

Почему ни один алгоритм не решает дедупликацию - и что делать вместо этого
10 июля 2025 г.Обнаружение дублирующихся сущностей в масштабе сложно из -за взрыва в парных сравнениях. Наивный подход к совпадениюнеПредметы друг с другом требуют сравнения O (N²). Цель состоит в том, чтобы обрезать пространство поиска, сохраняя при этом высокий отзыв (ловив наиболее настоящие дубликаты). Современные трубопроводы по деупликации, поэтому используютКандидат поколениеФаза с помощью блокирующих клавиш, хеширования, поиска и т. Д. - для сравнения только записей, которые, вероятно, совпадают. В этой статье мы обсуждаем стандартные и передовые методы блокировки, вероятностное хеширование (LSH), фильтрацию сходства с плотным вектором и мультимодальное (текст+изображение). Акцент делается на достижение высокого отзыва на многоязычные мультимодальные данные путем объединения различных стратегий.
Стратегии блокировки снижения кандидатов
Блокировка - это канонический метод, который группирует записи в блоки на основе некоторых ключей, так что сравниваются только элементы в одном и том же блоке. Эффективное блокирование резко сокращает сравнения, все еще группируя истинные дубликаты вместе. Несколько стратегий блокировки могут быть применены в нескольких простых для улучшения отзыва:
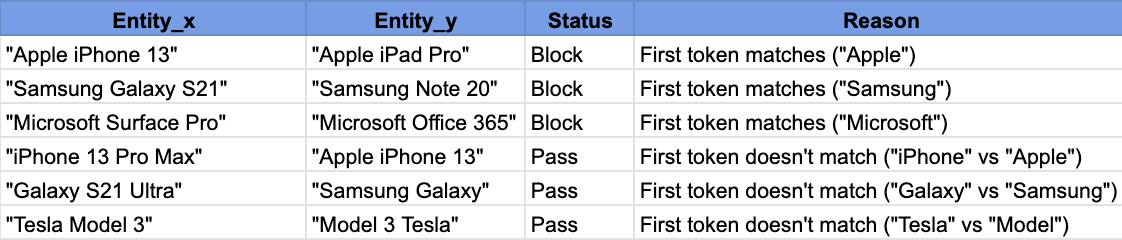
Стандартная блокировка:Определите блокирующий ключ из атрибутов записи (например, первые 3 символа названия продукта, нормализованный бренд и т. Д.). Записи, разделяющие один и тот же ключ, идут в один и тот же блок, и только они сравниваются. Этот подход использует принцип, который дублирует записи, как правило, разделяют общие жетоны или функции. Например, блокировка первыми тремя буквами заголовка будет группировать продукты, начиная с «SAM» вместе (вероятно, Samsung Itse). Стандартная блокировка проста и быстрая, но один ключ блокировки может пропустить дубликаты, которые отличаются по этому ключу (низкий отзыв, если данные грязные или многоязычные).
Многопроходная и иерархическая блокировка:Чтобы улучшить отзыв, запустите несколько проходов блокировки с разными ключами и возьмите союз пар кандидатов. Пример сортированный метод соседства по нескольким проходам: один проход может блокировать брендом, другой по модели продукта и т. Д., Так что если дубликатная пара сбои не удается один ключ блокировки, он может быть пойман другой. После нескольких проходов все пары кандидатов объединяются, и транзитивное закрытие выполняется для кластерных дубликатов.Иерархическая блокировкаидет дальше, используя последовательность клавиш в иерархии (грубо до тонкого). Например, можно сначала блокировать широкую категорию (например, электронику против одежды), а затем в каждом блоке категории от бренда, затем по более тонкому клавишу, как номер модели. Эта многослойная блокировка гарантирует, что только очень похожие предметы наконец сравниваются. Учененные правила блокировки также объединяют несколько предикатов (даже по областям) для созданияконъюнктивные блоки(например, тот же город и тот же почтовый индекс) для более высокой точности, а такжеДизъюнктивные комбинациирасширить отзыв.

Кластеризация навеса:ЭтоМягкая блокировкаТехника с использованием недорогой меры сходства для создания перекрывающихся кластеров, называемыхнавесыПолем Все элементы в навеса считаются потенциальными совпадениями. Например, используйте дешевую метрическую метрическую сходство TF -IDF Cosine или общие токены для грубо группируют продукты. Каждая запись может попасть в несколько навесов, обеспечивая отзыв (поскольку навесы перекрываются, без жесткого разреза). После этого вычисляется более дорогое сходство (например, расстояние редактирования или модель ML)внутри каждого навесаДля принятия окончательных решений. Подход навеса (McCallum et al.) Торгает некоторых дополнительных кандидатов назначительно улучшенный отзыв и скорость, и было показано, что во многих случаях превзойдет традиционную блокировку с одним проходом. Методы купола потенциально могут быть полезны для многоязычных данных, где недорогое сравнение (например, общие числовые токены или очень распространенные слова) может группировать элементы между языками перед более тонким сравнением.
Отсортировано соседство и окно:Еще один классический подход - сортировать записи по некоторым ключам, а затем сравнить только записи, которые появляются в скользящем окне размераW.в отсортированном порядке. Это предполагает, что дубликаты будут сортироваться рядом друг с другом. Многопроходная отсортированная соседство работает несколько раз с разными клавишами сортировки. Этот метод также снижает сравнения от N² до N · W, но выбор хороших клавиш является решающим и сложным.
Современные блокирующие трубопроводы частоучитьсяОптимальная комбинация правил блокировки из помеченных примеров. Например, библиотека Dedupe пробует множество функций предикатов (префиксы, N-граммы и т. Д.) На полях и использует жадный алгоритм сет-покрытия для выбора небольшого набора правил блокировки, которые охватывают все обучающие дубликаты при минимизации сравнений. Это обучение обеспечивает высокий отзыв о известных дубликатах с минимальными блоками. В целом, блокировка является критическим первым шагом к приручительной квадратичной сложности, и при применении многопроходным образом он может обеспечить набор кандидатов с высоким качеством.
Вероятностное поколение кандидатов (LSH)
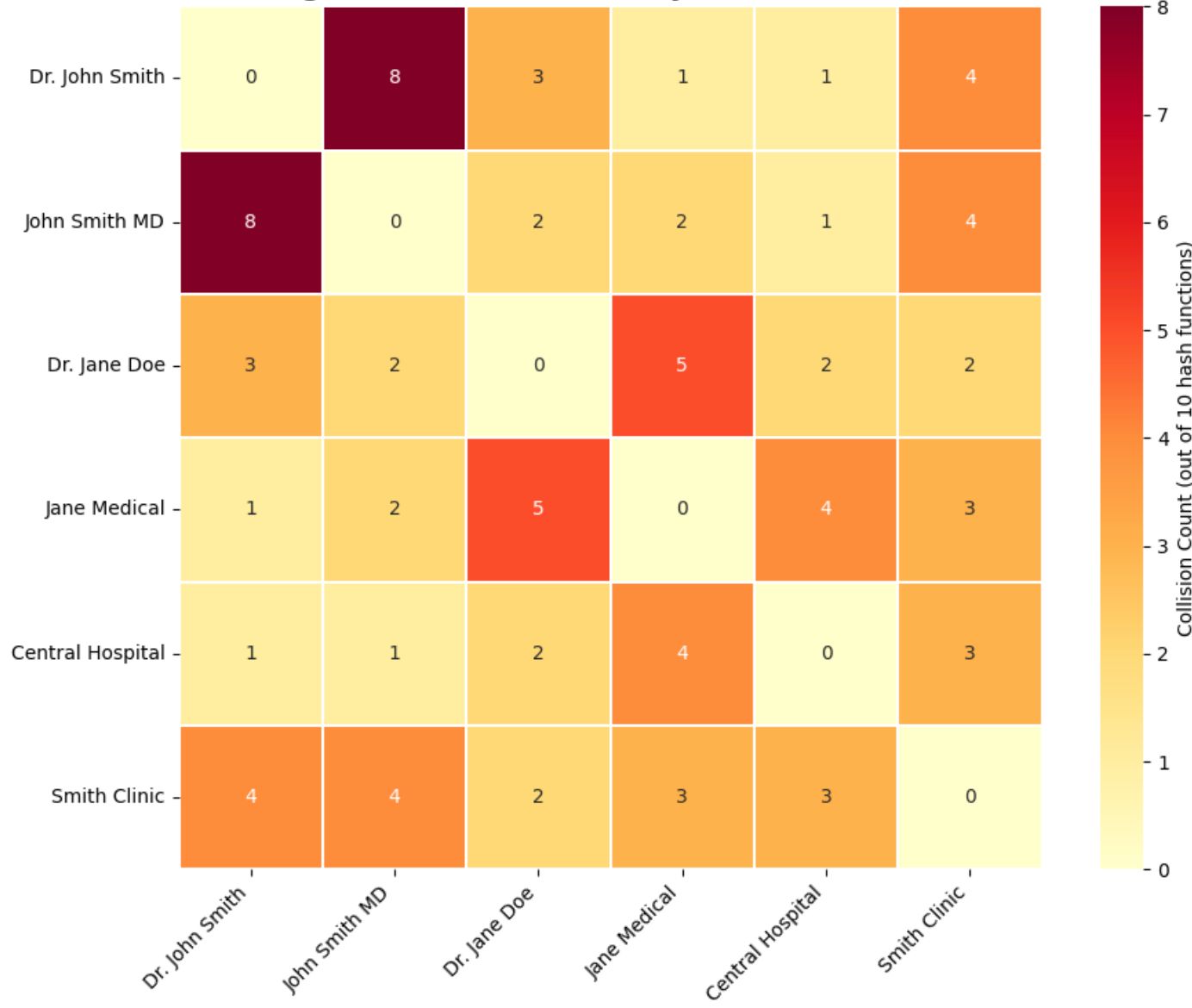
Чувствительное к месту хешинг (LSH)является вероятностной техникой, которая хэширует элементы таким образом, что подобные элементы могут приземлиться в одном и том же ведре (с высокой вероятностью). Подумайте о хешировании, как сортировка почты в разные почтовые ящики, LSH создает «умные мусорные баки», где подобные записи естественным образом оказываются вместе, даже когда они не совсем идентичны. Это можно рассматривать как обобщение блокировки, когда «блокирующие клавиши» получены из случайных проекций или минимального хэширования функций, а не явных атрибутов. LSH особенно полезен для высокомерных представлений (текстовая черепица, встраиваемые и т. Д.), Там, где прямая блокировка жестко. Ключевая идея: используйте несколько хэш -функций из семейства LSH таким образом, чтоИстинные дубликаты сталкиваются как минимум в одном хешс высокой вероятностью. Каждая хеш -функция фокусируется на различных аспектах данных: можно группировать первые токены, другой по последним токенам и третьи по структурным моделям. Это гарантирует, что аналогичные предметы имеют множество возможностей, которые можно найти вместе. Предметы, которые часто сталкиваются с различными хэш-функциями, становятся кандидатами с высокой достоверностью, в то время как те, которые редко сталкиваются, вероятно, являются разными (как показано на рисунках ниже). Затем столкновения образуют пары кандидатов для подробного сравнения. Приведенные ниже иллюстрации ясно демонстрируют этот принцип: «Доктор Джон Смит» и «Джон Смит MD» сталкиваются во всех трех хэш-функциях, потому что они разделяют множественные токены, что делает их самой высокой достоверной парой кандидатов с 3 столкновениями. Между тем, не связанные с этим предметы, такие как «Центральная больница» и «доктор Джон Смит», редко сталкиваются, естественно, отфильтровывая маловероятные матчи. Затем столкновения образуют пары кандидатов для подробного сравнения.

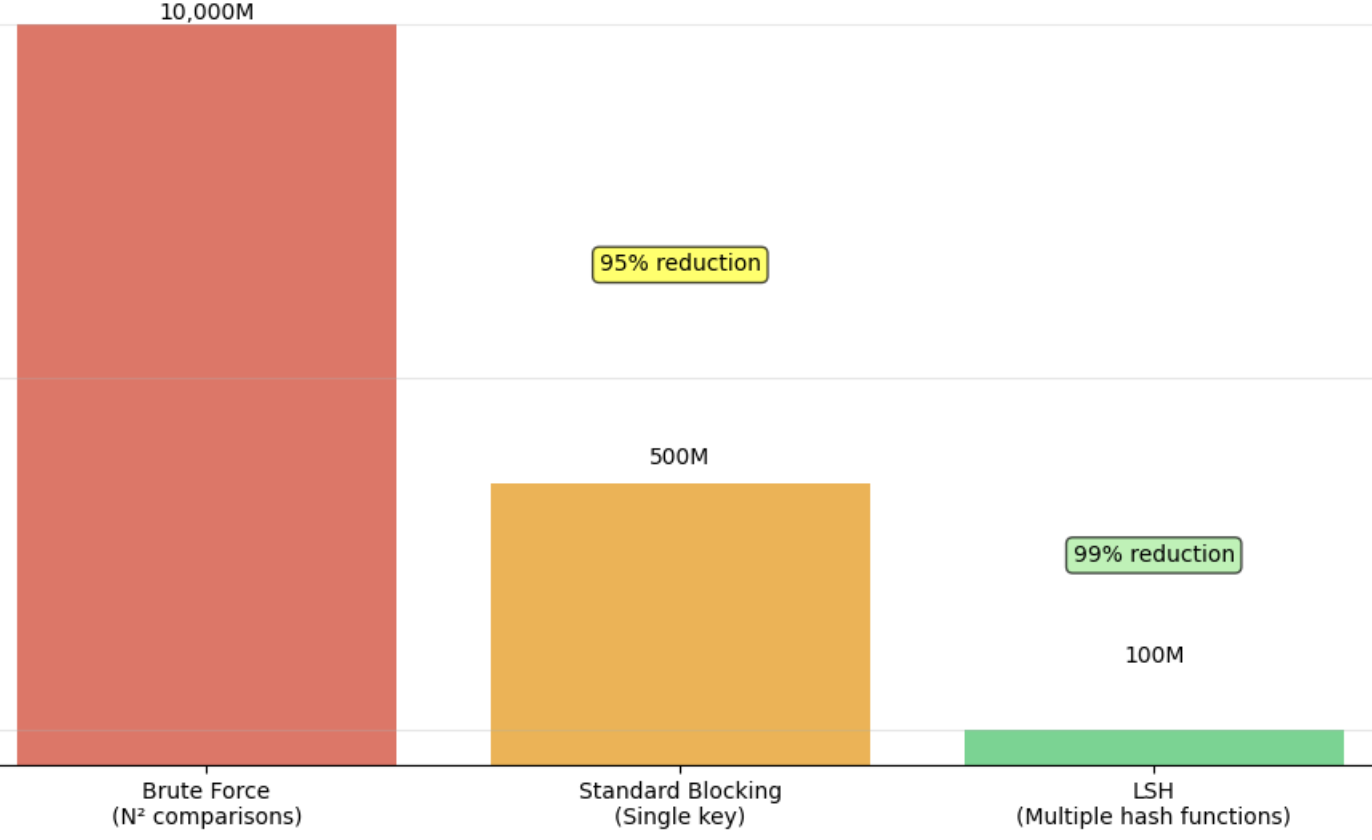
Общие варианты LSH включаютМинхашДля сходства Jaccard (например, на наборах токенов заголовка) иСимхаш(форма подписанной случайной проекции для сходства косинуса) для текстовых или векторных данных. Например, Min-Hashing может сжать набор слов описания продукта в короткую подпись; Идентичные или почти идентичные описания будут иметь соответствующие подписи с высокой вероятностью. Техника полосы может дополнительно группировать аналогичные подписи. Во многих внедрениях в отрасли LSH (Minhash On Spatial или текстовые функции) переводил сравнение N², заняв несколько дней в искру, в течение нескольких часов, полного ускорения по порядку матчей. Это иллюстрирует силу LSH, чтобы обменять крошечное каплю в точности намассивные достижения в масштабируемостиПолем


Другие методы вероятностной фильтрации включаютБлокировка Bloom на основе фильтра(Жетоны хешина, чтобы утомить массивы, чтобы быстро предварительно скольжения кандидатов) иэскизы(например, использование эскиза Count-Min для подсчета редких комбинаций). Например, HDB использует эскиз Count-Min для приблизительных размеров блоков без дорогих перетасовки данных. При проверке, является ли блок, содержащий «Furname = Smith», негабаритный, эскиз может быстро оценить, что он содержит ~ 50 000 записей, помечая его для пересечения с другими большими блоками, а не дорогостоящим точным подсчетом.Хэшированная динамическая блокировка(HDB) является хорошим примером: он динамически изучает редкие клавиши блокировки (комбинации значений атрибутов, которые очень характерны для совпадений) и использует LSH для обобщения этих ключей для больших баз данных. HDB может обнаружить, что в то время как «Furname = Smith» только создает массивные блоки, пересечение «Фамилия = Smith и First_name = John and Birth_year = 1985» встречается только в 12 записях, что делает его отличным ключом блокировки, который является как выборочным, так и вычислительно осуществимым. Компонент LSH обеспечивает настраиваемую ручку между отзывами и точностью блокировки для огромных данных.
Таким образом, вероятностные методы, такие как LSH, значительно уменьшают парные вычисления, индексируя элементы в ведра на основе хэш-функций, сохраняющих сходство. В отличие от строгого блокировки, LSH может захватывать нечеткие совпадения и позволяет четко компромисс: больше хэш-таблиц или более разрешительных параметров LSH увеличивает отзыв (ловить больше пар) за счет большего количества кандидатов. Эти методы стали стандартными в промышленности для обнаружения почти дублирования, часто интегрированных в платформы больших данных (например, Mllib Spark включает в себя классы Minhashlsh и Random Projection LSH).
Sparse vs. Плотная фильтрация сходства вектора
Другой крупный подход рассматривает дубликат обнаружения как проблему поиска информации, аналогично тому, как работают поисковые системы. Вместо того, чтобы сравнивать каждую запись с каждой другой записью, система ищет наиболее похожие записи с каждым элементом. Это значительно уменьшает вычислительную нагрузку при естественной обработке многоязычных данных.
Редкий текстовый поиск
Традиционные методы поиска информации, такие какTF-IDF(Терминчатная частота документов с частотой) иBM25Преобразуйте текст в редкие векторы, которые являются математическими представлениями, где большинство значений равны нулю, с ненулевыми значениями только для слов, присутствующих в тексте. Эти системы строятперевернутые индексы(как указатель книги).
Для академических документов вы можете индексировать все названия и тезисы публикаций, а затем искать 10 самых похожих статей при проверке дубликатов. Вместо того, чтобы сравнивать с миллионами статей, вы изучаете только самых перспективных кандидатов. Это работает хорошо, потому что дубликаты часто делятся конкретными идентифицирующими ключевыми словами, такими как: имена журналов, фамилии автора, медицинские диагностические коды, техническая терминология и т. Д.
Подход использует десятилетия оптимизации поисковой системы, что делает его быстро и масштабируемым. Тем не менее, разреженные методы имеют фундаментальное ограничение: они только захватываютлексическое сходствочерез точные совпадения слова. Когда записи пациентов используют разные термины, такие как «гипертония» против «высокого кровяного давления», эти системы не могут распознать семантическое соединение. Чтобы улучшить отзыв для многоязычных данных, системы могут расширять запросы с переводами или использовать межсочевую индексацию, но они все еще не могут понять, что «手机» (китайский) и «мобильный телефон» (английский) означают одно и то же без явных словарей.
Плотные встраиваемые и Энн Поиск
Плотные векторные встраивания представляют собой сдвиг парадигмы. Нейронные сети, особенно языковые модели, такие как Берт и Роберта, преобразуют текст в плотные векторы, где каждая позиция содержит значимую информацию о семантическом содержании. В отличие от разреженных векторов, которые считают слова, плотные встраивания отражают значение, контекст и отношения между концепциями.
Прорыв поставляется с многоязычными моделями, такими как Mbert, XLM-R и Labse, которые сопоставляют текст из разных языков в общее математическое пространство. Немецкий пациент -запись о сердечных процедурах и его английском эквиваленте может стать близлежащими векторами, несмотря на то, что он не разделяет общих слов, потому что ИИ узнал, что «Герзинфаркт» и «сердечный приступ» представляют собой ту же медицинскую концепцию.
Поиск аналогичных записей среди миллионов плотных векторов требует приблизительных алгоритмов поиска ближайших соседей (ANN). HNSW (иерархическая судоходная маленькая мир) создает графические структуры, где аналогичные векторы соединяются друг с другом, что позволяет быстрое навигацию с почти 100% отзывом в подростковое время. FAISS предлагает альтернативные подходы, такие как ЭКО (перевернутый файл), которые разделяют векторное пространство на кластеры и ищут только соответствующие ведра, что делает его возможным для индексации 100 м+ встраиваний со временем запроса в десятках миллисекунды.
Для финансовых учреждений отдельные индексы FAISS могут содержать встраивания для описаний транзакций и торговых категорий, каждая из которых обрабатывает миллионы векторов. При исследовании подозрительных транзакций система находит наиболее семантически похожие транзакции Top-K. Критическим аспектом является установление соответствующих значений для K (количество соседей) и порогов сходства. Если k слишком низкий, вы пропускаете дубликаты (нижний отзыв); Если слишком высокий, вы включаете отдаленные не дубликаты (больше сравнений).
Этот подход преобразует задачу сопоставления в задачу поиска: Учитывая векторное представление элемента, найдите наиболее похожие векторы в базе данных вместо сравнения с каждым элементом. Результатом является система, которая понимает семантическое сходство между языками, сохраняя при этом вычислительную эффективность для крупномасштабных операций.
Сочетание сильных сторон: гибридные подходы
Реальные системы все чаще объединяют обе методологии. Гибридный подход может использовать сопоставление ключевых слов BM25, чтобы собрать несколько сотен кандидатов, разделяющих основные термины, а затем применить встраивание сходства, чтобы выбрать наиболее семантически релевантные. Для записей здравоохранения это означает сначала поиск пациентов с общими диагностическими кодами посредством сопоставления ключевых слов, а затем с использованием семантического анализа для выявления перефразированных симптомов. Плотные векторы обеспечивают дополнительную фильтрацию с помощью порогов сходства косинуса (например,> 0,8) для обрезки очевидных не матчей до дорогих сравнений. Стратегия Союза объединяет результаты из нескольких методов, таких как текстовые встроения, встроенные изображения и сопоставление ключевых слов - используя дополнительные силы. Этот подход также может быть использован для выбора кандидатов для мультимодальных объектов. Страт с LSH на текстовых атрибутах, затем используйте сходство косинуса и изображения по изображениям, чтобы выбрать кандидатов для окончательного классификатора, который является наиболее дорогим и эффективным.

Заключение
Современное обнаружение дубликатов в масштабе требует объединения дополнительных методов для достижения как высокой отзывы, так и вычислительной эффективности. Ни один метод превосходит во всех сценариях: традиционная блокировка обеспечивает быстрое поколение кандидатов, но борется с многоязычными данными, в то время как плотные встраивания обеспечивают межнеязычное понимание при более высоких затратах на вычислитель и использование нескольких модальностей захватывают дубликаты, которые пропускают только текстовые методы. Наиболее эффективные системы используют гибридные трубопроводы, которые Союз является результатом разреженного поиска, плотных вторжений и мультимодальных сигналов, достигая высокого отзыва, одновременно снижая сравнения от квадратичной до субквадратической сложности. По мере того, как данные растет в объеме и разнообразии, успех заключается не в выборе между этими методами, а в том, чтобы эффективно организовать их, чтобы справиться с полной сложностью современных проблем дедупликации между языками, областями и методами данных.
Ссылки:
- Elmagarmid, A., Ipeirotis, P. & Songykios, V.Дубликатное обнаружение записей: опросПолем IEEE TKDE, 19 (1).https://www.cs.purdue.edu/homes/ake/pub/survey2.pdf
- Borthwick, A. et al. (2020).Масштабируемая блокировка для очень больших баз данныхПолем Amazon Science.https://assets.amazon.science/9d/b5/d7abad814e5fba5cc03806900fd0/scalable blocking-for-every-large-databases.pdf
- Dhonzi, T. et al. (2016).Дублирование обнаружения в веб -магазинах с использованием LSHПолем SAC ’16.https://personal.eur.nl/frasincar/papers/sac2016/sac2016.pdf
- Zeakis, A. et al. (2023).Предварительно обученные встраивания для разрешения сущности: экспериментальный анализПолем PVLDB 16 (9).https://www.vldb.org/pvldb/vol16/p2225-skoutas.pdf
- McCallum, A., et al. (2000).Эффективная кластеризация высокомерных наборов данных(Кластеризация навеса).https://www.cs.purdue.edu/homes/ake/pub/survey2.pdf
- Dedupe.io документация (2024).Блокировка и предикаетсяПолемhttps://docs.dadupe.io/en/latest/how-it-works/making-smart-comparisons.html
- Компания Coupang Engineering Blog (2022).Соответствующие дубликаты предметов для улучшения качества каталогаПолемhttps://medium.com/coupang-engineering/matching-duplicate-items-to-improve-catalog-quality-ca4abc827f94
- Блог Uber Engineering (2017).Обнаружение злоупотребления в масштабе: LSH в UberПолемhttps://www.databricks.com/blog/2017/05/09/detection-abuse-s.sale-locality-sensity-hashing-uber-engineering.html
- Peeters, R. & Bizer, C. (2022).Межязычное обучение для сопоставления продуктовПолем Www '22 Companion.https://arxiv.org/pdf/2110.03338
- KNN Search и BM25 Обзор.https://medium.com/coupang-engineering/matching-duplicate-items-to-improve-catalog-quality-ca4abc827f94
Оригинал