

Почему команды бросают DynamoDB
17 июля 2025 г.Команды иногда нуждаются в более низкой задержке, более низких затратах (особенно по мере масштаба) или способность запускать свои приложения где -то, кроме AWS.
Легко понять, почему так много команд обратились к Amazon Dynamodb с момента его введения в 2012 году. Это просто начать, особенно если ваша организация уже укоренилась в экосистеме AWS. Это относительно быстро и масштабируемо, с низкой кривой обучения. И поскольку он полностью управляется, он отвлекает оперативные усилия и ноу-хау, традиционно необходимые для поддержания и запуска базы данных в здоровом состоянии.
Но со временем появляются недостатки, особенно в том, что в случае развития масштабов рабочей нагрузки и бизнес -требований развиваются. Команды иногда нуждаются в более низкой задержке, более низких затратах (особенно по мере масштаба) или возможность запускать свои приложения где -то, кроме AWS. В этих случаях SCYLLADB, который предлагает DynamoDB-совместимый API, часто выбирается в качестве альтернативы.
Let’s explore the challenges that drove three teams to leave DynamoDB.
Гибкость и экономия затрат с несколькими облаками
Helfmo-это платформа онлайн-рекламы, которая связывает издателей и рекламодателей в режиме реального времени, используя систему на основе аукциона, оптимизированную с ML. Их бизнес полагается на быстрое предоставление рекламы (в течение 200-300 миллисекунд) и эффективно, что требует ультрастрабильных, высокопроизводительных поисков баз данных в масштабе. Задержка базы данных напрямую переводится на потерянный бизнес.
Первоначально они создали платформу на DynamoDB. Однако, хотя DynamoDB был надежным, по мере их роста появились значительные ограничения. Как объяснил Тодд Коулман, технический соучредитель и главный архитектор, их основные опасения были двояками: эскалация затрат и географические ограничения. База данных становилась все более дорогой по мере их масштабирования, и она заблокировала их в AWS, предотвращая истинную гибкость с несколькими облаками.
Изучая альтернативы DynamoDB, они надеялись найти вариант, который будет поддерживать скорость, масштабируемость и надежность при снижении затрат и обеспечивая независимость поставщика облачных поставщиков.
Доходность сначала рассмотрел остановку с DynamoDB и добавление кэширования слоя. Тем не менее, кэширование не может решить проблему географической задержки. Кэш промахи будет слишком медленным, что делает этот подход непрактичным.
Они также исследовали Aerospike, который предлагал скорость и поддержку кросс-облака. Тем не менее, индексация в памяти Aerospike потребовало бы чрезвычайно большого и дорогого кластера для обработки большого количества небольших объектов Data Data. Кроме того, переход на Aerospike потребовал бы обширных и трудоемких изменений кода.
Затем они обнаружили Scylladb. И Scylladb, совместимый с DynamoDB API (генератор), изменил правила игры.
Тодд объяснил: «SCYLLADB поддержал развертывание кросс -облаков, требовало управляемого количества серверов и предлагал конкурентные затраты. Лучше всего, его API был совместимым с DynamoDB, что означает, что мы могли бы мигрировать с минимальными изменениями кода. Фактически, один инженер внедрил необходимые изменения всего за несколько дней».
Процесс миграции был тщательно спланирован, используя их существующую архитектуру очереди сообщений Kafka, чтобы обеспечить целостность данных. Они провели два теста на доказательство концепции (POC): сначала с одной таблицей из 28 миллиардов объектов, а затем во всех пяти регионах AWS.
Результаты были впечатляющими. Тодд поделился: «Наша стоимость базы данных была сокращена вдвое, даже с зарезервированным ценообразованием DynamoDB». А помимо экономии затрат, урожайность приобрела гибкость, чтобы потенциально развернуться в разных облачных провайдерах. Их задержка улучшилась, и Scylladb был так же прост в работе, как DynamoDB.
Повернувшись, Тодд пришел к выводу: «Одна из наших первоначальных проблем заключалась в том, чтобы уйти от доказанной надежности DynamoDB. Однако Scylladb был отличным партнером. Их команда обеспечивает мониторинг наших кластеров, предупреждает нас о потенциальных проблемах и советует нам, когда масштабирование необходимо с точки зрения постоянного обслуживания.
Слышать от урожайности
Переход на GCP с лучшей производительностью и снижением затрат
Digital Turbine, крупный игрок в области мобильной рекламы с годовым доходом в 500 миллионов долларов, столкнулся с растущими проблемами с его реализацией DynamoDB. В то время как его основной мотивацией для миграции была стандартизация на платформе Google Cloud после приобретения, существующее решение DynamoDB вызывало как производительность, так и проблемы в масштабе.
«Честно говоря, это может быть немного дорого», - объяснил Джозеф Шортер, вице -президент по архитектуре платформы в Digital Turbine.
«Мы находили некоторые проблемы с производительностью. Мы делали тонну чтения - 90% всех взаимодействий с DynamoDB были операциями чтения. Со всеми этими операциями мы обнаружили, что достижения производительности требуют от нас масштабировать больше, чем мы хотели, что увеличило затраты».
Цифровая турбина нуждалась в миграции, чтобы быть максимально быстрой и низкой риском, что означало, что рефактор приложения к минимуму. Основная проблема, по словам Шортера, заключалась в том, что «как мы можем мигрировать без радикально рефакторной нашей платформы, сохраняя при этом, по крайней мере, такую же производительность и ценность-и избежать ситуации с крахом и сжиганием? Потому что, если она потерпела неудачу, это снесет всю нашу компанию».

После оценки нескольких вариантов цифровая турбина переехала в Scylladb и достигла немедленных улучшений. Миграция заняла меньше, чем спринт, и результаты превзошли ожидания.
«Разница в 20% - это большое число, независимо от того, о чем вы говорите», - отметил Шортер. «И если учесть наши планы, чтобы масштабироваться еще дальше, это становится еще более значимым».
Помимо экономии средств, они оказались «едва выявляющими кластеры Scylladb», предлагая место для еще большего роста без увеличения пропорциональных затрат.
Слушать из цифровой турбины
Высокая пропускная способность записи с низкой задержкой и более низкими затратами
Пользовательская команда и команда настройки для одной из крупнейших в мире служб потоковой передачи медиа использовала DynamoDB в течение нескольких лет. Поскольку они разрабатывали два существующих варианта использования, они задавались вопросом, пришло ли время для изменения базы данных. Два варианта использования были:
- Пауза/резюме:Если пользователь смотрит шоу и останавливает его, он может забрать с того места, где остановился - на любом устройстве, из любого места.
- Смотреть состояние:Используя те же данные, определите, смотрел ли пользователь шоу.
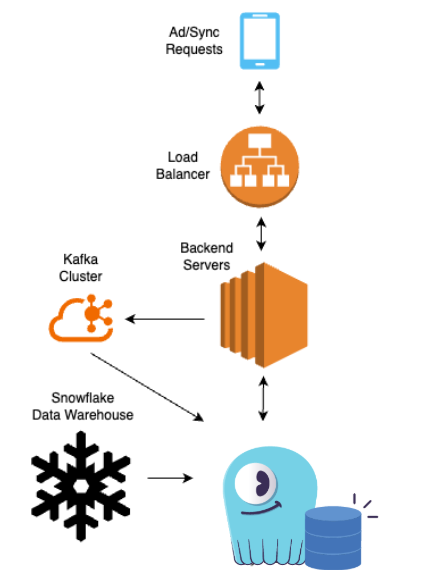
Вот простая архитектурная схема:

Каждые 30 секунд клиент отправляет сердцебиение с обновленной позицией Playhead шоу, а затем отправляет эти события в базу данных. Edge Pipeline загружает события в том же регионе, что и пользователь, в то время как авторитет (Auth) сочетает в себе события для всех пяти регионов, которые обслуживает компания. Наконец, данные должны быть извлечены и возвращаются клиенту для поддержки воспроизведения. Обратите внимание, что команда хотела сохранить разделение между областями Auth и Edge, поэтому они не искали какую-либо репликацию, специфичную для базы данных между ними.
Двумя основными техническими требованиями для поддержки этой архитектуры были:
- Чтобы обеспечить отличный пользовательский опыт, система должна была оставаться очень доступной, с чтениями с низкой задержкой и возможности масштабирования в зависимости от скачков трафика.
- Чтобы избежать обширной настройки инфраструктуры или работы DBA, им потребовалась легкая интеграция со своими услугами AWS.
Как только эти коробки были проверены, команда также надеялась снизить общую стоимость.
«Наша существующая инфраструктура имела данные, распространяющиеся по различным кластерам DynamoDB и Elasticache, поэтому мы действительно хотели что -то простое, что могло бы объединить их в гораздо более низкую систему затрат», - объяснил их инженер -бэкэнд.
В частности, им нужна база данных с:
- Поддержка Multiregion, так как услуга была популярна в пяти основных географических регионах.
- Способность обрабатывать более 170 тысяч пишет в секунду. Обновления не имели строгого соглашения на уровне обслуживания (SLA), но система, необходимая для выполнения условных обновлений на основе временных метров событий.
- Способность обрабатывать более 78 тыс. Чтения в секунду с задержкой P99 от 10 до 20 миллисекунд. В случае использования включал только простые точечные запросы; Такие вещи, как индексы, разделение и сложные модели запросов, не были основной проблемой.
- Около 10 ТБ данных с местом для роста.
Зачем переходить от DynamoDB? По словам их бэкэнд-инженера, «DynamoDB может идеально поддерживать наши технические требования. Но с учетом нашего размера данных и высокой (тяжелой) пропускной способности, продолжение DynamoDB было бы похоже на то, что вытирают деньги в огонь».
Основываясь на их требованиях к производительности и стоимости записи, они решили исследовать Scylladb. Для подтверждения концепции они создали тестовый кластер Scylladb с шестью узлами AWS I4I 4xlarge и предварительно загрузили кластер с 3 миллиардами записей. Они выполняли комбинированные нагрузки 170 тысяч пищи в секунду и 78 тыс. Чтения в секунду. А результаты? «Мы достигли комбинированной нагрузки с нулевыми ошибками. Наша задержка чтения P99 составила 9 мс, а задержка записи составляла менее 1 мс».
Эти низкие задержки в сочетании со значительной экономией затрат (более 50%) убедили их покинуть DynamoDB. Помимо более низких задержек при более низких затратах, команда также оценила следующие аспекты Scylladb:
- Конструкция Scylladb, ориентированная на производительность (строительство на основе Seastar, используя C ++, будучи NUMA, предлагая драйверы, осведомленные о шарде и т. Д.) Помогает команде сократить время обслуживания и затраты.
- Стратегия инкрементного уплотнения помогает им значительно снизить усиление записи.
- Гибкий уровень согласованности и коэффициенты репликации помогают им поддерживать отдельные трубопроводы и края. Например, Auth использует согласованность Quorum, в то время как Edge использует уровень согласованности «1» из -за дублирования данных и высокой пропускной способности.
Их бэкэнд инженер пришел к выводу: «Выбор базы данных сложно. Вам необходимо рассмотреть не только функции, но и затраты. Без сервера не является серебряной пулей, особенно в домене базы данных.
«В нашем случае, из -за высоких требований к пропускной способности и задержке, DynamoDB Serverbless не был отличным вариантом. Кроме того, не недооценивайте роль оборудования. Лучше использование оборудования является ключом к снижению затрат при повышении производительности».
Узнать больше
Ваша команда в следующей?
Если ваша команда рассматриваетход от DynamoDBВScylladb может быть вариантомисследовать. Зарегистрируйтесьтехническая консультацияЧтобы узнать больше о вашем варианте использования, SLA, технических требованиях и о том, что вы надеетесь оптимизировать. Мы сообщим вам, если Scylladb подходит, и, если да, то, что может включать миграцию с точки зрения изменений приложений, моделирования данных, инфраструктуры и так далее.
Бонус: Вот быстрый взгляд на то, как Scylladb сравнивается с DynamoDB:
Написано: Guilherme da silva nogueiraиФелипе Карденти МендесПолем
Оригинал