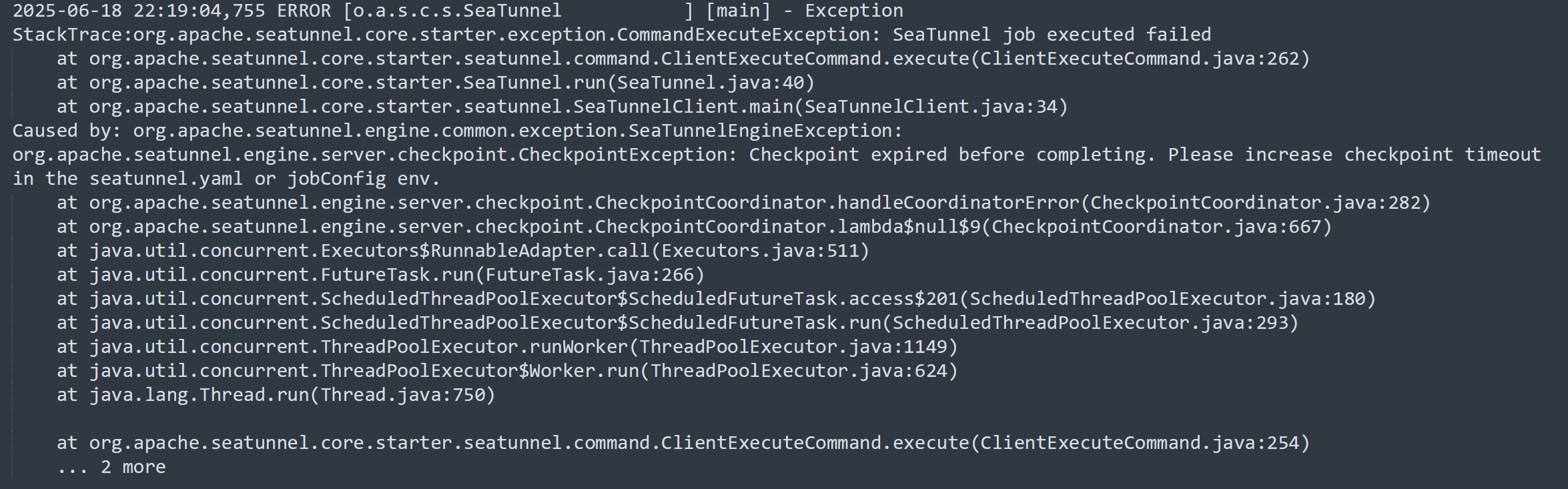
В нашем проекте Seatunnel используется для извлечения данных из бизнес-базы данных в хранилище данных (Staroccs), и мы уже успешно использовали MySQL-CDC для крупномасштабной синхронизации в реальном времени. Тем не менее, мы столкнулись с ненормальной проблемой при синхронизации конкретной таблицы MySQL: после начала работы журналы показали нулевое чтение и чтение количества, и работа не остановилась в течение долгого времени. После 6 часов работы он прекратился с ошибкой тайм -аута контрольной точки.
Структура работы заключается в следующем (конфиденциальная информация, удаленная):
Журналы ключей во время выполнения:
Фон
- Сценарий: извлечение данных в реальном времени из MySQL в Starrocks с использованием MySQL-CDC
- Seatunnel Версия: 2.3.9
- MySQL версия: 8.x
- Версия Старска: 3.2
- Данные исходной таблицы объем: 60–70 миллионов строк
Ключевые вопросы
- Почему количество чтения и записи остается на 0?
- Почему нужно так много времени, чтобы бросить ошибку тайм -аута?
Процесс анализа
Мы раньше использовали MySQL-CDC для многих заданий по синхронизации, и конфигурации были в основном одинаковыми, поэтому проблема, вероятно, не связана с самим сиденье.
Мы сравнили эту исходную таблицу с ранее успешными, чтобы увидеть, есть ли различия.
Конечно же, мы нашли что -то подозрительное:
Все предыдущие таблицы имели первичные ключи автоматического интеграции; Этот не сделал. У него было только несколько уникальных индексов.



Итак, возникает вопрос: как именно синхронизированные данные Seatunnel?
Насколько нам известно, Seatunnel использует двухэтапный подход при синхронизации данных CDC: сначала синхронизации снимка, а затем инкрементная синхронизация на основе Binlog.
Поскольку чтенный счет остается нулевым, работа должна застрять на этапе снимка. Итак, как работает синхронизация снимка?
Мы проверили официальные документы Seatunnel:
MySQL CDC | Apache Seatunnel:
https://seatunnel.apache.org/zh-cn/docs/2.3.9/connector-v2/source/mysql-cdc
Нет никаких архитектурных объяснений, но мы нашли некоторые настраиваемые параметры.
Пояснение параметра
chunk-key.even-distribution.factor.upper-bound
Значение по умолчанию: 100
Описание:
Верхняя граница коэффициента распределения ключей чанка. Этот коэффициент используется для определения того, распределены ли табличные данные равномерно. Если коэффициент распределения (например, (MAX (ID) - MIN (ID) + 1) / CONC ряд) составляет ≤ это значение, таблица считается равномерно распределенной и будет использовать равномерный Chunking. Если оно превышает это значение, и предполагаемое количество осколков превосходитsample-sharding.threshold, будет использоваться стратегия шардинга на основе отбора проб. По умолчанию: 100.0
chunk-key.even-distribution.factor.lower-bound
Значение по умолчанию: 0,5
Описание:
Нижняя граница коэффициента распределения. Если коэффициент распределения ≥ этого значения, таблица считается равномерно распределенной. В противном случае это считается неравномерным и может вызвать шарнинг на основе отбора проб.
sample-sharding.threshold
Значение по умолчанию: 1000
Описание:
Если коэффициент распределения находится за пределами [нижнего, верхнего] диапазона], и предполагаемое количество осколков (примерно количество рядов / размер куски) превышает этот порог, будет использоваться стратегия шардов на основе отбора проб. Это повышает эффективность для больших наборов данных.
inverse-sampling.rate
Значение по умолчанию: 1000
Описание:
Используется в Sharding на основе отбора проб. Значение 1000 означает скорость отбора 1/1000. Он контролирует гранулярность отбора проб и влияет на количество окончательных осколков.
snapshot.split.size
Значение по умолчанию: 8096
Описание:
Количество рядов на кусок в снимке синхронизации. Таблицы будут разделены на куски на основе этого.
snapshot.fetch.size
Значение по умолчанию: 1024
Описание:
Максимальное количество рядов, полученных за опрос во время чтения снимка.
Из этих параметров мы узнали:
Во время синхронизации Seatunnel Buls Data в несколько разрывов. Стратегия шардинга зависит от того, распределены ли данные равномерно.
Наша таблица имеет ~ 60 миллионов строк (по оценкам бизнес -персонала, поскольку мы не могли их считать напрямую).
Поскольку таблица не имеет первичного ключа, мы не были уверены, что Field Seatunnel использует для Chunking.
Мы предположили, что он использовал столбец ID, который имеет уникальный индекс и протестирован:
SELECT MAX(ID), MIN(ID) FROM table;
- Максимальное значение ключа: 804306477418
- Минимальное значение: 607312608210
- Коэффициент распределения = (804306477418 - 607312608210 + 1) / 60 000 000 ≈ 3283,23
Это явно выходит за рамки [0,5, 100] «даже» диапазона → Seatunnel рассматривает это неравномерное распределение.
- Размер чанка по умолчанию: 8096
- Количество осколков = 60 000 000 /8096 ≈ 7411 → больше, чем
sample-sharding.threshold(1000)
Таким образом, Seatunnel, вероятно, переключился на Sharding на основе отбора проб.
- Скорость выборки (обратная): 1000 → необходимость выборки 60 000 строк
В этот момент мы были убеждены, что Seatunnel застрял отбора проб - и мы стали любопытны: как именно это вызывает? Почему он работает в течение 6 часов?
Даже при 60 млн рядах, выборка 60K не должна бытьчтомедленный. Конечно, это сканирует столбец ID (который имеет уникальный индекс)?
Мы решили погрузиться в исходный код.
GitHub:https://github.com/apache/seatunnel/
Архитектура Seatunnel довольно сложна, и создание окружающей среды заняла нас целый день (в основном настройка зависимости).
Поиск критической логики занял еще один день - мы отследили от сообщений журналов и поиска ключевых слов.
Анализ частичного исходного кода
private List<ChunkRange> splitTableIntoChunks(
JdbcConnection jdbc, TableId tableId, Column splitColumn) throws Exception {
final String splitColumnName = splitColumn.name();
// Get min/max values
final Object[] minMax = queryMinMax(jdbc, tableId, splitColumn);
final Object min = minMax[0];
final Object max = minMax[1];
if (min == null || max == null || min.equals(max)) {
// Empty table or only one row — full table scan as a chunk
return Collections.singletonList(ChunkRange.all());
}
// Get chunk size, distribution factor bounds, and sampling threshold from config
final int chunkSize = sourceConfig.getSplitSize();
final double distributionFactorUpper = sourceConfig.getDistributionFactorUpper();
final double distributionFactorLower = sourceConfig.getDistributionFactorLower();
final int sampleShardingThreshold = sourceConfig.getSampleShardingThreshold();
log.info("Splitting table {} into chunks, split column: {}, min: {}, max: {}, chunk size: {}, "
+ "distribution factor upper: {}, distribution factor lower: {}, sample sharding threshold: {}",
tableId, splitColumnName, min, max, chunkSize,
distributionFactorUpper, distributionFactorLower, sampleShardingThreshold);
if (isEvenlySplitColumn(splitColumn)) {
long approximateRowCnt = queryApproximateRowCnt(jdbc, tableId);
double distributionFactor = calculateDistributionFactor(tableId, min, max, approximateRowCnt);
boolean dataIsEvenlyDistributed =
doubleCompare(distributionFactor, distributionFactorLower) >= 0 &&
doubleCompare(distributionFactor, distributionFactorUpper) <= 0;
if (dataIsEvenlyDistributed) {
final int dynamicChunkSize = Math.max((int) (distributionFactor * chunkSize), 1);
return splitEvenlySizedChunks(tableId, min, max, approximateRowCnt, chunkSize, dynamicChunkSize);
} else {
int shardCount = (int) (approximateRowCnt / chunkSize);
int inverseSamplingRate = sourceConfig.getInverseSamplingRate();
if (sampleShardingThreshold < shardCount) {
if (inverseSamplingRate > chunkSize) {
log.warn("inverseSamplingRate {} > chunkSize {}, adjusting...", inverseSamplingRate, chunkSize);
inverseSamplingRate = chunkSize;
}
log.info("Using sampling sharding for table {}, rate = {}", tableId, inverseSamplingRate);
Object[] sample = sampleDataFromColumn(jdbc, tableId, splitColumn, inverseSamplingRate);
log.info("Sampled {} records from table {}", sample.length, tableId);
return efficientShardingThroughSampling(tableId, sample, approximateRowCnt, shardCount);
}
return splitUnevenlySizedChunks(jdbc, tableId, splitColumn, min, max, chunkSize);
}
} else {
return splitUnevenlySizedChunks(jdbc, tableId, splitColumn, min, max, chunkSize);
}
}
Давайте сосредоточимся на логике отбора проб:
public static Object[] skipReadAndSortSampleData(
JdbcConnection jdbc, TableId tableId, String columnName, int inverseSamplingRate
) throws Exception {
final String sampleQuery = String.format("SELECT %s FROM %s", quote(columnName), quote(tableId));
Statement stmt = null;
ResultSet rs = null;
List<Object> results = new ArrayList<>();
try {
stmt = jdbc.connection().createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
stmt.setFetchSize(Integer.MIN_VALUE);
rs = stmt.executeQuery(sampleQuery);
int count = 0;
while (rs.next()) {
count++;
if (count % 100000 == 0) {
log.info("Processing row index: {}", count);
}
if (count % inverseSamplingRate == 0) {
results.add(rs.getObject(1));
}
if (Thread.currentThread().isInterrupted()) {
throw new InterruptedException("Thread interrupted");
}
}
} finally {
if (rs != null) rs.close();
if (stmt != null) stmt.close();
}
Object[] resultsArray = results.toArray();
Arrays.sort(resultsArray);
return resultsArray;
}
Это основная логика выборки:
Он сканирует всю строку таблицы по строке, отбирая 1 из каждых 1000 записей.
Это объясняет, почему он работал так медленно - мы виделиProcessing row indexСообщения в журналах и задавались вопросом, что они делают.
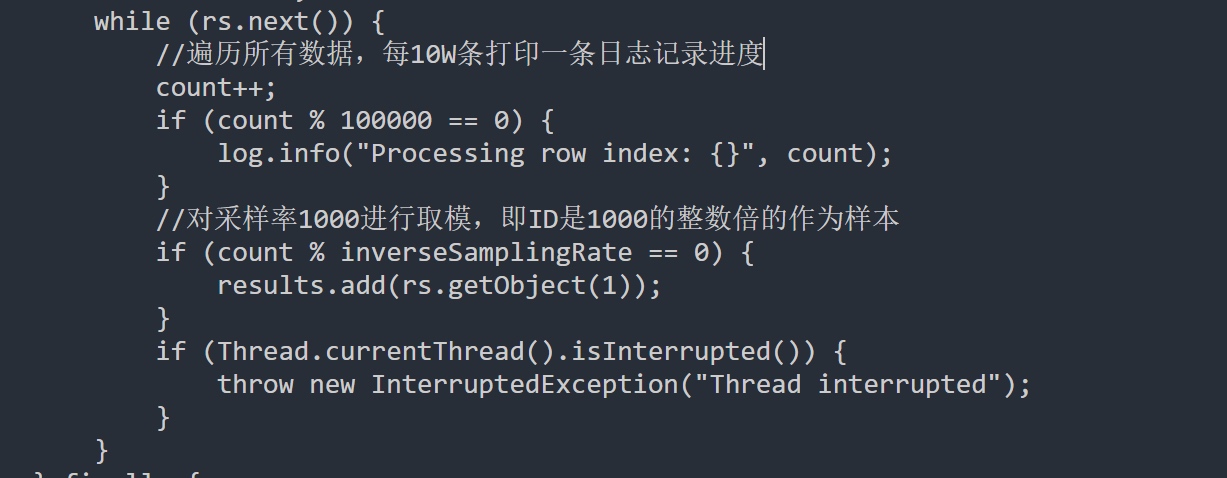
Примерно 60 000 идентификаторов были отобраны.
Теперь для стратегии шардинга на основе отбора проб:
protected List<ChunkRange> efficientShardingThroughSampling(
TableId tableId, Object[] sampleData, long approximateRowCnt, int shardCount
) {
log.info("Using sampling-based sharding on table {}, approx rows: {}, shards: {}",
tableId, approximateRowCnt, shardCount);
List<ChunkRange> splits = new ArrayList<>();
if (shardCount == 0) {
splits.add(ChunkRange.of(null, null));
return splits;
}
double approxSamplePerShard = (double) sampleData.length / shardCount;
Object lastEnd = null;
if (approxSamplePerShard <= 1) {
splits.add(ChunkRange.of(null, sampleData[0]));
lastEnd = sampleData[0];
for (int i = 1; i < sampleData.length; i++) {
if (!sampleData[i].equals(lastEnd)) {
splits.add(ChunkRange.of(lastEnd, sampleData[i]));
lastEnd = sampleData[i];
}
}
splits.add(ChunkRange.of(lastEnd, null));
} else {
for (int i = 0; i < shardCount; i++) {
Object chunkStart = lastEnd;
Object chunkEnd = (i < shardCount - 1)
? sampleData[(int) ((i + 1) * approxSamplePerShard)]
: null;
if (i == 0 || i == shardCount - 1 || !Objects.equals(chunkEnd, chunkStart)) {
splits.add(ChunkRange.of(chunkStart, chunkEnd));
lastEnd = chunkEnd;
}
}
}
return splits;
}
Каждый кусок получает отчетливый старт и конец на основе отсортированных идентификаторов отбирателей - без перекрытия.
Давайте посмотрим наChunkRangeкласс, который представляет результат:
Sharding Snapshot позволяет считываться параллельными данными, ускоряя историческую синхронизацию.
Окончательное решение
Благодаря вышеуказанному анализу мы подтвердили, что задание застряло на этапе снимка, выполняющую выборку, запускаемой, потому что Seatunnel определил, что исходная таблица была неравномерно распределена.
Поскольку задача синхронизации была заблокирована в течение нескольких дней, мы придумали простое исправление: отрегулируйте пороги коэффициента распределения, чтобы Seatunnel рассматривал таблицу как равномерно распределенную и пропустить выборку.
Диапазон коэффициентов по умолчанию0.5 ~ 100, но фактор нашей таблицы был ~ 3283 - поэтому мы увеличили верхнюю границу до 4000. Окончательная конфигурация была:
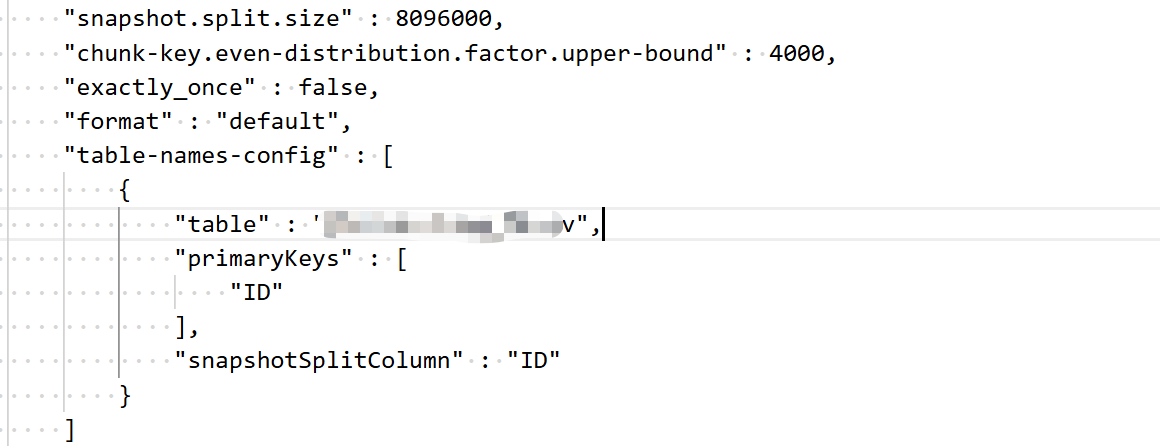
snapshot.split.size: Наша таблица была очень скудной, поэтому мы резко увеличили это значение (случайным образом умножено на 1000 - по общему признанию не очень научно).
table-names-config: Вручную указали первичный ключ и разделенную клавишу, так как в таблице не было первичного ключа, и мы не были уверены, какой столбец Seatunnel использовал. Лучше быть явным.
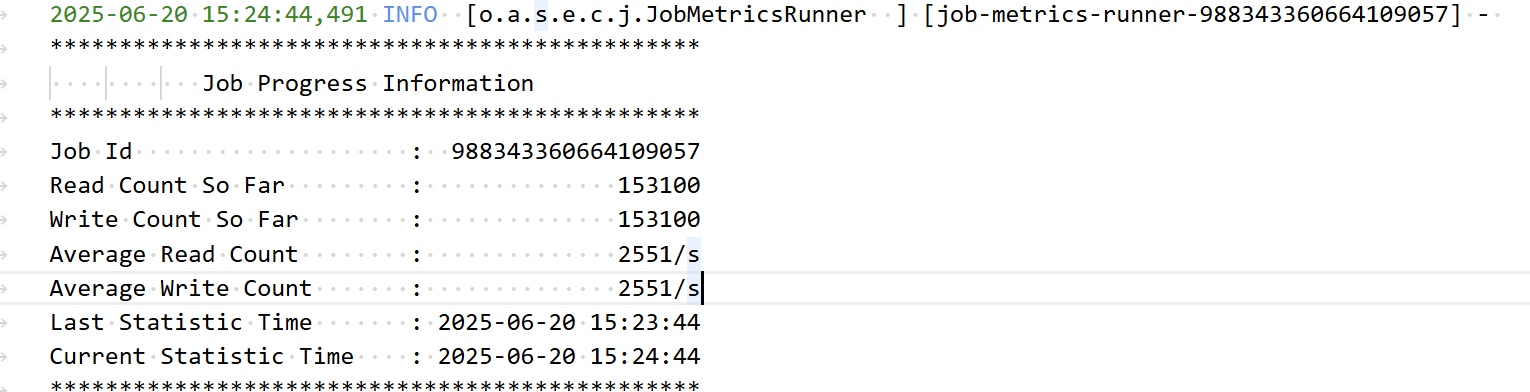
Окончательный результат
Наконец -то начал синхронизировать! 🎉
Оригинал