
Почему OCR борется со страницами с несколькими колоннами
20 августа 2025 г.Таблица ссылок
Аннотация и 1. Введение
1.1 Печатная станка в Ираке и Иракском Курдистане
1.2 Проблемы в исторических документах
1.3 Курдский язык
Связанная работа и 2,1 арабского/персидского
2.2 Китайский/японский и 2,3 коптса
2.4 Греческий
2.5 латынь
2.6 Tamizhi
Метод и 3.1 Сбор данных
3.2 Подготовка данных и 3.3 Предварительная обработка
3.4 Настройка среды, 3,5 подготовка набора данных и 3,6 Оценка
Эксперименты, результаты и обсуждение и 4.1 обработанные данные
4.2 Набор данных и 4.3 эксперименты
4.4 Результаты и оценка
4.5 Обсуждение
Заключение
5.1 Проблемы и ограничения
Онлайн -ресурсы, подтверждения и ссылки
4.4 Результаты и оценка
После завершения обучения мы оценили модель, используя различные методы. В этом разделе мы показываем результаты для каждого метода оценки. Во время учебного процесса тренер дает отчет, в котором изложено точность модели каждые 100 итераций. После того, как обучение было завершено, мы оценили модель с использованием оценки Tesseract и получили минимальное значение ошибок обучения (BCE) 0,755%.
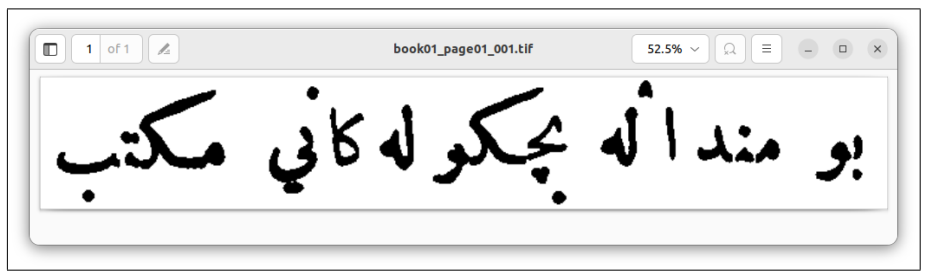
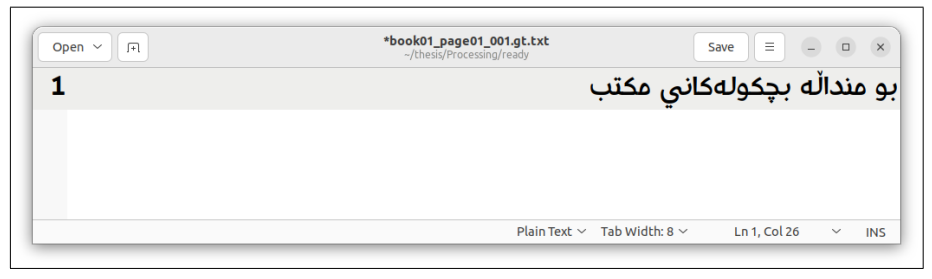
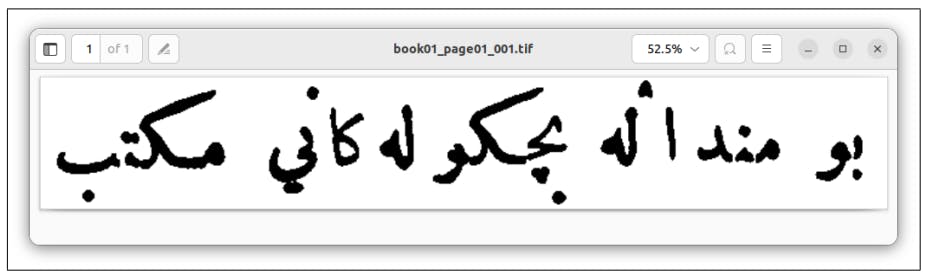
Мы случайным образом выбрали подмножество страниц из собранных данных, которые не использовались при обучении и тестировании модели. Эти страницы были транскрибированы вручную, а изображения страниц и их соответствующие ручные транскрипции были представлены в Ocreval для оценки. Результаты этой оценки можно наблюдать на рисунках 18, 19, 20 и 21.
4.5 Обсуждение
Ограниченная доступность ресурсов представила значительные проблемы в процессе сбора данных. Преобразование собранных данных в цифровой формат оказался дополнительным препятствием, за которое мы получили поддержку от Центра документации и повторного поиска Центра Zheen. Ручная транскрипция документов ставила значительную трудность из-за неясного текста, нестандартного интервала между словами и персонажами, а также уникальный словарь под влиянием арабских букв и терминологий. Кроме того, мы обнаружили, что у системы возникают проблемы при правильном извлечении текста со страниц с несколькими колоннами и математических уравнений.
В этом исследовании мы переподходили существующую арабскую модель, используя наш уникальный курдский набор данных, что дало замечательные результаты. Учитывая наши выводы, если мы дальше обучаем модель на более крупном наборе данных, она может создать результаты, подходящие для использования в производстве. Такая модель может значительно помочь библиотекам и центрам в эффективном извлечении текста из исторических документов.
Авторы:
(1) Blnd Yaseen, Университет Курдистана, Регион Курдистан - Ирак (blnd.yaseen@ukh.edu.krd);
(2) Университет Курдистана Хоссейна Хассани Курдистана Регион Курдистан - Ирак (hosseinh@ukh.edu.krd).
Эта статья есть
Оригинал